在如今的科技浪潮中,生成式 AI(GenAI)和大语言模型(LLMs)逐渐成为推动技术变革的关键力量。无论是用于自动化内容生成,还是提升人机交互体验,LLMs 都展现出强大的潜力。作为开发者,可能有人已经意识到,在边缘计算设备上高效部署这些复杂模型的需求越来越迫切。(文末参观英特尔科技体验中心)为了满足这一需求,英特尔推出了 OpenVINO™ 工具套件,并支持与 vLLM 结合,优化大语言模型的推理性能。以下内容将深入浅出得探讨如何利用 OpenVINO™ 与 vLLM,在英特尔® 酷睿™ Ultra 处理器上实现大语言模型的高效部署。OpenVINO™(Open Visual Inference and Neural Network Optimization)是一款由英特尔开发的开源工具套件,旨在通过优化深度学习模型的推理性能,帮助开发者在各种硬件平台上高效部署 AI 应用。OpenVINO™ 支持多种框架的模型优化,包括 TensorFlow、PyTorch 等,使其能够在 CPU、GPU 和专用 AI 加速器上获得更高的推理效率。
在最新的 2024.3 版本中,OpenVINO™ 进一步增强了对生成式 AI 的支持,特别是针对大语言模型的优化。这些改进使得开发者可以更轻松地将 AI 应用部署在从边缘设备到云端的各种环境中。
Hugging Face:https://huggingface.co/OpenVINOvLLM 是由加州大学伯克利分校开发的开源框架,专为大语言模型的高效推理和部署而设计。与传统的 LLM 库(如 Hugging Face Transformers)相比,vLLM 在推理吞吐量上有着显著提升,最高可达 24 倍。其设计目标是简化大语言模型的部署过程,同时降低部署成本。
- 高性能:vLLM 通过优化内存管理和计算资源利用,大幅提升了推理性能,尤其是在处理大规模并发请求时效果显著。
- 易于使用:无需修改模型架构,即可在现有的 LLM 上实现高效的推理。- 低成本:通过提高硬件资源的利用率,vLLM 使得大语言模型的部署更为经济实惠。随着 vLLM 对 OpenVINO™ 后端的支持,开发者现在可以利用英特尔硬件平台的优势,进一步提升大语言模型的推理效率。
三、在英特尔® 酷睿™ Ultra 处理器上部署大语言模型英特尔® 酷睿™ Ultra 处理器作为英特尔最新的处理器系列,集成了 CPU、GPU 和 NPU(神经处理单元)三大 AI 引擎,专为终端设备上的 AI 推理计算而设计。这使得它成为部署大语言模型的理想选择,特别是在边缘设备或不联网的环境中。
在开始部署大语言模型之前,我们首先需要搭建一个 OpenVINO™ + vLLM 的开发环境。当前,vLLM 仅支持 Linux 操作系统,因此建议安装 Ubuntu 22.04 LTS 作为开发环境。如果您的开发设备运行的是 Windows 系统,可以通过 Windows Subsystem for Linux (WSL2) 安装 Ubuntu 22.04 LTS。
sudo apt-get update -ysudo apt-get install python3sudo apt-get install python3.10-venvpython3 -m venv vllm_ovsource vllm_ov/bin/activate
在虚拟环境中,克隆 vLLM 的代码仓库并安装所需的依赖项:
git clone https://github.com/vllm-project/vllm.gitcd vllmpip install -r requirements-build.txt --extra-index-url https://download.pytorch.org/whl/cpu
最后,安装支持 OpenVINO™ 后端的 vLLM:
PIP_EXTRA_INDEX_URL="https://download.pytorch.org/whl/cpu https://storage.openvinotoolkit.org/simple/wheels/pre-release" VLLM_TARGET_DEVICE=openvino python -m pip install -v .
