
本文分享了物流技术团队在垂直领域大模型开发和部署过程中的技术细节、挑战解决策略以及实际应用案例。
大家好,我们是淘天物流技术团队,在过去一年多的实践工作中,我们团队围绕“物流体验”这一垂直领域,尝试通过垂直领域大模型“物流AI”为消费者物流相关咨询、物流商业化答疑、内部小二/研发的工单答疑等场景提供快捷、轻便的大模型能力。同时,我们又在实践探索中,慢慢打磨了“物流AI平台”,支持使用者可以在1-2分钟内就可以自定义场景并创建专属于自己的物流小助手。在此也把这两年的一些经验分享出来,希望跟大家一起交流和探讨。
垂直领域大模型是指以通用大模型作为base model,再喂以特定领域或行业的领域知识,经过训练和优化的大语言模型。与通用语言模型相比,垂直领域大模型更专注于某个特定领域的知识和技能,具备更高的领域专业性和实用性。但因为B端场景的一些特殊性(比如对于准确性的要求、知识库的频繁迭代等),To B大模型也面临着不一样的挑战。
领域专业性:垂直领域大模型经过专门的训练,能够更好地理解和处理特定领域的知识、术语和上下文。
高质量输出:由于在特定领域中进行了优化,垂直领域大模型在该领域的输出质量通常比通用大模型更高。
特定任务效果更好:对于特定领域的任务,垂直领域大模型通常比通用大模型表现更好。
准确性:C端场景下,消费者对于大模型的产出都有一定的容忍度,比如写个小说、画个图。大模型只要回答的不是太差,消费者对于结果都会一定程度的接受。但B端场景,商家对于大模型产出的结果的准确性更加敏感。同时大模型在B端的试错成本很高,如果一次结果不满意,商家可能就不愿意用第二次。
