导读 数据分析平台作为企业内部数据价值变现的重要载体,在企业数字化进程中发挥着重要作用。企业数据需求的复杂性以及当前平台存在使用高门槛、口径不统一、需求响应不及时等问题,使得分析平台价值体现受到影响。如何解决这些挑战,成为业界普遍关心的议题。我们融合 Chat BI 与 Headless BI,构建了新一代数据分析平台,为用户提供了更高效、更智能的数据分析服务和体验。
本次分享主要内容包括以下几大部分:
1. 数据分析平台现状
2. 架构演进思考
3. Chat BI 与 Headless BI 融合实践
4. 未来展望
1. 业务团队痛点
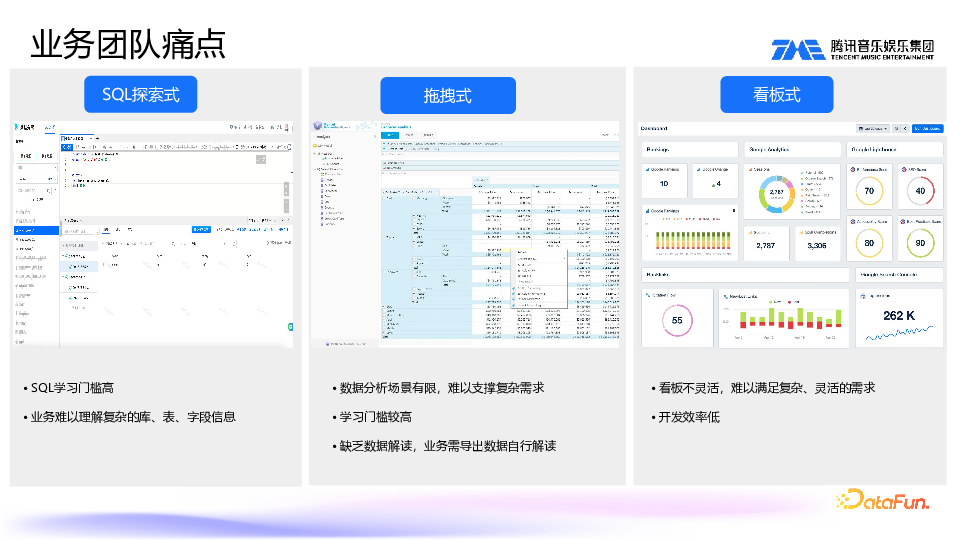
我们从数据分析平台的现状讲起。当前,数据分析主要采用三种模式。
第一种是 SQL 探索式,即数据工程师开发一个平台,通过写 SQL 来查取数据或进行探索。这种方式有两个不足之处,一是 SQL 学习门槛高,对普通业务人员来说上手较慢;二是元数据、库表和字段信息很多很复杂,业务人员很难快速理解,需要不断询问数据工程师字段含义、表的位置以及库里有哪些表等,数据工程师只能忙于处理这些繁杂的需求。
第二种是拖拽式。将一些维度指标放在一起,通过拖拽来查看数据。这种模式也存在不足之处,首先,分析场景有限,如果针对特定领域,就需要创建很多这样拖拽式的已建模好的数据;此外,操作门槛也较高,需要不断进行下钻、查看等操作;再者,缺乏数据解读,难以直接获知数据内涵,业务方常常需要将数据下载后再通过 Excel 等离线方式自行解读。
第三种是看板式。这种方式在数据解读等方面做得不错,但看板不够灵活,想增加一些维度就需要额外提需求,再制作一个看板,导致开发效率低下。2. 业务团队诉求
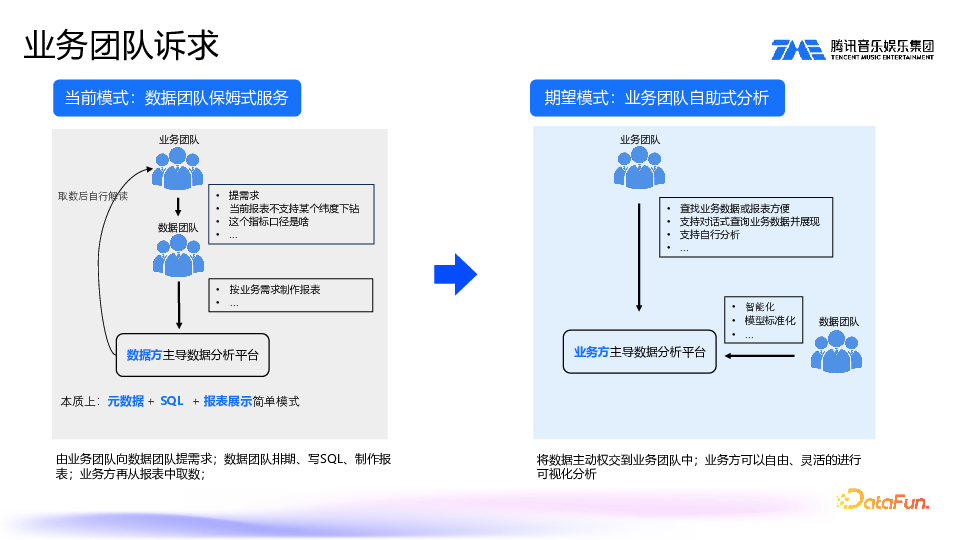
在当前模式下,数据团队提供保姆式服务。业务团队提出需求,数据团队按需求制作报表,发布到自助分析平台上,业务团队查看报表和看板,再下载数据进行分析。本质上,这个分析平台采用的是抽取元数据后写 SQL 的简单模式,效率低下。
