导读 最近,大型语言模型(LLMs)已经成为数据科学社区和新闻界的热门话题。自 2017 年 Transformer 架构问世以来,我们看到这些语言模型处理的自然语言任务复杂程度呈指数级增长。这些任务包括分类、意图和情感抽取,甚至它们被要求生成与人类自然语言相似的文本内容。大语言模型是否能够承接推荐任务,它是如何辅助推荐系统工作的?大语言模型对于特定推荐任务的模型表现如何?针对上述问题,本文将分享一些探索性实验的结果。另外,此工作相关论文及代码可通过下方链接获取:
PDF: https://arxiv.org/pdf/2305.02182.pdf
Github: https://github.com/rainym00d/LLM4RS
1. LLMs for Recommendtion
2. Experimental Results
3. Discussion
分享嘉宾|徐君 中国人民大学 教授
编辑整理|乔伊
内容校对|李瑶
出品社区|DataFun
LLMs for Recommendtion
首先来介绍一下什么是Large Language Model,我们应该如何去设计实验来运用这些model。
第一个思路是,将LLM当作backbone,利用训练时的strategy,让它去适应某一个推荐任务。例如早期的BERT4Rec,在训练的时候让模型猜测,如果少了一个item,这个item应该是什么,由模型补上这个item。再比如UniSRec,利用了pre-train和fine-tune的流程。以及P5,利用了pre-train和promting的流程。
第二个思路是,把LLM当作现有推荐系统的补充。比如可以把LLM当作一个embedding生成器,让它生成更好的user、item以及context的表达,换句话说,LLM可以辅助我们更好地理解用户。当然,不仅是通过生成embedding的方式,我们也可以用LLM生成一段文字描述来用户等。然后把LLM带来的附加信息加入现有的推荐模型中去。