- 知识库维护:B端场景下,商家经常频繁的更替、维护自己的知识库,并且知识库里面的素材多种多样,有流程图、ppt、pdf等。如何保证大模型高效、准确的识别不同知识库体系里面的相关知识,并为后续的RAG召回高质量的答案是需要面临和解决的挑战。
适用性限制:B端场景的垂类大模型在特定领域中的适应性较强,但在其他领域的表现可能相对较弱。但我们在实际使用中,又不能完全杜绝使用者会问一些“非物流”相关的问题,所以在实际的微调过程中,需要与一些通用数据集合并在一起进行微调。
以上是To B垂类大模型的一些特点,下面主要分享下这段时间遇到的模型层面的一些挑战和对应的解决方案。
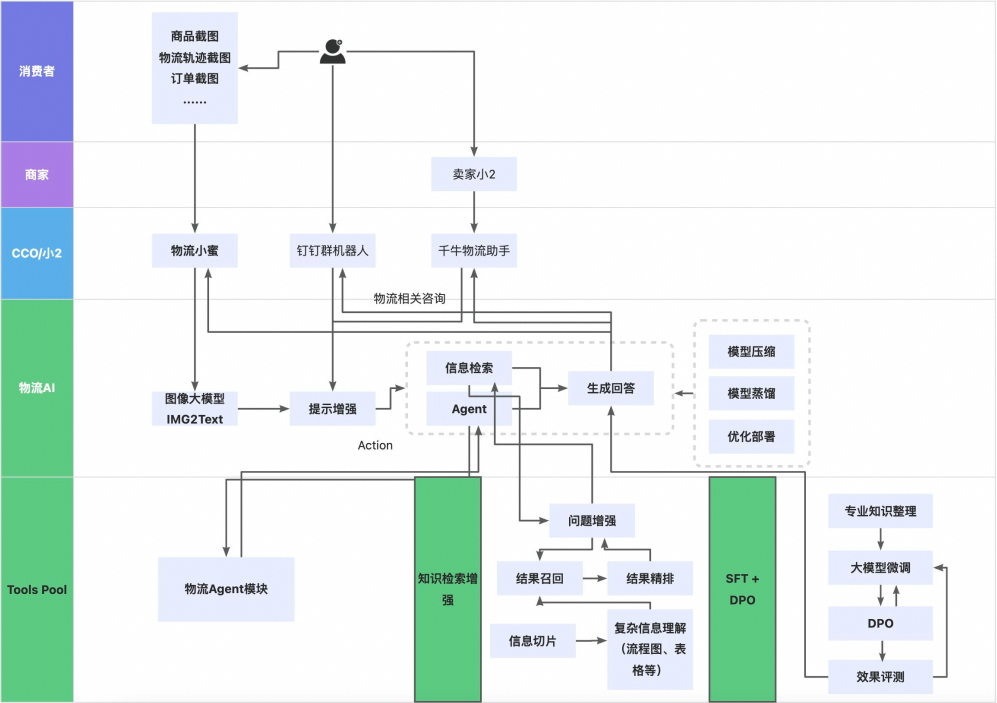
物流AI大致框架结构图
1、对齐增强
主要作用:在实际的答疑场景中,提问者并不会将问题进行过多的描述,所以我们借鉴了BPO的思路,通过优化提问和提供思路使得大模型更好的理解问题和回答问题,可以有效的提升大模型的回答质量和准确度。(关于BPO的思路,可以详见文章“Black-Box Prompt Optimization: Aligning Large Language Models without Model Training”),BPO的大致过程:Step1: 给某一个大模型A init instruction ,让A针对标准问题pair(Q1,A1)的问题,生成答案(Q1, A1'),因此每个标准问题对都变成了三元组(Q1, A1, A1'), 这边A1对应的是good answer, A1' 对应的是bad answer。Step2: 然后让GPT4对比good answer 和 bad answer 以及问题Q去优化 init instruction 生成 tuned instruction。