一、解构RAG
1.Context
近日OpenAI联合创始人的Andrej Karpathy表示LLM更像是一种新型操作系统的CPU。正如现代计算机具有RAM和文件访问权限一样,LLM也有一个Context Window,可以加载从多个数据源检索到的信息。如下图。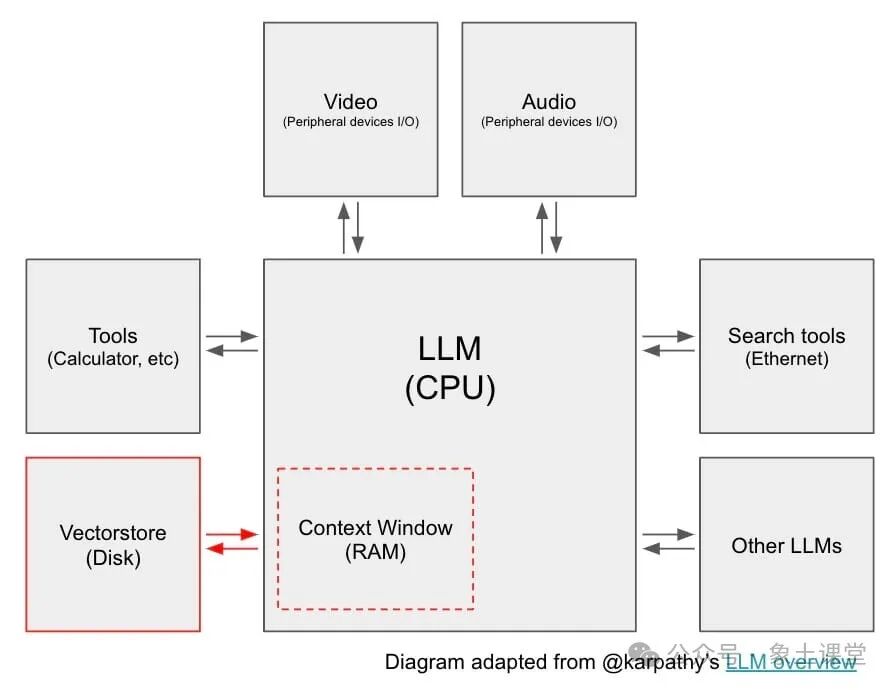
所有检索到的信息被加载到Context Window中,并用于LLM输出生成,这个过程通常称为检索增强生成(RAG)。RAG是LLM应用程序开发中最重要的概念之一,因为它是将外部信息传递给LLM的简单方法,与更复杂的微调相比具有一定的优势。通常RAG系统涉及:确定要检索哪些信息的问题(通常来自用户),从数据源(或来源)检索该信息的过程,以及将检索到的信息作为提示词(prompt)的一部分直接传递给LLM的过程。2.挑战
随着RAG的应用越来越广泛,也衍生出很多问题!最典型的就是用户对从哪里开始?!以及如何考虑各种方法产生一定程度的疑虑和困惑!下面我们将集中讨论一些概念和进展以便给大家解除一些疑惑,提供一些可行的方案。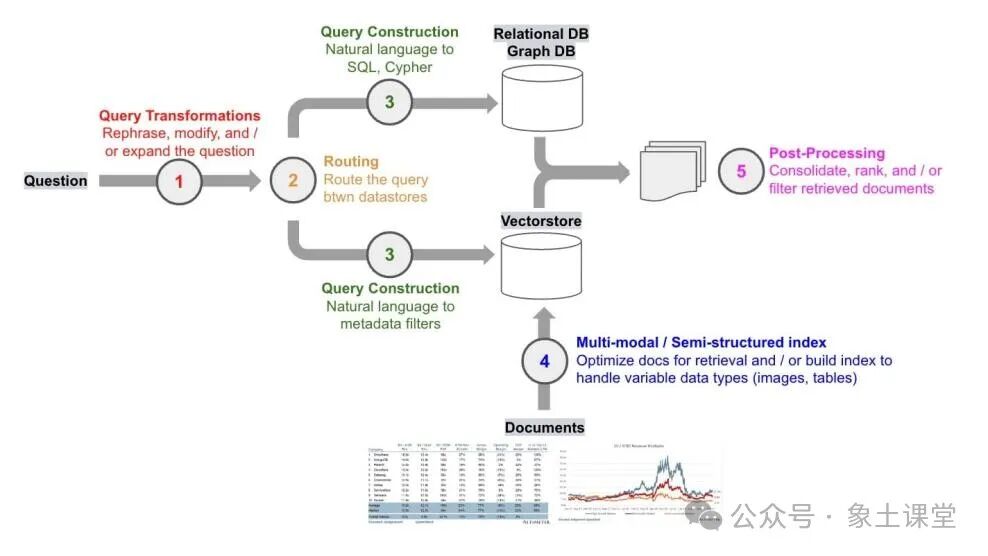
3.查询转换
考虑RAG落地时要问的第一个问题是:我们如何使检索对用户输入的变异性稳健?