业务团队期望的模式是变数据方主导为业务方主导。他们能直接向数据分析平台询问和查询数据,自主、自由地进行可视化数据分析,并进行数据解读等。而数据团队只需做一些标准化的工作,将数据模型标准化,并提供智能化服务插件等。3. 数据团队痛点
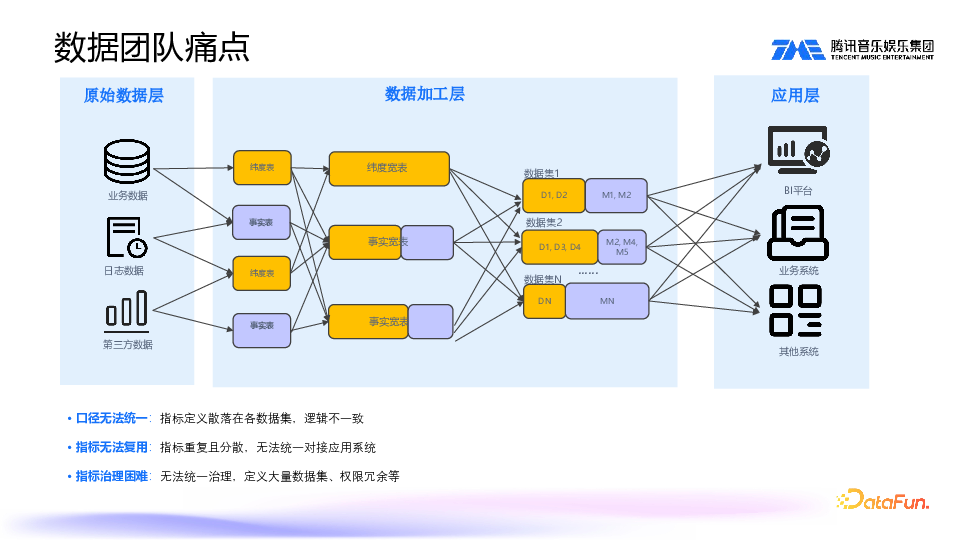
再来看看数据团队的痛点。数据加工链路如上图所示,从原始层接入,到加工层,通常分为 ODS 层、DWD 层、DWS 层、ADS 层等进行分层的数据加工处理。加工处理后,基于 ADS 层或 DWD 层的表,写 SQL 创建数据集,再发布到 BI 平台上,或对接其它系统。
这样的模式下需要制作很多数据集,一个数据场景就要注册一个数据集,并且权限分配在数据集层面,比如同一指标在不同数据集会定义不同权限,因此存在大量冗余。二是指标逻辑不一致,难以复用。这些是数字团队面对的主要痛点。
架构演进思考
1. 引入 Headless BI 解决数据治理问题
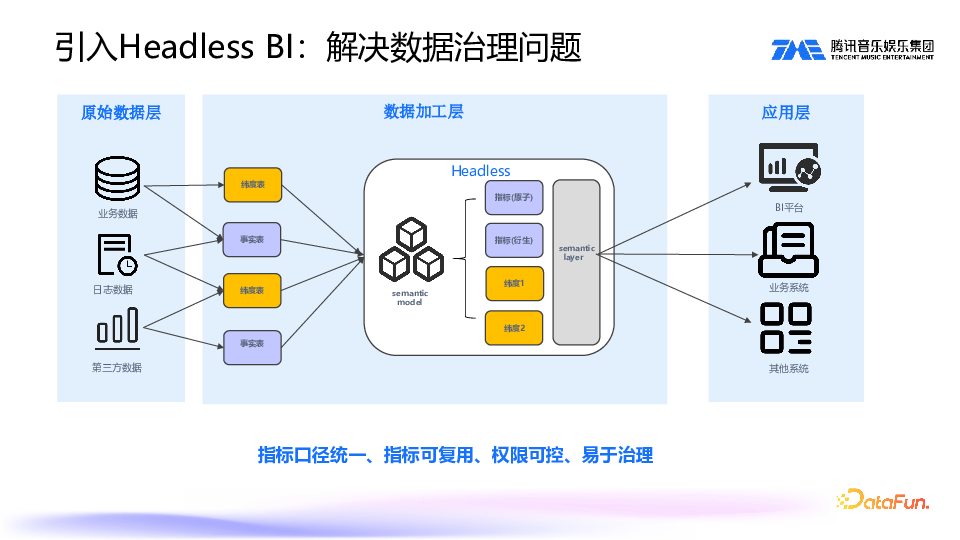
针对上述痛点,我们考虑引入 Headless BI 方案来解决数据治理问题。Headless BI 主要包括两块,一个是 semantic model(语义模型),另一个是 semantic layer(语义层)。通过抽象出指标、维度等语义对象,将这些语义对象暴露给外部系统直接使用。这样做的最大好处是口径统一,可以一处定义,多处复用。第二个好处是权限可控。以前,一个数据集里设置一个权限,另一个数据集中又设置一个权限,导致权限不可控,可能引发数据泄露。现在我们针对指标设置权限,当外部系统对接时,权限能够得到控制,不会产生误解。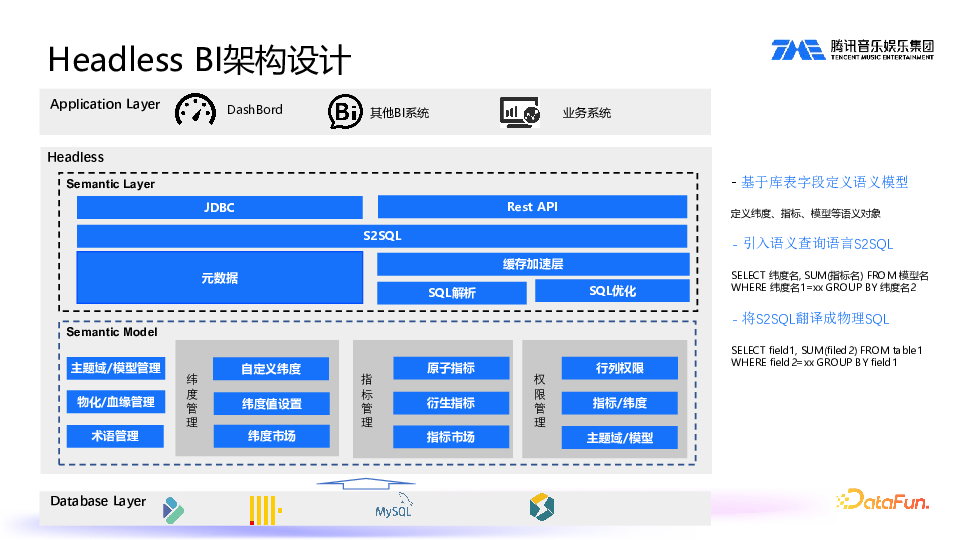
