导读 本次分享主题为生成式检索的探索和实践,将介绍当前常见的检索范式,以及发表于 EACL 的关于生成式检索的一篇论文,重点剖析记忆机制相关问题。
1. 研究团队
2. 检索范式
3. GDR:记忆机制的双刃剑效应
4. GDR:应用场景
5. 问答环节
分享嘉宾|冯少雄博士 小红书 算法工程师
编辑整理|蔡郁婕
内容校对|李瑶
出品社区|DataFun
研究团队

目前团队有四名成员,主要研究方向包括大模型评测推理及生成式检索,目前在进行技术攻关以实现大模型在搜索系统各环节的落地应用。
检索范式
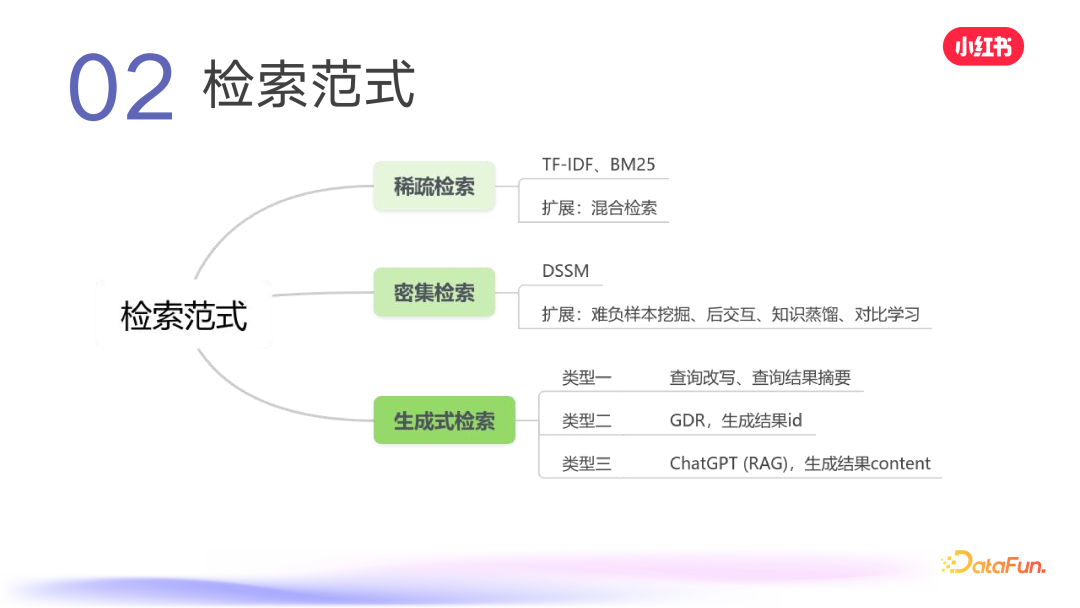
- 稀疏检索,如 TF-IDF、BM25,以及一些扩展的混合检索;
- 密集检索,常见模型有 DSSM,还有一些变体,如难负样本挖掘、后交互、知识蒸馏,以及 loss 上的一些工作(对比学习)。
- 生成式检索,常见的有三种,一种是对现有检索系统各个模块进行优化,比如在 QP 环节对查询进行改写,对最终结果进行摘要,这在商品搜索、小红书、抖音、快手等平台都能看到,即 one box 查完后上文的摘要;第二种是今天要介绍的主题 GDR,根据 query 直接生成笔记 ID 或文档 ID,要求对检索系统的召回环节进行较大改动;第三种是理想态,如 ChatGPT,直接生成结果的 context。从使用角度看,对于某一类问题,用户可能希望有直接生成的结果,但对于像小红书、抖音、快手等内容平台,用户不仅希望看到搜索结果的摘要,还希望看到其他用户在平台上关于查询内容的分享,所以这几种检索类型都有必要。
GDR:记忆机制的双刃剑效应
