
导读 本文将介绍 LLMOps 大模型。
1. LLMOps 的定义
2. LLM 微调技术
3. LLM 应用构建架构
4. LLM 应用构建难点
5. LLM 应用解决方案
分享嘉宾|邹晓东 上海深擎信息科技有限公司 架构leader
编辑整理|陈业利
内容校对|李瑶
出品社区|DataFun
LLMOps 的定义
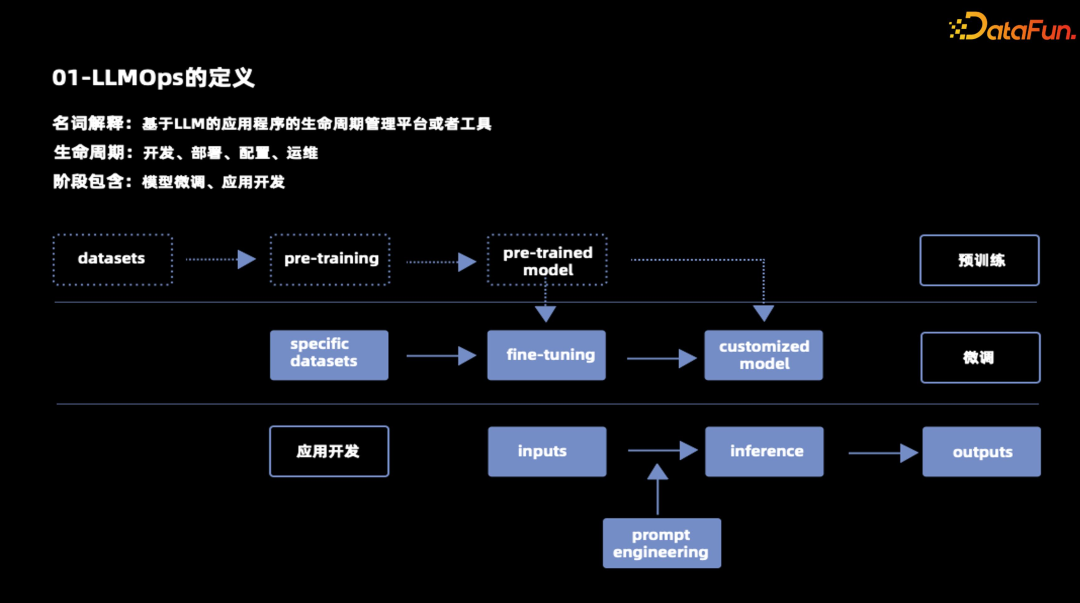
LLMOps 的概念可以分解为 LLM 和 Ops 两部分,其中 LLM 是指大语言模型,即大模型;Ops 则是指平台和工具。LLMOps 的完整定义是基于大模型的应用程序的生命周期管理平台或者工具。
- 在预训练阶段,数据集通过预训练产生预训练模型,这个过程是千模大战的主战场,各类开源闭源的大模型都是通过这个阶段产生的。
- 微调阶段是指特定领域的数据集,在预训练模型的基础上,通过 finetune 手段产生特定领域的模型。
- 应用开发阶段只是在预训练模型和特定领域模型的推理功能基础上,为其喂入我们的输入,经过提示工程进行指令编排,最终产生我们所需要的大模型输出。
大模型应用平台主要关注的是模型微调和应用开发阶段。
大模型应用的生命周期包括开发、部署、配置和运维。我们着重提出了配置的阶段,即 prompt engine 提示工程。与传统的应用程序不同,配置阶段在大模型里面是非常重要非常核心的阶段。
02
LLM 微调技术
接下来介绍大模型微调技术。在 Bert 出现之后,模型微调技术广泛流行,即固定预训练模型权重,根据具体任务在特定场景进行微调。

如上图右侧展示了各类开源大模型在特定领域数据进行加权设计之后,通过增量微调技术,产生的特定领域模型的过程。这个过程是循环迭代,循环增强的。不停地对各个领域的数据进行清洗补充之后,提升特定领域模型的效果,产生更强的模型。
目前使用的微调技术通常被称作 PEFT,参数高效微调技术。这个技术在尽可能减少所需的参数和计算资源的情况下,实现对预训练语言模型的有效微调,解决了传统微调技术需要大量资源的问题。
1. 基座大模型概述
在介绍具体的微调技术之前,先对基座大模型进行简单的介绍。
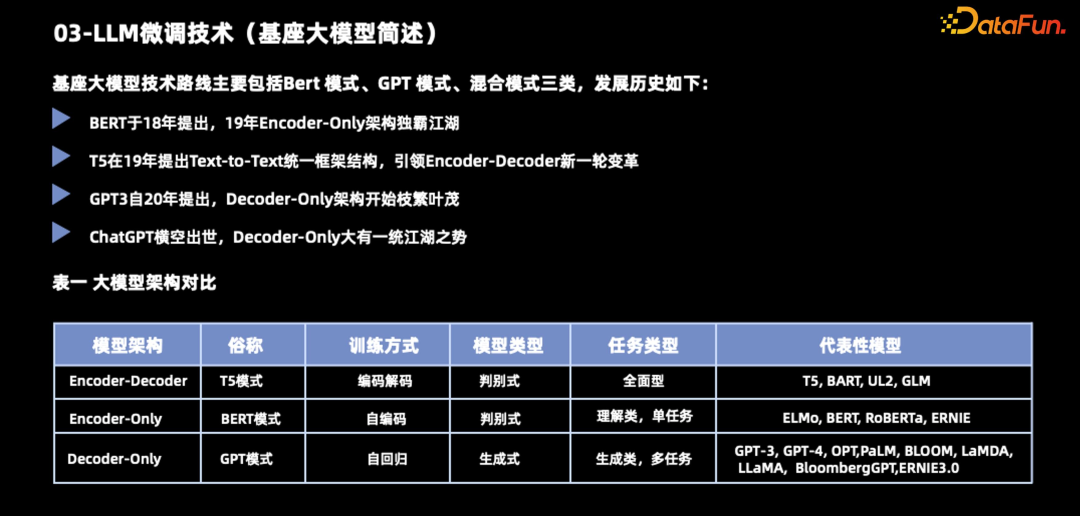
追溯其发展历史,在 BERT
于 18
年提出之时,大模型真正开始了流行,那个时候流行的都是与 BERT
相似的 Encoder-Only
的架构,在 19
年基本上是独霸江湖。后来,谷歌在 19 年提出了 T5
模型,这个模型主要是为了解决 Text-to-Text 的统一框架结构,取得了比较好的结果,引领了 encoder
到 decoder
的新一轮变革。在 20
年,随着 GPT3