查询扩展
例如,用户的问题可能措辞不当,不严谨。查询转换是一套专注于修改用户输入以改善检索的方法。下面我们想象一个应用场景,用户的问题是:
“谁最近赢得了冠军,红袜队还是爱国者队?”
回答这个问题可以通过询问两个具体的子问题中而获得更加精准的答案:
“红袜队上一次赢得冠军是什么时候?”
“爱国者队上一次赢得冠军是什么时候?”
查询扩展将输入分解为子问题,每个子问题都是范围更小更加具体的检索挑战。multi-query retriever执行子问题生成、检索,并返回检索到的文档。
查询重写
为了解决框架或措辞不当的用户输入,Rewrite-Retrieve-Read(论文)是一种重写用户问题以改善检索的方法。查询压缩
在一些RAG应用程序中,如WebLang(open source research assistant),用户问题遵循更广泛的聊天对话。为了正确回答问题,可能需要完整的对话上下文。为了解决这个问题,我们使用此提示将聊天历史记录压缩为最后一个问题以供检索。4.Routing(路由)
思考RAG落地时要问的第二个问题:数据在哪里?在许多RAG演示案例中,数据通常会存在单一数据存储中,但在生产环境中通常并非如此。当数据在一组不同的数据存储中运行时,就需要路由传入的查询。5.查询构建
思考RAG落地的第三个问题是:在考虑RAG时需要问的一个问题是,查询数据所需的语法是什么?虽然路由的问题是用自然语言提出的,但数据存储在诸如关系型数据库或图数据库等源中,这些源需要特定的语法来检索数据。即使是向量存储也利用结构化的元数据进行过滤。在所有情况下,查询中的自然语言需要转换为检索的查询语法。 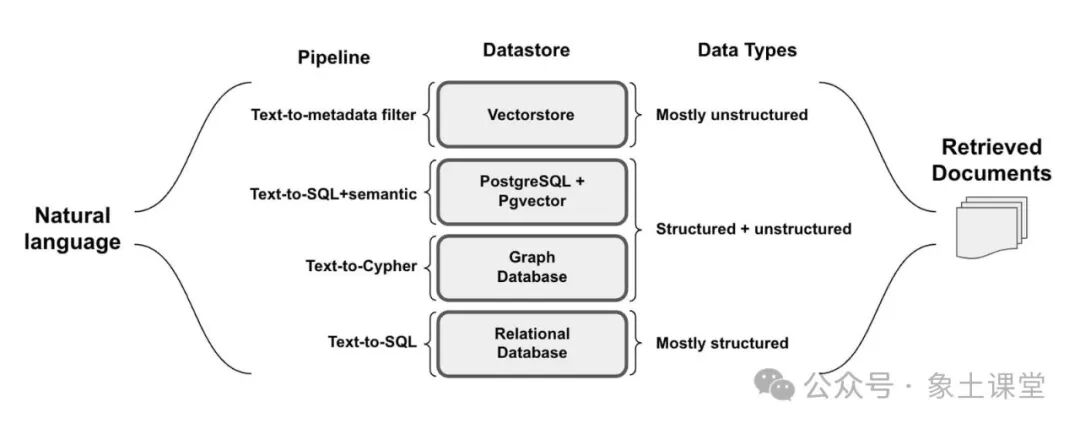
文本到SQL
相当多的工作集中在将自然语言翻译成SQL请求上。通过向LLM提供自然语言问题以及相关表格信息,可以轻松完成从文本到SQL的转换。开源LLM可以轻松完成此类任务。文本到Cypher
虽然向量存储很容易处理非结构化数据,但它们不理解向量之间的关系。虽然SQL数据库可以对关系进行建模,但模式更改可能具有破坏性且成本高昂。知识图谱可以通过对数据之间的关系进行建模和扩展关系类型来应对这些挑战。对于具有难以以表格形式表示的多对多关系或层次结构的数据,它们也是比较适合的。文本到Metadata Filter
配备Metadata Filter的向量存储使结构化查询能够过滤嵌入式非结构化文档。self-query retriever可以使用向量存储中元数据字段的规范,使用元数据过滤器将自然语言转换为这些结构化查询。
6.索引
