导读 本文将分享数禾科技在 AIGC 辅助营销素材生成方面的工作。
1. 背景介绍
2. 面临挑战
3. 解决思路
4. 未来展望
5. Q&A
分享嘉宾|周伟鹏 上海数禾信息科技有限公司 算法专家
编辑整理|王丽燕
内容校对|李瑶
出品社区|DataFun
背景介绍
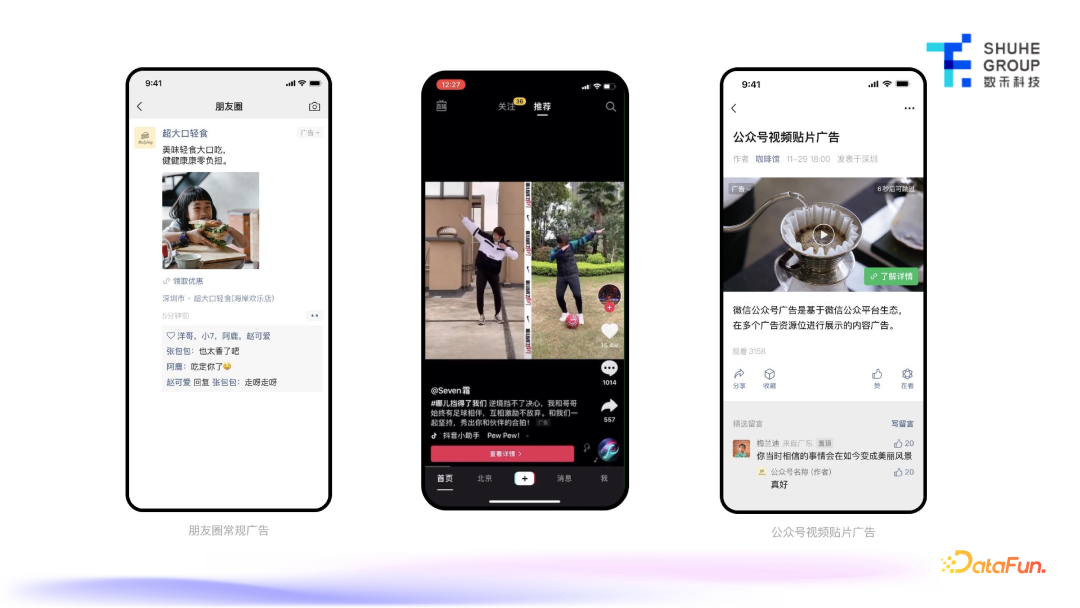
数禾科技是一家互联网金融科技公司,广告营销投放渠道主要依赖各大社交媒体,比如腾讯微信朋友圈、抖音信息流,或者公众号中视频和图片的版位。

上图是投放的素材样例,左图是图片的素材样例,大多会投在公众号文章中间的位置,右图是日常在投的动画类的视频素材的样例。
面临挑战

在腾讯微信朋友圈、抖音、百度、快手等众多投放渠道中,每个月单渠道投放的视频素材量会超过 5000 条,即每天需要产出 170 多条视频素材去做投放;同时图片会有 7000 多条,大多投放在朋友圈或者公众号,并不是所有渠道都会有。这就带来了一些问题,首先是如何产出足够数量的素材,另一方面是当素材多了之后,媒体方会对素材有一些要求,比如新鲜度足够高、不能过多地重复、能够吸引人,因为媒体侧平台不希望自身平台是一个纯广告分发平台,这样就会失去对用户的吸引力。所以素材如何能够在足够数量的情况下,又保证质量过关,是我们主要面临的挑战。