Step3: 训练一个seq2seq模型,输入是问题Q,输出是 tuned instruction。Step4:将这个seq2seq模型,放到大模型体系里面,所有的用户问题都可以利用这个seq2seq生成对应的提示信息,然后将 提示信息 + 问题 放到大模型里面去进行回答。通过使用BPO给我们回答准确率带来了1.8%的提升。通过对话增强优化后的提问:你是物流部的机器人,针对天猫超市供应商入驻物流及供应链产品的流程,进行详细且有条理的解答,包括但不限于入驻申请、签署协议、品牌授权、创建二级供应商、签署商务合同和确定入仓方案等步骤。请确保你的回答准确、有深度且连贯,能够帮助用户理解和使用产品。备注:BPO这个方法在这届WAIC会议GLM专场中也有专门提到过,可见确实是好用。2、Text2API
主要作为:大模型作为一个Agent,学会使用现有工具去解决较复杂的逻辑问题是大模型区别于传统答疑类机器人的一个显著特点。在物流场景,我们有超过1000个需要高频调用的API,同时部分API还具备一定的相似性(比如查询商品信息、查询组套信息、查询货品信息等)。并且因为用户体验,查询api的时间通常要压缩在2s以内,如何高效和准确识别问题中的参数、和找到对应的api是我们需要去解决的2个问题。最开始的时候我们使用langchain中自带的react框架进行text2api的构造,但发现几个问题:后来我们尝试引进了Reflexion框架,(详见:Reflexion: Language Agents with Verbal Reinforcement Learning),相较于传统的Reactor,Reflexion提供了自我反思机制,然后在memory模块中保存之前的短期记忆和长期记忆,从而在之后的决策中,基于储存的记忆诱导大模型生成更好的答案。