思考RAG落地时要问的第四个问题:如何设计我的索引? 对于向量存储有相当多的机会调整块大小和/或文档嵌入策略等参数,以支持可变数据类型。块大小在OpenAI的RAG策略中仅仅通过在文档嵌入期间尝试块大小就看到了性能的显著提升。这是有道理的,因为块大小控制我们向上下文窗口(或LLM操作系统类比中的“RAM”)加载多少信息。由于这是索引构建的核心步骤,推荐开源的Streamlit应用程序。文档嵌入策略
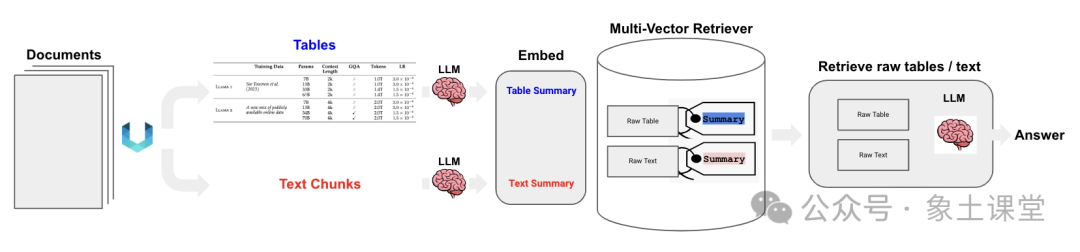
索引设计中最简单和最有用的想法之一是将您嵌入的内容(用于检索)与您传递给LLM的内容(用于答案合成)解耦。例如,考虑大量带有冗余细节的文本。我们可以嵌入一些不同的表示方式来改善检索。多向量检索
也适用于包含文本和表格混合的半结构化文档。在这些情况下,可以提取每个表,生成适合检索的表摘要,但将原始表返回到LLM进行答案合成。
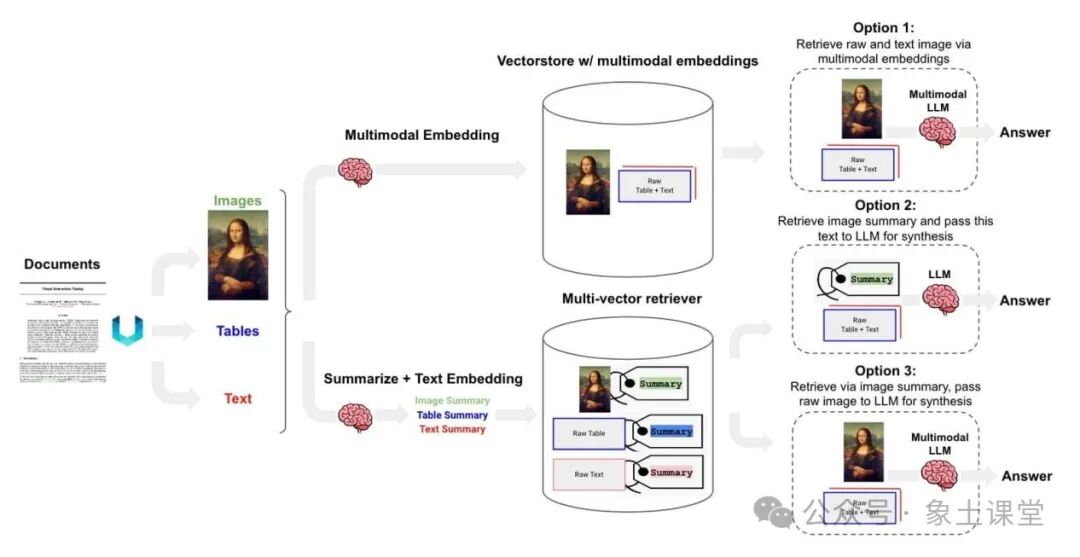
7.Post-Processing(后处理)
考虑RAG落地时要问的最后一个问题是:如何合并我检索到的文件?这很重要,因为Content Windows的大小有限。重新排名
在我们检索大量文档的情况下,Cohere ReRank endpoint可用于文档压缩(减少冗余)。与之相关,RAG-fusion从检索器返回的ReRank文档(类似于多查询)。
分类
OpenAI根据每个检索到的文档的内容进行分类,然后根据该分类选择不同的提示。这种基于标签的文本标记,用于逻辑路由(在这种情况下,用于提示)进行分类。最后我们来探讨一下RAG与LLM微调的对比,究竟什么时候用RAG什么时候采用LLM微调的方式。
二、与LLM微调(fine-tune)对比


RAG和微调为使大模型具有实时性并减少幻觉等问题行为提供了互补的优势和劣势。微调有助于使大模型专注于特定领域、词汇或新颖数据,但需要时间和计算资源,存在灾难性遗忘的风险,并且无法解决互联网快速演变的特性。RAG利用外部知识以增加事实和时效性,但仍然面临有关最佳检索的挑战。
两种方法都不能完全解决LM的所有缺陷,但都有助于解决一些即时的问题。随着LLMs不断渗透到我们的数字体验中,我们可以预期进一步尝试将微调、RAG和其他信息检索技术结合起来,为LLMs提供更及时、真实的知识。目前meta的技术人员就开发了一个模型RA-DIT, 知识密集型的零和少量次学习基准范围内实现了最先进的性能。

































 粤ICP备17114055号
粤ICP备17114055号