解决思路
接下来从图片素材和视频素材两个方面来分别介绍我们的解决方案。
1. 图片素材

针对图片素材的处理相对比较简单,上图是两个图片素材样例,会有文案或者其他一些固定存在的元素,比如 logo、警示语等。AIGC 能做的主要是生成文案和图片。图片元素像左边素材中间点缀型的 logo,可以通过 AIGC 的方式去生成,并且不断地变化。右图这一类版式素材,主要是背景生成,系统流程示意图如下:
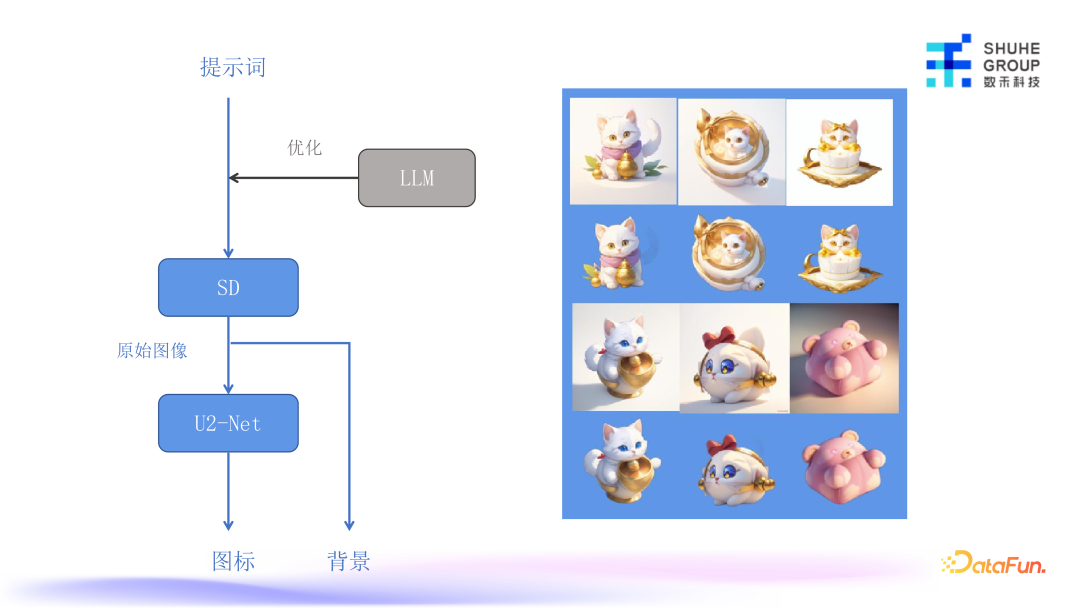
在系统里,素材生成部分的输入是提示词,提示词来源于负责素材生成的人和定期调度的产出提示词的任务,输入提示词后由大模型去做优化,优化后进入模型产出一张原始图片,然后把原始图片通过 U2-Net 抠图模型,将图片变成一个图标,再把图标放到对应的素材上面。如果是背景,最开始会设置好各种尺寸。
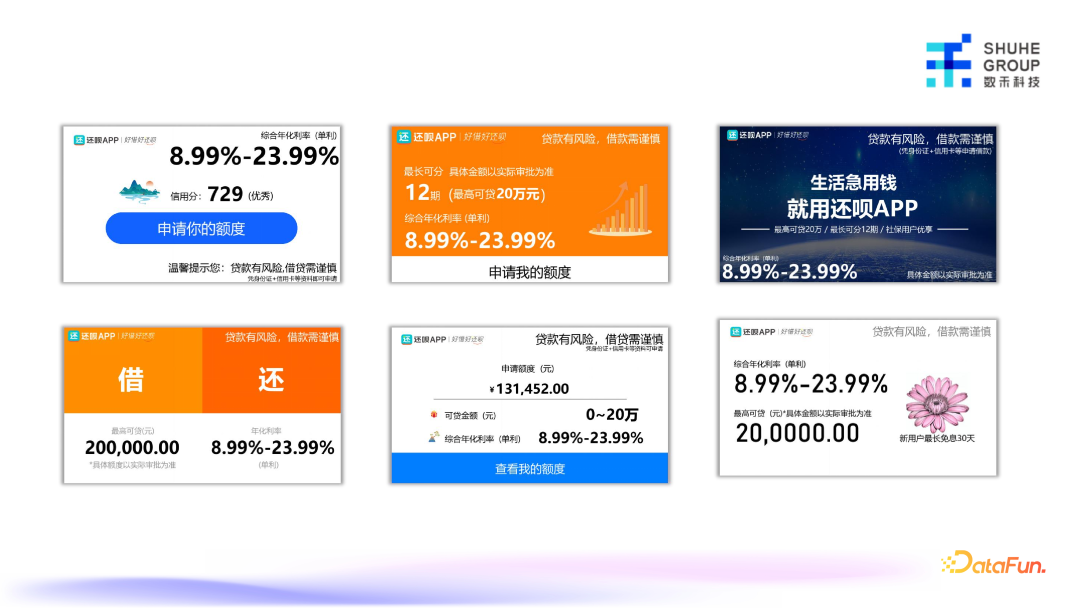
这类素材我们做了几十个不同的图片的版式,并没有完全由 AIGC 来生成,中间会有各个文案、图标、背景的流控,每一类的版式在生成的时候都会去调对应的 AIGC 素材生成服务,比如文案,信用分,图标或者背景等,由 AIGC 模型生成并做一些后处理,应用到不同的模板上。