我们现有实践中的 Headless BI 架构设计如上图所示。最底层是数字层,包括 StarRocks、Doris、ClickHouse、MySQL 等数据引擎。通过这些数据引擎进行语义建模,建立维度、指标。在维度和指标上进行权限设置,如行列权限、指标/维度权限、主题域/模型权限等。此外,还有对物化和血缘的管理,以及术语处理。
Headless
BI 第二个重要模块是 semantic layer,也就是查询层。我们抽象了一个语言 S2SQL,所有对外数据都是通过 S2SQL 来查询的。对外支持以 JDBC 模式来连接,也可以通过 HTTP 请求来连接。Semantic layer 还有一个重要功能,是把 S2SQL 转译成物理 SQL。这涉及到缓存,SQL 解析和 SQL 优化。
最上层是应用层,Dashboard、BI 系统以及其它业务系统都通过 S2SQL 这一语言进行查询。
2. 引入 Chat
BI 解决业务易用性问题
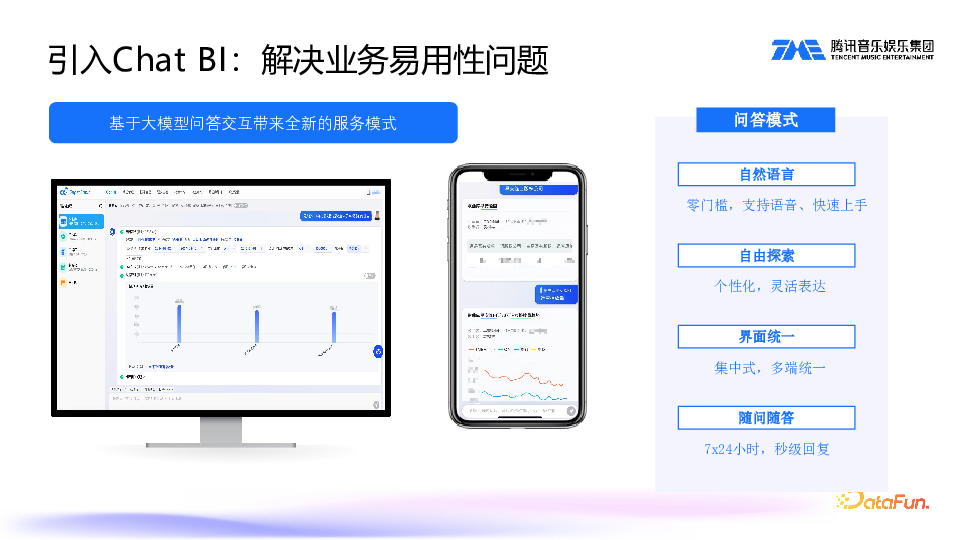
引入 Headless BI 后,还有一个问题未解决,即业务的易用性问题。如何让业务更便捷更好地使用数据呢?如今大模型技术发展如火如荼,我们考虑通过结合 Chat BI 技术进行问数和取数。例如,在电脑 PC 端输入一段文本,就能让数据看板实时展现出来,还可以在移动端,直接通过语音或文字的方式进行提问,非常方便。
这种方式带来的好处:一是零门槛,无需额外提需求,只需语音提问即可;二是灵活,PC 端和手机端都支持;三是随问随答,秒级回复。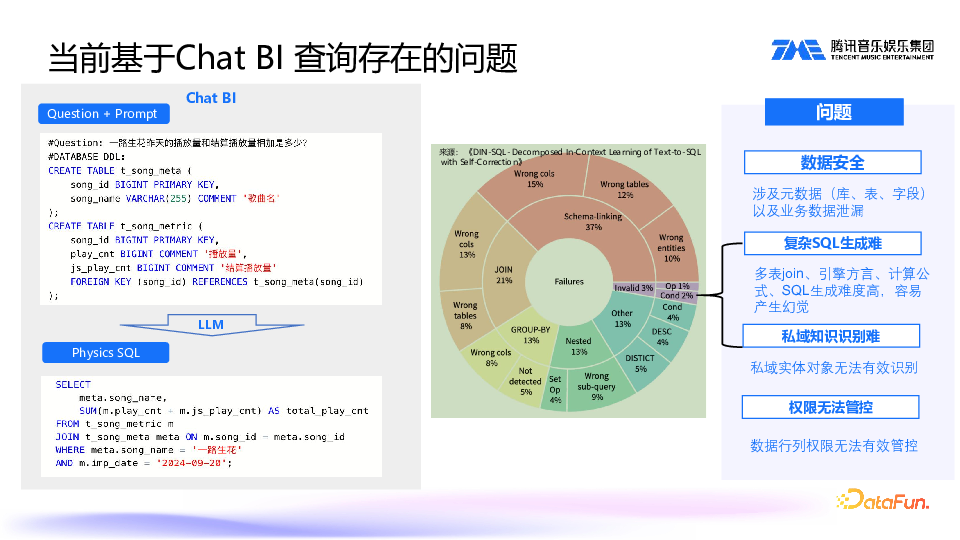
但是当前的 Chat BI 仍存在一些问题。我们先来看看当前的模式是什么样的。Chat
BI 通过给大模型一些语料,让它生成 SQL。比如提问“一路生花昨天的播放量和结算播放量相加是多少?”然后,我们需要提供建表语句,维度表包括歌曲 ID、歌曲名;指标表包含播放量、结算播放量,以及与维表的关联关系,比如歌曲 ID。把这些信息一起告诉大模型,让其生成一个物理 SQL。这种方式非常依赖于大模型的能力,如果大模型能力有限,生成的 SQL 很可能是错的。
