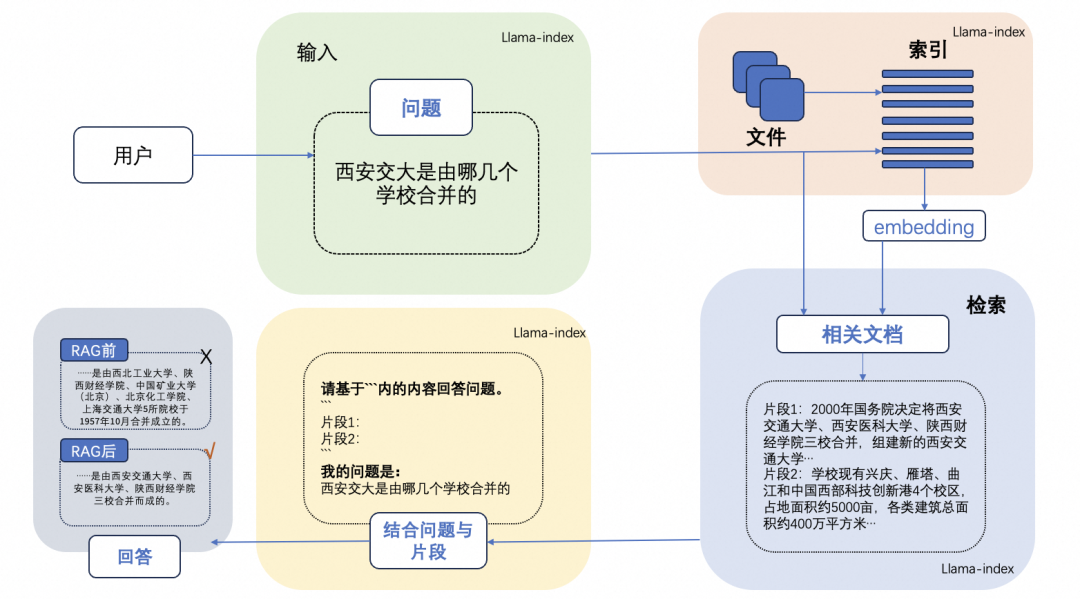
RAG 检索增强生成技术这篇《一文搞懂 RAG 检索增强生成》做了详细介绍,一个典型的 RAG 案例如下图所示,包含3个步骤:
- 索引:将文档库分割成较短的 Chunk,并通过 Embedding 编码器构建向量索引。
- 检索: 根据 Prompt 问题和 Chunks 的相似度检索相关文档片段。
- 生成 :以检索到的上下文为增强条件,最终生成 Prompt 问题的回答。
今天我们聊聊引入 Rerank 技术如何进一步增强 RAG 应用落地的效果。
—1—
Rerank + RAG 增强落地
Rerank 是一种重排序技术,通过引入 Rerank,可以在不牺牲准确性的情况下加速大模型的查询(实际上可能提高准确率),Rerank 通过从上下文中删除不相关的节点,重新排序相关节点来实现这一点,如下图所示:下面详细剖析下 Rerank + RAG 技术,有效地缓解了幻觉问题,提高了知识更新的速度,并增强了内容生成的可追溯性,使得大语言模型在实际应用中变得更加实用和可信。与 Embedding 模型不同,Rerank 使用问题和文档作为输入,直接输出相似度而不是 Embedding 向量。通过向 Rerank 模块输入查询和段落来获得相关性分数。Rerank 往往基于交叉熵损失进行优化的,因此相关性得分不受特定范围的限制。bge-reranker-v2-m3 适用于中英文双语 Rerank 场景。Rerank 的工作(如下图)就像是一个智能的筛选器,当 RAG 从文档集合中检索到多个文档时,这些文档可能与你的问题相关度各不相同。有些文档可能非常贴切,而有些则可能只是稍微相关或者甚至是不相关的。这时,Rerank 的任务就是评估这些文档的相关性,然后对它们进行重新排序。它会把那些最有可能提供准确、相关回答的文档排在前面。这样,当大模型开始生成回答时,它会优先考虑这些排名靠前的、更加相关的文档,从而提高生成回答的准确性和质量。通俗来说,Rerank 就像是在图书馆里帮你从一堆书中挑出最相关的那几本,让你在寻找答案时更加高效和精准。LlamaIndex 是一个基于大语言模型应用的数据框架,用于增强大语言模型的能力。 这种基于大语言模型的应用被称为 RAG 应用,对标微调(Fine-tuning)技术。LlamaIndex 提供了必要的抽象,可以更轻松地获取、索引、存储和访问私有或特定领域的企业级数据,以便将这些数据安全可靠地注入大语言模型中,以实现更准确的知识生成。
在做知识增强时,根据不同的任务,需要的大语言模型的能力是不同的,比如:分类任务选用 3B 参数量,翻译任务选用 7B 参数量,意图识别选用 13B 参数量,Action 函数调用(Function Calling)选用 70B 参数量。在以上实践原则下,对于闭源大模型可以考虑:OpenAI ChatGPT 系列和百度文心一言系列。对于开源大模型可以考虑:阿里 Qwen 1.5、智谱 ChatGLM3、百川3、Llama 2 以及 xAI 最新推出的参数量为 314B 的Grok 1.5和 Databricks 开源的 132B 参数量的 DBRX。
- Pytorch 1.12 及以上版本,推荐 2.0 及以上版本
- 详细配置参考这里:https://github.com/modelscope/modelscope-classroom/blob/main/LLM-tutorial/RAG%2BRerank%2BLlamaindex.ipynb

































 粤ICP备17114055号
粤ICP备17114055号