通过reflexion返回的api准确率提升了4%。值得一提的是,在实际使用前,我们还通过对齐增强模块对某个api的描述进行提示性的补充增强,从而解决部分相似api无法识别的问题。3、RAG
RAG是经典、高效的垂类大模型应用方案,就是通过自有的垂域数据库检索相关信息,然后合并成为提示模板,喂给大模型生成最终的答案。但在ToB场景,因为内容素材的多样性,例如下图是我们实际官方上门的某一个白皮书文档,里面包含了pdf式的合同、表格、系统界面截图和操作流程图。如何在文档注入的时候能够很好的解析这些素材,并且在做RAG时候能精准的返回对应的结果是我们核心要解决的问题。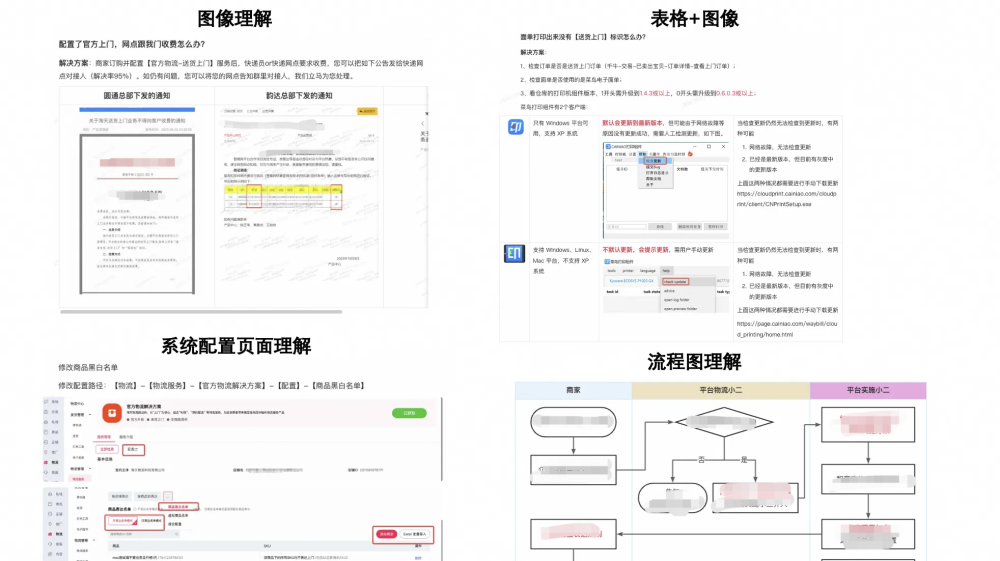
如何解决复杂的素材:以流程图为例,我们首先让chatgpt帮我们描述流程图里面对应的步骤,然后我们人工对近1000个chatgpt4生成的结果进行review,并最终放到我们的基座模型中进行sft + dpo。
关于文本切分,目前只要有基于深度模型的切分和基于规则的切分。我们第一个版本用的是基于transformer的切分,但实际效果并不好,后面沿用了基于规则的切分,不过依然有一些经验可以和大家分享:如果将文本分割的结果直接作为embedding,需要特别注意chunk_size大小,太长了大模型容易忘掉中间的内容,太短了又不能包含有效的信息,从而导致关键信息而被忽略;
不需要拘泥于原来的文章的行文结构来决定内容的前后关联度,我们引入了一个聚类的方法重新把内容通过「语义逻辑」重新组合,目前来看效果还不错;