1.Key Tasks:Top-K Ranking of Items
假设在用户界面和使用方式不发生大的改变的情况下使用大模型来做推荐,一个重要任务就是选取Top-K的items,再将其进行排序。要完成此任务大致有以下三种方式:
- 第一种是打分的方式,Point-wise ranking。假设有5个items,可以直接询问大模型对这5个item的打分。这种方式最大程度模拟了业界推荐模型的工作方式,因为在线侧每一个item都会询问一次大模型,所以是Point-wise的方式。
- 第二种方式是Pair-wise ranking。每一次选取两个items去问大模型,哪个才是更适合用户的结果,哪个才是用户更喜欢的item,大模型会告诉我们一个答案。这样的话,如果我们有n个item,那么我们最多问 n*(n-1)/2次,就能得到n个item的排序。
- 第三种方式是List-wise ranking。这种方式对于大模型的理解是个挑战,直接询问大模型n个item的排序方式,相当于直接把大模型当成item排序结果的生成器。
2. LLMs for Recommendation: Overall Evaluation Procedure综合上述三种LLMs的使用方式,我们的实验流程如下图所示。
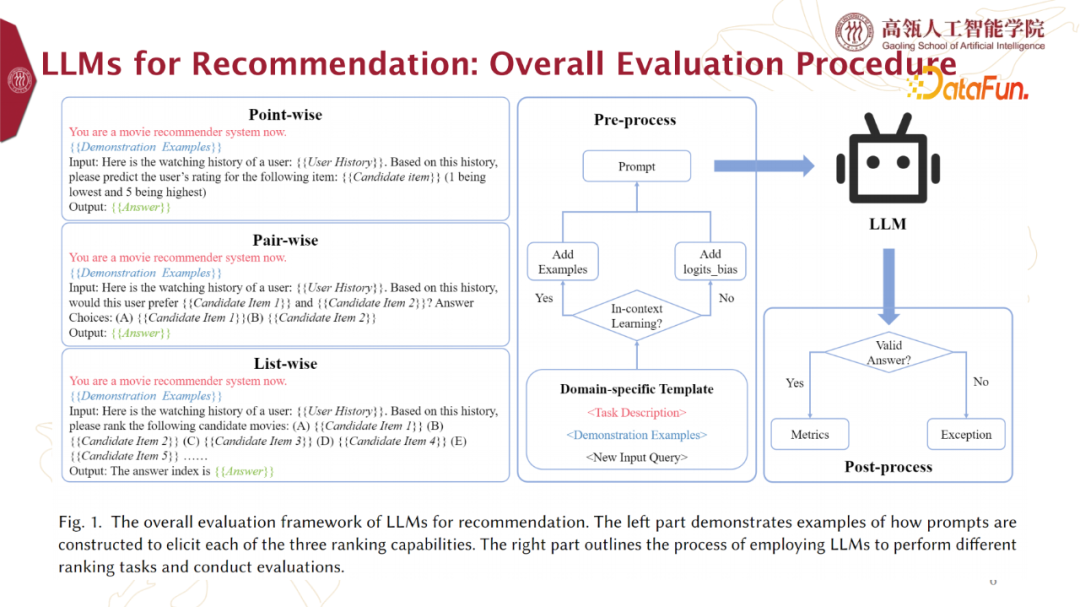
我们有一个template,它可以是point-wise的,也可以是pair-wise或是list-wise的。Prompt的构建包括三部分。第一部分是Task Description,指出是哪种推荐系统,比如电影推荐系统,相当于指定推荐的domain;第二部分是Demonstration Examples,告诉模型想让它做出什么样的动作;最后是New Input Query,是想要问的问题。通过这个template,基于是否要in-context learning,就构造出了一个prompt。将这个prompt给到LLM,LLM就会按照它的生成方式,输出一段话,我们再从这段话中提取出答案。有时这个答案可能是不符合要求的,就需要一个exception处理流程。