接下来介绍我们发表在 EACL 2024 Oral 的一个工作:

主要探索生成式检索的关键问题——记忆机制。文章中分析了记忆机制的几个问题,并与密集检索进行了重要差异对比。针对生成式检索的问题,提出了一些解决方案。
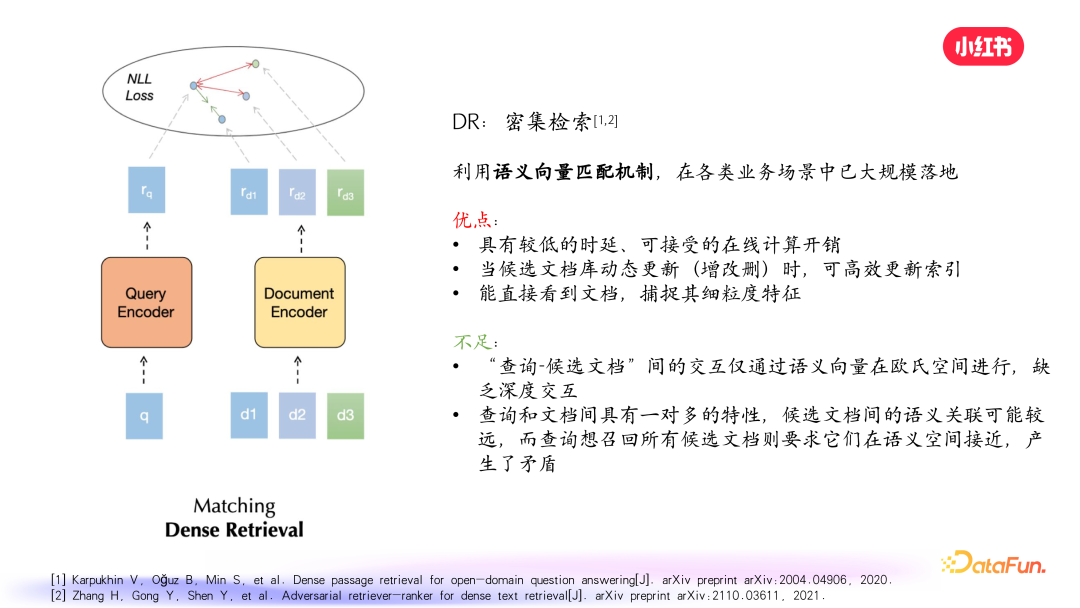
简要回顾密集检索,其本质是利用语义向量匹配机制,在各个业务场景广泛应用。其优点是具有较低的时延、可接受的在线计算开销,并且比较灵活,当文档库发生动态更新时,可以快速高效地更新索引。采用双塔模型,无论是 query 侧还是笔记侧,都可以输入丰富的信息,有助于模型捕捉细粒度特征。上图中可以看到,双塔一侧是 query 的语义向量编码,另一侧是 doc 的语义向量编码,在向量空间做距离计算,进行优化。
其不足之处是双塔模型无法进行深度交互,都是得到向量后,语义向量在欧氏空间进行计算。我们知道深交互有助于特征交叉,提升模型性能。但在检索环节,由于对计算时间和开销的要求,一般不会进行深度交互。另外一个缺点是,查询和文档之间具有一对多的特性,候选文档的语义关联可能较远,而查询想召回的所有候选文档则要求它们在语义空间接近,产生了矛盾。

再来看一下生成式检索。给定一个 query,生成式检索的编码端首先得到一个向量,然后将这个向量给到文档解码器,用 Beam Search 解码策略逐步得到每篇笔记的 ID。这意味着笔记需要通过 ID 进行表示,可以是单值或一串序列的值。预测过程是给 query 直接生成笔记 ID,而不是先得到 query 的向量,在欧氏空间和笔记向量进行计算找到最相似的向量。其本质是利用记忆机制,因为 query 进去后,笔记没有拿出向量,所以要求模型根据 query 记住相关笔记的 ID 序列。