为了使LLM处理长文本,如果不能无限制的提升context的话,就只能掉过头来先把长文本「压缩」成短文本而尽量不要减少信息量;
当聚类之后的 chunk 数量超过了预定的值之后,递归总结的过程还会在内部再次进行递归总结,一直优化到需要的长度。基于上面几步优化,文本信息被重新组织、优化成一棵树。
4、SFT
在业务团队的帮助下,我们沉淀了几万条标注过的物流垂类场景测评数据。这些测评数据是让我们选定基座模型、微调方法 和 后续一直迭代模型的一个重要指引。在这些测评数据的基础上,我们测评了市面上几乎所有的开源基座模型,以及能看到的几乎全部微调方法,并利用embedding similarity、人工打分、chatgpt4打分这3个维度分别测试 “基座模型” 和 “基座模型+微调” 在物流场景下的表现情况,从而挑选适合我们场景的基座模型和微调方法。在实际sft时候,我们还夹杂了部分公开数据集为了解决垂类大模型通用能力退化,适用性限制这一问题。公开数据集主要参考了有COIG-CQIA、alpaca-gpt4-data-cn等。最近,我们也参考ORPO(详见:ORPO:Monolithic Preference Optimization without Reference Model),尝试将SFT + DPO的模式变成单纯在SFT中增加一个惩罚项来让大模型做更好的偏好对齐。通过实验对比,ORPO相较于之前的链路,整体回答效果提升了约5.2%。在这边主要跟大家分享下物流AI的主要3个应用场景和物流AI产品界面,也欢迎感兴趣的同学一起交流合作。物流小蜜:跟cco的技术团队合作,通过对图像以及上下文的理解,识别消费者的问题和对应诉求,为整体的解决方案提供帮助。物流答疑钉钉机器人:通过在钉钉群部署专属物流机器人,释放部分物流技术支持者和小二日常工作答疑的工作。