2. 视频素材

视频是流量最大的一部分素材,包括动画类、街头采访类、单人口播类和情景剧类,我们针对每一类采用不同的方案去逐个做解决。
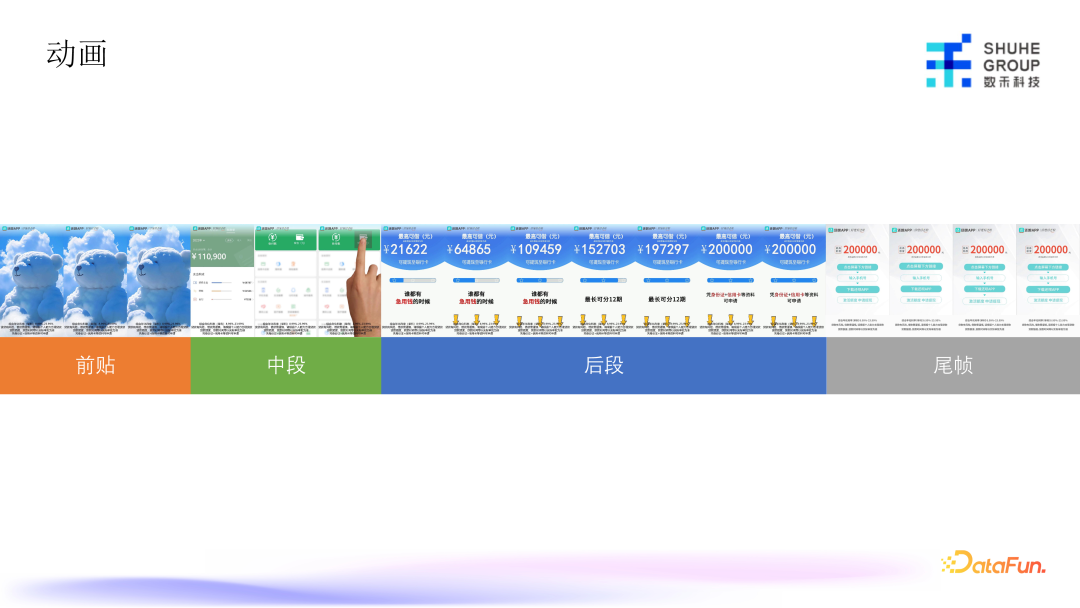
上图是对动画类的视频抽帧、拆解后的示意图,基本上我们在投的大部分的视频都可以拆解为 4 段:前贴、中段、后段和尾帧,每一段关注点不一样。前贴更多展示的是容易吸睛的部分,比如热点视频、猎奇类的图片,或其他容易吸引人看下去的内容;中段主要的作用是直接地表达广告主题;后段以引导为主,更多地是给用户一些更直观的刺激,引导用户去做对应的动作;尾帧是一个固定的部分,会有一些做好的文案、提醒和类似品牌广告类的内容。
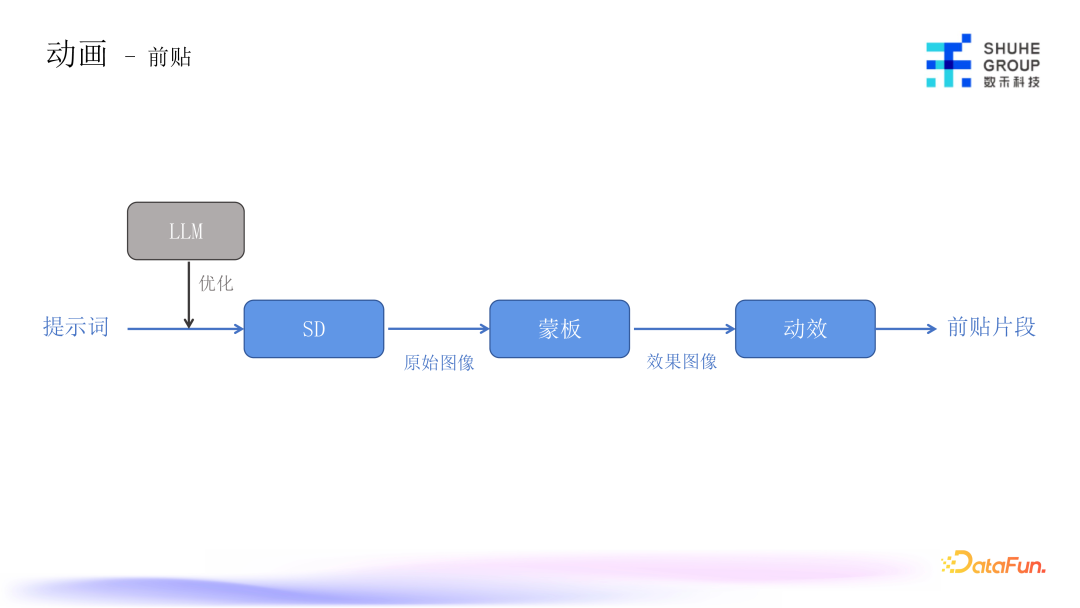
前贴的目标是吸睛,是 AIGC 能够发挥比较大价值的地方。前贴制作流程是从提示词开始,由大模型做简单的提示词优化之后,进到 SD 模型产出初版原始图片,然后根据不同的业务场景加上不同的蒙版,蒙版是比如把它加到微信朋友圈,或转账界面、聊天记录的背景,最后再加上各种动效,就变成了前贴的片段。

