推荐语
掌握AI量化模型在金融数据非平稳性下的应对策略。
核心内容:
1. AI模型面临的数据漂移挑战及其重要性
2. 针对数据漂移的三个主要应对视角:数据分布、模型结构、训练模式
3. 基于改进因子构建指数增强组合的效果测试与业绩表现
杨芳贤
53A创始人/腾讯云(TVP)最具价值专家
金融数据分布在时序上的非平稳性对AI量化模型是关键性挑战,有效应对数据漂移或可提升AI模型的表现。本研究针对AI时序预测模型应对数据漂移的方法进行调研和综述,总结出近年来应对数据漂移的三个主要视角:数据分布、模型结构、训练模式。本研究对市场特征门控模块、注意力特征提取模块在不同特征集上进行多项对比实验,实验结果表明市场特征门控机制、特征提取模型结构等改进均有效。最后基于改进因子尝试进行因子合成并构建指数增强组合,测试结果表明市场特征门控合成因子表现提升显著。
人工智能86:与时偕行:AI模型如何应对数据漂移?金融数据分布在时序上的非平稳性对AI量化模型是关键性挑战,有效应对数据漂移或可提升AI模型的表现。本研究由两部分构成,第一部分针对时序预测问题中数据漂移的应对方法进行调研和综述;第二部分基于AI量化模型应对市场变化的代表性研究进行多方面改进和实证。结果表明,针对特征提取模块结构、门控机制等改进均有效。将传统AI量价因子与市场特征门控因子合成,基于其构建的中证1000指数增强组合2016-12-30至2025-01-27年化超额收益25.6%,信息比率3.24,业绩表现提升显著。应对数据漂移的三个视角:数据分布、模型结构、训练模式本研究针对AI时序预测模型应对数据漂移的方法进行调研和综述。近年来发表于AI顶级会议及期刊的14篇相关研究主要通过三类方法应对数据漂移:其一,通过在模型训练前或训练过程中对非平稳的时间序列数据进行动态调整,化波动为稳定;其二,改进神经网络结构以动态检测和适应数据分布漂移;其三,利用在线学习、元学习、动态模型集成等方式提升模型迭代速度。量化领域相关研究中,Li等(2024)的研究从模型结构出发,做出了两项改进:其一,将市场特征通过门控机制输入神经网络,其二,通过三层注意力机制交叉提取股票时序和截面上的信息,具有较高参考价值。实验结果:市场特征门控机制、特征提取模型结构等改进均有效本研究对市场特征门控模块、注意力特征提取模块在不同特征集上进行多项对比实验。针对市场特征门控模块的实验结果表明,加入市场特征门控模块后因子评价指标及组合业绩均有提升,注意力机制门控表现更优,相比无门控模型中证1000指增组合2016-12-30至2025-01-27区间年化超额收益最高可提升4 pct;针对特征提取模块的实验结果表明,三层注意力特征提取模块相比传统GRU更具优势,三组特征集上预测因子RankIC均值平均可提升0.8 pct。因子相关性测试结果表明,加入门控、修改特征提取模块后因子与改进前因子及传统端到端AI量价因子间相关性均较低。本研究最后基于改进因子尝试进行因子合成并构建指数增强组合。最终综合因子由9个因子等权合成,分别为3个不同频率的端到端AI量价因子以及6个基于注意力门控和不同特征集训练得到的市场特征门控因子。测试结果表明,合成得到综合因子RankIC均值达到14.5%,RankICIR达到1.43,提升显著;基于该综合因子构建中证1000指数增强组合自2016-12-30至2025-01-27年化超额收益25.6%,信息比率3.29,业绩表现优异。01 导读
“凡益之道,与时偕行” —— 《易经》
金融市场庞大复杂,瞬息万变,传统AI模型多基于独立同分布假设构建,当数据分布随着时间动态变化时,若模型依然固守成规,则其预测结果很可能产生偏差。因此,提升AI量化模型表现的关键在于使得模型具有应对数据漂移的能力。本研究首先针对AI时序预测模型应对数据漂移的方法进行广泛的调研和综述。数据漂移及其应对方式在时序预测领域是炙手可热的话题之一,相关研究屡见不鲜。总结而言,应对数据漂移的方式主要分为三类:1、数据分布:在模型训练前/过程中对非平稳的时间序列数据进行动态调整;2、模型结构:改进神经网络结构以动态检测和适应数据分布漂移;3、训练模式:利用在线学习、元学习、动态集成等方式提升模型迭代速度。以上研究中也不乏针对量化领域AI模型做出的改进。其中Li等人于2024年发表于AAAI的会议论文针对股票市场中数据漂移的问题提出了Master模型,主要做出两方面的创新:1、市场特征门控模块:通过门控模块引入市场状态对个股特征进行动态加权;2、多维注意力特征提取模块:构建三层注意力模型对股票截面及时序信息动态建模。本研究在Master模型的基础上,对门控模块、特征提取模块和不同特征集进行多方向改进和实证,结果表明门控机制、注意力特征提取层等改进均有效。最终基于市场特征门控合成因子构建中证1000指数增强组合,业绩得到显著提升。

