概述
1.1 背景
大语言模型(LLM)已显示出一定的规划和决策能力。利用这种能力,ReAct 将环境信息和智能体(Agent)可执行的行动提供给大语言模型,就可以利用它确定当前状态下需要执行的行动。然而,ReAct 系统通常生成单一、直接的因果推理路径,这限制了它在具有复杂因果关系的任务中的有效性。以 TOT、GOT 和 RAP 为代表的一系列推理指导范式,它们允许在每一步生成多种可能的行动,并根据多个环境反馈结果和选择策略决定下一步路径。虽然这种方法提高了 agent 处理复杂因果关系的能力,但在真实世界的场景中,在同一情况下执行多个行动往往是不现实的。所以需要一种在每轮中仅生成一种行动但能够处理多样、复杂推理的智能体框架。
处理预测与实际结果之间的差异往往有助于人们扩展思维过程和进行反思,从而促进推理朝着正确的方向发展。受科学研究的过程和任务导向对话中有关预测未来的研究成果的启发,我们提出了一个将预测、推理和行动融为一体的 agent 推理框架——PreAct。利用预测提供的信息,基于大语言模型的 agent 可以提供更多样化、更具战略导向性的推理,进而产生更有效的行动,帮助 agent 完成复杂的任务。我们在 AgentBench 中的 HH、OS、DB、LTP 等数据集上进行了大量的实验,实验表明 PreAct 在完成复杂任务方面优于 ReAct 方法,且可以与 Reflexion 结合,进一步增强 agent 的推理能力。我们用不同数量的历史预测对模型进行提示,发现历史预测对 LLM 规划有持续的正向影响。PreAct 和 ReAct 在单步推理上的差异表明,PreAct 在多样性和战略方向性方面确实比 ReAct 更有优势。

方法
2.1 前置知识
2.1.1 Agent与Enviroment