提升面向业务的服务能力和服务水平提高自动答疑效率、节约人效成本。千牛物流商家后台(研发中):该项目是与千牛的产技算团队合作,在千牛物流tab页为商家提供物流相关(时效、送货上门等)答疑和商业优化建议(择仓、择配的建议等)。物流AI产品:提供快捷、轻便的一站式物流解决方案助手。只需要1-2分钟即可以上传知识库,部署专属于自己的物流助手。这个项目是与cco团队合作,将多模态能力嵌入到物流小蜜当中,当消费者上传图片后,会调用物流AI多模态大模型,通过对图像以及上下文的理解,识别消费者的问题和对应诉求,为后续整体的解决方案提供帮助。因为这个模块涉及到多模态,并且落地在整个小蜜的链路中,所以除了前面提到的一些挑战,还有以下2个问题需要克服:
1、需要在多轮对话夹杂着图像的复杂场景中准确相关物流属性信息(例如运单号、订单号等)的同时,识别出消费者问题和核心诉求。2、需要在3s以内完成图像识别、text2api、大模型生成结果等全部流程。关于这一部分的实现技术,会在后续的文章中详细介绍,目前该项目已经上线并且已经切流50%。目前平均rt1.7s,失败率不足1%,经过人工抽样检测,物流小蜜图片分类准确率在89%,消费者问题&诉求识别准确率在77%,物流要素提取准确率在90%。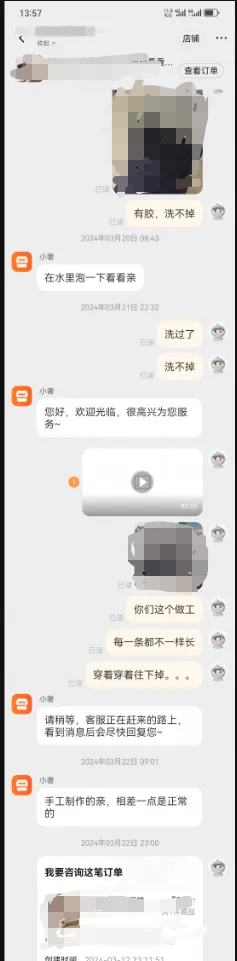
物流AI最终识别结果:
{'问题': '用户遇到的核心问题是手工制作的内裤存在质量问题,如长度不一、穿着后裂开,且用户已经清洗无法退货', '诉求': '用户希望申请仅退款,因为产品有质量问题且清洗后无法退货', '是否协商一致': '否'}目前我们正在尝试通过扩大上下文长度来提升线上模型效果,经过我们离线测试,通过引入图片中的上文信息,可以将用户问题、用户诉求的识别准确率从74.6%提升到87.2%。