02 AI模型如何应对数据漂移?
股票收益率预测问题面临的核心挑战之一为股票市场的非平稳性。股票特征与预期收益率之间的关联具有时变特性,即股票市场的统计规律易受到市场风格切换、投资者风险偏好、经济周期波动、货币政策调整、监管规则变更等多重因素影响。而传统AI量化模型多假设数据符合独立同分布,基于历史数据静态建模,在市场状态切换时容易失效。
AI量化模型如何适应市场状态?该问题其实可以拆解为两个部分:
1、时序预测任务中,AI模型如何应对数据漂移?
2、如何将这些方法应用于股票收益预测任务以提升AI量化模型表现?
以上话题是学术界的研究热点,本节中对近年来相关研究进行综述。
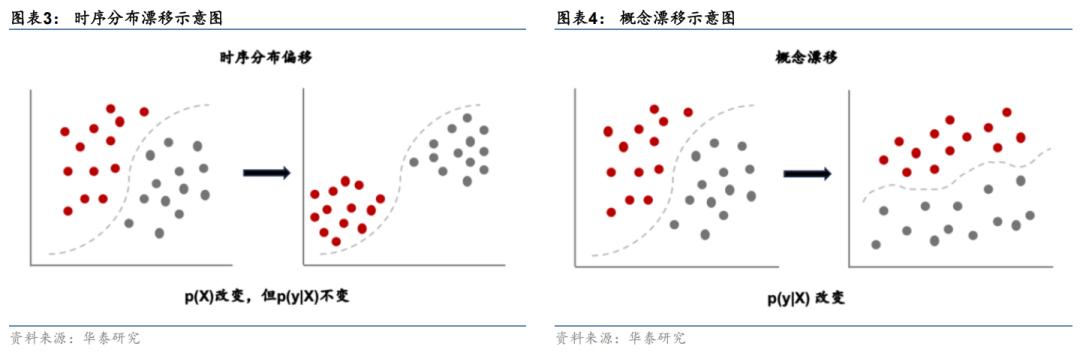
时序预测模型如何应对数据漂移?在时序预测领域,数据的时序分布偏移(Temporal Distribution Shift)和概念漂移(Concept Drift)是影响模型预测准确性的关键因素。两者从不同角度描述了时序数据的非平稳性,其中时序分布偏移特指过去训练数据与未来测试数据之间分布的不一致,也称为“协变量漂移”或“特征漂移”;概念漂移特指输入特征与预测目标之间基础关系随时间的改变。两种漂移现象都会对模型预测造成影响,导致模型预测精度下降,产生误导性结果和决策。
针对数据漂移的问题,学术界提出了多种应对方法,从改进视角出发主要可归纳为数据分布、模型结构、训练模式三个维度。
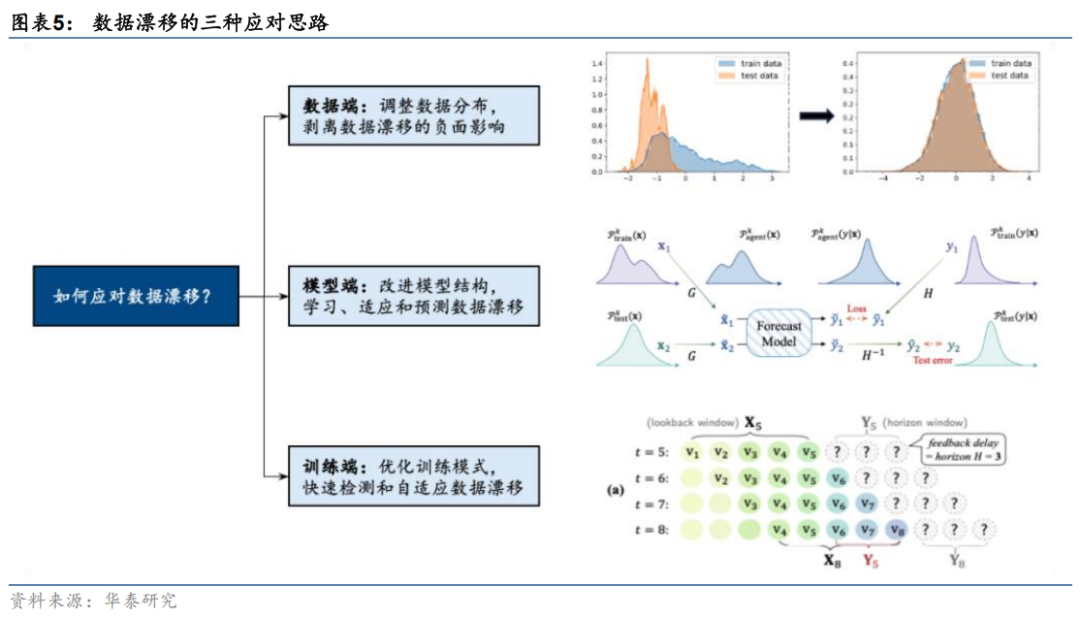
本节对近年来AI顶级会议及期刊中的相关研究进行汇总综述,文献列表如下。
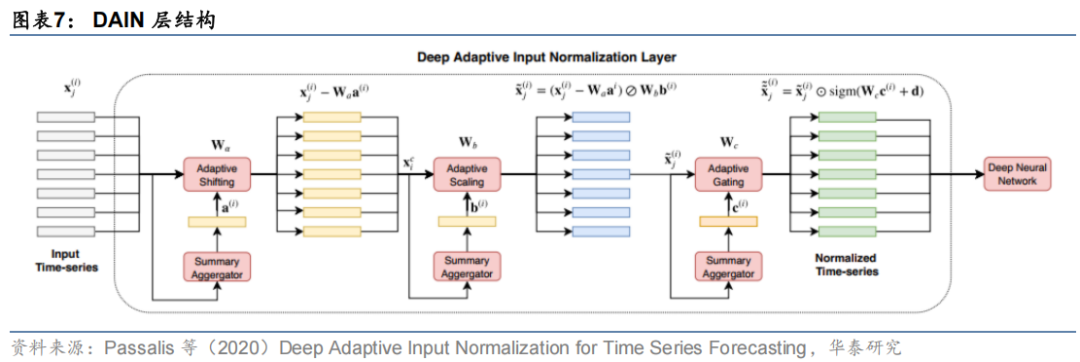
第一类应对方法从数据视角出发,对非平稳的时间序列数据进行调整。Passalis等(2020)构造了一种深度自适应标准化层DAIN(Deep Adaptive Input Normalization),将数据标准化步骤融入到神经网络模型中,构造了一种端到端的自适应标准化模型,在训练的过程中学习时序数据的偏移(shifting)、缩放(scaling)和门控(gating)等标准化规律,并在推理时对输入特征进行自适应的标准化。
Kim等(2021)提出了一种可逆时序标准化方法RevIN(Reversible Instance Normalization),对输入时间序列进行可学习的标准化变换,将非平稳时间序列转化为符合标准分布的时序特征进行训练,对模型预测目标时序分布再进行逆标准化还原原始数据中的时变信息。
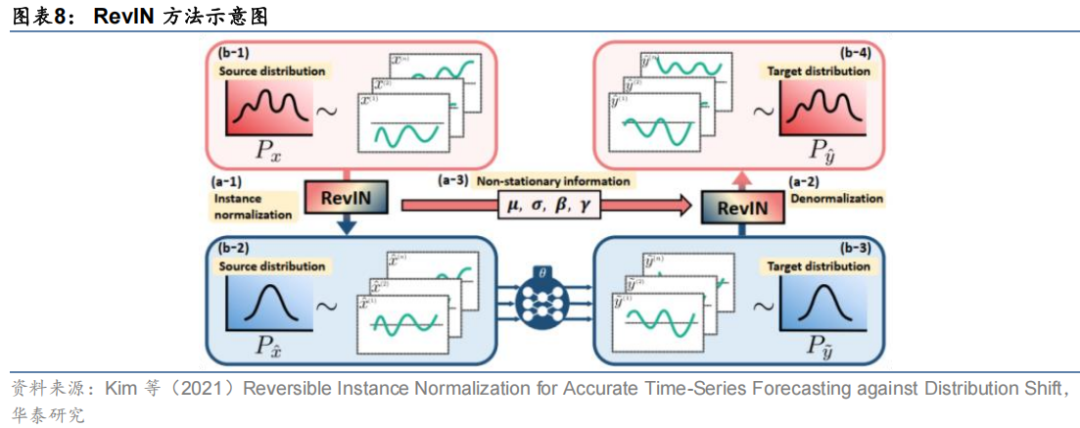
Liu等(2022)在Transformer模块的基础上改进得到了非平稳Transformer。该模型框架同样采用可逆平稳化的方式处理输入输出时间序列,但在模型结构中将Transformer中的注意力机制改进为去平稳化的注意力机制(De-stationary Attention),将非平稳时间序列信息注入神经网络中。
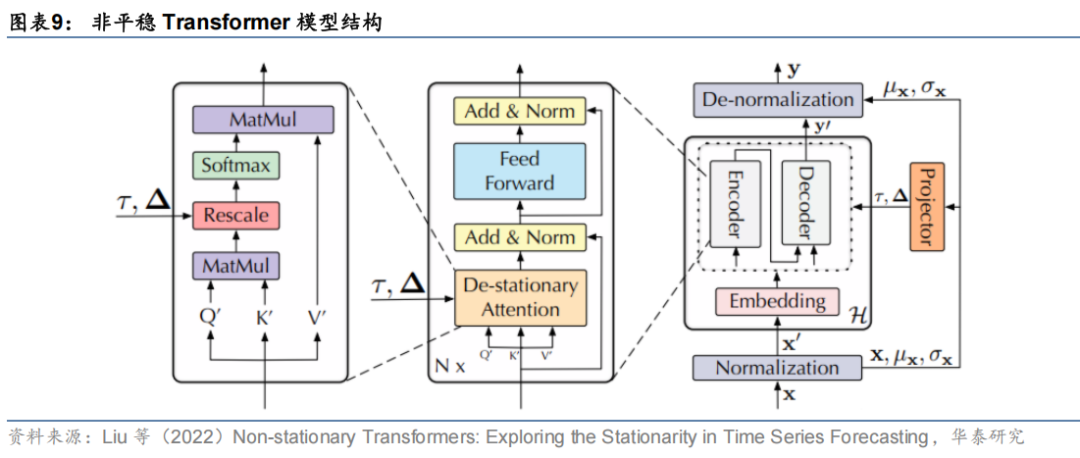
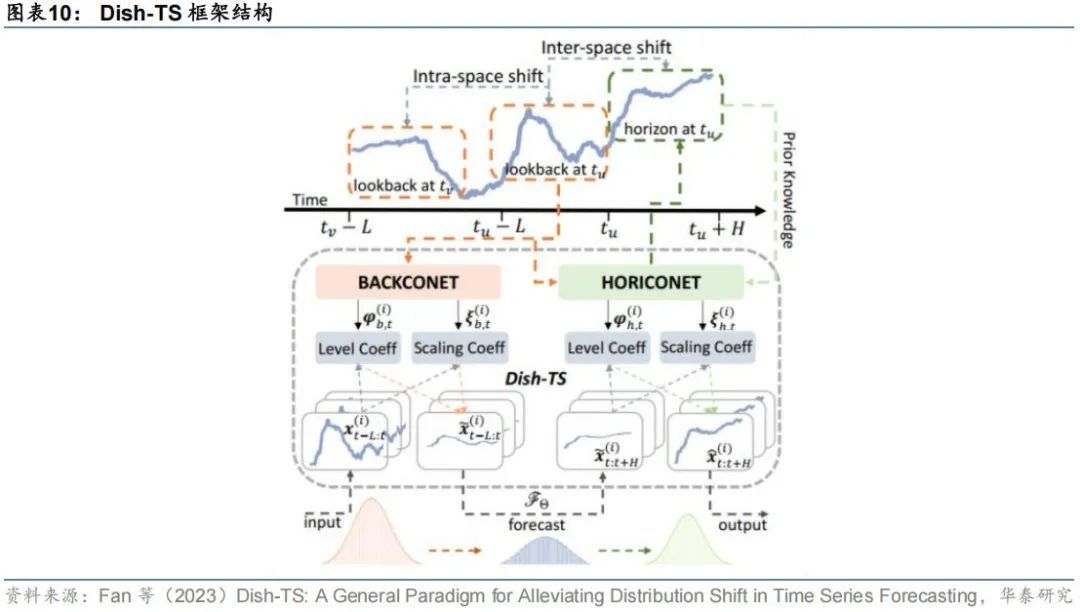
Fan等(2023)提出了一个名为Dish-TS(Distribution shift in Time Series)的通用时序分布自适应调整框架,利用任意形式的系数网络(CONET)捕捉回望窗口和预测窗口时序数据的水平(level)和尺度(scale)特征,在模型训练和推理阶段缓解回望窗口内的数据漂移以及回望窗口与预测窗口间数据漂移现象。
模型结构
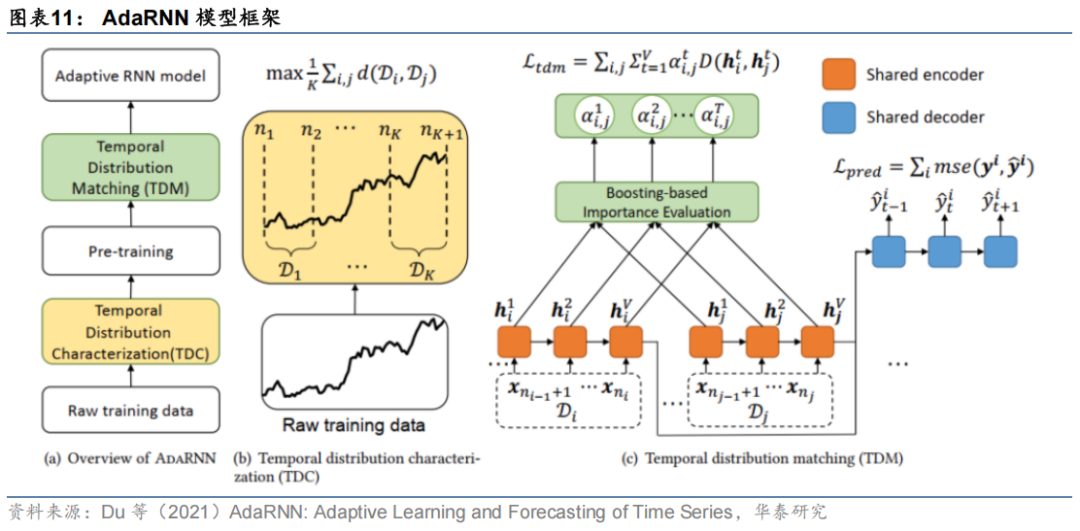
第二种应对方法从模型结构出发,重点在于让模型能学习和预测数据分布的变化,从而适应非平稳的时间序列。其中,Du等(2021)提出了一种网络结构AdaRNN,将迁移学习和循环神经网络相结合。其核心思路分为两步,第一步通过时序相似性量化模块TDC(Temporal Distribution Characterization)将历史时间序列分成分布差异最大的多个小段;第二步通过时序分布匹配模块TDM(Temporal Distribution Matching)基于这些不同分布的序列,让模型学习共性信息,从而在预测有分布变化的数据时,能够更好地根据共性信息实现泛化。