决定要采取的动作后,agent 将在环境中执行动作,并通过环境策略 获得新的观察结果。对于 LLM 代理来说,它只能控制 和 的构建。因此,LLM agent 的目标就是设计出高效的 和 。ReAct 是一项面向 LLM agent 的开创性工作,它结合了思考 、行动 和观察 。ReAct 使用 作为 和一组 作为 。利用 LLM 的规划能力,ReAct agent可以探索环境并逐步解决问题。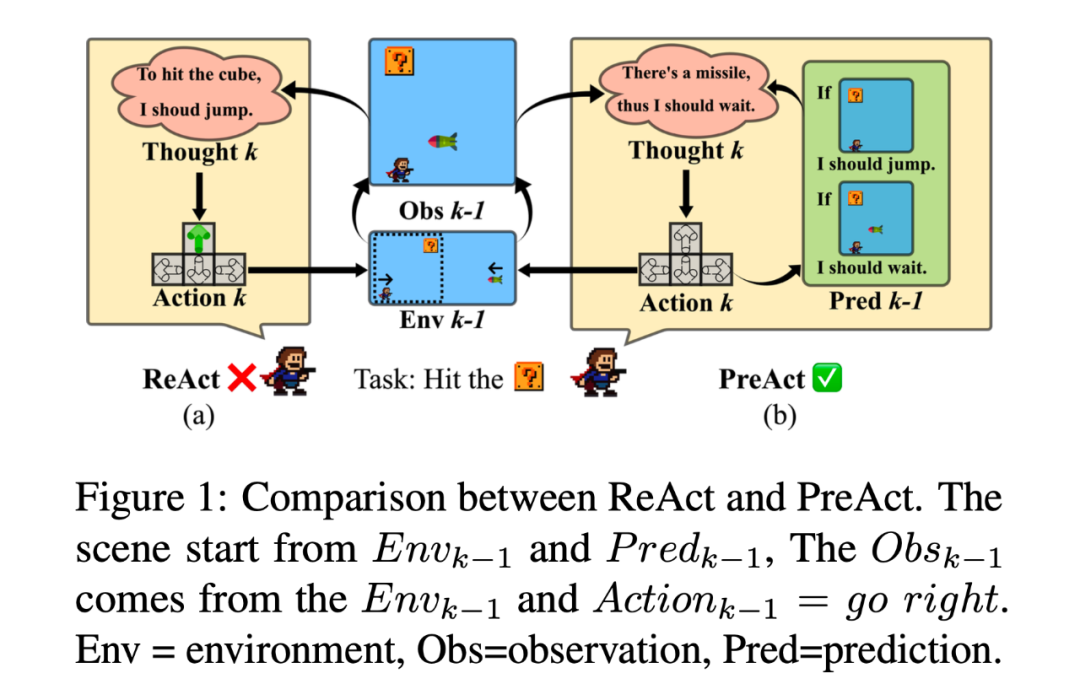
PreAct 的框架如图 1 所示。它与 ReAct 有两点不同:对于 部分,PreAct 会在每一步中要求 LLM 生成对未来观察的预测和相应的应对措施 ,并根据预测观察与实际观测之间的差异提示 LLM 反思或改变其计划方向。通过这种提示,可以提高 LLM 所做计划的多样性和策略导向性。对于 部分,PreAct 会在其中添加对未来观察的预测。虽然 PreAct 提高了 LLM 的思考和计划能力,但还有两个问题有待探究:(1)PreAct 是否能与 Reflexion 结合使用并进一步提升效果?1. 永久模式:所有预测都将保留在永久历史中,如:
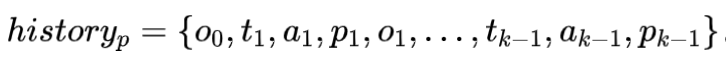
2. 即时模式: 只有最后一次预测会保留在即时历史中,如:
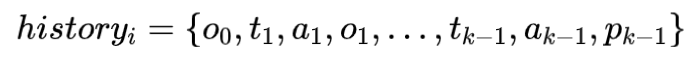
3. 反思模式:反射和所有预测都将保留在历史记录中,如:

实验
- 与 ReAct 相比,不同模式的 PreAct 在处理任务时是否表现得更好?
- PreAct 比 ReAct 能更好促进规划的内在原因是什么?
3.1 实验设置