具体的,在构建Prompt的做法如下图所示。

下面是我们给出几种真实案例。红色部分为Task Description,蓝色文字则为Demonstration Examples,最下面的黑色文字包括组织好的New Input Query和输出的LLM的Answer。
02
Experimental Results

我们在上面四个数据集上做了测试。我们采用来自不同Domain的四个数据集以增加实验的丰富性。需要注意的是,大模型在某一些推荐任务或者某些特定的Domain上面效果是不同的,我们在后续的实验结果上也看出了显著差异。Movie数据来自MovieLens
Book和Music数据来自Amazon
News数据则来自MIND-small
电影、书籍与音乐这三个数据集具有一定相似性,例如它们都具有明确或者流行的title,而新闻类数据更多是拥有基于内容的属性,而不是title属性。在后续实验数据上面,我们看到电影、音乐和书籍的实验数据呈现相关性。
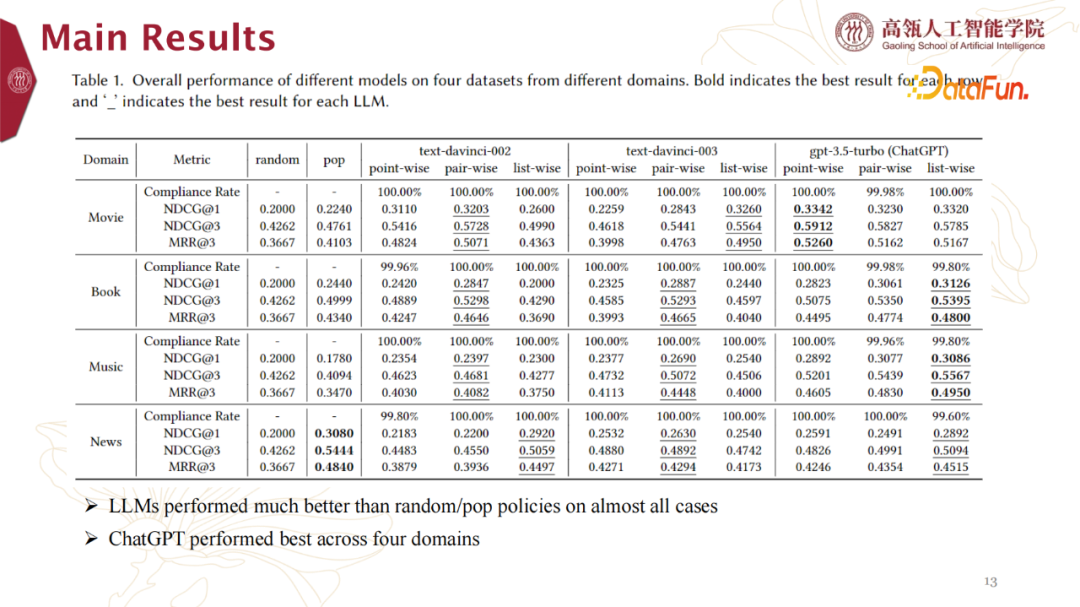
另外,Baseline我们选取的是Random(随机)、Pop(热门)、MF和NCF(传统机器学习模型)。Metric则是选择关注NDCG和MRR指标。2. Main Results
针对Baseline为Random和Pop的情况,主要实验结果数据呈现如下:
- LLMs performed much better than random/pop policies on almost all cases。LLMs相比于random/pop 规则几乎在所有实验实例上表现更好。
- ChatGPT performed best across four domains。关于各个LLMs的效果,ChatGPT针对4个Domain表现最佳。