在较小规模的候选文档场景下,生成式检索展现出了优于密集检索的召回性能。具体优点包括:模型以参数作为记忆载体,记住所有候选文档,在解码过程中隐式实现了候选文档和查询的深度交互,这是密集检索的主要缺点;另外,文档被赋予了独立的 ID,避免了密集检索存在的 one to many 情况;如果将 query 的编码器换成大语言模型,能有效利用预训练语言模型的语义理解能力。
但生成式检索也存在不足,接下来从三个方面来详细介绍。
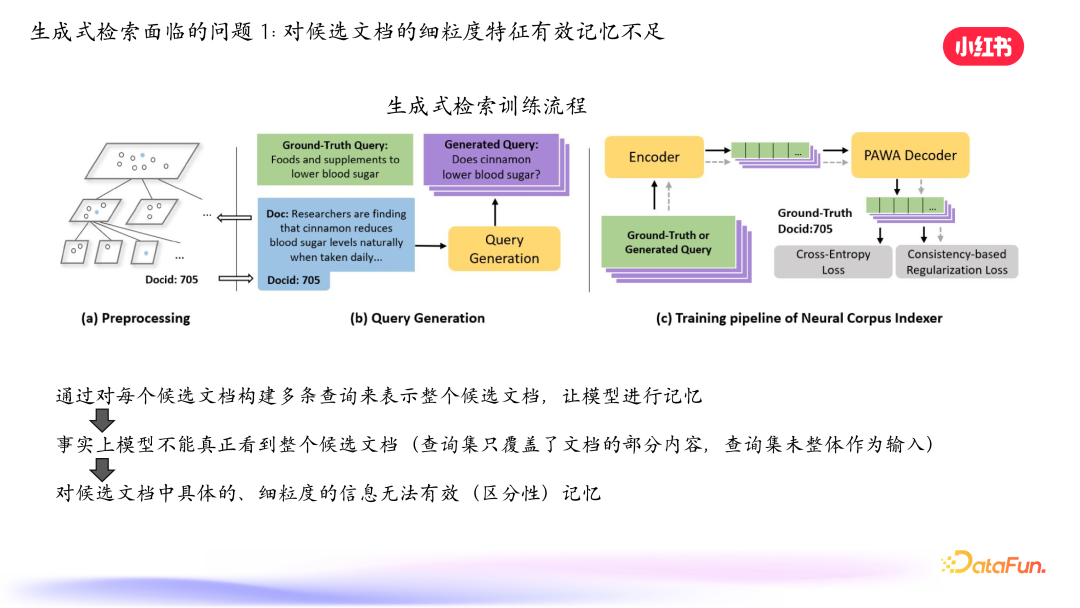
首先,对候选文档的细粒度特征有效记忆不足。生成式检索的训练流程是先对文档进行表示,通过聚类得到层级树状图,每篇笔记通过一条 path 表示。然后对 query 进行处理,为每篇笔记生成一堆 query 来表示笔记,将真实 query 和生成 query 集合作为输入,生成对应的笔记 ID。但目前构建 query 的方式不能很好地充分拿到所有笔记信息和进行从细粒度到 high level的表示学习,导致候选文档不能很好地记住细粒度特征。

我们做了一个实验,对比基线是常见的密集检索模型和生成式模型 NCI。对文档获取语义向量后聚类,得到层次化 ID,分别用 AR2 和 NCI 模型召回笔记,在测试集上统计错误率。发现生成式检索模型在前面几位错误率较低,但越往后错误率升得特别快,验证了对细粒度特征有效记忆不足的问题。