我们在 AgentBench 中的 HH、OS、DB 和 LTP4 4 个不同的子数据集上对 PreAct 进行了评估。我们使用 GPT3.5 和 GPT4 作为 agent 的 LLM。更多的实验设置和所有提示词都能在论文附录中找到。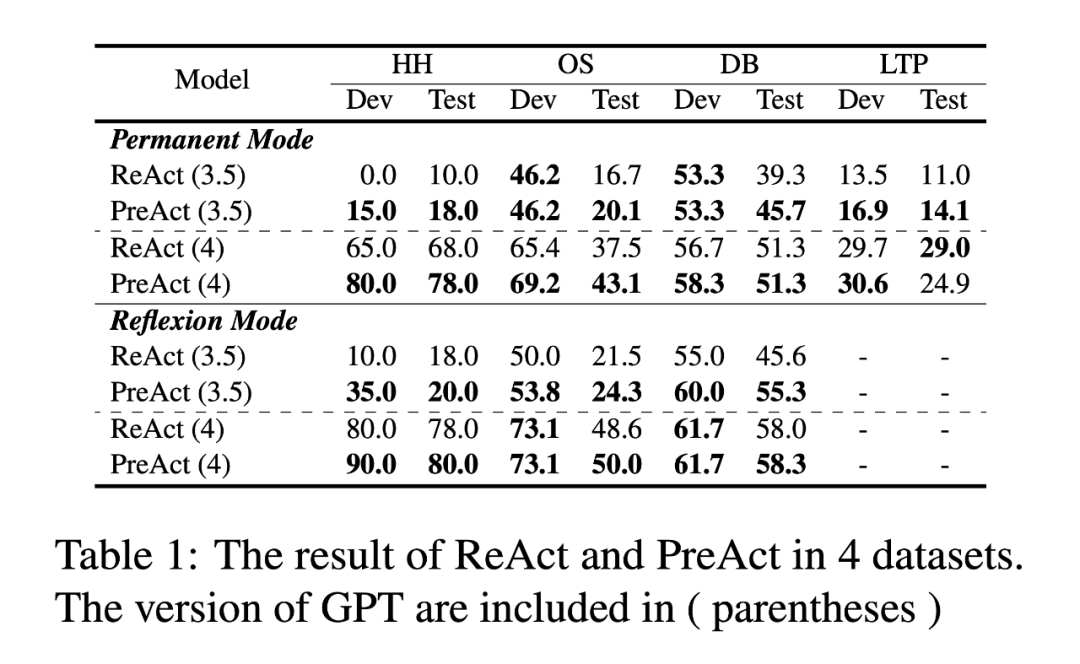
表 1 列出了 PreAct 和 ReAct 在 Permanent 和 Reflexion 两种不同设置下,在四个数据集上的性能表现。在 HH 任务中,PreAct 比 ReAct 提高了约 20%。在 OS 和 DB 任务中,在 Permanent 设置下,PreAct 的平均性能相比 ReAct 分别提高了 12% 和 6%,在 Reflexion 设置下,Preact的性能相比同样采取了 Reflexion 的 React 分别提高了 5% 和 8%。在 LTP 情景下,PreAct 的结果与仅 Act 的结果类似,这可能是由于 GPT 的安全机制导致其多次拒答,从而减少了有效的探索步骤。总的来说,在大多数情况下,PreAct 都优于 ReAct,在某些指标上甚至超过了带 Reflexion 的 React。此外,在 PreAct 的基础上应用 Reflexion 还能持续提升模型性能。这表明,先验任务信息和观察预测可以共同提高 LLM 的规划和决策能力。根据我们的假设,PreAct 可增强推理的多样性和策略方向性,从而提高 LLM 的规划能力。在本节中,我们将研究这两个促进因素。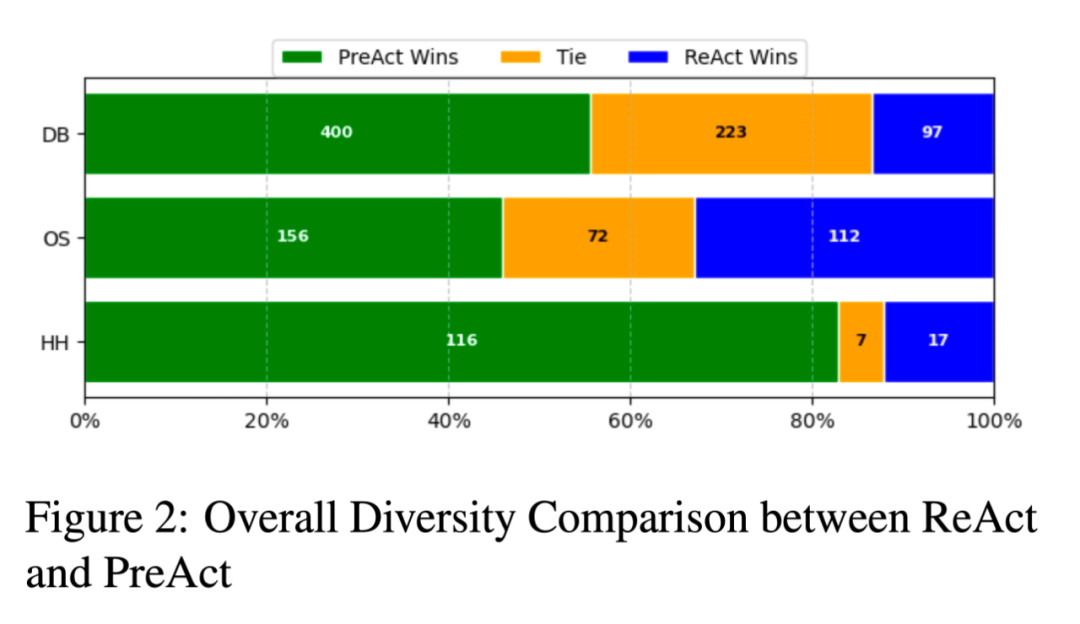