此外,我们从其他维度将上述实验结果做个排序,得到实验结果如下:
text-davinci-002 and text-davinci-003 performed better with Pair-wise ranking in most cases。针对Pair-wise ranking的方式,text-davinci-002 与text-davinci-003表现更好。
ChatGPT is better with List-wise ranking except on movie。针对List-wise ranking的方式,ChatGPT表现更佳,当然在movie数据集是个例外。
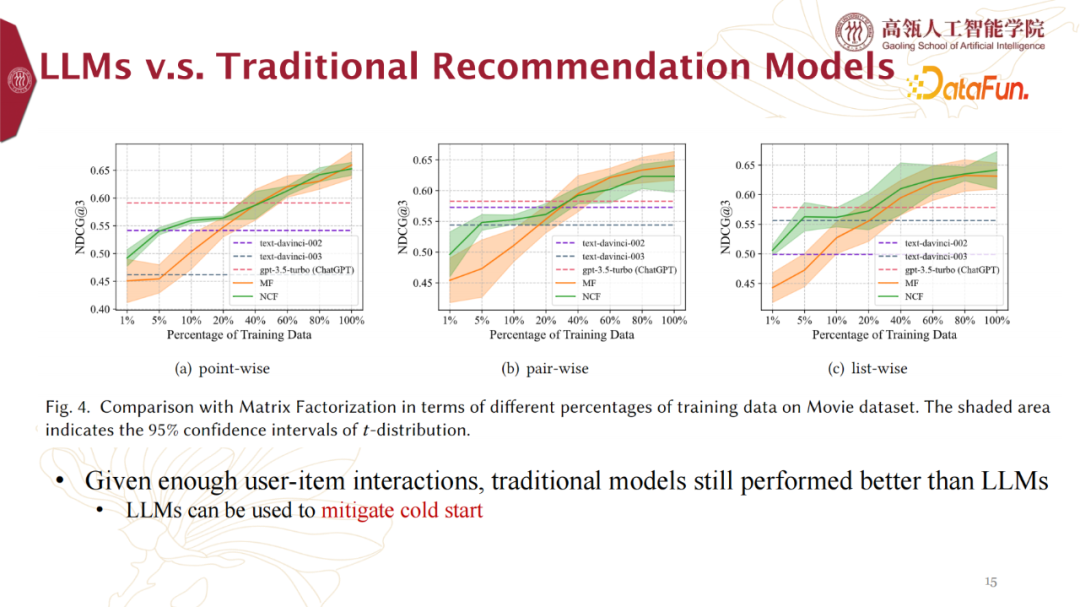
3. LLMs v.s. Traditional Recommendation Models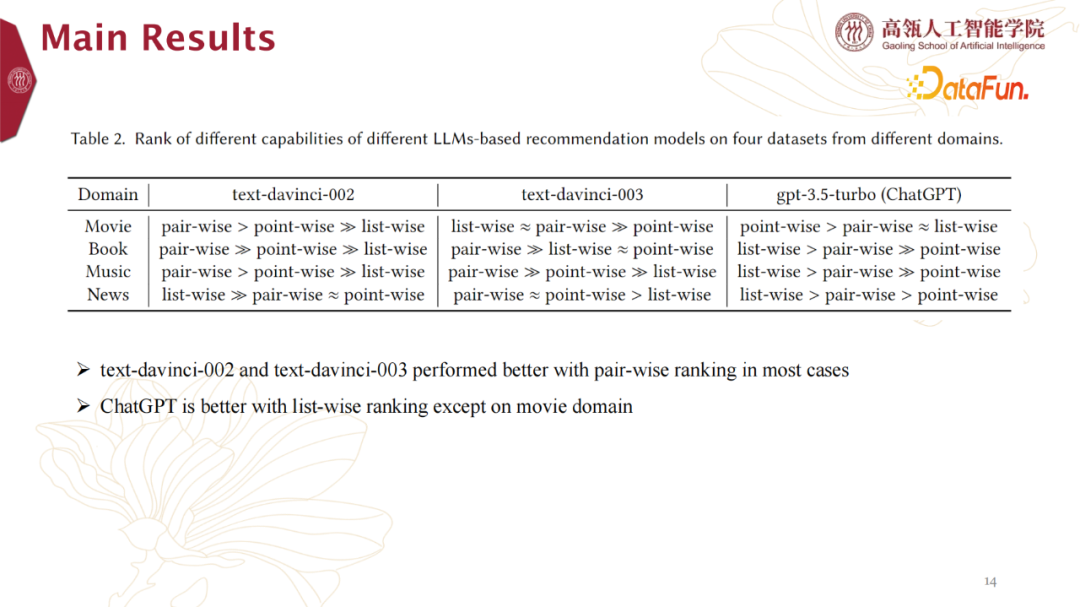
针对Baseline为传统推荐模型,实验结果数据如下:Given enough user-item interactions, traditional models still performed better than LLMs。在给足训练数据的情况下,传统推荐模型表现比LLMs更佳。
LLMs can be used to mitigate cold start。针对上述情况,LLMs具有更广阔的世界知识,则更适合冷启动任务。
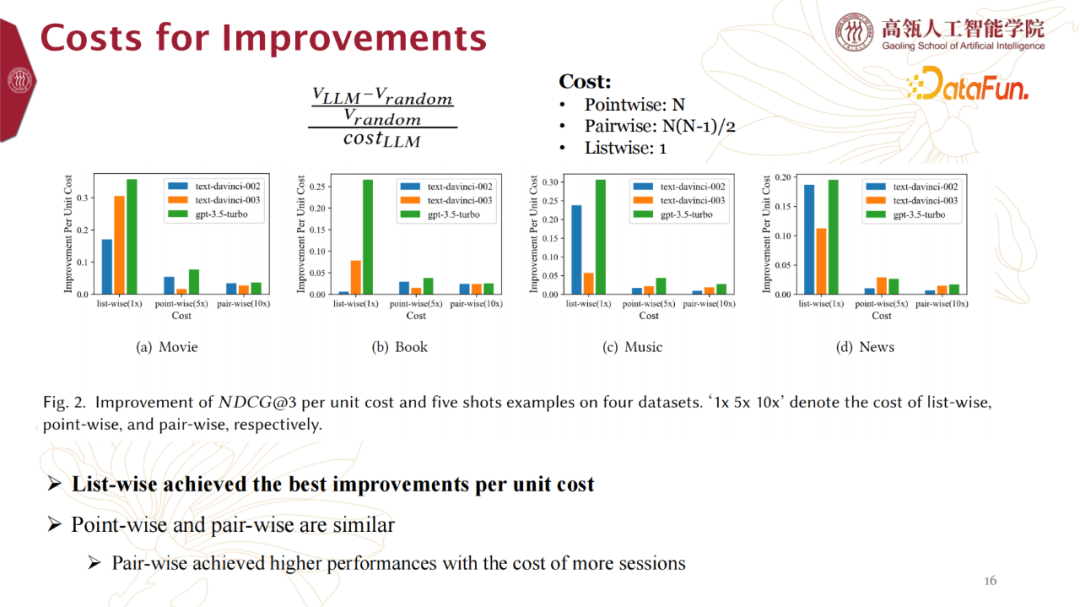
4. Costs for Improvements
另外我们不能忽视的一点是,Point-wise、Pair-wise和Listw-ise这三种大语言做推荐的使用方式带来的成本开销是不同的。
- List-wise achieved the best improvements per unit cost。List-wise 的方式在单位成本上提升最明显。