目前整个项目仍处在快速迭代当中,等有了最新进展再跟大家同步。我们尝试将大模型技术引入到商家咨询和工单答疑系统中,为商家和内部小二提供相关答疑服务:
在物流服务的实施环节,我们为商家解答上门、时效等服务相关的问题。目前已经服务20+钉钉群,涉及商家1w多。
在工单技术支持工作中,基于工单历史数据、知识库沉淀,在工单场景提供智能答疑服务,节约人效成本。目前物流AI主要应用于天猫国际平台、天猫国际直营、喵速达&考拉、天猫超市、猫淘、物流平台6个行业。AI数据库共沉淀FAQ数量2W+,文档类3500+。
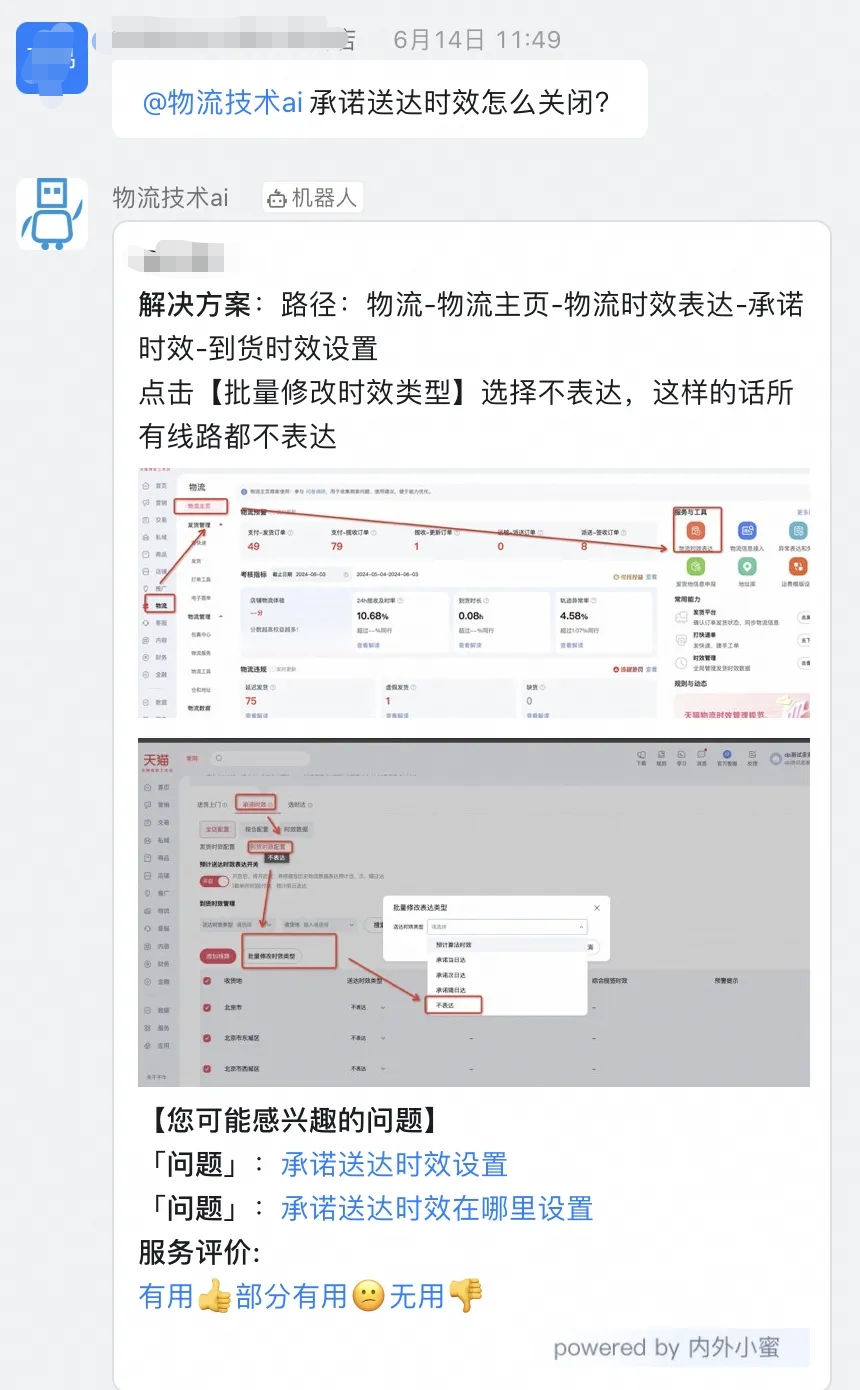
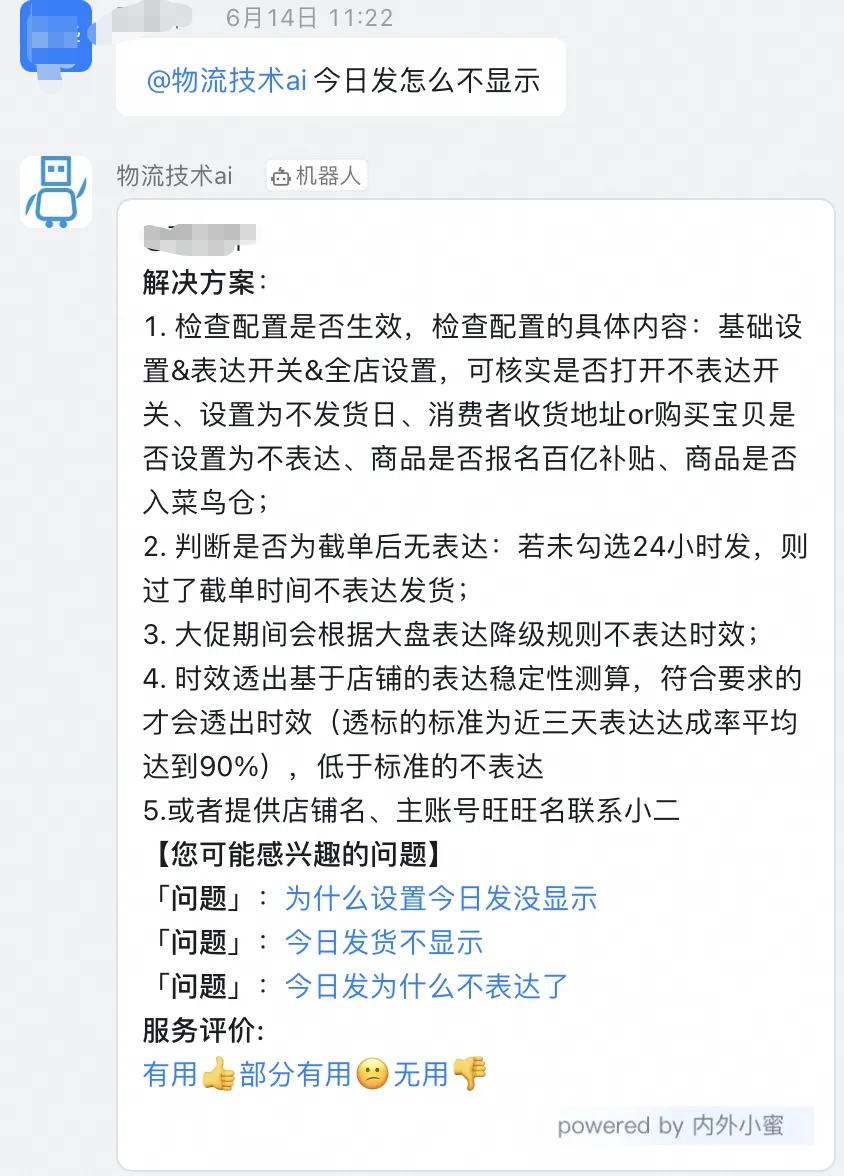
工单答疑场景
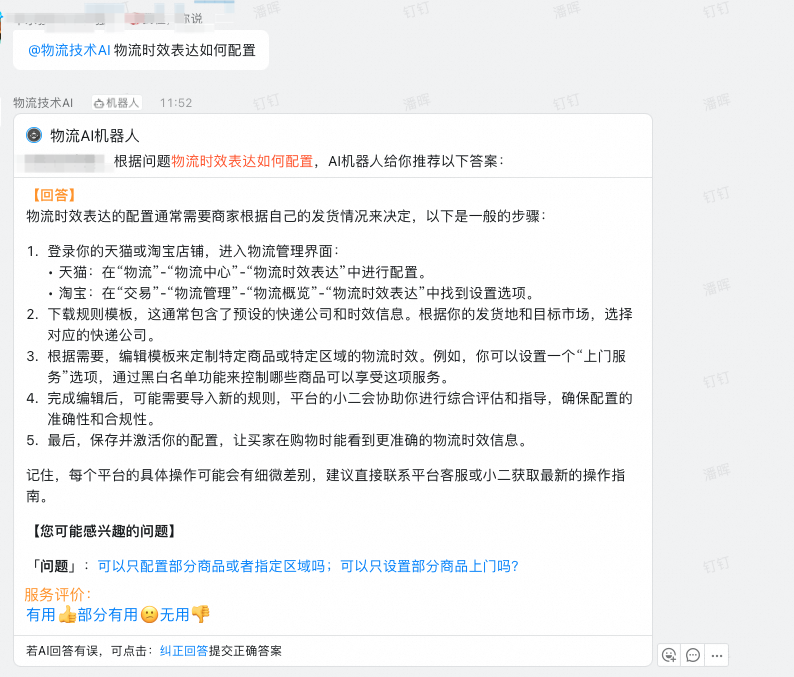
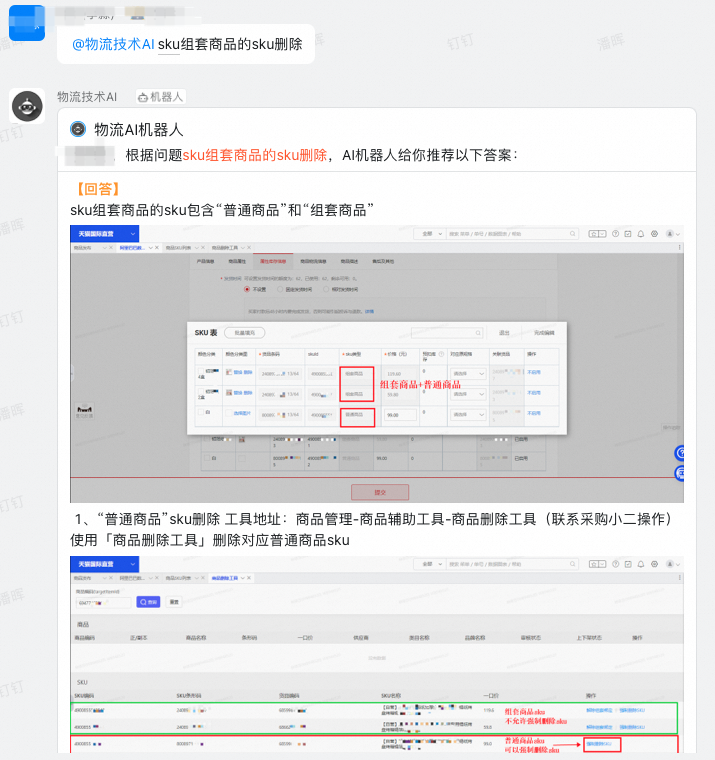
跟淘宝物流部、千牛的产技算团队进行合作。计划在千牛的物流tab页,对物流AI助手能力进行升级,从而给商家提供物流相关答疑服务。目前这个项目已经进入研发阶段,待项目上线后再跟大家分享经验。
在与我们的客户实际接触中,我们发现物流领域涉及到的知识面和领域知识实在过于繁琐,我们很难创建一个完整的知识库囊括所有的物流知识,并且应用于所有的物流场景。于是,我们就想有这么一个产品,可以帮助物流从业人员依据自身场景的不同,轻便、快捷的部署属于自己的物流助手。这就是我们创建物流AI产品的初衷,使用者只需要简单的3步(场景上传、场景绑定 以及 助手导入)就可以完成整个环节。