一篇论文中指出了生成 SQL 通常出错的点在哪里。第一个是 schema linking,占了 37%;join 占了 21%;group by 占了 23%,还有其他一些点。因此直接让大模型去执行 SQL 是很困难的,而且大模型经常产生幻觉问题,生成的 SQL 经常会出错。
主要问题可以归纳为四大方面:首先是数据安全问题,可能出现元数据以及业务数据泄露;另外,如前文提到的,复杂 SQL 生成困难;第三,私域知识识别难,例如“一路生花”,大模型可能不知道这是一个维度值,可能会把它误认为是纬度名;第四个问题就是权限无法管控,比如结算播放量指标属于敏感指标,只允许特定的人去查看,而大模型生成 SQL 语句时很难做到权限管控。3. 融合 Chat
BI + Headless BI
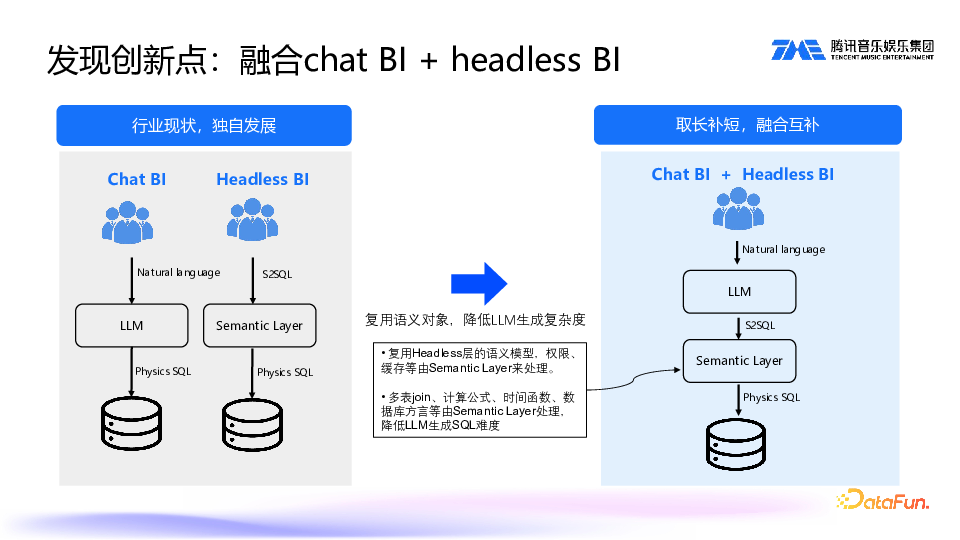
前面介绍了 Chat BI 和 Headless BI 的优势,和它们存在的问题。我们将二者进行了融合。
首先,我们将 Headless BI 的 Semantic layer 作为大模型查询的基础底座,复用其中定义的一些语义对象,这样能够降低生成 SQL 的复杂程度,像权限、计算公式、关联等操作都可以由语义层来处理。这样,大模型只需要专注于提取实体的语义,进而生成一个简单的 S2SQL,就能用来查询数据了。这里的 S2SQL 不会涉及敏感信息,它属于一种逻辑概念,不会把真实的数据表提供给大模型,避免了真实数据表的暴露。而查询数据也是通过语义层来操作的,这样也防止了真实数据出现泄露的情况。
Chat BI 与 Headless
BI 融合实践
在第三部分,将详细介绍 Chat BI 与 Headless BI 的融合实践。1. 融合 Chat
BI + Headless BI 的初始版本