- Point-wise and Pair-wise are similar. Pair-wise achieved higher performances with the cost of more sessions。Point-wise 和Pair-wise是类似的,Pair-wise会带来更好的表现,但是是在增加更多的session成本的基础上。这一点,在具体应用中也是重点考察项目。
5. Zero-shot v.s. Few-shot
Zero-shot比random和pop方式表现更佳,也从侧面印证了LLMs可能更适合冷启任务。Few-shot比Zero-shot在大多数case上表现好很多。
6. Analysis: Number of Prompt Shots
我们进一步对prompt的次数进行了实验。我们发现更多的prompt不代表更好的模型效果。推测,更多的prompt带来更多的context information,同时也带来了更多的noise,导致影响效果。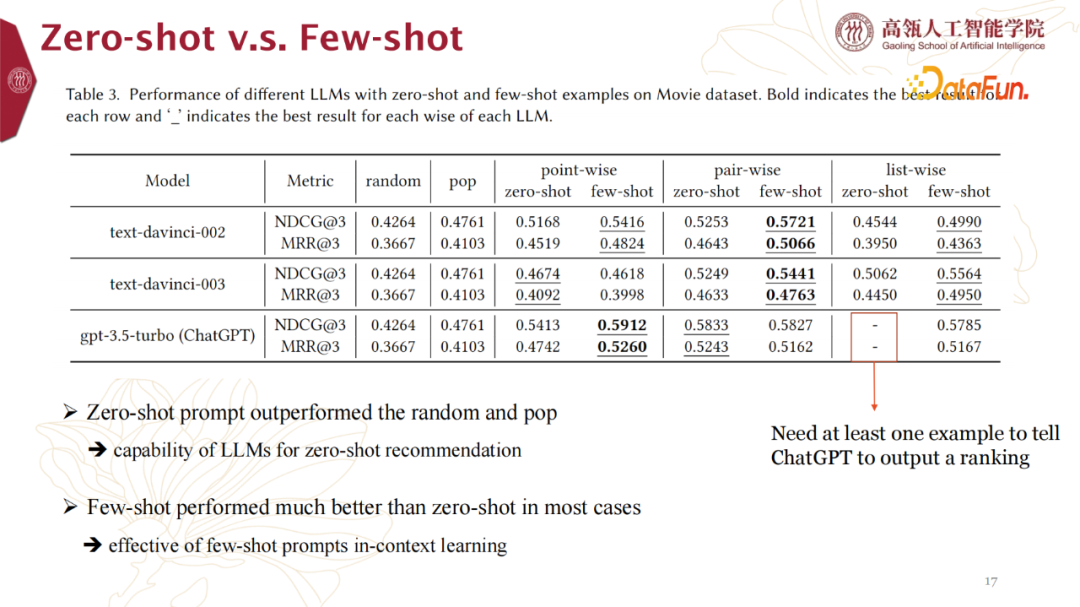
More examples -> more context information, but higher noise 7. Analysis: Number of History Items
我们在向大模型提问的时候,会提前描述一些,例如用户历史喜欢编号1、3、5等。所以适量输入用户历史行为也是我们调查调整的参数之一。我们发现,更多的历史例子不代表提问效果更好。推测同上,更多的history items带来更多的context information,同时也带来了更多的noise,从而影响效果。如何安排LLMs获取到用户历史行为,也是重点实验方向。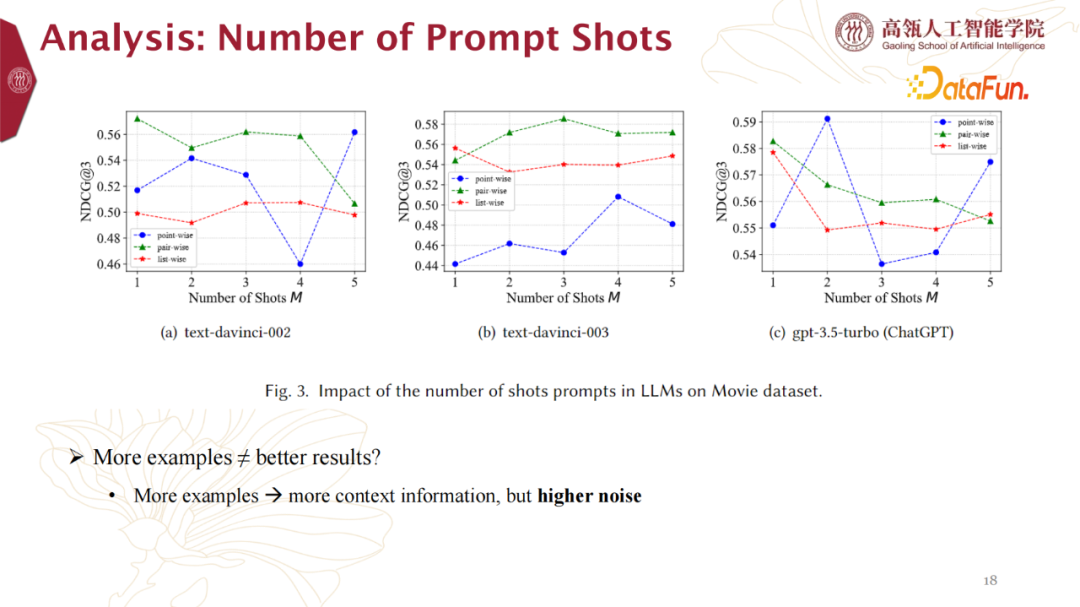
Given more historical interacted items ≠ better results?