的出现,Decoder-Only 架构已经开始慢慢变得枝繁叶茂。到 22
年的 ChatGPT
横空出世,Decoder-Only 目前看起来大有一统江湖之势。
- 第一种 Encoder-Decoder,又称为 T5 模式。它的训练包括编码和减码阶段,主要的模型类型是判别式,任务的类型是全面型。它主要的代表模型是 T5,BART 以及 GLM 等等。
- 第二种 Encoder-Only,这是 BERT
模式。这种模式的模型主要类型是判别式的,任务的类型是理解任务以及单任务模式,它的主要代表是 BERT
以及文心的早期版本。
- 第三种 Decoder-Only,也就是 GPT
模式。它采用的训练方式是自回归模型类的生成式模型,任务类型是生成类以及多任务,现在常见的 GPT 系列以及 Palm、LaMDA、Bloom 等都是采用这种方式,包括文心 3.0 也更改为这种模式。
2. PEFT

回到大模型的微调技术上,目前主要的微调技术包括以下几种:
Adapter Tuning 的方式就是新增 adapter 的层嵌入 Transformer 的结构里面,在训练时固定住原来的预训练模型参数不变,只对新增的层进行微调。其优点是在只额外增加 3.6% 的参数规模下就相当于做了一次完整的 finetune。
这是前缀的策略模式,在输入的 token 之前先构造一段任务相关的虚拟 token 作为前缀,然后在训练的时候只更新前缀部分,在 transformer 里面,其他部分是固定的,相比原来的 finetune,对于不同的任务只需要不同的 prefix 就可以保证不同的训练效果。
这是前缀 Prefix Tuning 的一个简化版本,只要在输入层加入 prompt tokens,并不需要加入 MLP 进行调整来解决比较难训练的问题。在这种情况下,很多时候只需要调整最上面的一层。这是现在常用的一种方式,只需要训练模型足够强大,Prompt Tuning 的结果会越来越接近于 Fine-Tuning。
P-Tuning 与 Prompt Tuning 的区别在于它将 prompt 层换成了 embedding,embedding 在实际上表应能力更强,它的优点就是微调参数只有 0.65%,比之前的微调技术参数更少。
LoRA 是在整体的微调中在涉及矩阵相乘的模块引入 a、b 两个低秩矩阵去模拟 Full-finetune,也就是全微调的逻辑。这样做的好处在于它跟之前的所有推理方式都是正交的,在推理阶段不会引入额外的计算量。
03
LLM 应用构建架构
了解了当前主要的微调技术,接下来介绍 LLMOps 的核心部分,即大模型应用构建架构。
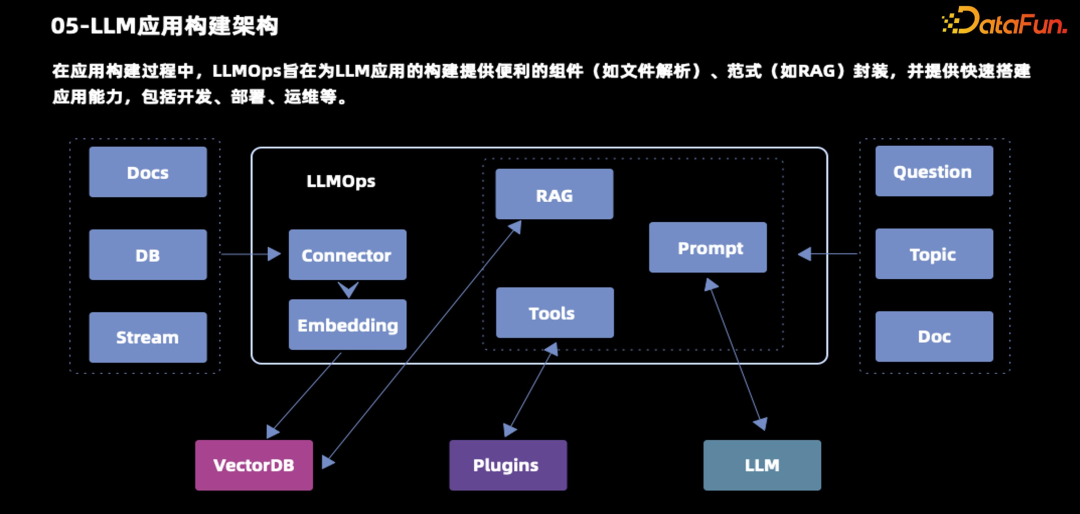