图 2 展示了 PreAct 和 ReAct 在 HH、OS 和 DB 数据集上的多样性比较。我们向 GPT-4 输入了两条包含思考和行动的轨迹,要求它在 0 到 100 的范围内对每条轨迹打分。图表显示,在任何给定的数据集上,至少有 45% 的实例显示出 PreAct 的推理多样性优于 ReAct,而相反的情况则不超过 34%。这表明,使用 PreAct 可以显著提高推理多样性,从而扩大推理空间,拓宽可能行动的范围。我们选择 Alfworld 任务来分析策略方向性。对于每条轨迹的每一轮,我们都向模型提供 ground truth、截至本轮次的所有思考和行动,同时去除所有预测。然后,我们要求 GPT-4 对其策略方向性进行评分,分数范围为-1 ∼ 3。策略方向性的评价指标如下:其中, 为样本, 为一轮思考和行动, 为评分器。如表 2 所示,PreAct 的策略方向性得分比 ReAct 高出至少 20%。这表明 PreAct 在确定规划方向方面更胜一筹。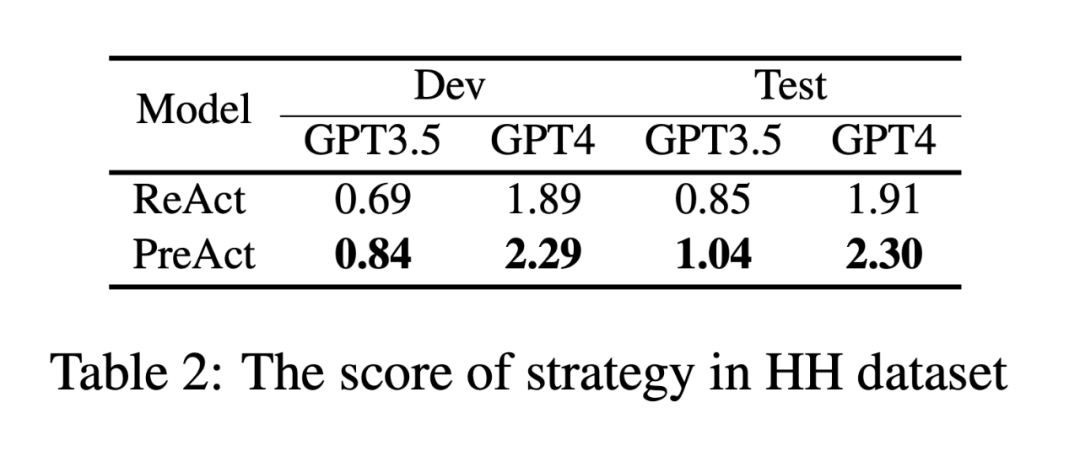
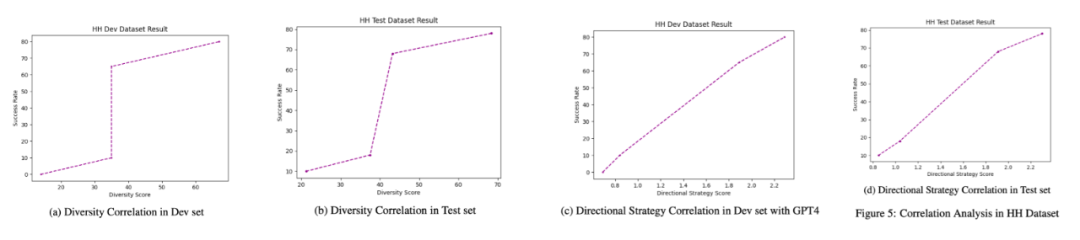
图 5 显示了在 HH 数据集上,多样性、策略方向性和成功率之间的关系,揭示了成功率与这两个指标之间的正相关关系。此外,策略方向性与成功率的相关系数分别为 99.8%(Dev)和 99.3%(Test),而多样性与成功率的相关系数分别为 83.7%(Dev)和 91.2%(Test)。
图 3 显示了 PreAct 和 ReAct 在 DB 和 HH 数据集上的部分轨迹。虽然 PreAct 和 ReAct 在这两个数据集的初始执行阶段都出现了错误,但 PreAct 可以借助预测纠正错误,而 ReAct 则不能。在 DB 数据集中,ReAct 和 PreAct 在第一轮中都使用了相同的错误列名。PreAct 通过验证实际列名纠正了这一错误,而 ReAct 则反复使用了错误的列名。