微软亚研院的Li等(2022)提出了DDG-DA模型,该模型认为导致数据分布漂移的某些因素是可预测的,因此其设计了一个预测器用于预测数据未来可能发生的漂移,并根据预测数据分布对训练数据进行重采样生成新的数据集,再基于新数据集进行预测,从而减小训练数据和预测数据间的分布偏差,提升模型表现。

与AdaRNN思路类似,Lu等(2022)提出了一种基于对抗学习的域外表示学习框架DIVERSIFY,该框架优化目标是一个Min-Max问题,一方面让模型自动学习如何将时间序列切分属于多个域的片段,最大化各个域片段的分布差异;另一方面,学习域无关的共性表征,最小化模型在不同域中的预测误差。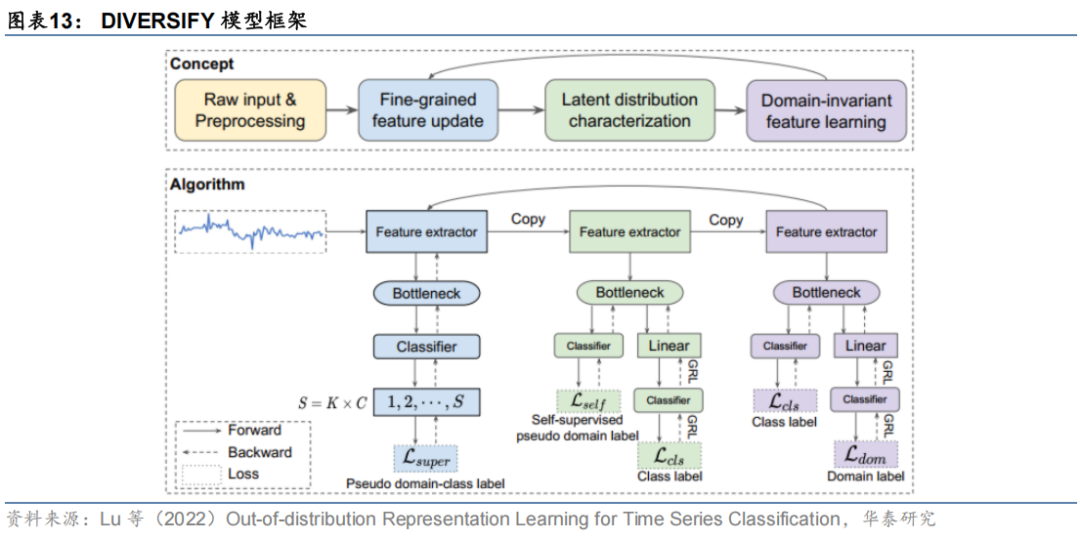
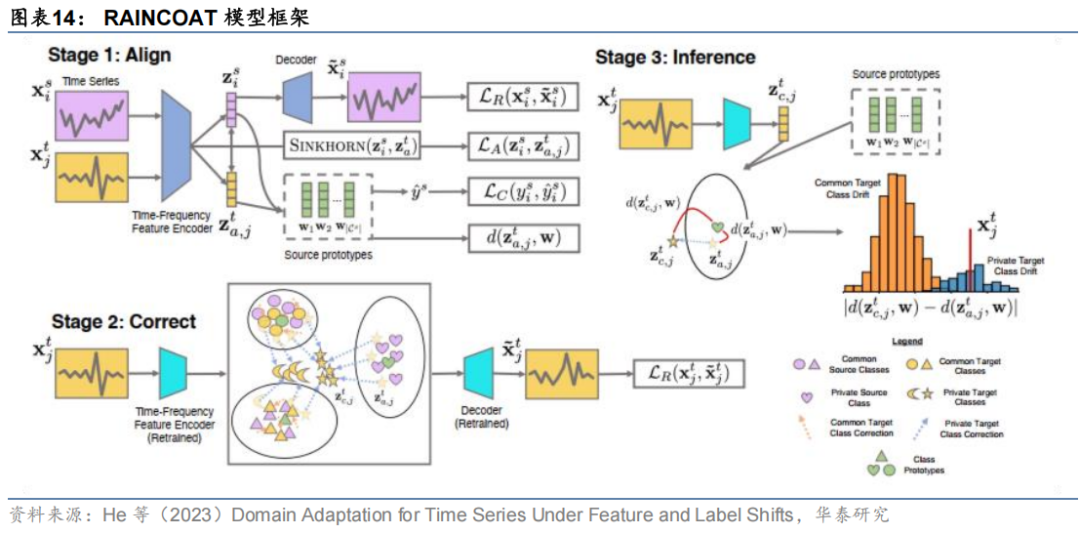
哈佛大学的He等(2023)提出了RAINCOAT(fRequency augmented AlIgN-then-Correct for dOmain Adaptation for Time series)模型,对训练域和预测域时间序列数据分布的时域和频域特征进行建模,通过对齐、修正和推理三个阶段实现域自适应。
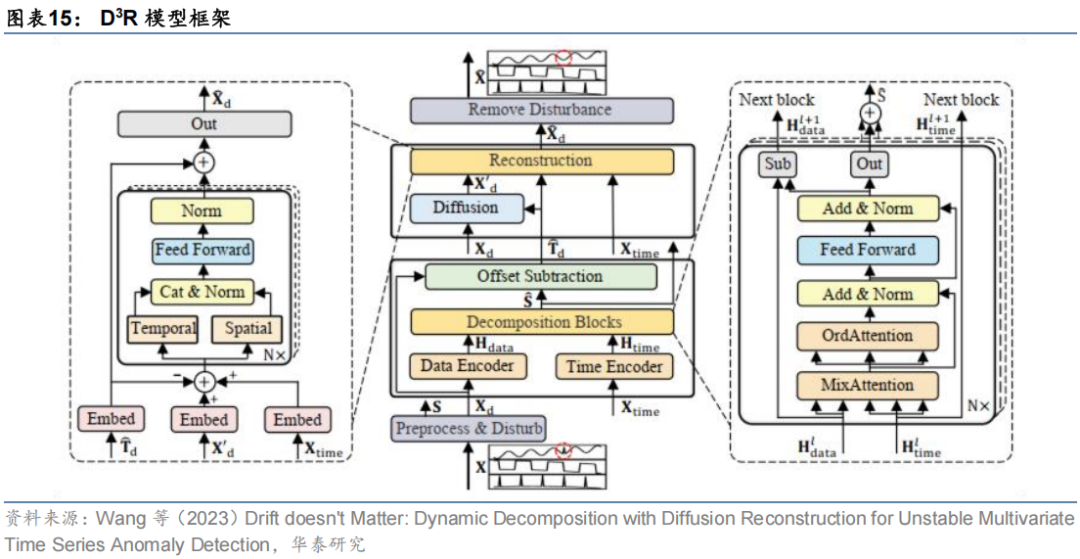
Wang等(2023)针对多变量时序异常检测场景下的数据漂移问题,提出了D³R(Dynamic Decomposition with Diffusion Reconstruction)模型,包含动态分解和扩散重构两个模块。其中动态分解模块针对时序数据漂移现象构建了时序数据-时间戳混合注意力机制,并在训练过程中加入漂移项噪声以增强模型的鲁棒性。
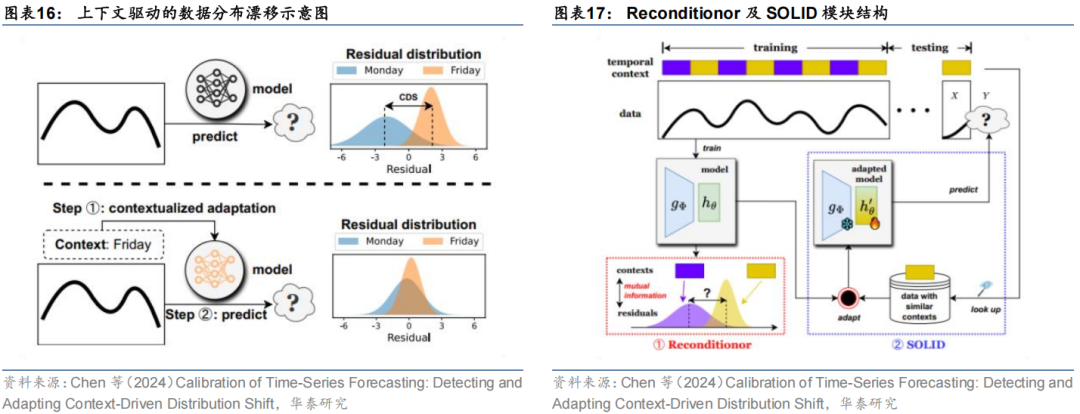
Chen等(2024)提出了一个数据漂移检测和自适应框架,主要包括了Reconditionor(Residual-based context-driven distribution shift detector)和SOLID(Sample-level cOntextuaLIzed aDapter)两个模块,其中Reconditionor模块用于评估预测残差与数据分布之间的互信息,以衡量模型对分布漂移的敏感度,当探测到严重偏移时,SOLID模块则会利用有限步数对模型的预测层进行微调,从而实现最优的偏差方差平衡。
训练模式
第三类应对方法着眼于改进模型训练模式,通过在线学习、元学习等方式让模型更及时准确的适应新数据分布。其中,Pham等(2022)提出FSNet(Fast and Slow learning Network),借鉴互补学习系统(Complementary learning systems theory,CLS)理论,FSNet设计了一个快-慢学习网络用于在线时序预测场景,对于神经网络中的每一层均设计一个快速适应单元和一个联想记忆单元,通过检测两者的梯度相似性动态更新模型参数。
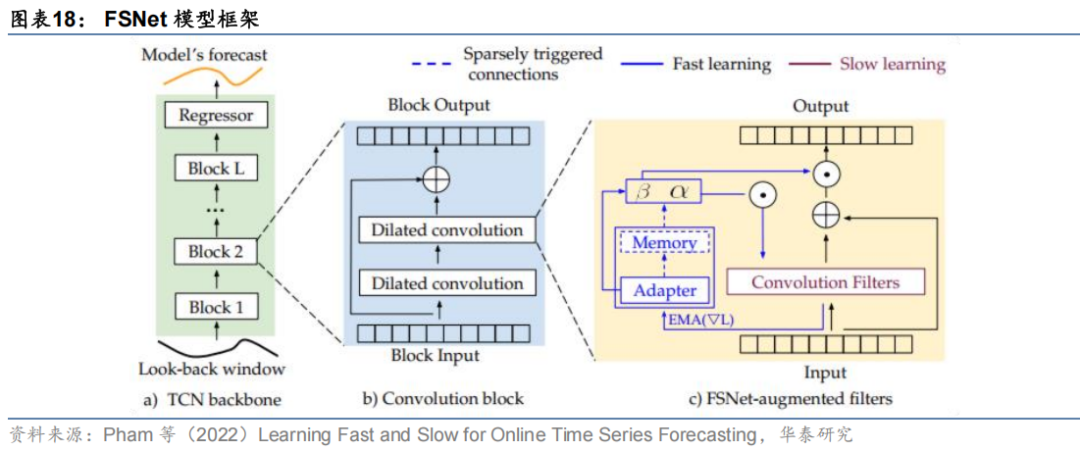
Zhang等(2023)设计了一种双流在线模型集成框架OneNet(Online Ensembling Network),该框架并行维护两个互补的预测模型分别对时序数据的时间维度、变量维度进行建模,同时引入强化学习模块,结合长期权重更新与短期历史反馈,在线调整模型集成权重。
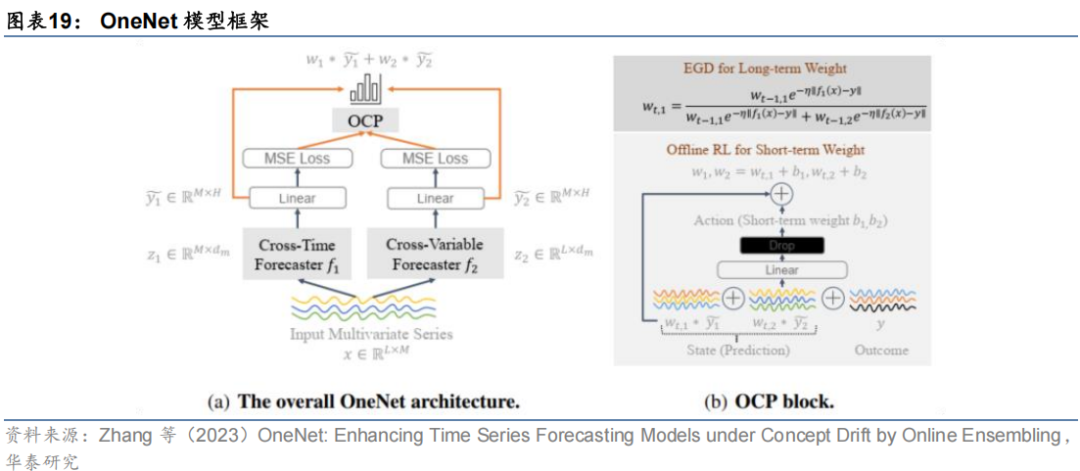
Zhao等(2023)提出了一个元学习框架DoubleAdapt,包含两个基学习器:数据适应模块和模型适应模块。其中数据适应模块的作用类似第一种改进视角,即对数据分布进行动态调整,模型适应模块基于调整后数据优化模型预测准确性;而元学习器的目标即通过多个训练任务优化该两个基学习器的超参数,提升模型在线推理时对新数据分布的适应能力。
Zhao和Shen(2024)提出了一种具有主动适应能力的在线学习框架PROCEED,该框架通过一组编码器捕捉近期训练数据与测试数据间的概念漂移,并将其映射至模型权重之上,从而在模型在线推理时引入数据漂移信息,达到主动自适应调节的效果。

量化选股场景中如何实践?