大模型平台需要为大模型应用的构建提供便利的组件,以及具体的范式,提供快速搭建应用的能力,包括开发、部署、运维等。
在了解大模型应用如何构建之前,首先需要知道大模型的四个缺点:- 第一个缺点,大模型是静态的,大模型训练成本比较高,它的所有数据可能终止在某个时间点,在这之后的数据没办法实时更新。
- 第二个缺点,大模型对于特定领域的数据,特别是私有数据是没法获取到的。
- 第三个缺点,大模型的成本问题,公司或者个人开发者没法实现微调过程。在大部分情况下还是会使用云端的大模型。
- 最后一个缺点,大模型是一个黑盒,在很多情况下我们没法知道大模型回答的东西到底是它掌握的知识还是胡编乱造的,它没有一个准确或者保真的逻辑在里面。
基于此,大模型应用的主要构建逻辑就是对大模型原生能力的体现,使用问题 question、主题 topic 或者文档 Doc,根据 prompt 与大模型交互产生需要的内容。这里包括问答、改写、文档生成,以及知识推理,都可以使用大模型原生的能力。但大模型无法自动获取新的能力,也没办法知道私有化的数据。我们需要引入一个范式(RAG 检索增强),检索增强的生成是基于本地的知识库。为了增强它的语言理解,通常会使用如向量数据库的方式来构建。在数据准备阶段,需要引入以下组件:- Connector,即数据准备。将文档数据、数据库的数据、数据流的数据等通过embedding 向量的方式存到向量数据库里面,供 RAG 调用。在大模型问答的过程中,Prompt 可以通过 RAG 去检索最相近的一些文档、知识,供大模型引用进行问答。这样来保证知识的有效、准确、真实。
- 在有效准确真实的基础之上,需要扩展一些能力,比如本地的一些 API、数据库、或者现实世界更多的知识,供给大模型调用。可以把 API 调用或者大模型外部工具的使用,作为一个插件。在与大模型交互之前先通过工具去获取一些信息,再与大模型进行交互,达到增强的结果。这能极大地提升应用的交互能力。
04
LLM应用构建难点
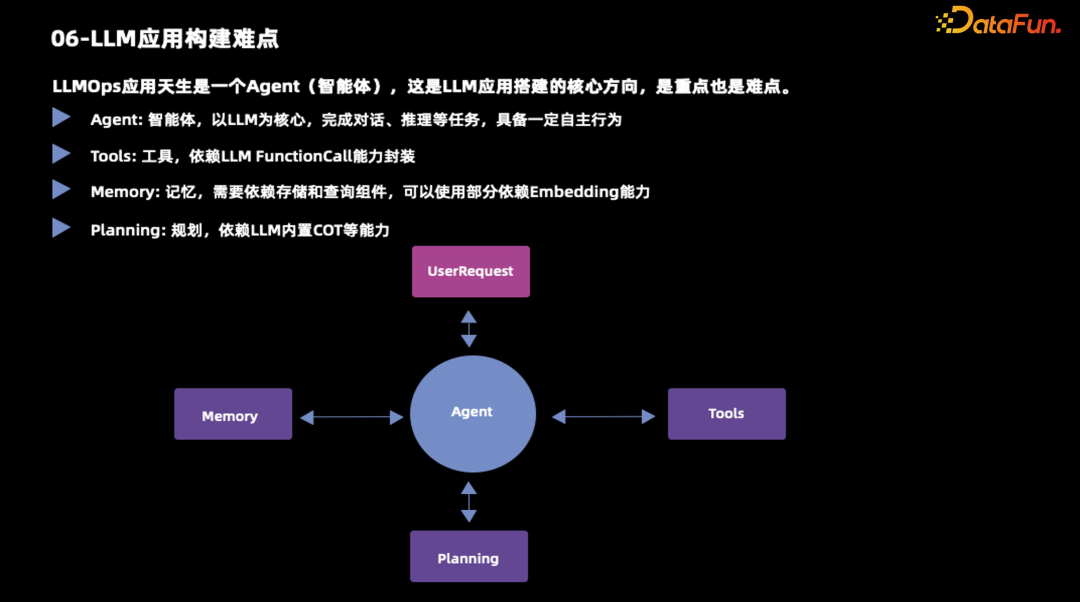
大模型的应用天生是 Agent 的,也就是智能体,这是大模型应用搭建的核心方向,这既是重点也是难点。对于智能体来说,大模型的核心是完成对话和推理的任务,它具备一定的自主行为,需要以下的几个核心部件:- 工具,即 Tools,依赖大模型的 FunctionCall 能力。
- 记忆,里面包括短期记忆和长期记忆。短期记忆是指大模型的上下文,需要大模型具备多轮对话能力。长期记忆就需要像数据库那样去存储交互的一些细节。实际上知识库也可以认为是记忆的一种。其实人类的学习过程就是存储记忆的一个过程。
- Planning,规划能力,指依赖大模型的内置 COT,即思维链的能力。
1. 常见 Agent
技术