其次,当候选文档规模增大时,性能会显著下降。原因是模型参数有限,记忆容量有限,当候选文档容量超过模型记忆容量时,记忆出现瓶颈,性能下降明显。我们做了一个实践,构建不同规模的候选文档集合训练 NCI 模型,测试在不同候选文档下的表现,发现候选文档增多时,生成式模型的召回率下降明显。
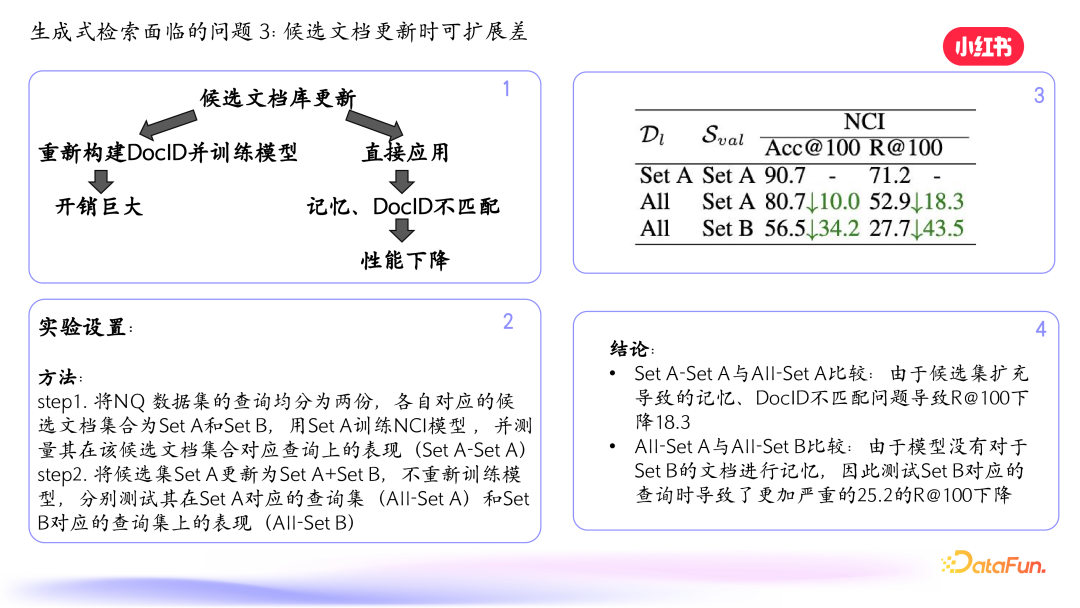
第三,候选文档更新时可扩展性差。对于密集检索,新文档加入后可以快速更新向量加入索引。但对于生成式检索,文档变了需要生成新的 query 加入模型训练,容易出现灾难性遗忘问题。如果不训练直接应用,可能会出现预测不准确的问题。我们做了一个验证实验,将数据集均分为两份,先用一份子集训练 NCI 模型,然后更新候选集不重新训练模型,测试在不同查询集上的表现,发现候选集扩充后召回率下降。

总结一下生成式检索和密集检索的优缺点。生成式检索的本质是记忆机制,是序列化生成笔记 ID,自回归解码范式导致时间和计算开销大,当候选文档多时代码层数变多,对细粒度特征记忆不足,候选文档库变化时需要重新训练模型。但优点是在解码过程中实现了查询和候选文档的深交互,文档有独立 ID 且能利用大模型的理解能力。密集检索本质是向量匹配机制,优点是较低的时延、可接受的计算开销,能捕捉细粒度特征,文档库动态变化时可高效更新索引。但缺乏深交互,存在一对多的问题。
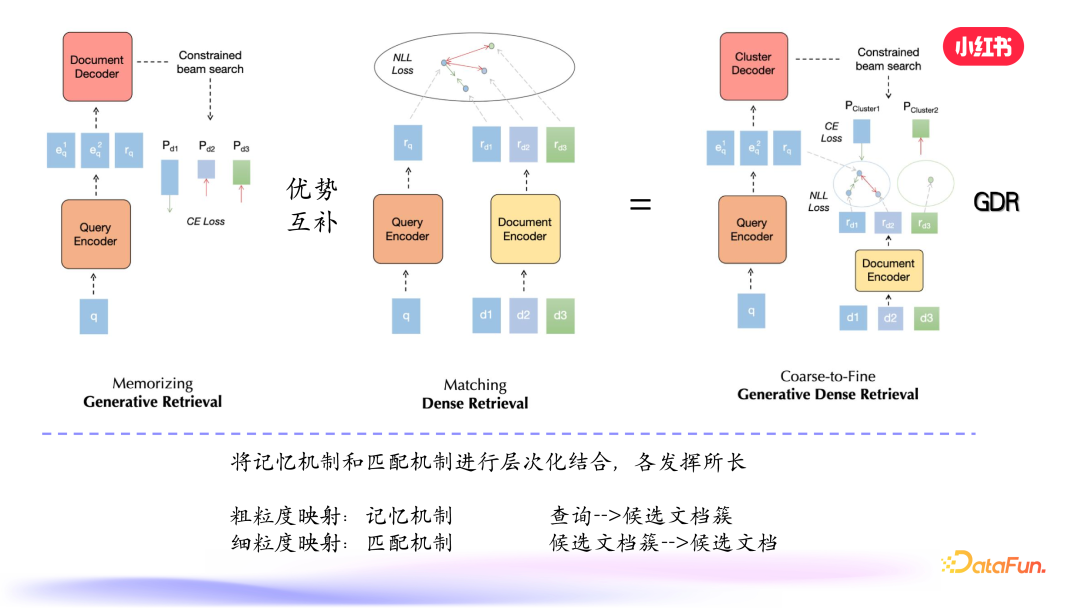
我们可以利用生成式检索的记忆能力记住 high level 的语义类 ID,到细粒度的地方用密集检索做匹配。具体而言,记忆机制主要用来记忆候选文档簇,一旦选到簇这个粒度之后,就会使用匹配机制,在更少的候选文档集合-簇里面做细粒度的匹配。