以上汇总文献主要针对时序预测任务中的数据漂移问题提出了相对通用性的解决方案,除此之外也不乏直接围绕量化选股中股票收益预测任务中数据分布漂移问题所做的研究。近期前沿研究中较有代表性的是由上海交通大学以及阿里的Li等人于2024年发表于AAAI的会议论文,该研究针对股票市场中数据漂移的问题,提出了Master(MArket-guided Stock TransformER)模型,主要做出了两方面的创新:1、市场特征门控模块:将市场状态以宽基指数对应指标的形式显式表达,并通过门控模块输入神经网络,对个股特征进行动态加权;2、多维注意力特征提取模块:模型主体由两层标准自注意力层以及一层简化注意力层堆叠而成,前两层分别提取每只股票时序变化的信息、单个截面各个股票间的信息,最后一层对时序信息进行聚合得到当前时间步的输出。Master模型针对数据分布漂移的解决方案可归类为模型结构的优化。与Chen等(2024)研究思路类似,将市场特征视作模型预测时的上下文信息,在不同的上下文背景(市场环境)下对模型进行微调(调整输入特征权重)。模型整体框架如下。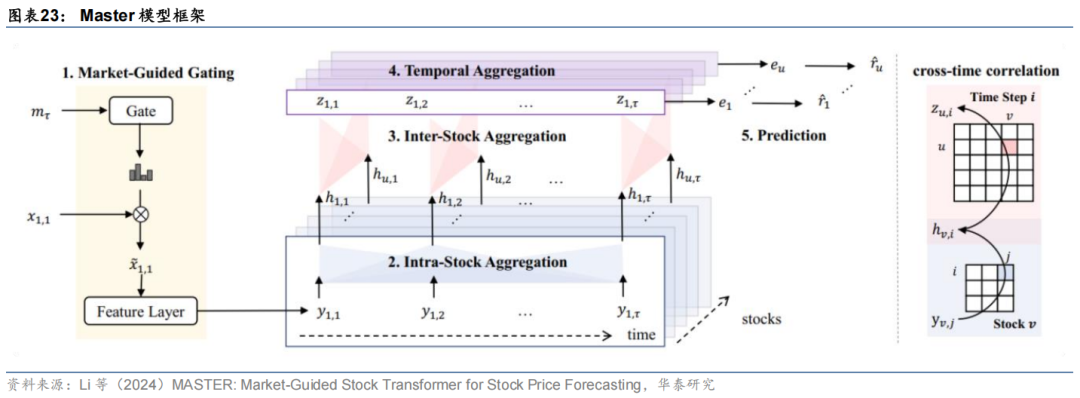
Master模型适应数据漂移的关键在于市场特征门控模块,其底层结构如下。
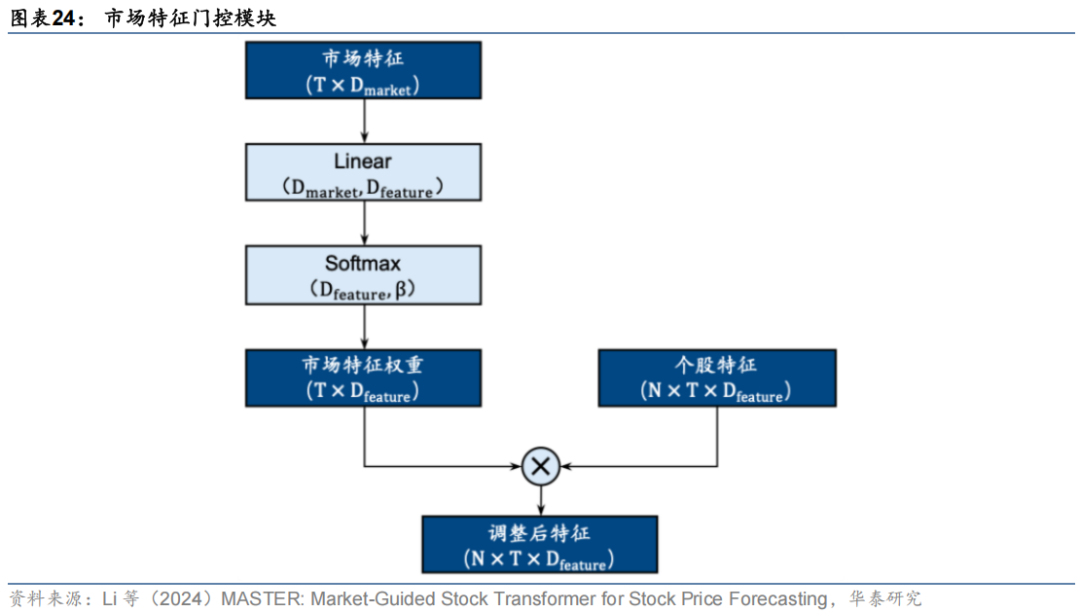
该模块接受两部分输入,分别为市场信息特征和常规的个股特征,其中市场信息特征的维度为, 为时序长度, 为市场特征数。经一层线性层以及Softmax层变换后即可得到归一化的市场特征权重,该权重即不同市场状态下的个股特征重要性。其中Softmax层中还引入了一个额外参数 ,用于控制市场特征对于个股特征的缩放幅度。将得到的市场特征权重与个股特征在后两个维度上直接相乘即可实现根据不同市场状态对个股的各特征权重进行动态调整。模型主体部分也有别于传统Transformer模型。作者手动设计了三层注意力层用于提取和聚合不同维度的特征,各层结构如下。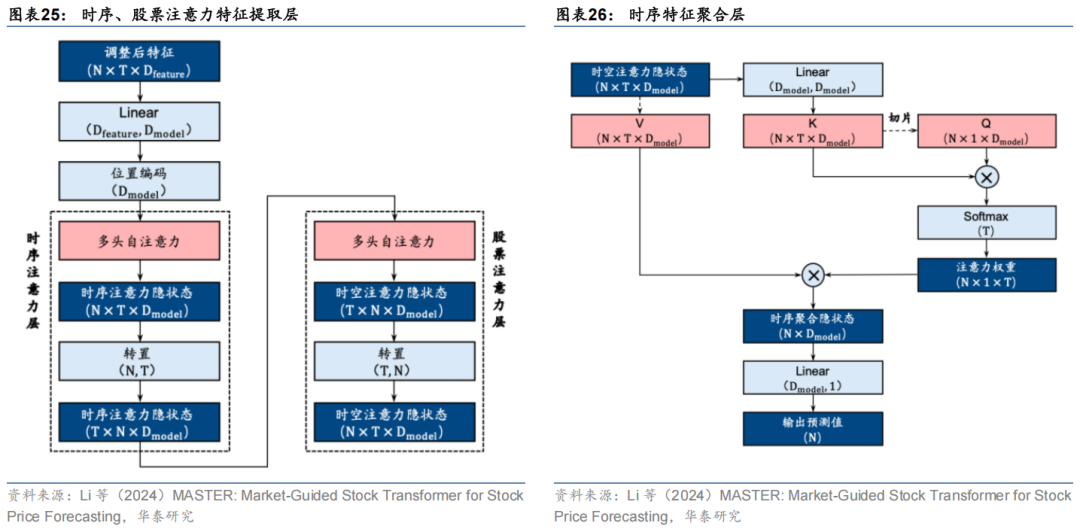
其中前两层采用标准的多头自注意力层,分别提取时序维度 以及股票维度 上的注意力特征,最终输出一个包含时空注意力特征的隐状态层。最后一层以该隐状态作为输入,将该隐状态的最后一个时间步作为查询向量,计算其与其他时间步之间的注意力权重,再与输入隐状态点积,将前两层提取的所有时间步信息聚合到最后一个时间步作为模型输出。
03 方法
Master模型的市场特征门控机制和注意力机制设计逻辑清晰,结构巧妙,均有较大参考价值。本研究借鉴该模型,开展系列实验,尝试提升AI量化模型表现,并应用于指数增强组合的构建。
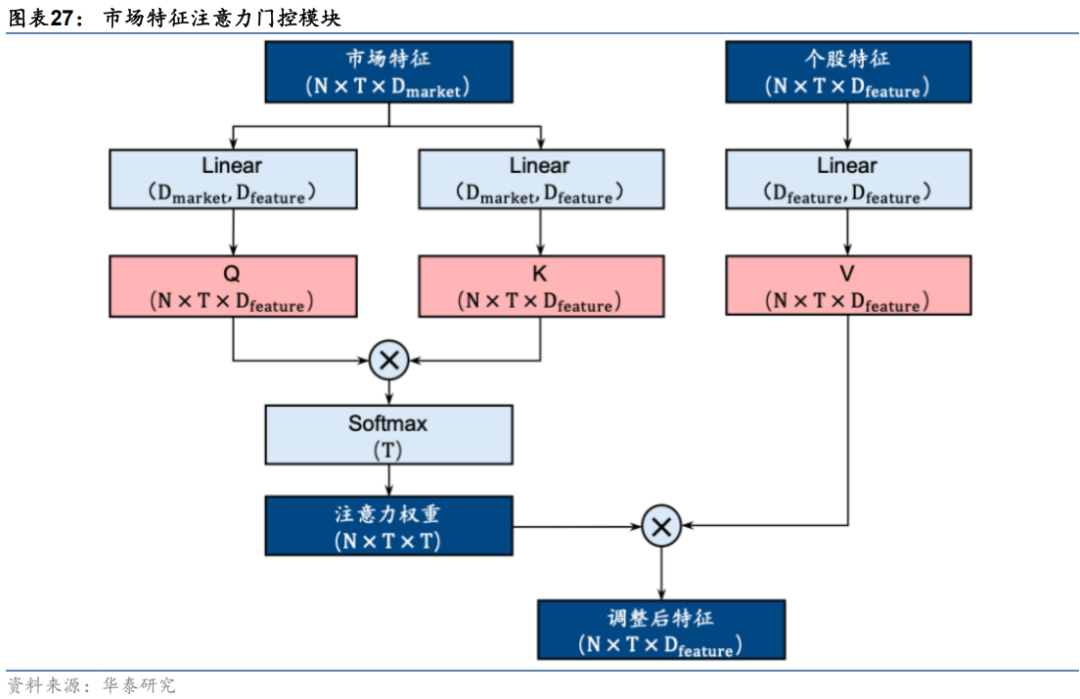
参考Master模型结构设计,本研究拟测试神经网络结构主要包含门控模块和特征提取模块。其中门控模块设计采用两种方案,方案一与原文献保持一致,使用单层线性层提取市场特征权重;方案二将线性层替换为注意力层,将市场特征作为查询向量和键向量,将个股特征作为值向量,利用市场特征输出的注意力权重调整个股特征的重要性,结构如下。