上图是系统里 SD 模型生成的原始图片截图,我们内部素材使用者可以去圈选想要的质量高且符合投放场景的图片。
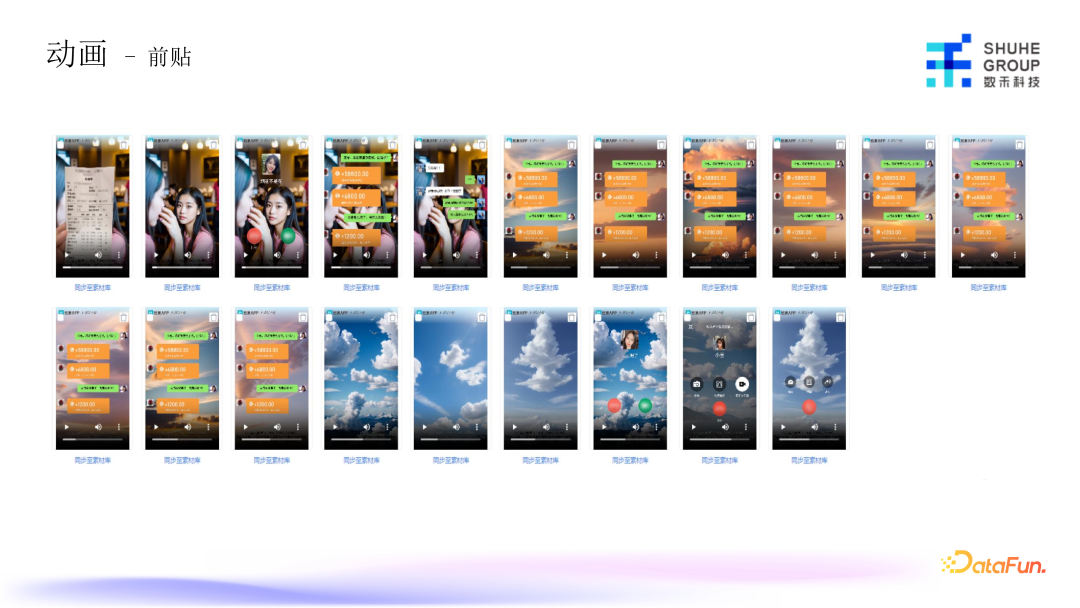
上图是一些蒙版的示例,现金交易的场景会比较多,比如结账、日常转账、借款等场景的蒙版,对目标用户可能会更有吸引力。
中后段部分放在一起处理,虽然各自负责内容不太一样,但表现形式差不多。核心点在于布局,要把最高额度、优惠条件和其他转化引导的内容加上去。但是中后段内容又不能都很一致,不然会影响到在媒体侧的投放。
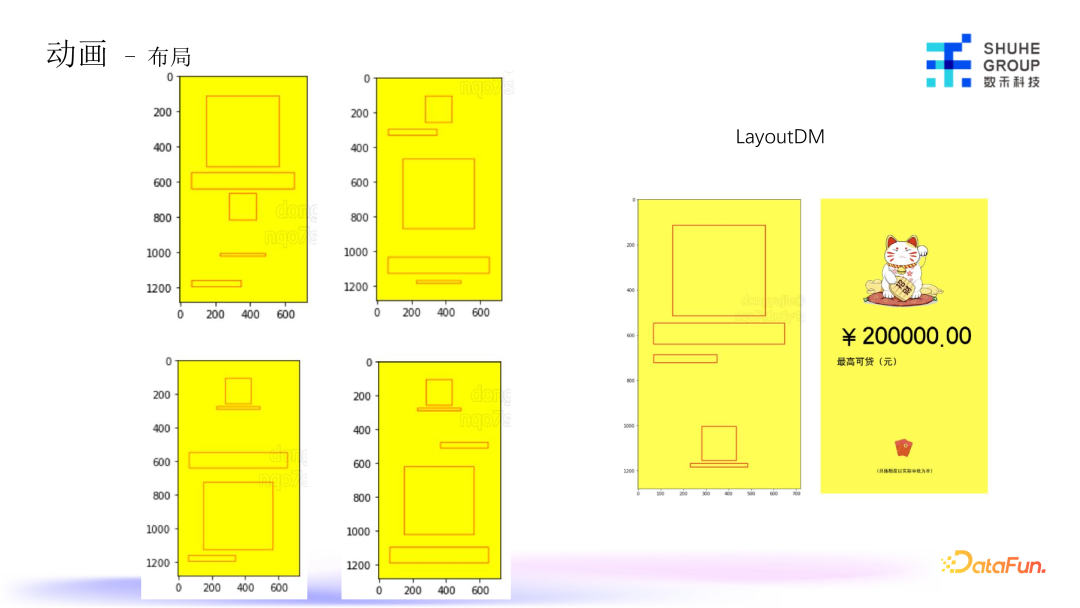
我们使用 LayoutDM 模型去做布局生成,根据我们要用到的文案的内容,生成图标的大小尺寸,以及不同的关注点去做布局,每个前段、中段和后段可能展示的利益点不同,有的可能关注利率,有的关注额度、免息等等,文案内容长短和整体的占位也不一样,所以我们围绕这些去生成很多布局格式,根据生成的布局,最终生成中后段内容。LayoutDM 布局模型在生成的美感上会有一些不适合,因此我们对模型单独做了一些定制,在此不做展开介绍。
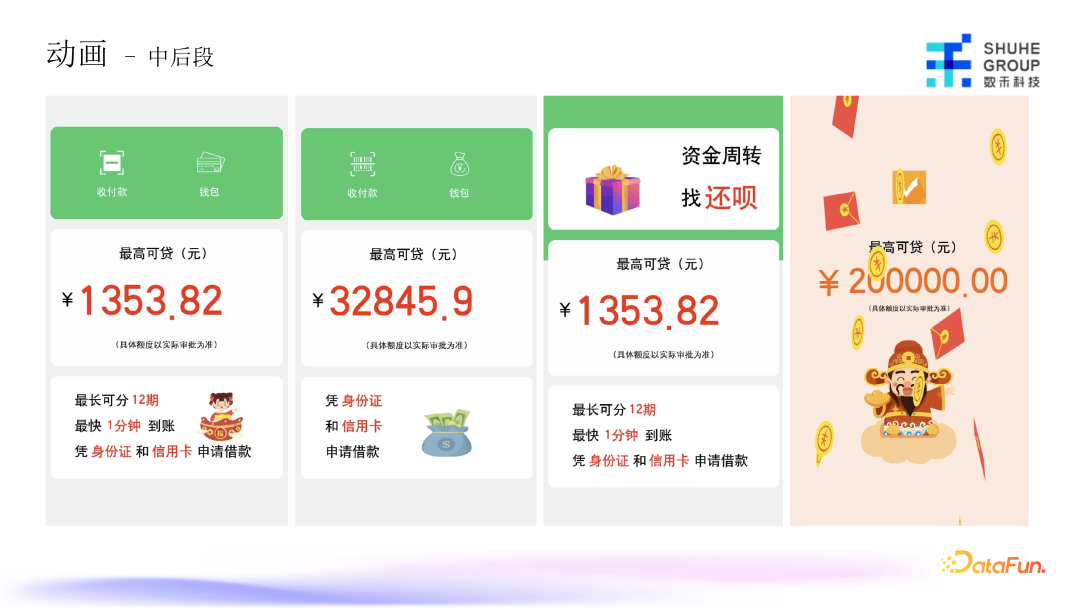