最初,我们通过融合这两者制作了一个初始版本。首先,定义好 semantic model,包括歌曲名、数据日期等维度,以及播放量、结算播放量、总播放量等指标,以及“热歌”这一术语,并为指标、维度设置权限。将这些语义在 Headless BI 中明确下来。定义好后,将这些语义告知大模型。例如,可以看到其数据库类型是 MySQL,table 是歌曲库,分区字段为数据日期,以及维度信息和涉及的指标。根据这些信息就会生成一个简单的 S2SQL,与前面包含 join 关系和计算公式的复杂 SQL 相比,这个 S2SQL 非常简单。对于大模型来说,生成 SQL 的复杂度大大降低。然后,我们通过这个 S2SQL 到 semantic layer,进行一些操作,比如权限控制、缓存,以及 SQL 解析和优化,最终得到一个物理 SQL。
初始版本的准确率较高。但存在一个比较大的问题,因为库有很多,比如歌曲库、艺人库、专辑库等等,每个库又包含很多字段,在这种情况下,由于上下文不够,而装载的数据太多,模型就容易产生幻觉,导致生成的 SQL 错误。因此我们抽象了一个 Schema Mapper 组件来解决这一问题。2. Scheme Mapper:提升语义实体识别准确性
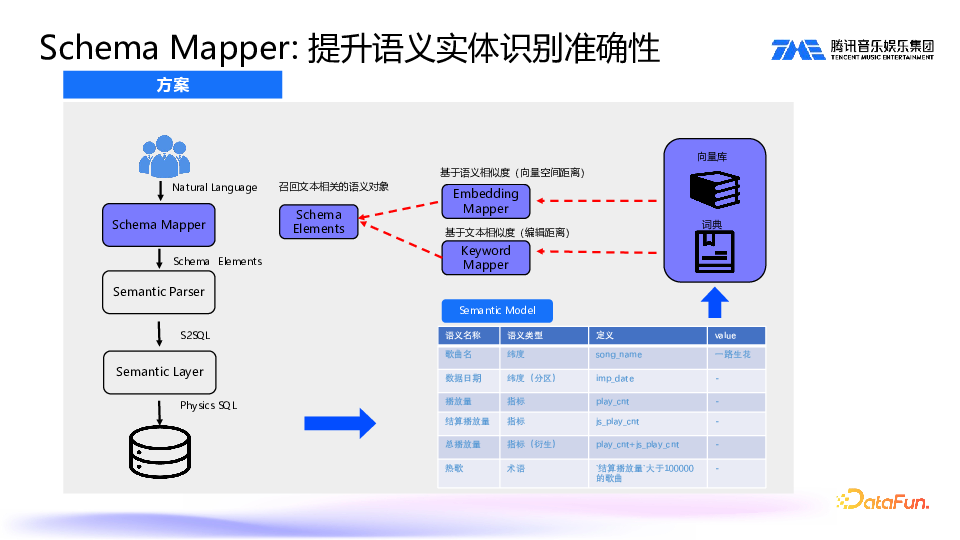
首先,我们将维度和指标都存入知识库(向量库+词典库);然后,通过相似度(向量空间距离、编辑距离)召回所需的语义,而不是将所有语义都带给大模型。这样,大模型就能更好地聚焦,从而提升其实体识别的准确性。通过 Mapper 之后,把这些识别到的语义对象 Schema Elements 一起组装给大模型,让大模型再生成 SQL,这样生成的准确率可以得到大幅提升。3. QueryFilterMapper:支持 Copliot
Chat 模式
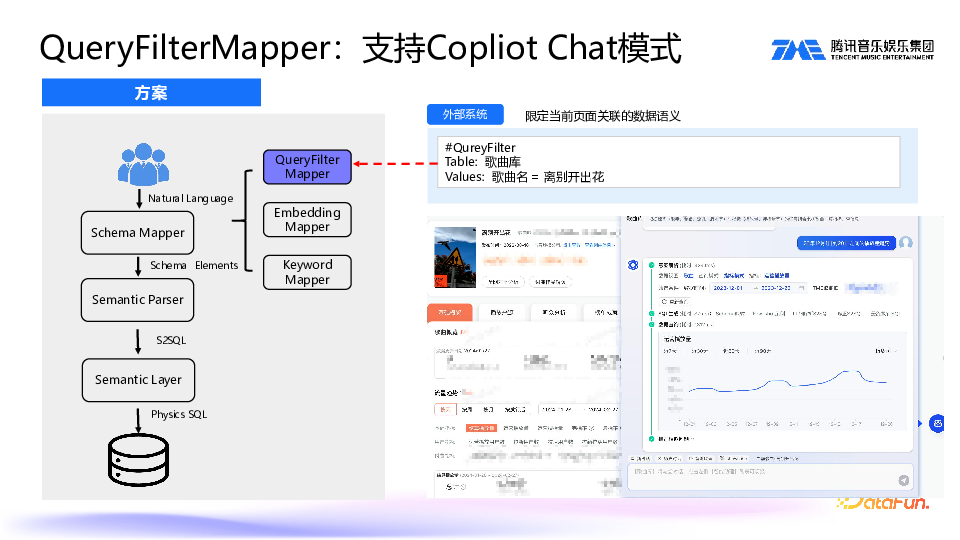