前文中提到了 agent,agent
主要包含以下几种类型:
第一种是自主式智能体。自主式智能体是指根据指令或者引导自动完成任务,达成目标结果,明确工具属性的一个智能体。目前主要的项目如:- Auto-GPT:是大模型思维链自主实现任务目标的项目。
- BabyAGI:基于前序任务结果和目标来创建新任务。
- GPT-Engineer:是根据向 AI
提供一些动人的解释或者指导来完成完整的代码库。
第二种是生存式智能体,这种智能体是模拟人类具备记忆和自主决策能力。但不是以服务人类为目标,而是以模仿为目标,这里面的优秀项目如:- GPTeam:内置了很多智能体,每个智能体都有独立的记忆,能够相互地交流进行协作。
- GBT
Researcher:根据定制化的需求,生成详细客观不带偏见的研究报告。
- MetaGPT:多个智能的不同角色协作来完成一个复杂任务。
2. 技术难点

Agent 在真正的落地过程中会碰到如下 5 个难点:- 可靠性。大模型的幻觉是非常难克服的一个问题,经常在 planting 阶段或者 thought 阶段提出一些不真实或者环境无法满足的操作或者推论,导致应用难以执行。
- 稳定性。大模型是非常随机性的,会使用户在多次结果中得到截然不同的结论。生成式智能体在最初可能颇具吸引力,但在完成具体任务时又可能难以接受。
- 准确性。大模型存在知识欠缺,我们需要给他一些参考的知识,基于参考知识来回答。受限于当前的搜索技术,在应用构建中,很难保证获得到的知识或者记忆是最相关的。特别是在 RAG 系统里面,体现得尤为明显。
- 完整性。现在大模型的 token 通常比较受限,如 4096 或者现在推的比较多的是 6K,但也达不到一个文档的完整长度。在这种情况下,我们不可能将一个完整的文档或者任务作为上下文投喂给大模型,这会导致一些任务比如法规读取或者coding 难以取得很好的体验。
- 成本。智能体在实际的应用过程中,特别是比较复杂的一些诸如使用思维链、思维树或者 React 这种大模型交互的智能体,需要与大模型进行反复的交互。即使是一个极小的任务,也会产生比较高的成本。
05
LLM 应用解决方案

针对可靠性、稳定性问题。我们有称为 Prompt IDE 的解决方案,它的核心逻辑是为我们的提示词建立一个稳定可靠的解决方案。Prompt IDE 中文名可以称为提示词工作区,主要目的是为了保证与大模型交互的提示词,最终能够生成一个稳定可靠的版本,其核心能力包括:参数化模板的作用主要是为了扩展或者批量量产数据,它需要支持参数化模板,能够自由配置替换参数,提升 Prompt 场景的应用效率。如上图中的示例,其中有一些参数,比如职位、知识领域、新闻风格和目标人群,可以产生比如 100 条的评测数据,会列出每个职位或者资质领域,再整体评估这个参数化模板的功能或者效果。