场景上传:使用者上传自己的知识库(语雀文档、pdf、ppt等都可以)场景绑定:选择物流AI要调用的API(e.g. 异常物流轨迹识别、包裹是否发货、商品时效等)助手导入:将助手与钉钉群绑定 或者通过API直接引入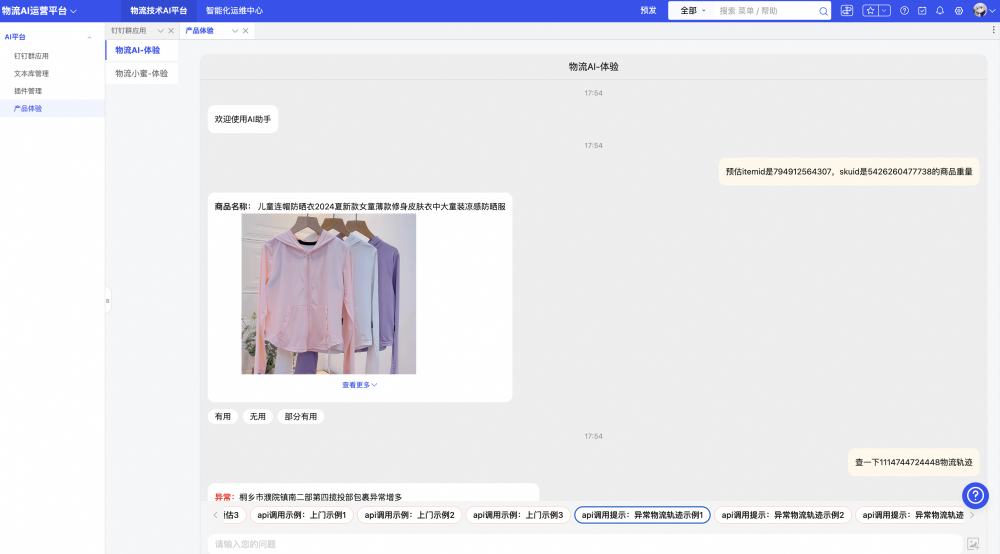
2、查看订单物流轨迹,包括物流轨迹中的中转站,对可能出现的异常订单做出预警。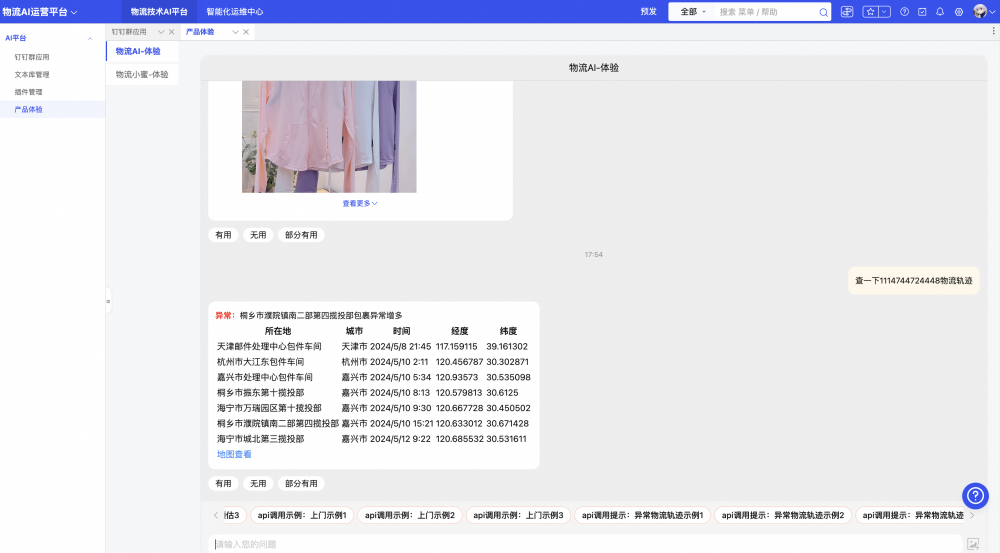
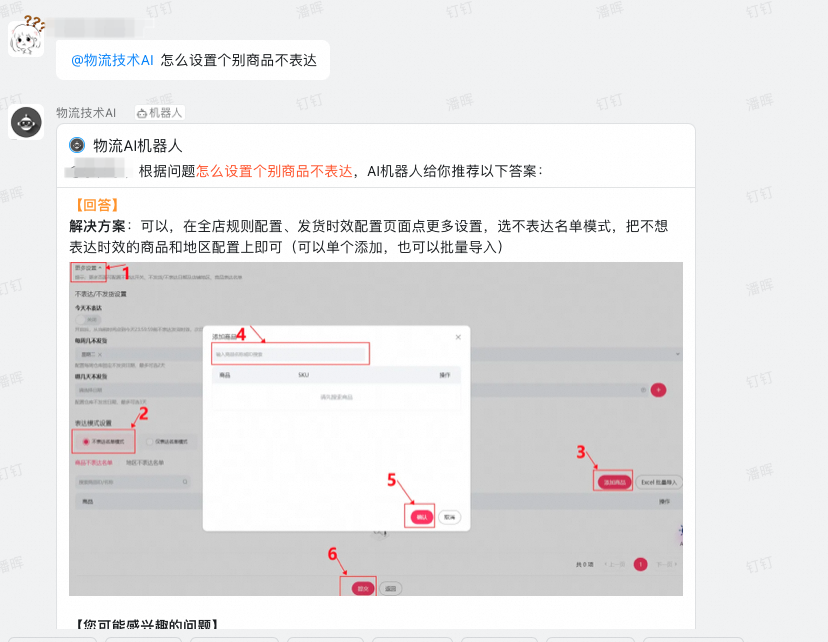
自定义完场景后,使用者也可以将“自定义的物流AI”直接拖到自己的钉钉群中进行使用:
以上就是物流AI团队这段时间在垂类大模型的一些思考和实践。经过一年多的探索,虽然我们在不少的场景上都有突破和进展,但肉眼可见依然有很多领域尚未完善,未来有很多工作需要进一步展开,也非常欢迎各个团队的同学一起交流大模型技术。最后,非常感谢一直默默支持我们前端和后端技术团队,帮我们做标注review模型效果的业务团队,感谢UED的小姐姐,感谢合作的上下游CCO团队、千牛产技算团队,感谢老板们的大力支持,也非常感谢物流AI团队所有成员的辛勤付出。本方案介绍如何将网站的自建数据库迁移至云数据库 RDS,解决您随着业务增长可能会面临的数据库运维难题。数据库采用高可用架构,支持跨可用区容灾,给业务带来数据安全、可用性、性能和成本方面收益。方案提供了快速体验教程,模拟了数据库迁移所需的工作,帮助您快速上手。

































 粤ICP备17114055号
粤ICP备17114055号