More items -> more context information, but higher noise
Open question: how to retrieval historical items for recommendation
8. Case Study
(1) Ranking with Explanations

图中黑色部分是我们的描述和提问,绿色部分是模型的回答。回答给出了排序结果,并详细说明了原因。这个回答满足了我们的需求,很好地解决了我们的排序问题。
(2) No Ranking, with Explanations

上图实例中,模型并没有按要求给出排序结果,但是对每一个item进行了说明解释。这种情况,我们需要抽取更多信息才能完成排序需求。
(3) Reject to Answer

这个实例中,模型拒绝回答。针对这种情况需要系统进行相应处理,例如重新提问等。
(4) Incorrect Ranking with Explanations

上图实例中,模型并没有按要求给出排序结果,但是对每一个item进行了说明解释。这种情况,我们需要抽取更多信息才能完成排序需求。
(5) Reject to Answer
这个实例中,模型拒绝回答。针对这种情况需要系统进行相应处理,例如重新提问等。(6) Incorrect Ranking with Explanations
上图中模型给出了错误的答案。我们发现,模型很倾向于按照已有的item顺序给出答案。针对这一点,我们后续会进行更多的实验来尝试解决。03
Discussion
1. Summary
本文介绍了我们对于大语言模型辅助推荐系统进行工作的实验尝试。我们分别在电影、书籍、音乐与新闻等domain数据上面,验证了ChatGPT等大模型的表现,并给出了相关实验结论。另外,本文总体阐释了Point-wise、Pair-wise、List-wise三种方式来使用LLMs生成items ranking任务。需要注意,我们此次实验使用的item list长度不是很长,实验均取Top 5。当然,后续如何增加item list长度也可以研究方向之一。实验中我们发现ChatGPT表现不俗,尤其是在List-wise模式下只需要提问LLM一次,从效能方面看,是非常经济高效的。另外,将大模型与简单的传统模型来比较,如果能够给传统模型输入足够多的训练数据,它们会带来比大模型更好的效果。不过,大模型拥有更多的世界知识,它更善于解决冷启动问题。另外,因为大模型的回答不仅包括打分,还有对结果的解释,所以我们可以利用这一点进行可解释推荐。

2. Discussion
最后,我们列出了一些开放问题供大家讨论,其中一些也是我们后续的实验方向。

- LLMs是基于大规模文本数据(世界知识)的语义信息
- 传统模型是基于训练数据中的user-item交互行为(领域知识)
- 它们是互补的!?(比如网络搜索中的LM4IR和PageRank?)
n Embedding方式:user/item side info -> LLMs -> user/item text-embedding -> combine/align with ID-embedding
n LLMs as RecSys 大语言模型作为推荐系统的方式:natural language输入 & natural language 输出- New UI for recommendation 是否需要新的UI作为推荐入口
- Do we really need natural language in ? 我们是否需要自然语言输入?Finetune is the way to go虽然LLM很强大,但在具体的某一个领域的知识还是有局限的,因此我们需要通过微调将LLM向某个领域引导,从而使其在特定领域做得更好。Jun Xu is a Professor at Gaoling School of Artificial Intelligence, Renmin University of China. His research interests focus on applying machine learning to information retrieval and recommendation. He has published more than 100 papers and 2 monographs at top international journals and conferences, including TKDE, TOIS, JMLR, SIGIR, KDD, WWW ACL etc. His work on information retrieval has received the Test of Time Award Honorable mention of ACM SIGIR 2019, Best Paper Runner-up of ACM CIKM 2017, and Best Paper Award of CCIR 2022 and AIRS 2010. He has served or is serving top international conferences as Senior PC members, including SIGIR, CIKM, AAAI, and top international journal of JASIST as an editorial board member, and ACM TIST as an associate editor. He received funding grants from the National Natural Science Foundation of China (NSFC) and National Key R&D Program of China.

































 粤ICP备17114055号
粤ICP备17114055号