模型主干的特征提取模块同样测试两种方案,方案一与原文献保持一致,即采用三个注意力层提取和聚合;方案二将注意力层替换为华泰金工前期报告中常用且证实有效的GRU模块作为对比,其模型结构如下。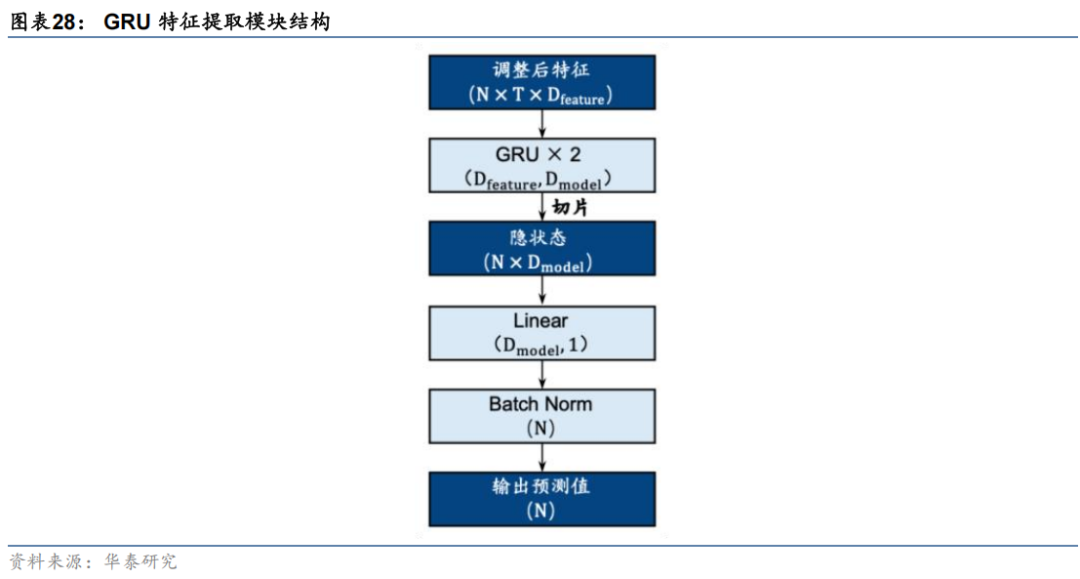
市场特征用于刻画市场当前状态,需选择具有代表性的指标。原论文中作者采用沪深300、中证500以及中证800三个指数的量价指标作为市场特征,然而原论文中的任务选股域仅局限于中证800成分股。因此本研究拟将宽基指数扩展至中证全指域,分别选取沪深300、中证500、中证1000和中证全指四只指数的各21个量价指标共构建84个刻画市场状态的特征。21个量价指标分5组,分别刻画宽基指数近期收益率及成交额的变化及波动,构造方法与原论文保持一致,具体构造细节如下。原论文中个股特征选用微软qlib框架中的预置特征集Alpha158,本研究中在此基础上额外测试两组特征集,分别为基本面+量价特征集Fundamental64以及资金流特征集MoneyFlow93。其中基本面+量价特征集从价值、成长、盈利、预期等多个维度计算64个基本面及量价指标,资金流特征集来自Wind底层表AShareMoneyFlow,包含不同类型投资者、不同交易时间段共93个资金流入流出数据。三组特征集的构造方式如下。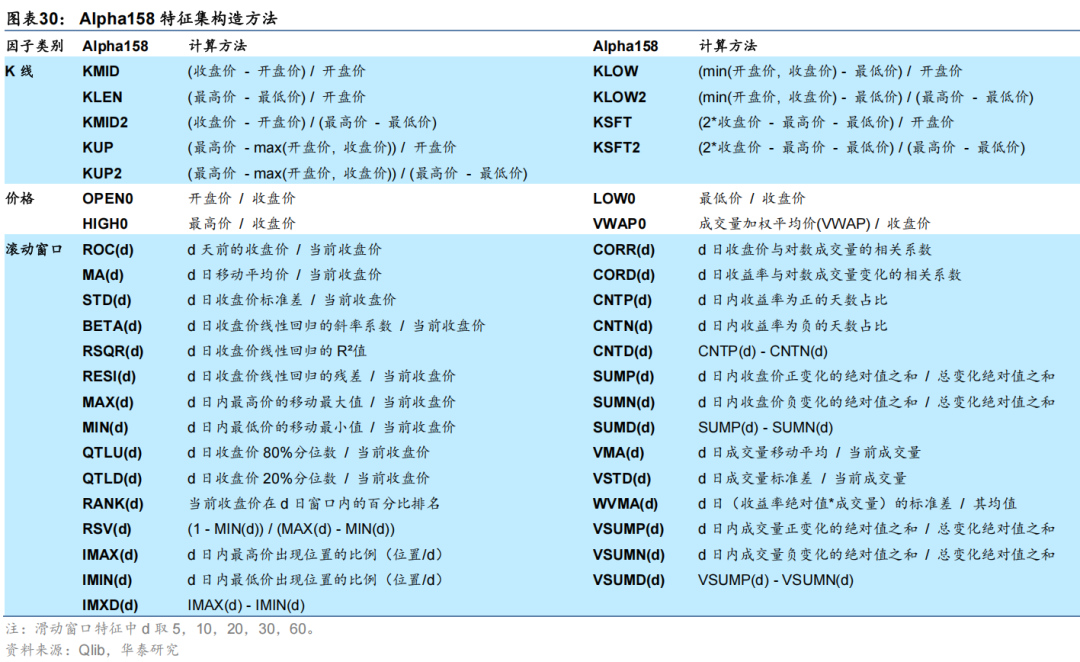

实验最后一步对模型输出预测值进行定量评价,并进一步基于该预测值构建指数增强组合和回测,以上步骤中涉及参数汇总如下。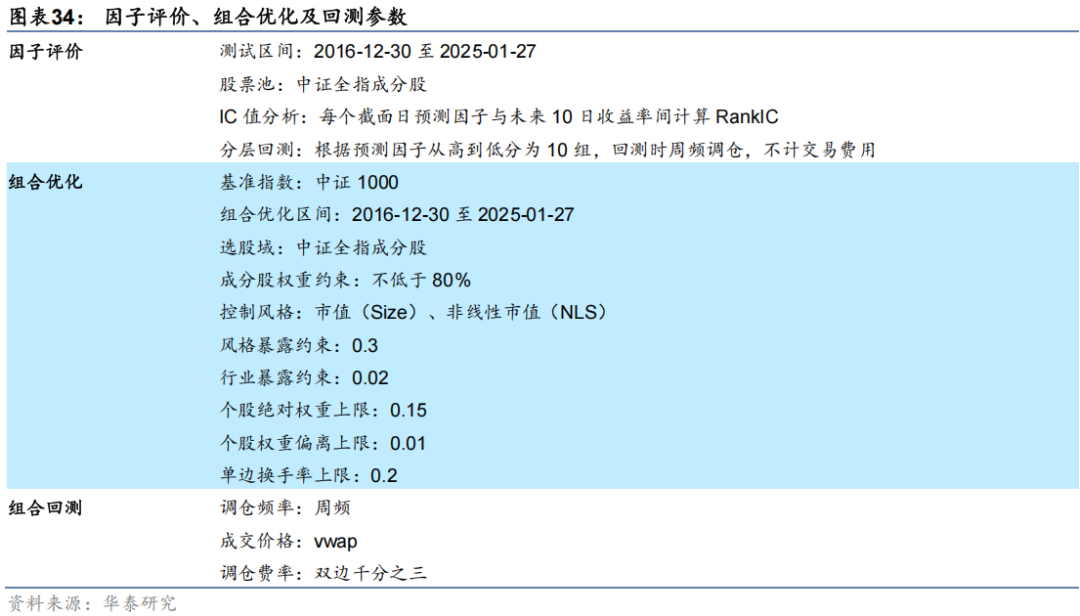
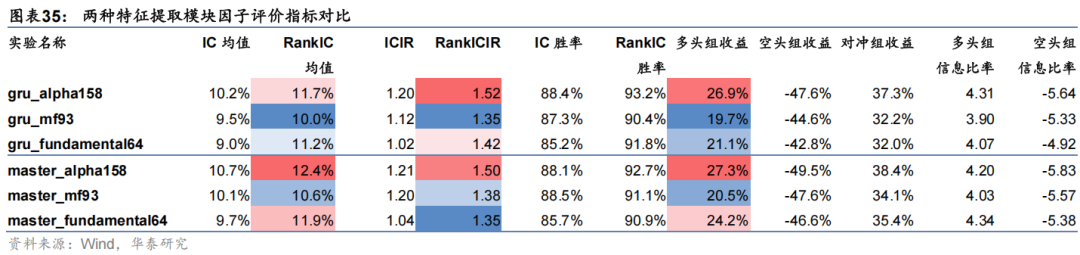
本节对特征提取模块进行对比测试。分别使用GRU和Master模型中的三层注意力神经网络在三组特征集上进行训练,模型均不加入市场特征门控模块,首先对比模型预测因子表现如下。

经组合优化后中证1000指数增强组合业绩对比如下。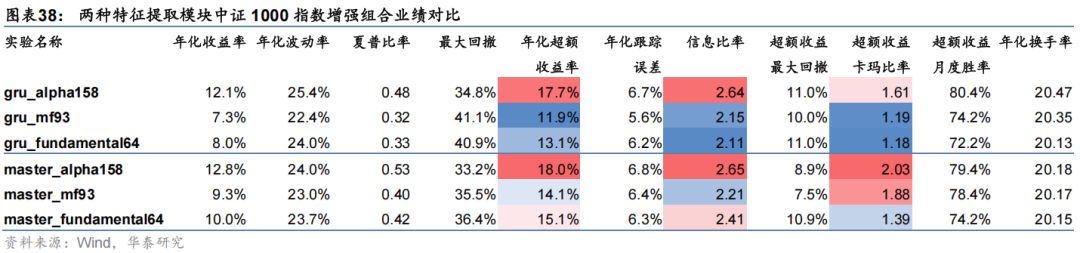
以上结果表明,Master模型中的三层注意力特征提取模块总体效果优于双层GRU:1、从预测因子评价指标看,三层注意力模型在三组数据集上RankIC均值相比GRU模型均可提升约0.7 pct,RankICIR略有降低;2、三层注意力模型在三组数据集上分层回测多头组收益均高于GRU模型,其中在数据集Fundamental64上多头收益提升效果较突出;3、从中证1000指数增强组合业绩看,三层注意力模型在三组数据集上年化超额收益及信息比率等指标均优于GRU模型,对于MoneyFlow93及Fundamental64数据集提升效果突出,全区间年化超额收益可提升约2 pct。本节重点对线性门控模块中缩放系数参数 β 的敏感性进行测试。市场特征对个股特征的调整方法用公式表示为: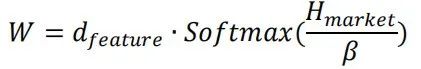
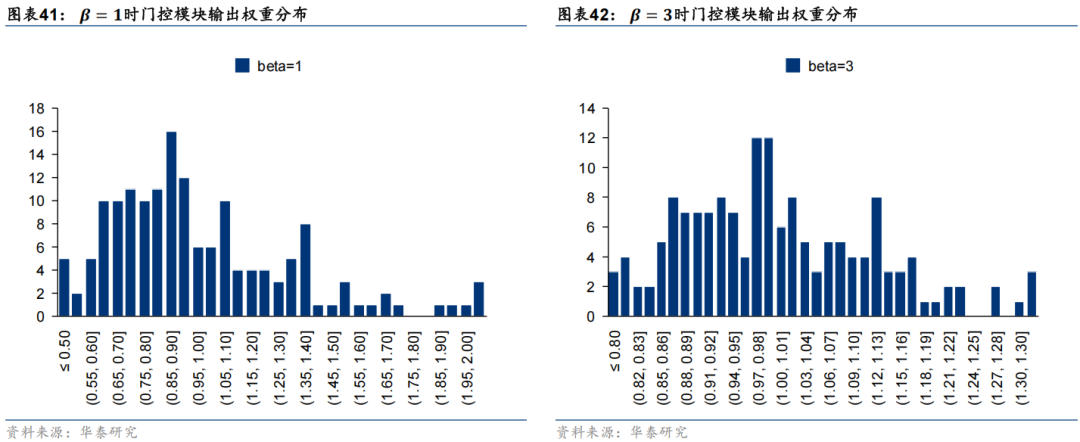
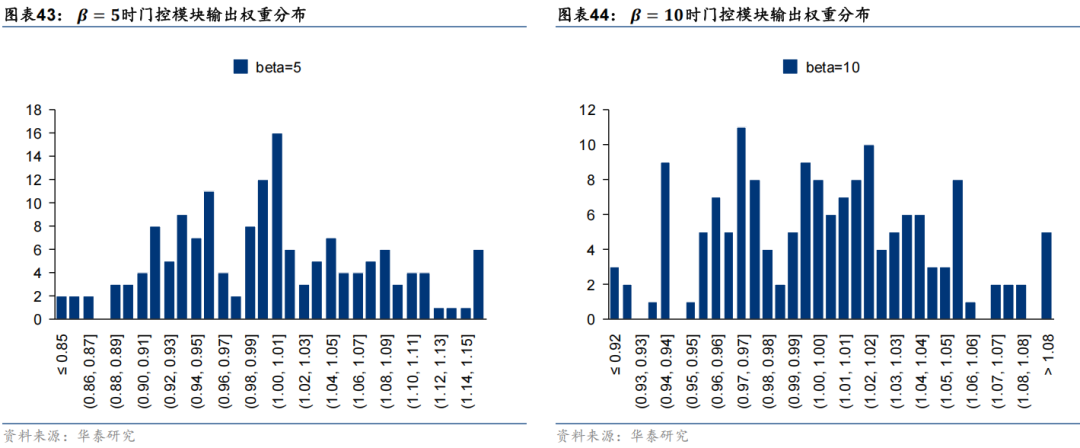