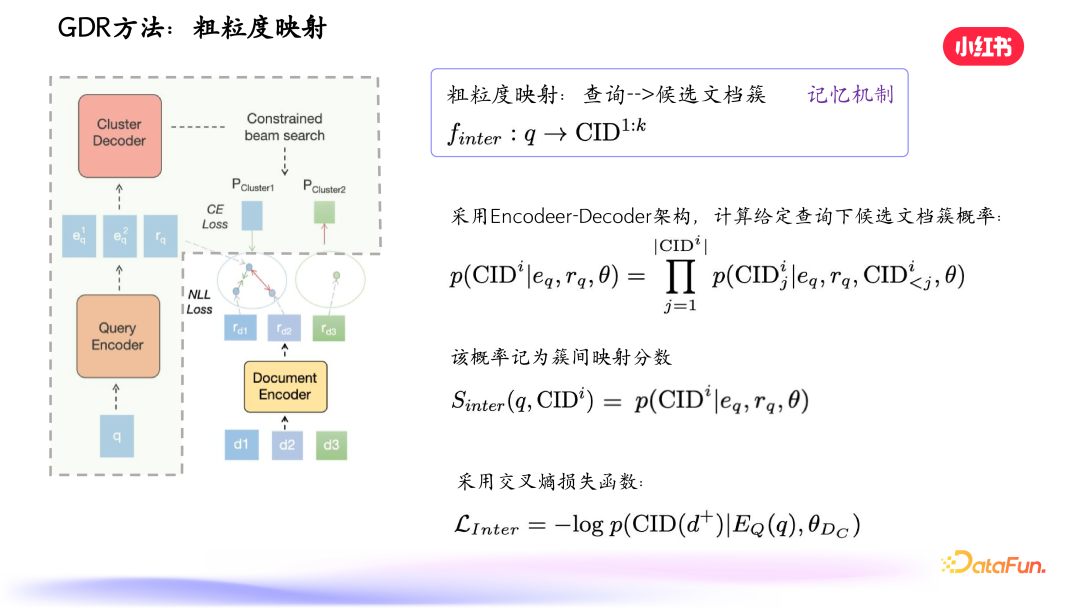
给定 query,编码器先编码出向量,进入解码阶段,首先对笔记进行向量表示和聚类,解码层级树的前面部分 high level 的 ID,得到候选文档簇的概率。在粗粒度生成后,在相关的叶子节点内进行细粒度的匹配,使用损失函数得到综合分数得到最终结果。

文档簇 ID 层级结构的构建至关重要。传统检索表示到 doc ID 维度会有问题,一是文档数量增加时模型参数量也要增加,否则召回性能下降;二是目前文档表示不一定有助于构建层级文档簇 ID。我们做了分析,如上图中的公式,先用 Bert 对文档进行向量表示得到一个树,再以我们的方式,用双塔模型进行密集检索训练,用文档的 encoder 生成向量,构建一个树,这样得到两个树。在两个树里,分别对正确文档的 ID 计算出最大公共子序列,最前面的最大公共子序列应尽量一致,越一致,模型记忆的负荷越小。因此我们希望构建易于记忆的文档簇,减少模型记忆负荷。

我们还设计了约束,根据模型大小控制文档簇数量,每个叶子节点包含一定数量的文档,留下部分通过细粒度匹配机制去匹配。

另外一个特别的设计是基于簇的自适应负采样策略,在细粒度匹配阶段挑选正负样例,让匹配机制更有针对性。
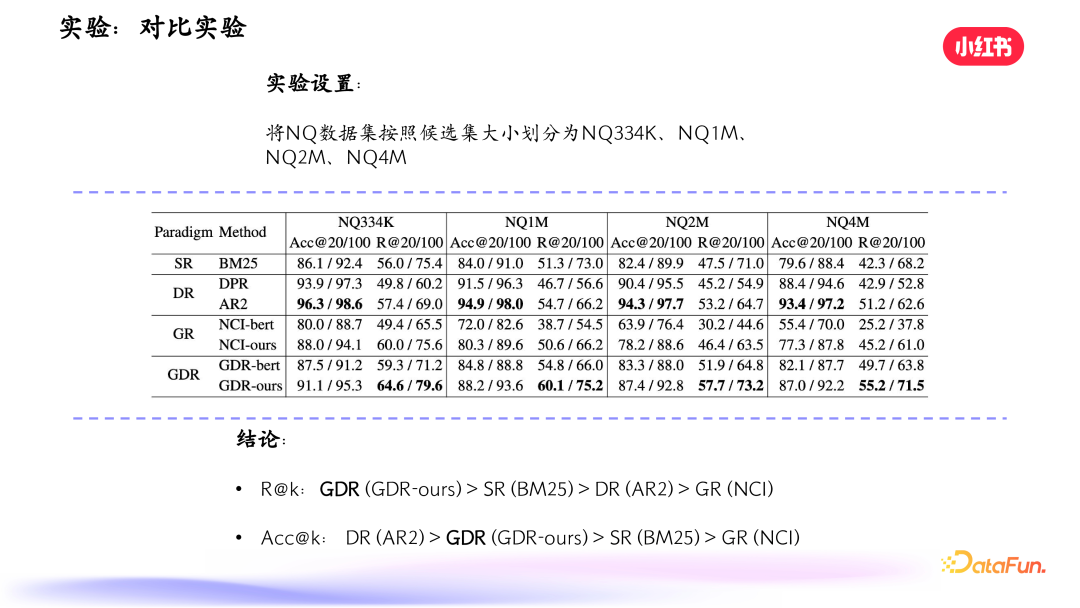
实验结果表明,我们提出的 GDR(生成式密集检索)在召回指标方面是最优的,准确性方面 DR 是最好的,GDR 次之。
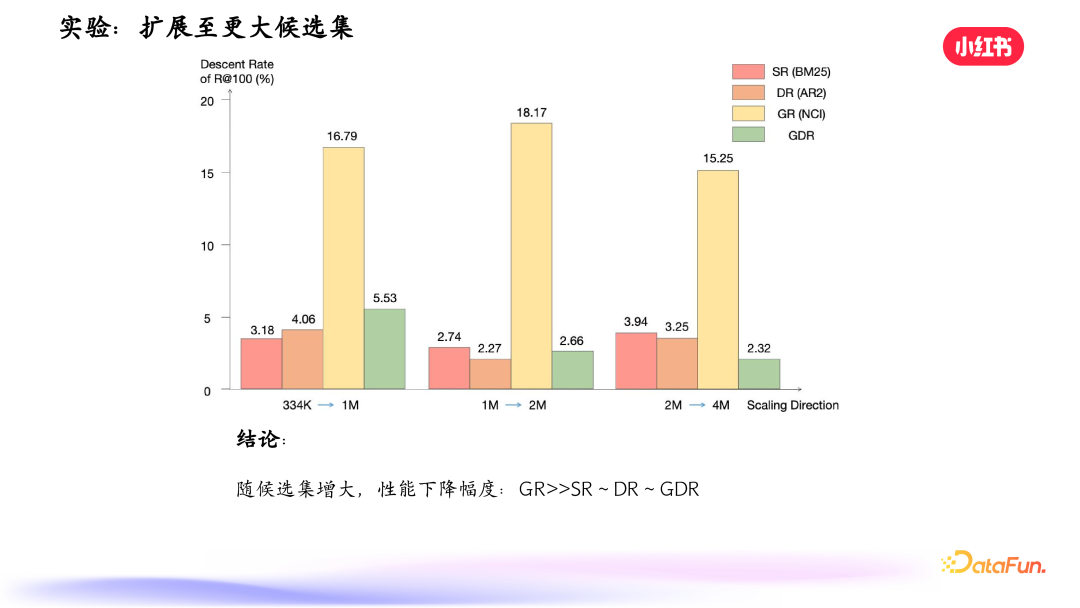