上图示例是最后生成的中后段的效果图,这里面的文案基本不会用大模型生成,因为这一行业的文案很重要,基本上都是由运营同学审核过的确保没问题的几类文案或者不同的几种表述形式,存在库中供选择。图标之类的会由 AIGC 模型生成,最后再加一些特效组成最终的视频。
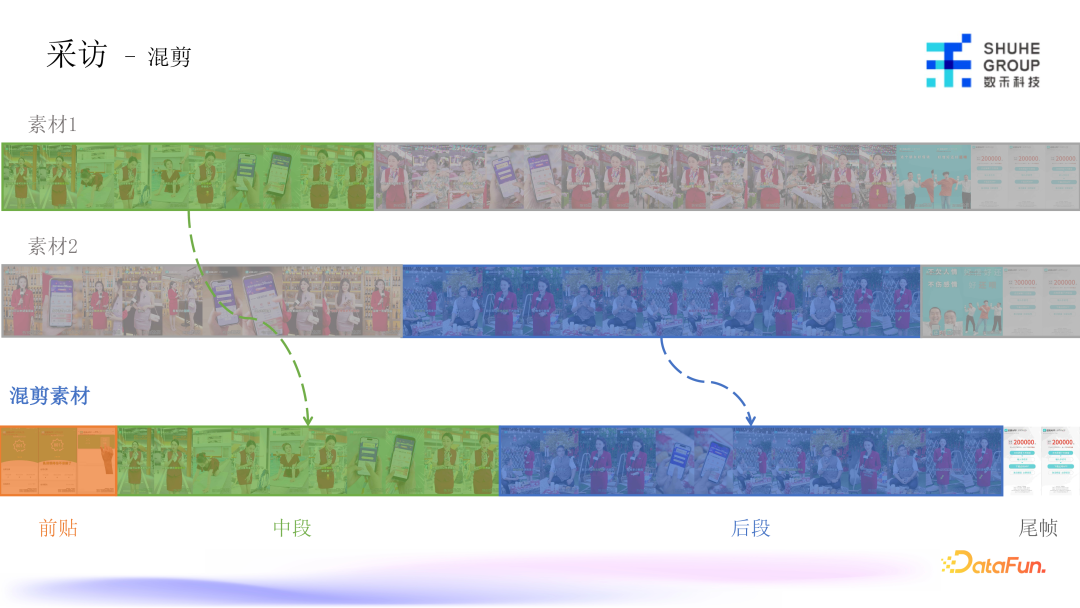
这部分目前还没有特别好地应用 AIGC,当前主要采用混剪的形式,涉及到的算法并不多,主要涉及到场景的识别,把所有采访类的素材,按照不同的场景做拆分,最后拼接时有一个素材选择的模型,把在语义上比较相近的素材筛选出来,最后拼接成一整段采访素材。
采访素材前贴有一部分是由 AIGC 生成,也有一部分是从线上跑量素材的前贴中筛选出来,最后生成一个完整的混剪素材。
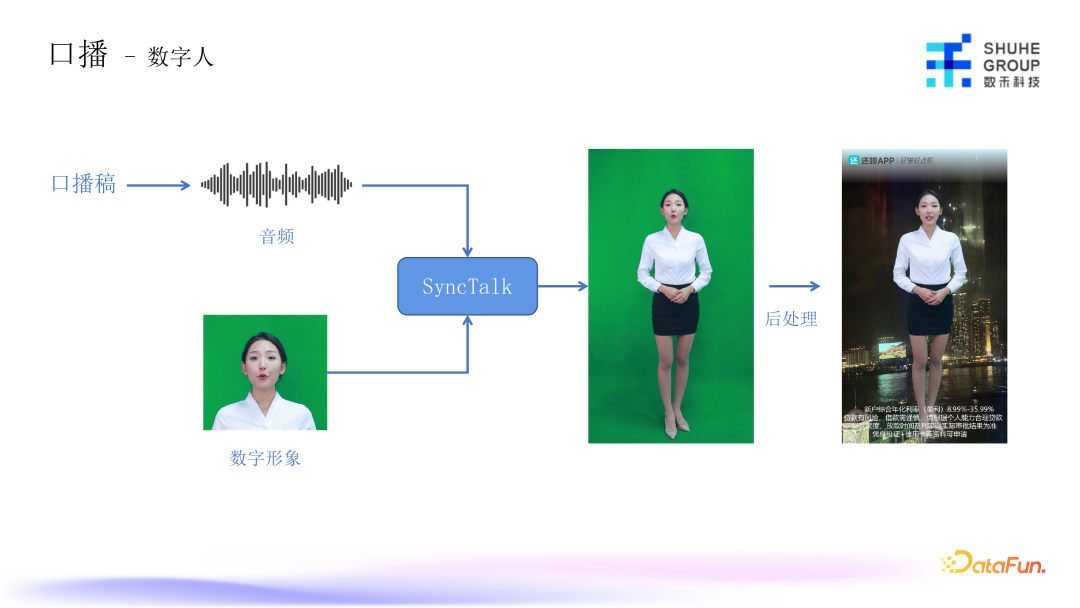
口播目前都是采用数字人的方案,基本的流程图如上图所示,先由代理产生口播稿,再通过 TTS 模型生成音频,最后通过定制的数字形象口播出来。我们采用 Sync
Talk 模型,它是基于 NeRF 的数字人生成模型, 由它来生成一段数字人口播的视频,再给这段视频做一些后处理,比如背景、去噪,和其他一致性优化等,还有特有的一些 logo、警示语等内容,最终拼接成一个完整的数字人口播素材。