其中 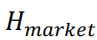 为市场特征经过线性层后的输出,该输出除以 β 之后经过Softmax层即可得到一个归一化的向量,将该权重与特征数相乘即可得到一个均值为1的权重向量,即可视为对于每个特征的缩放系数。由此可知,β 参数越大,最终输出权重越均匀,市场特征对于个股特征的调整幅度也越小。本节基于GRU模型和Alpha158特征集进行对比实验,其中门控模块中缩放系数参数 β 分别取1、3、5、10,基线模型为移除门控模块后的GRU模型,实验结果如下。首先观察不同缩放系数参数 β 下门控模块输出权重的分布,可以发现,β 取值为1时输出缩放系数方差较大,部分特征会得到2倍以上的放大;随着 β 取值增大,门控模块输出缩放系数取值范围对应缩小,当 β 取10时输出缩放系数基本集中在0.95至1.05之间。
为市场特征经过线性层后的输出,该输出除以 β 之后经过Softmax层即可得到一个归一化的向量,将该权重与特征数相乘即可得到一个均值为1的权重向量,即可视为对于每个特征的缩放系数。由此可知,β 参数越大,最终输出权重越均匀,市场特征对于个股特征的调整幅度也越小。本节基于GRU模型和Alpha158特征集进行对比实验,其中门控模块中缩放系数参数 β 分别取1、3、5、10,基线模型为移除门控模块后的GRU模型,实验结果如下。首先观察不同缩放系数参数 β 下门控模块输出权重的分布,可以发现,β 取值为1时输出缩放系数方差较大,部分特征会得到2倍以上的放大;随着 β 取值增大,门控模块输出缩放系数取值范围对应缩小,当 β 取10时输出缩放系数基本集中在0.95至1.05之间。
5组模型预测因子评价指标汇总如下。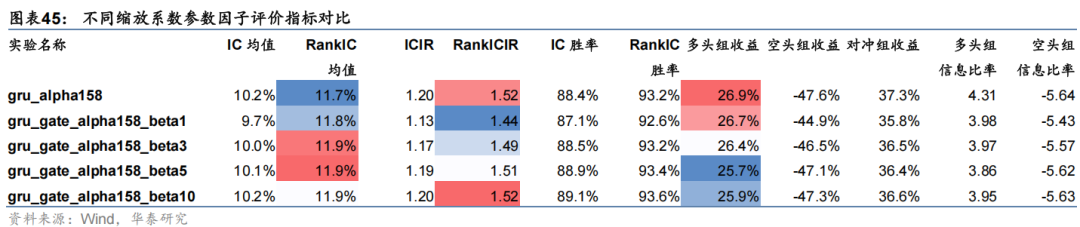
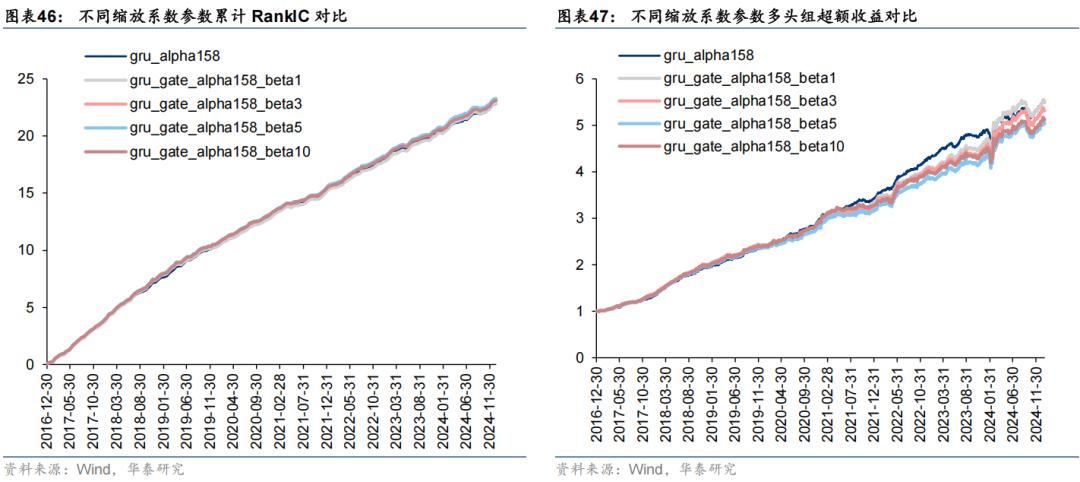
经组合优化后中证1000指数增强组合业绩对比如下。
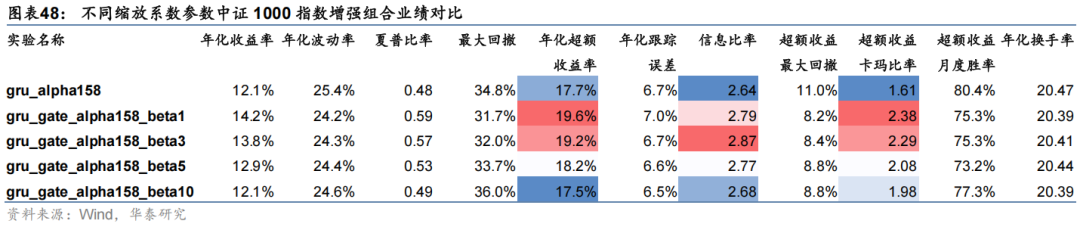

对比以上结果发现,β 取值在1到3时模型表现较优。具体来说:1、从模型预测因子RankIC角度看,加入门控机制后均有所提升,且随着 β 增大逐步提升,β 取5时最高,不过RankICIR有所降低;2、从中证1000指数增强组合业绩看,加入门控机制后年化超额收益及信息比率均有显著提升,β 取1时年化超额收益最高,β 取3时信息比率最高;3、加入门控机制后超额收益最大回撤均得到了较好控制,从11%降低到8%左右,说明引入市场信息确实可提升模型对市场环境的适应性,一定程度上避免大幅回撤。本节重点对比线性层门控模块与注意力机制门控模块表现。根据上节结论,本节线性层门控模块中缩放系数参数 β 设置为3。本节基于GRU和三层注意力特征提取模块,分别搭配线性层门控模块和注意力机制门控模块进行实验,在Alpha158,MoneyFlow93和Fundamental64三组特征集上进行测试。首先对比模型预测因子评价指标如下。
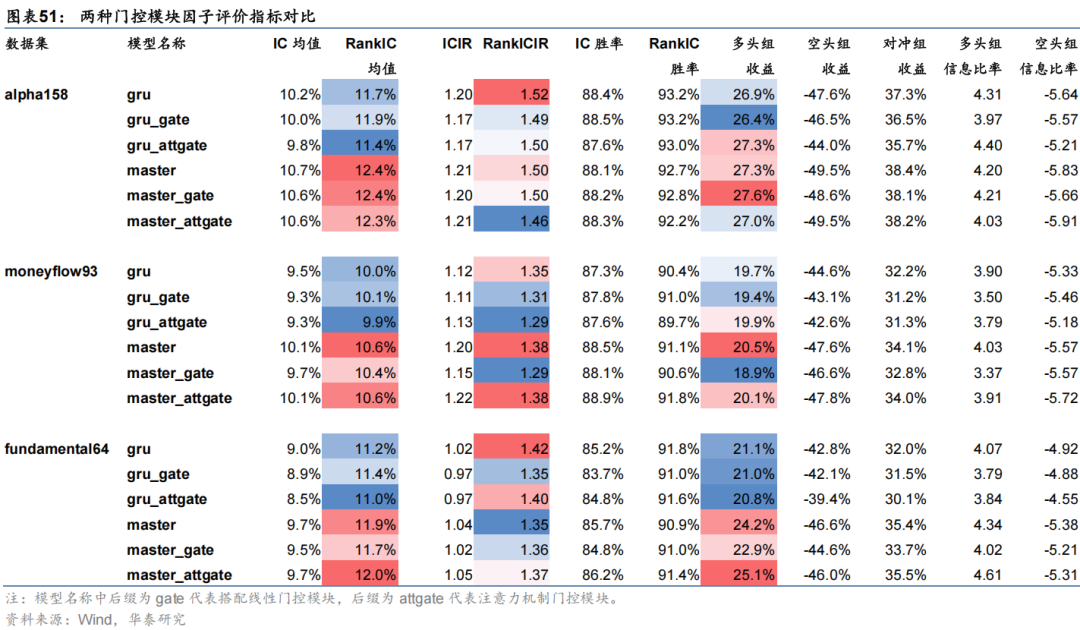
经组合优化后中证1000指数增强组合业绩对比如下。

从以上结果可知,线性门控模块和注意力门控模块均有效,其中注意力门控模块对应组合业绩表现有显著提升,具体来说:
1、从因子评价指标看,线性门控模块和注意力门控模块孰优孰劣并无确定性结论。从RankIC看,对于GRU模型,线性门控模块在三组数据集上均表现最好,而对于Master模型,注意力门控模块综合表现较优。
2、从中证1000组合业绩看,注意力门控模块综合表现占优。除Master模型在资金流数据集上表现一般之外,其余情况下注意力门控模块对应组合年化超额收益率和信息比率指标均最高,相比未加门控机制模型年化超额收益率可提升1至4 pct,信息比率可提升0.1至0.5的水平。
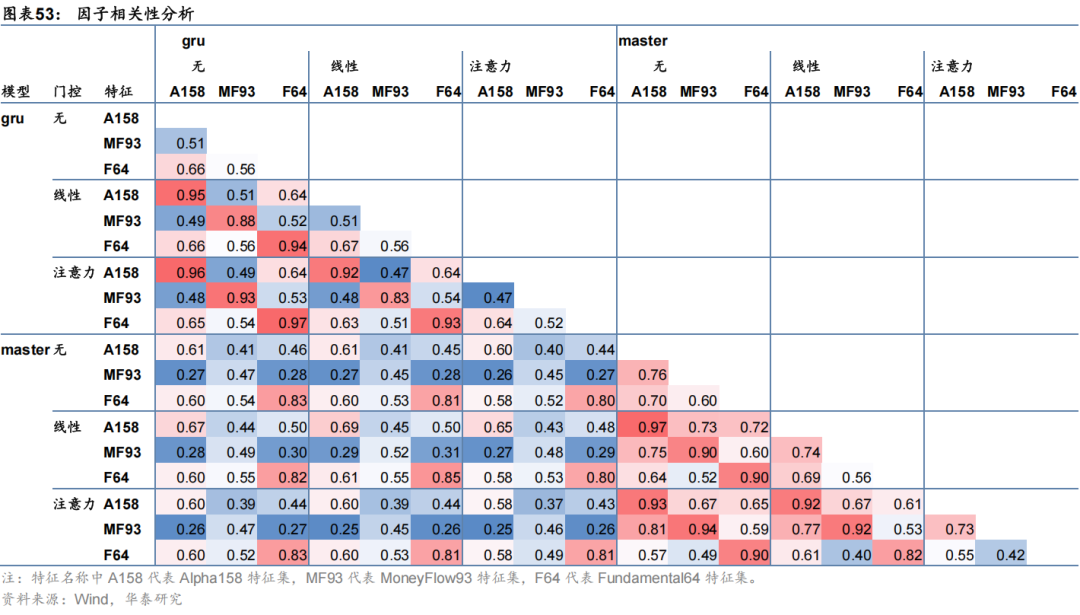
因子相关性分析
本节对加入门控机制前后模型输出预测因子间相关性进行对比。选取因子包括两种特征提取模块在不加门控、线性门控和注意力门控的情况下在三组特征集上训练得到的因子。
华泰金工前期报告《神经网络多频率因子挖掘模型》(2023-05-11)中尝试构建神经网络端到端因子挖掘模型,该模型输出的日K线、周K线、月K线因子与以上因子相关性也进行测试,结果如下。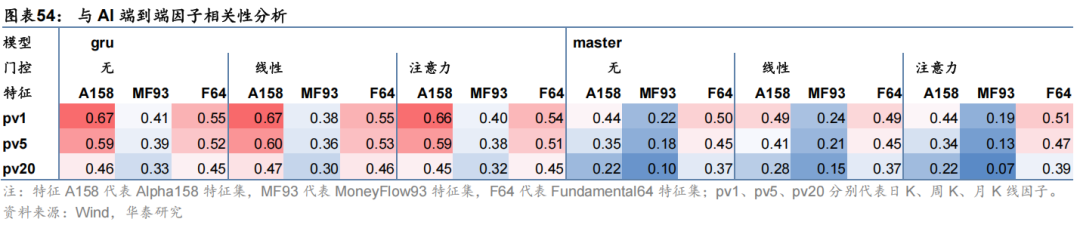
可以发现,不同数据集因子相关性较低,GRU模型与Master模型因子相关性同样也较低,普遍在0.6左右;同模型同数据集不同门控模块因子相关性较高,普遍高于0.9;另外本文测试因子与AI端到端因子相关性普遍较低,大多数不超过0.5。
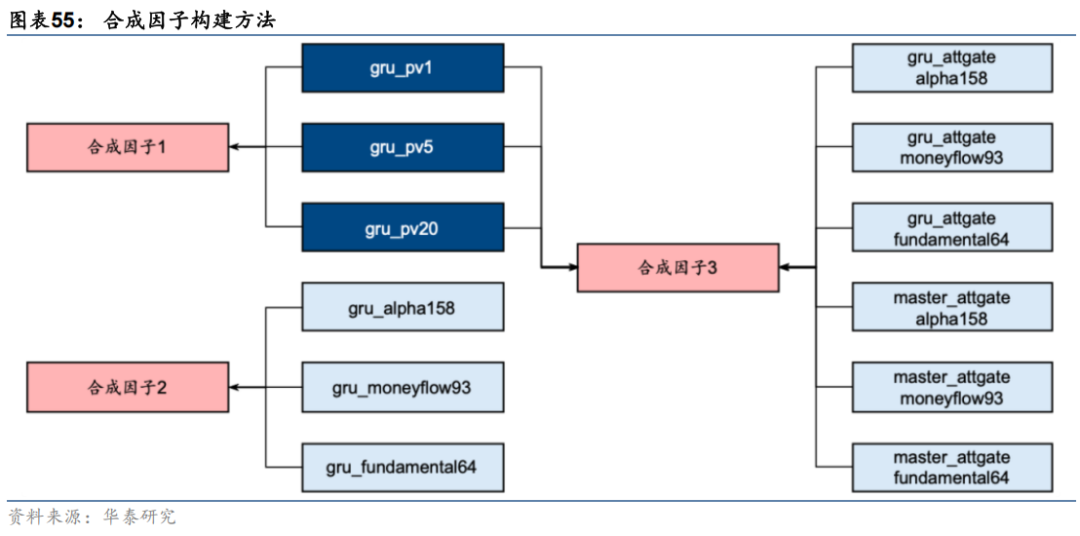
因子合成与组合构建
本节基于前文构建因子,结合AI端到端因子挖掘模型输出因子合成得到综合因子,并基于该因子构建中证1000指数增强组合。本节拟构建三个合成因子,具体构建方法如下。其中合成因子1和2作为基线参考,分别对应传统端到端AI量价多频率合成因子,以及三组特征集GRU合成因子的表现,合成因子3在端到端AI量价因子的基础上,引入市场特征门控和三层注意力特征提取模型的预测因子。以上每组因子合成时权重均为等权。
三组合成因子评价指标对比如下。

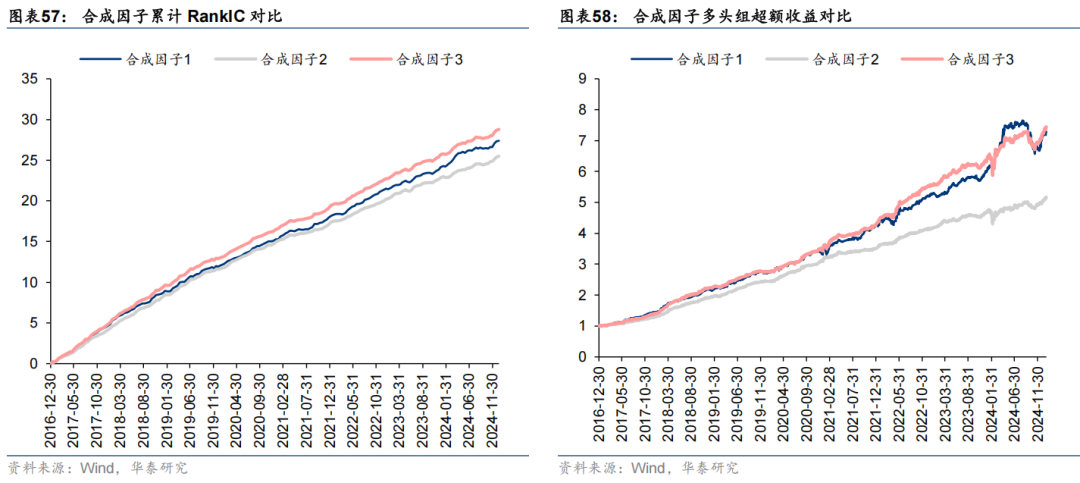
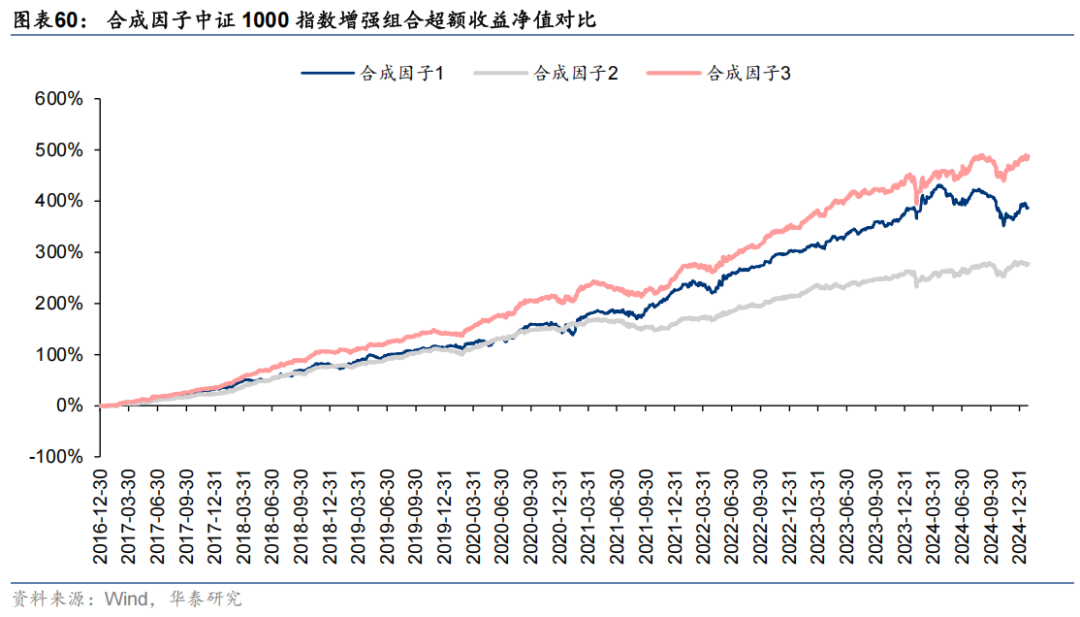
经组合优化后中证1000指数增强组合业绩对比如下。

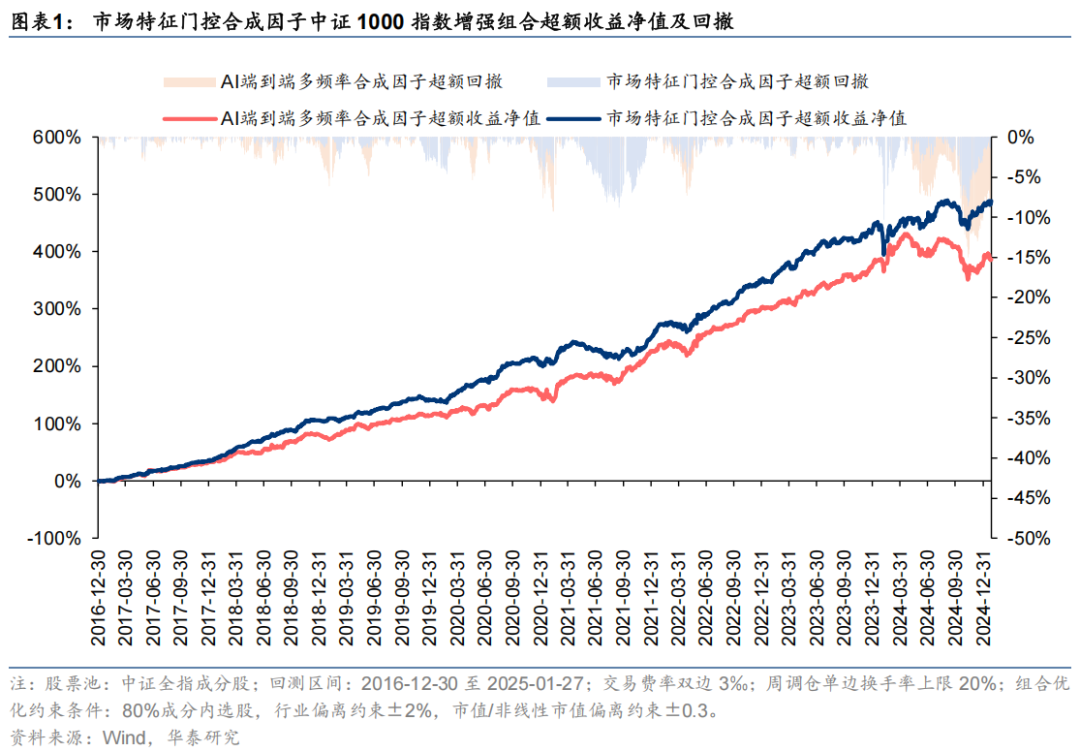
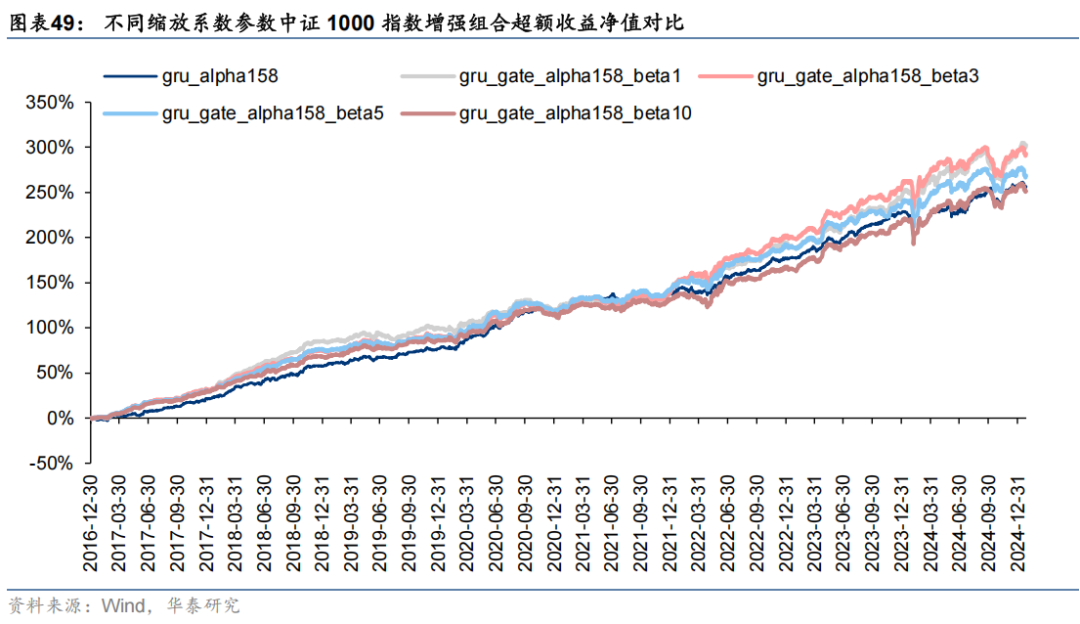
其中,合成因子3对应指增组合超额收益净值曲线及动态回撤如下。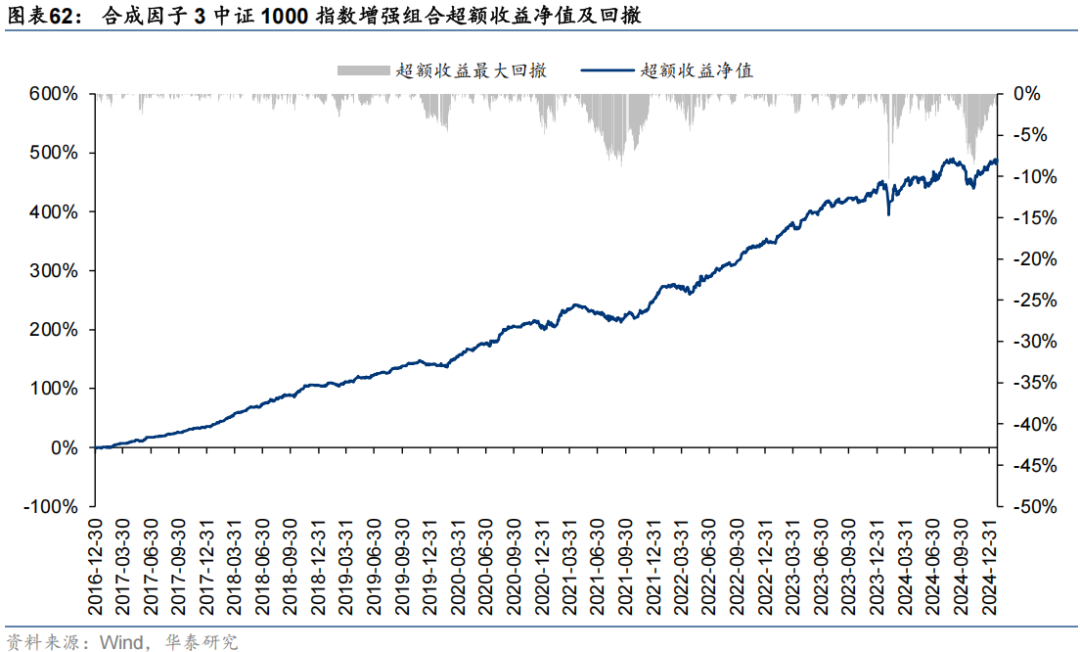
对比以上结果可知,在传统端到端AI量价等因子的基础上加入市场特征门控因子后表现得到了较为显著的提升。其中:1、对比三组合成因子表现可知,三组新特征集经基础GRU模型合成后因子表现一般,而加入市场特征门控以及三层注意力特征提取模块后合成因子表现提升显著;2、从因子评价指标的角度看,合成因子3的RankIC均值达到14.5%,在端到端AI量价合成因子的基础上提升了0.8 pct,RankICIR达到1.43,在端到端AI量价合成因子的基础上提升了0.27,改进效果显著;3、经组合优化后,中证1000指数增强组合自2016-12-30至2025-01-27年化超额收益25.6%,信息比率3.29,业绩表现优异。