除了利用 Embedding Mapper 和 Keyword Mapper 来进行召回以外,我们还抽象出了一个 QueryFilter Mapper。因为除了 Chat BI 还有一些原有的BI系统,所以需要进行集成。利用 QueryFilter Mapper 组件,其它系统能够通过 copilot 的方式进行问数。比如可以通过小助手直接提问,就可以获得原有看板之外的数据信息。
用户直接在当前上下文里提问,通过 QueryFilter Mapper 组件,会将 table、维度等关键信息直接提供给大模型,这样就实现了将 Chat BI 集成到现有系统中。4. Semantic Corrector:解决大模型幻觉问题
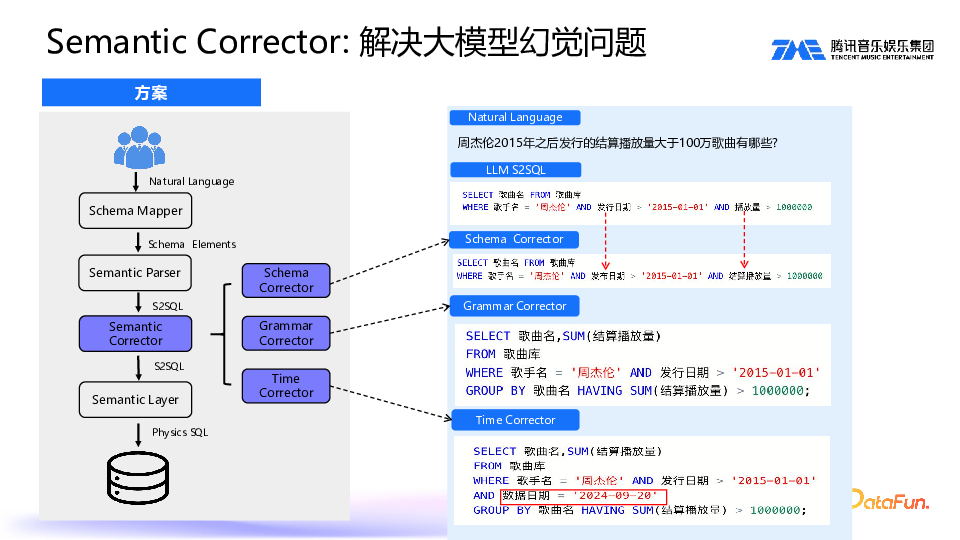
前面提到,即便对大模型进行了诸多优化,它仍有可能出现幻觉问题。主要问题有三类,即 Schema 错误、语法错误和时间错误。需要针对性地修正:Schema Corrector,修正错误的维度和指标;Grammar Corrector,修正语法错误,例如计算结算播放量大于 100 万,要加上按维度分组,再进行后过滤,加上一个 HAVING SUM;Time Corrector,没有分区日期过滤可能导致查询超时,因此需要限制数据日期,修正时间语义。5. 记忆管理:持续学习领域知识
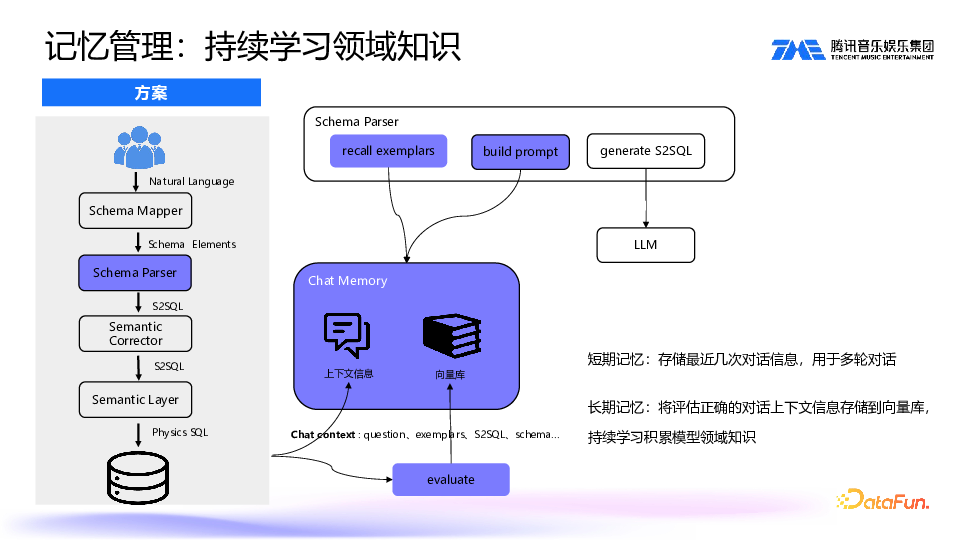
另一个关键点是记忆功能,即大模型是否有学习到领域知识。我们需要将历史问题和相关数据收集起来,作为后续大模型生成的参考。这样,大模型就能学习到更多领域知识,生成的 SQL 也会更符合业务方的需要,Chat BI 会越来越聪明。
我们添加了一个 Chat Memory 模块,主要包括两部分:短期记忆和长期记忆。短期记忆用于收集最近几次的上下文信息,包括问题、示例、生成的 SQL 以及 schema 映射到的信息,构造 prompt,用于多轮对话。长期记忆,会把评估正确的对话上下文信息存储到向量库。这里的评估有两种模式,一种方式是由业务方、数字分析师等进行评估;另一种方式是通过大模型自行评估。通过长期记忆,让大模型持续积累领域知识。6. 引入 Agent:解决复杂数据需求