情景剧是最难的一个部分,还没有很好的解决方案,目前采用的方案是风格迁移的形式,输入图片和 reference 的风格性的图片,最终产生这个风格的图片。我们使用原来的真人情景剧的素材,直接把每帧图片放到 StyleGAN 中去做对应的风格迁移,然后产出另外一个风格的视频,再去做投放。
目前风格迁移的方案投放效果比较一般,所以还在进一步探索过程中。
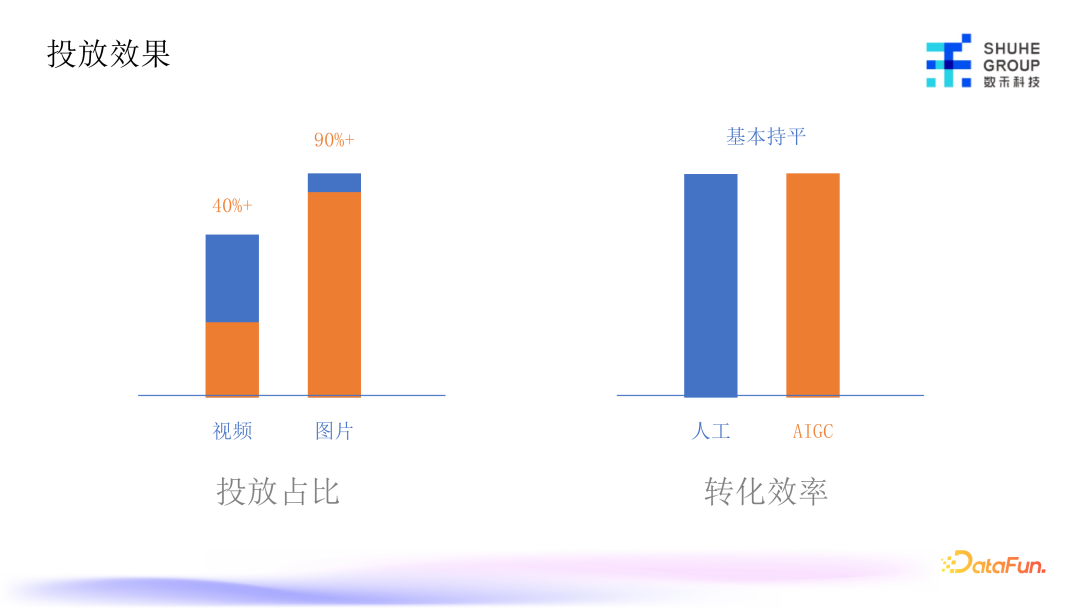
通过上述一系列方案的产出,在单渠道里由 AIGC 产生的视频素材占总素材的 40% 以上,图片素材达到了 90%以上。之所以没有达到 100% 是因为图片素材不只是单张的图片素材,还有很多是组图、九宫格等形式的图片,目前没有在素材产出的体系里,后续会加入。视频则是由于情景剧和口播类,当前只做了一部分,真人类的素材相对难做,所以动画类的素材占比较高。
我们对人工和 AIGC 转化效率进行了大量实验,这里的转化效率是指单素材投放成本和最后转化收益。实验结果表明,我们通过 AIGC 产出的素材的转化效率,达到了与人工持平的水平,所以后面会继续推广 AIGC 产出视频和图片。
未来展望