至此,OpenVINO™ + vLLM 的开发环境已经搭建完毕,你就可以开始在酷睿™ Ultra 处理器上进行大语言模型的部署了。
vLLM 在结合 OpenVINO™ 后端时,能够通过一系列环境变量来控制其行为,以优化模型的推理性能。例如:
- VLLM_OPENVINO_KVCACHE_SPACE:指定键值缓存的大小,可以根据硬件配置和内存管理需求调整。
- VLLM_OPENVINO_CPU_KV_CACHE_PRECISION:控制 KV 缓存的精度,默认为 FP16 或 BF16,可以选择更高效的 u8 精度。- VLLM_OPENVINO_ENABLE_QUANTIZED_WEIGHTS:启用模型加载阶段的 U8 权重压缩,进一步提升推理性能。在设置完这些环境变量后,可以使用 vLLM 提供的范例程序进行大语言模型的推理计算。以下是一个简单的范例程序调用:
export VLLM_OPENVINO_KVCACHE_SPACE=40export VLLM_OPENVINO_CPU_KV_CACHE_PRECISION=u8export VLLM_OPENVINO_ENABLE_QUANTIZED_WEIGHTS=ONpython3 vllm/examples/offline_inference.py
该程序会下载并运行一个预先优化的模型,展示了在酷睿™ Ultra 处理器上进行高效推理的过程。如果希望使用 ModelScope 中的模型,可以通过简单的代码修改来实现模型的替换和本地化部署。
为了进一步优化推理性能,vLLM 提供了分块预填充功能,可以显著减少推理延迟。通过调整批处理大小(例如设置为 256),用户可以在处理大量并发请求时获得更好的性能表现。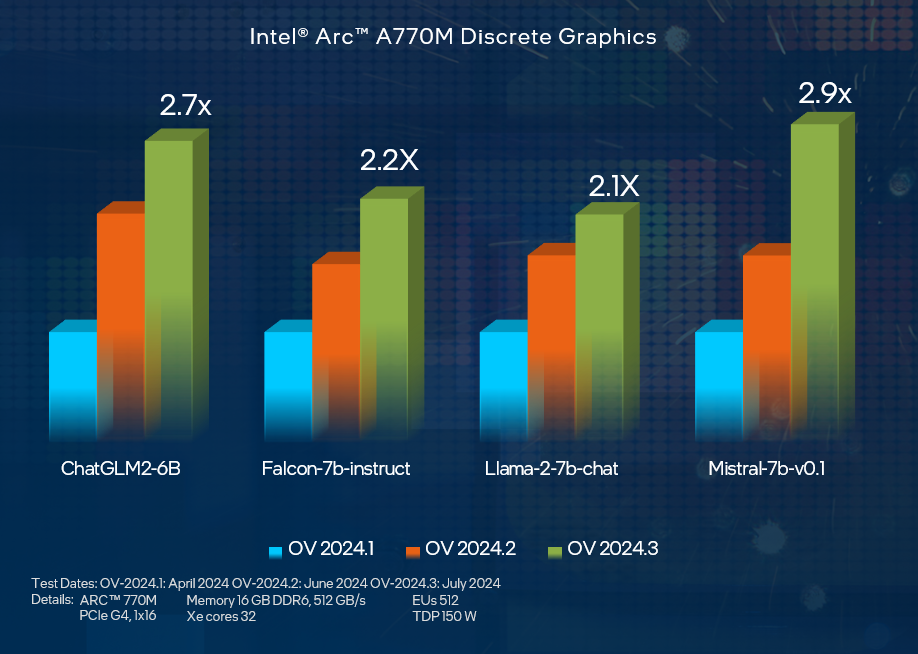
在实际部署中,OpenVINO™ 的优化能力与 vLLM 的高效推理相结合,使得大语言模型可以在酷睿™ Ultra 处理器上稳定运行,并支持更广泛的应用场景。OpenVINO™ 与 vLLM 的结合,为开发者在本地和边缘设备上部署大语言模型提供了一种高效、经济的解决方案。借助英特尔® 酷睿™ Ultra 处理器的强大 AI 引擎,开发者可以充分利用其 CPU、GPU 和 NPU 的计算能力,实现大语言模型的快速推理。在未来,随着更多模型的支持和优化算法的引入,OpenVINO™ + vLLM 的应用场景将更加广泛,为 AI 技术的落地应用带来更多可能性。无论是在物联网设备中实现实时智能,还是在本地设备上部署复杂的语言模型,这一组合都将为开发者提供强大的技术支持。说到这,如果有小伙伴对使用 OpenVINO™ 和 vLLM 进行大语言模型部署感兴趣,特别是想了解如何在 PC 及小型设备上优化和部署这些模型,那么你绝不能错过即将举行的 OpenVINO™ 加速 PC 及小型设备 LLM 性能 主题活动!活动将在 9 月 13 日(周五)下午 13:30-17:00 于北京东城举办,线上线下同步直播。届时,DEVCON 中国 系列工作坊 以“OpenVINO™ 加速 PC 及小型设备 LLM 性能”为中心,邀请7位讲师与大家分享基于 OpenVINO™ 和 AI PC 的最新技术与实战经验,还有动手练习环节帮助你优化自己的 AI 项目。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