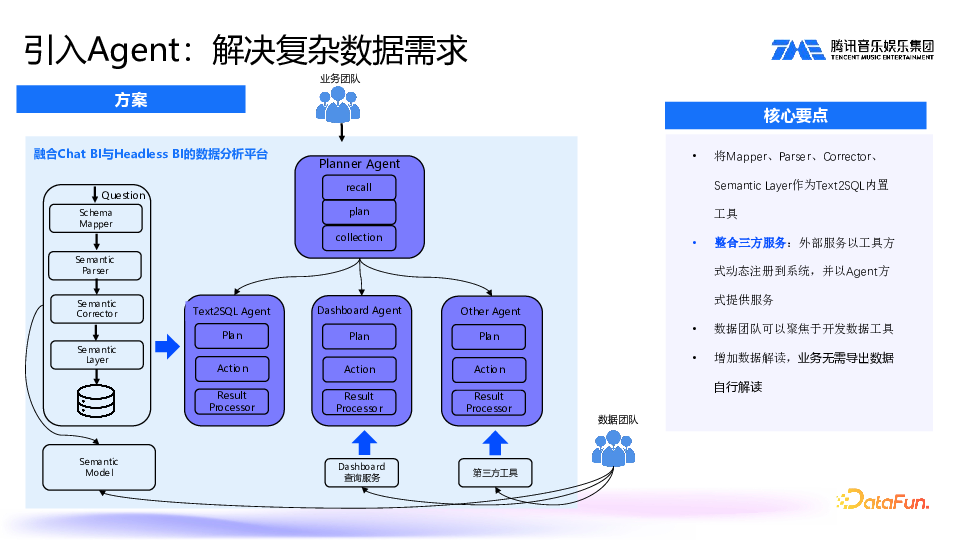
首先,我们将前面提到的 Mapper、Parser、Corrector、Semantic layer 抽象成一个 text2SQL 工具,然后把这个工具注册为一个 text2SQL Agent。另外,在最前面设置一个 Planner Agent,去做具体 Agent 的选择,召回可能用到的 Agent,接着为每个工具制定 plan,判断这个工具能否执行,工具执行完成后进行结果的收集,并对数据进行总结和解读。
其它外部工具和服务可以不断注册进来,注册后作为一个 Agent,由 Planner Agent 进行召回和选择。
这样,数据团队可以更加专注于开发数据工具。同时,数据解读问题也得到了解决,业务方不再需要导出数据自行解读,现在 Planner Agent 会对数据进行总结再返回给业务端。7. 抽象核心组件+SPI 机制:解决框架扩展性问题

前面讲到的各种组件,如 Mapper、Parser 等等,都较为复杂,我们将核心组件抽象出来,再加上 SPI 机制,解决了框架扩展的问题。我们可以插件化地对工具进行修改,修改可以立即生效,还可以根据特定场景进行自定义的配置,其它第三方语义层也可以很方便地集成进来。8. 面向业务团队查询数据
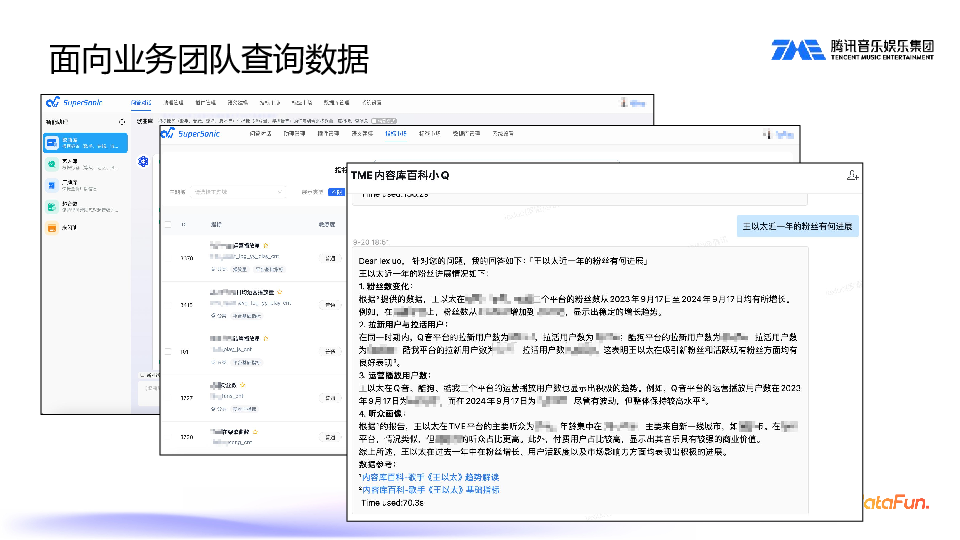
下面来看一下面向业务方的查询数据的效果。业务方只需输入一个问题,就可以得到所需数据,操作非常方便。结果也一目了然,非常方便业务方展示和使用。另外,业务方经常想要了解表、指标或维度的定义口径。在指标市场中,用户可以轻松查询定义口径。
另外,针对用户提问,Agent 可以自动拆解问题,调用所需工具,将查询到的数据返回给客户端,并进行数据总结。这样我们就能清晰地看到数据的变化,获得更深层次的数据趋势。除此以外,还会给出参考链接。这个真正实现了由业务方主导的数据分析平台。9. 面向数据团队治理数据