文生视频,当前没有文生视频端到端的解决方案,因为存在非常多的不可控性,对于素材投放不是很友好,我们希望在未来把文生视频加到素材生产的工作流中。
真人情景剧目前也还没有非常好的方案。未来可能会先去做一些脚本的生成,然后数字人加文生视频做一些剪辑的形式,实现类似真人情景剧效果的视频。
热点追踪,当前视频领域的热点比较难捕捉。因为有些热点可能不是一个词或者一个句式,而可能是一个形象或 IP 等,如何去快速地捕捉这些热点,并且应用到产出的素材中,是我们接下来要探索的一个方向。
Q&A
Q1:在图片生成的时候,如何知道布局是合理的、最优的?
A1:最开始在生成的时候会有一个两难的选择,大部分布局我们希望它规整,但又希望它足够丰富。规整的核心在于对齐,会有居中对齐、居左对齐、居右对齐等指标,比如对齐的边有多少;同时还有丰富度的概念,就是图片最终布局出来,又不是全部居中或居左对齐,所以在损失函数里加了额外的控制项。最终评估布局是不是好,还是由人去打了一些标,去选择哪些是好的布局,哪些是不好的布局,最终去训练布局模型。
A2:文案主要是由我们的策略同学去确定的,因为文案的要求会比较高,比如一些词的应用很讲究,如果用得不太对,会有一些风险或者误导的情况,所以这一部分没有大规模的上 AIGC。