05 总结
金融数据分布在时序上的非平稳性对AI量化模型是关键性挑战,有效应对数据漂移或可提升AI模型的表现。本研究从两个部分进行展开,第一部分针对时序预测问题中数据漂移的应对方法进行调研和综述;第二部分基于AI量化模型应对市场变化的代表性研究进行多方面改进和实证。结果表明,针对特征提取模块结构、门控机制等改进均有效。将传统AI量价因子与市场特征门控因子合成,基于其构建的中证1000指数增强组合2016-12-30至2025-01-27年化超额收益25.6%,信息比率3.24,业绩表现提升显著。
应对数据漂移的三个视角:数据分布、模型结构、训练模式。本研究针对AI时序预测模型应对数据漂移的方法进行调研和综述。近年来发表于AI顶级会议及期刊的14篇相关研究主要通过三类方法应对数据漂移:其一,通过在模型训练前或训练过程中对非平稳的时间序列数据进行动态调整,化波动为稳定;其二,改进神经网络结构以动态检测和适应数据分布漂移;其三,利用在线学习、元学习、动态模型集成等方式提升模型迭代速度。量化领域相关研究中,Li等(2024)的研究从模型结构出发,做出了两项改进:其一,将市场特征通过门控机制输入神经网络,其二,通过三层注意力机制交叉提取股票时序和截面上的信息,具有较高参考价值。实验结果:市场特征门控机制、特征提取模型结构等改进均有效。本研究对市场特征门控模块、注意力特征提取模块在不同特征集上进行多项对比实验。针对市场特征门控模块的实验结果表明,加入市场特征门控模块后因子评价指标及组合业绩均有提升,注意力机制门控表现更优,相比无门控模型中证1000指增组合2016-12-30至2025-01-27区间年化超额收益最高可提升4 pct;针对特征提取模块的实验结果表明,三层注意力特征提取模块相比传统GRU更具优势,三组特征集上预测因子RankIC均值平均可提升0.8 pct。因子相关性测试结果表明,加入门控、修改特征提取模块后因子与改进前因子及传统端到端AI量价因子间相关性均较低。市场特征门控合成因子表现提升显著。研究最后基于改进因子尝试进行因子合成并构建指数增强组合。最终综合因子由9个因子等权合成,分别为3个不同频率的端到端AI量价因子以及6个基于注意力门控和不同特征集训练得到的市场特征门控因子。测试结果表明,合成得到综合因子RankIC均值达到14.5%,RankICIR达到1.43,提升显著;基于该综合因子构建中证1000指数增强组合自2016-12-30至2025-01-27年化超额收益25.6%,信息比率3.29,业绩表现优异。1、综述部分重点总结AI时序预测领域对数据漂移的应对方式,其中许多方法或可在AI量化领域上进行迁移和测试;2、实证部分当前仅以宽基指数的量价数据作为市场特征,未对市场特征的选取开展大规模测试。而宽基指数的量价指标并不能准确且完善的表述金融市场状态。未来可尝试加入行业、风格、宏观等多角度特征;3、最终构建合成因子时仅采用简单等权合成的方法,未来或可使用机器学习模型尝试进一步提升合成因子及指增组合的表现;4、本研究中模型训练时均未大范围调参,对模型训练流程深入探索或可进一步提升表现。

































 粤ICP备17114055号
粤ICP备17114055号