不同大模型针对于指令或者具体的一些参数会有不一样的响应结果。我们通常调试就是在 prompt 里面加一些指令性的设置,或者在最后的参数随机性上做一些调试,这需要我们能够灵活地在不同模型下快速获得相应的结果来保证写 Prompt 的效率。
大模型的调优并不是线性的,也不是全能的。我们在不同版本的调优过程中可能会发现 a 版本对于 a 任务表现比较好,b 版本是在 a 版本的基础上进行改良,针对于 a 任务确实效果更好,但是对于 b 任务来说,效果可能反而降低了。在这种情况下,需要对于不同场景产生不同版本来进行沉淀。
由于 Prompt 的不稳定,不能根据一条数据就判定 Prompt 的好坏,而是需要 100 条或者 200 条等的批量数据发起批量调用,根据结果做标注。根据优质结果的占比,来更科学地评价 Prompt。

一键部署主要是指大模型应用平台能够让用户快速构建应用上线,并且能够在线调优实时部署整个 SOP 过程中获得比较好的体验,这就需要具备以下核心功能:- 低代码构建,很多组件都需要快速沉淀下来,使用户能够在这些组件的基础上快速搭建出一个场景;
- 场景的模板化,我们搭建的场景要能够尽可能地复用,因为大模型很多流程都是比较固定的,在提供了丰富的模板之后,能够快速孵化出一个新的场景;
- 配置的在线化,即 Prompt 工程。能够进行快速地替换、调节,让线上的一些效果快速地更改、调试、发布。
针对线上的效果,我们需要做到效果的监控和成本的监控,包括:
针对知识问答的点击场景,也是比较核心的场景,它依赖于召回结果的准确性,因此需要对知识库的命中率和相关性进行监控,为效果提供保证。
敏感词调用,这是针对于大模型的监管问题。大模型通常会命中一些敏感词,导致输出结果异常。这通常是输入的问题,由于 RAG 的影响,输入其实大部分来自于知识库。因此知识库或者问题产生敏感词会极大地影响用户体验,产生不可预知的行为。这种情况下,如何评估知识库的好坏就尤为重要。可以采用对敏感调用率进行监控,来保证场景下是以极低风险在运行,而不是经常命中敏感词,导致应用不可用。
成本的考虑,需要对 token 消耗进行监控。特别在改写或者 agent 的场景,在大模型进行多次交互过程中,消耗的 token 数量是非常可观的。企业需要直观地获取每个场景 token 消耗速度,来保证核心成本不被浪费。
邹晓东,硕士毕业于中国科学院光电研究院,现任深擎科技架构团队负责人。目前主要负责深擎 MLOps 机器学习平台和 LLMOps 大模型应用平台的设计研发工作。


































 粤ICP备17114055号
粤ICP备17114055号