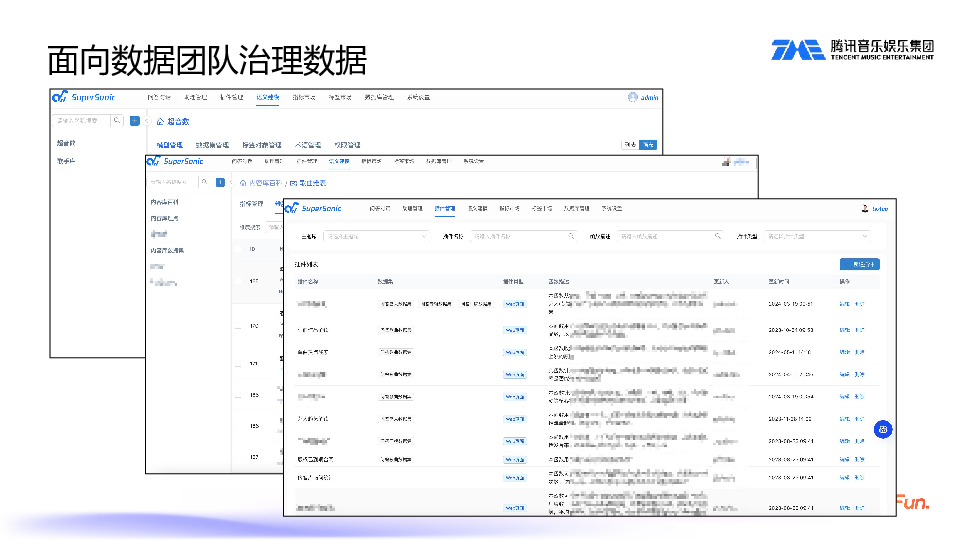
面向数据团队,主要进行语义建模,设置好关联关系,定义好维度指标。定义好之后,就不需要对每个需求开发看板了,借助 Chat BI 加大模型和语义层即可实现复杂查询需求。
数据团队还有一项重要的工作,就是开发插件,例如词曲作品解读插件、热点线索插件、访问统计插件等等。开发完成后自动加载入 Agent 即可生效。
未来展望
Headless
BI 方面,我们将持续推进血缘构建和物化加速等方面的建设。比如,从数仓的 DWS、DWD、ADS 层进行血缘关联关系的构建。另外,数据团队进行建模成本较高,因此我们希望探索借助大模型的能力进行智能建模。例如只要连接到一个库、一张表,就能自动给出维度指标、别名等内容,实现一键智能建模。从而减少数据开发的工作量,降低建模成本。
Chat
BI 方面,希望结合移动端和语音转文字技术,进一步提升便捷性。同时,开发和集成更多数据工具,并优化召回准确率,以便拓展到更多场景。
Q&A
Q1:可否透露一下 SuperSonic 的未来发布计划以及路线图?
A1:我们在 GitHub 上会发布具体计划。此外,还可以关注“SuperSonic”
微信公众号获取最新信息。目前我们的开发模式是针对具体 issue 进行讨论,再进行相应的开发,未来会考虑将每个版本应具备的功能以 roadmap 的形式展示出来。
Q2:针对分享中介绍的一系列技术,包括结合大语言模型的一些技术,如何保证数据输出的准确性?是否有一些实际的量化指标?
A2:前面讲到,我们通过 Mapper、Corrector 以及 Semantic layer 等一系列优化来提升准确性。我们在 CSipder 上进行了评估,在两三个月前的评估中,准确性大概为 80%+。

































 粤ICP备17114055号
粤ICP备17114055号