扩展至更大候选集,传统生成式检索方法效果下降明显,其他三种方式下降不明显。
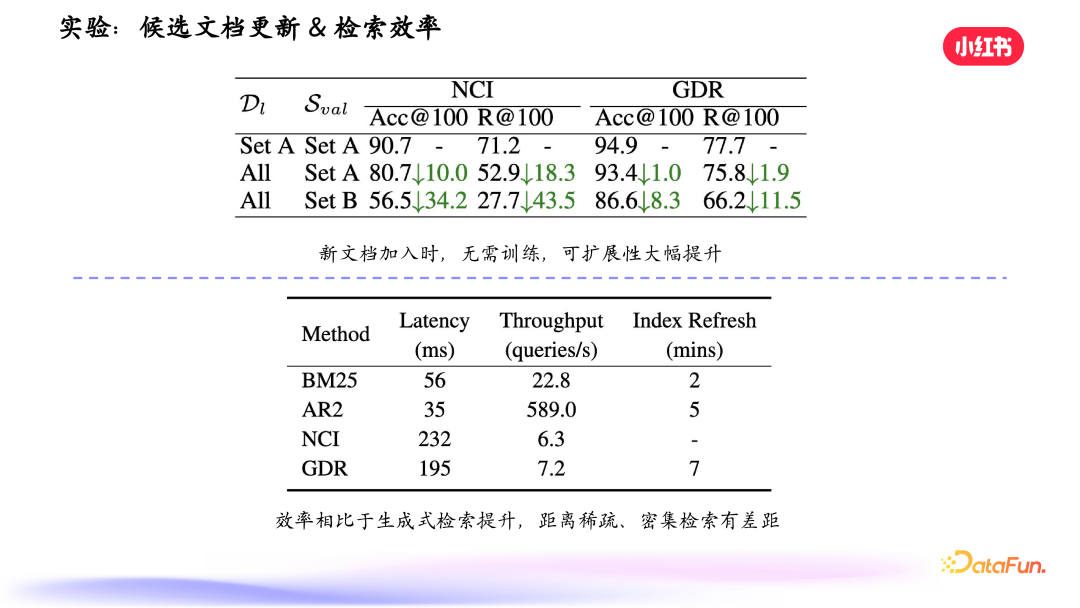
关于文档更新,可以看到,相比于传统方式,GDR 效果下降的幅度很小。检索效率方面,包括时延、吞吐量,相比 BM25、AR2 有显著提升,这也是需要继续优化的一个方向。
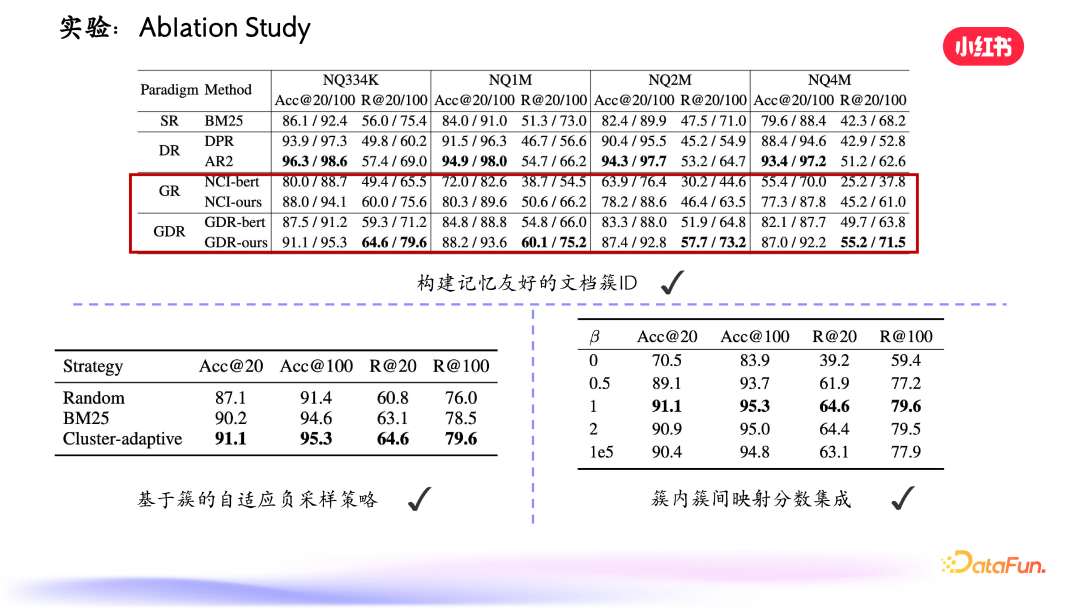
我们还做了消融实验,验证了构建记忆友好的文档簇 ID 和自适应负采样策略的有效性,以及超参数的泛化性。
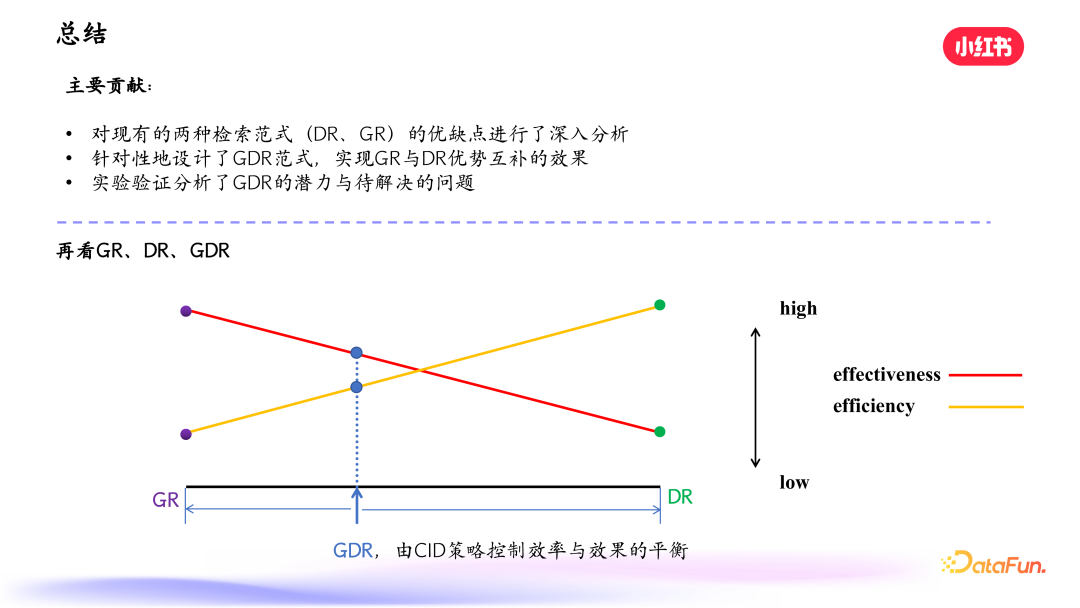
最后总结一下该工作的主要贡献。首先我们对现有的两种检索范式,即 DR 和 GR 进行了深入分析,然后针对性地设计了新的 GDR 范式,实现了 GR 和 DR 的优势互补,为生成式检索落地提供了有力支持。我们通过实验分析了 GDR 的潜力和问题,并指出可能的解决方向。
上图下半部分显示了 GR、DR 和 GDR 在效率和效果上的表现,可以看到,GR 的效率较低,但其召回效果是非常优秀的;DR 的效率很高,但效果较弱;而我们的 GDR 的方式,则在效率和效果上进行了平衡。
GDR:应用场景
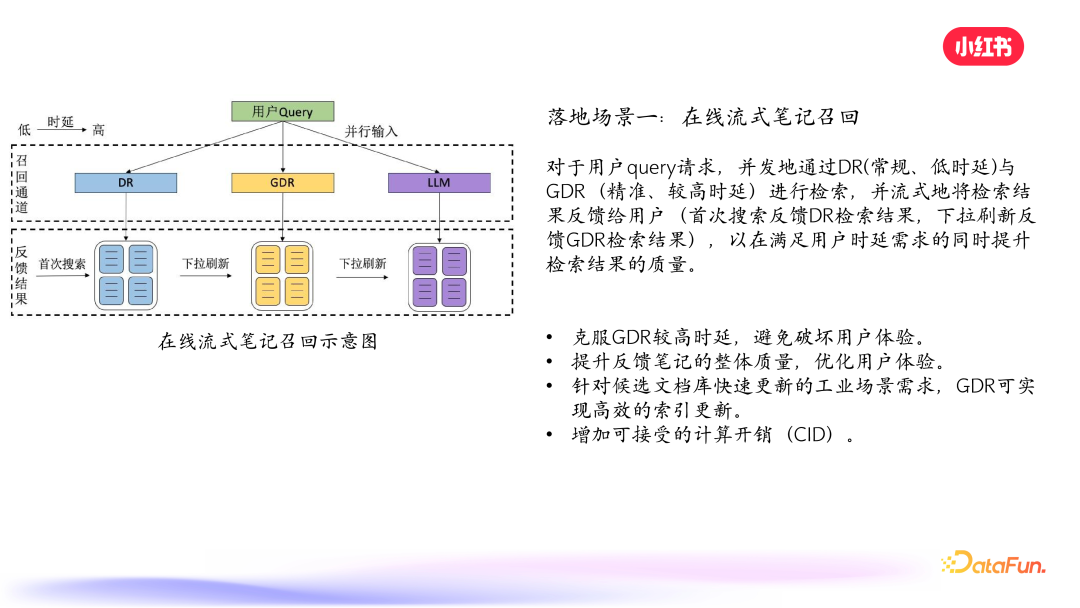
通常在召回阶段可以默认触发 DR 密集检索的过程,与此同时并行地调用 GDR 和 LLM 检索,从而在利用 GDR 和 LLM 精准的召回效果的同时,避免其高时延的问题。