Q3:数字人用的模型是 SyncTalk,这个模型开是开箱即用的吗?还是在上面做了一些定制的优化。
A3:我们是做了一些微调。我们最初尝试直接只用它开箱即用,观察出来的数字人的效果发现,唇形部分的匹配度并不是很高。所以我们又对这个模型做了一些额外的训练,针对各个不同的数字人的形象是有单独做优化的。但如果你对唇形要求没有那么高的话,直接开箱即用也可以,但这里面更多的内容不在于直接去开箱即用的这个模型,其实更多在于前面的数据准备、数据处理的部分,原始的形象有多好。
Q4:针对唇形不对,做了些什么样的一些优化,用什么样的数据进行修正?大概需要多少数据量?
A4:唇形优化有两个部分:一个是对于音频部分的处理,一个是对于视频部分的处理。音频部分,声音可能会有一些噪音、回响,对微调会有很多影响,所以在音频处理前,我们做了非常多的前处理的工作,把音频尽量处理得比较干净。在视频部分也做了很多处理,包括绿幕,不仅能方便换背景,对于做训练也是会有帮助的。我们最后去微调的一版,基本上每一个形象大概会用 30 分钟左右的一段视频做微调,基本上效果就还 OK。

































 粤ICP备17114055号
粤ICP备17114055号