Pre Act 对查询和更正列名的考虑反映了其推理的多样性。在 HH 任务中,ReAct 检查完冰箱后,与冰箱内的物体进行了互动,这与任务无关,而 PreAct 则预测到了 "冰箱内没有生菜 "的条件,并根据 Pred 3 中的预测结果,指导其在其他地方找到生菜,最终完成了任务。这种重新考量生菜的可能位置而不是继续在冰箱附近寻找的决定表明,PreAct 具有更好的策略方向性。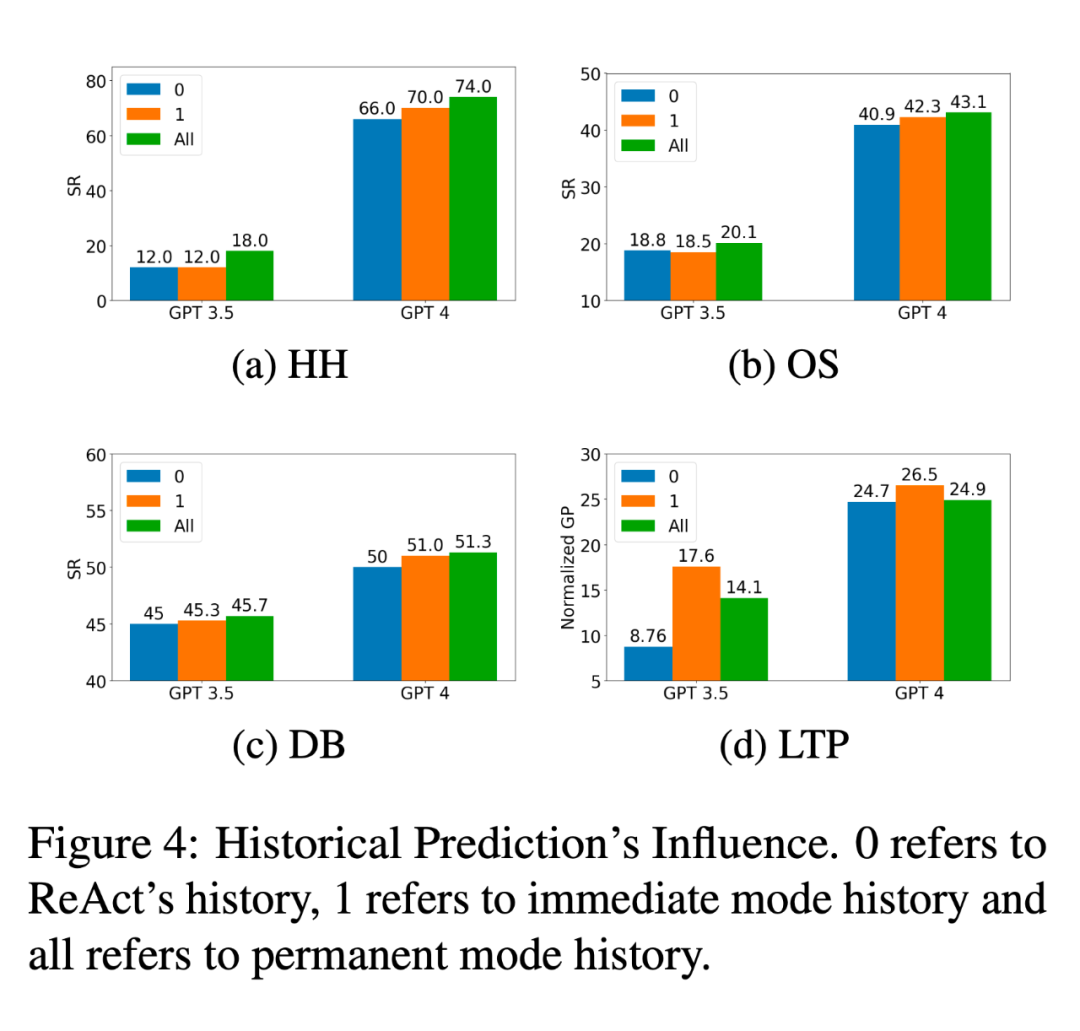
图 4 展示了不同数量的预测历史对 LLM 推理性能的影响。在 HH、OS 和 DB 数据集上进行的实验表明,增加预测历史的保留量可以提高成功率。以 PreAct(GPT4)为例,3 种设置下任务的成功率在 HH 中分别为 66%、70%、74%;在 OS 中分别为 40.9%、42.3%、43.1%;在 DB 中分别为 50%、51%、51.3%。这些发现表明,历史预测对模型的推理能力有持续的正向影响。然而,在 LTP 数据集上,更多的历史数据会导致更高的拒答概率,进而导致永久模式下的 Preact 性能下降。

结论
本文中,我们介绍了一个简单却有效的 agent 推理框架——PreAct,它利用预测来增强规划的多样性和策略方向性,从而提高 agent 完成任务的能力。这种增强是持续性的,它独立于 Reflexion,并将随着历史预测的积累而不断提高。基于 PreAct 的研究结果,我们提出了两个评估规划的指标,这可能有助于在未来的工作中为强化学习设置过程级的奖励函数,以训练出更强大的 agent。

































 粤ICP备17114055号
粤ICP备17114055号