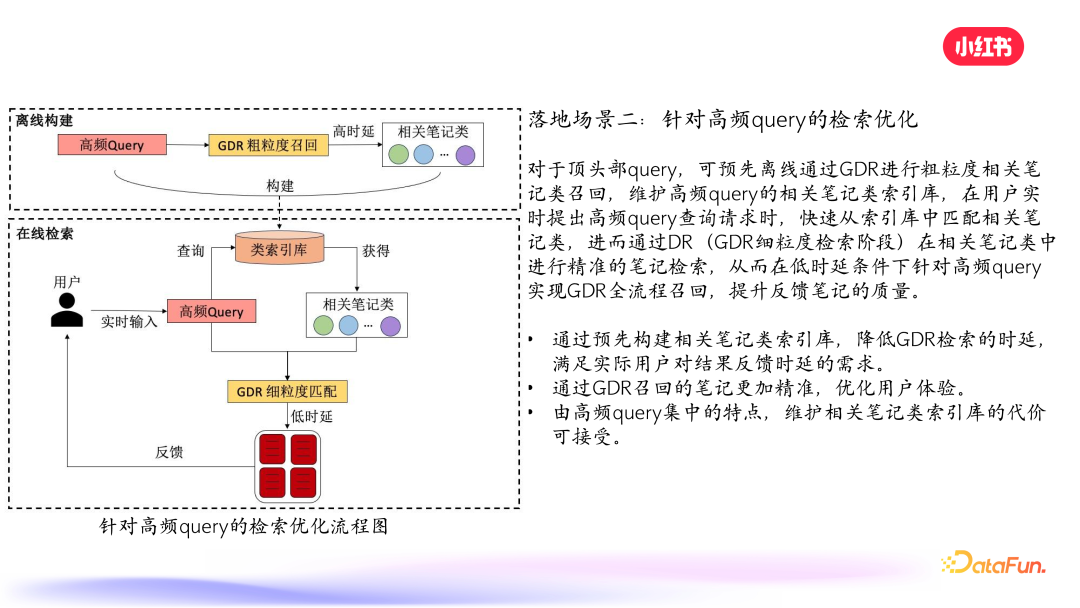
对于 query,可以预先离线通过 GDR 进行粗粒度相关笔记类召回,维护高频 query 的相关笔记类索引库,之后再遇到该 query,即可快速匹配,进而通过 DR 在相关笔记类中进行精准的笔记检索。这样不仅可以降低时延,还能提升召回准确度。
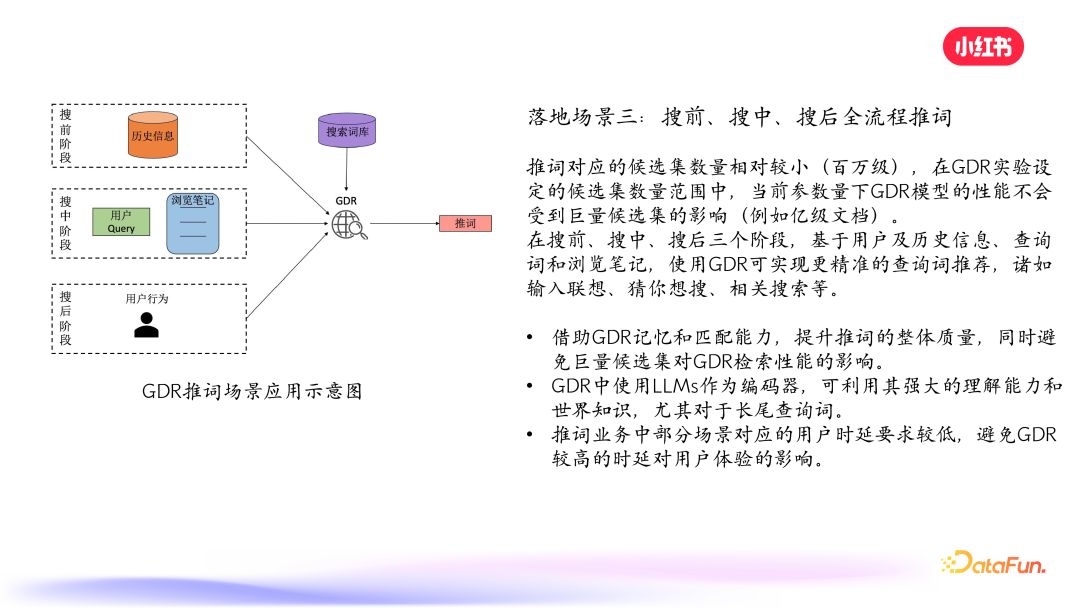
推词对应的候选集数量相对较小(百万级),在 GDR 实验设定的候选集数量范围中,当前参数量下 GDR 模型的性能不会受到巨量候选集的影响(小红书笔记库在亿级以上),其能力能够充分发挥。另外,也可以对 query 编码端使用 LLM,利用其强大的理解能力和世界知识,优化查询,尤其是长尾查询。
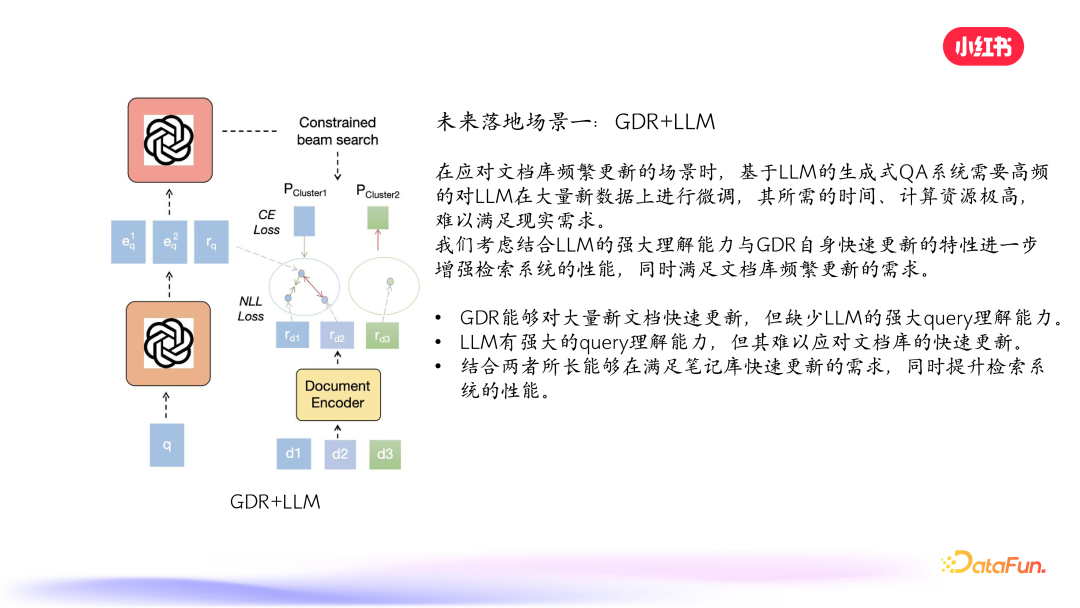
未来的落地场景之一是将 LLM 应用在 GDR 中。不仅可以提升对 query 的理解能力,同时提升检索性能。
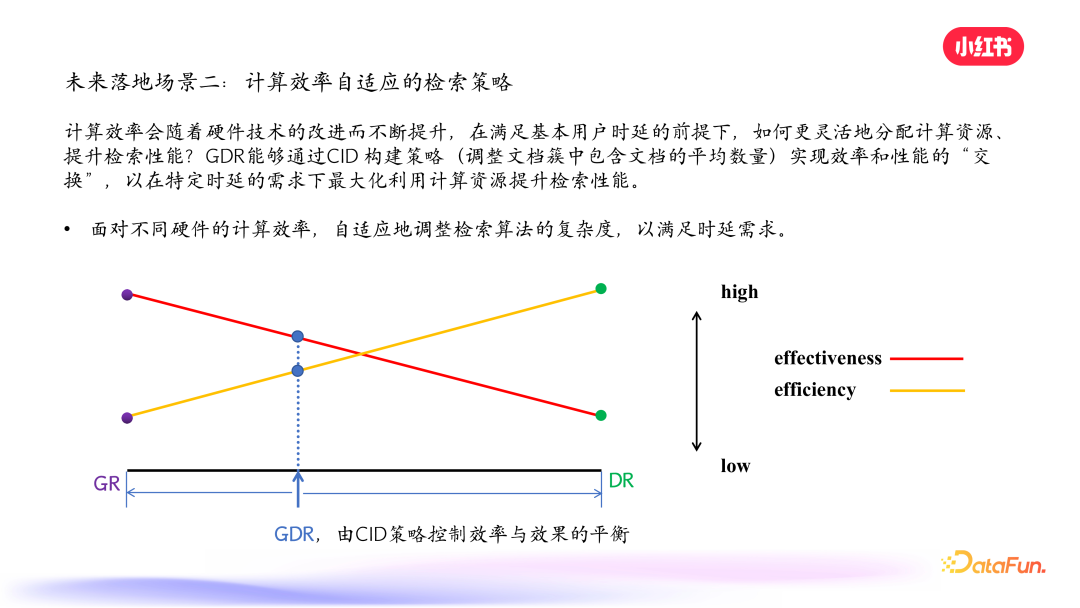
计算效率会随着硬件技术的改进而不断提升,在满足基本用户时延的前提下,实现更灵活的资源分配,提升检索性能。
问答环节
Q1:如何解决层次聚类,即层次化 ID 不稳定导致 GR 模型需要重新训练的问题?
A1:GDR 可以避免这个问题,在细粒度阶段使用匹配机制,文档变化可放到相近叶子节点,不需要重新训练记忆模块。
Q2:生成式检索对于新文档加入之后的处理流程是怎么样?如何应对 ID 快速增量更新的问题?
A2:一部分新文档可直接加入叶子节点,长周期内新文档足够多时可对记忆模块进行周级或月级更新,避免频繁更新记忆模块。
Q3:从现在只从文本信息中获得 ID,是否会导致传统模型中协同信息的缺失?
A3:会缺失,可以在解码文档 ID 阶段加入用户行为,让模型有一定概率选择真实笔记 ID 和探索别的,loss 上也可引入历史行为特征。
Q4:从 1 到 6 的错误率不是应该累计增加吗?为啥第六个的错误率会降低?
A4:对于 AR2 这种向量检索,训练过程没有学习更高维向量的匹配,只算最后一个错误率低是因为其与细粒度笔记向量匹配更好,中间几层没有学习。
Q5:GR 里去记忆 ID 不就抛弃了大模型的优势吗?
A5:没有抛弃,query 的编码用大模型对长尾 query 理解能力更强,可减少对每篇笔记生成大量 query 的需求,能用到大模型的能力。
Q6:层次数设置是几层?每层多少个簇?一个文档可能属于多个簇嘛?
A6:模型大小决定簇的数量,超参设置每一层最多生成 10 个簇。目前一个文档属于一个簇,但在框架下允许一个文档属于多个簇,类似密集检索中一个文档有多个向量表示。
Q7:论文中讲的这些东西在现实的生产环境中有没有落地?
A7:已经在推动落地,在召回环节作为另一个通道,尤其是推词阶段更适合落地。
Q8:真实场景下如何应对一个更新周期内里从零开始突然爆发式增长的某一类笔记?
A8:可以马上启动整个笔记的训练,或对这一类笔记再做细致聚类,产生更多层级的表示。在框架下也可灵活更新 DR,对突然增长的一类笔记进行针对性学习。

































 粤ICP备17114055号
粤ICP备17114055号