导读 本文将分享大语言模型在推荐系统中的应用现状及未来趋势,将梳理学术界最近的相关工作和一些发展方向。本次分享的大部分内容是基于 WWW'24 上的同名 tutorial,感兴趣的同学可以查阅该 tutorial 的完整内容。
1. 应用大模型做推荐的背景知识
2. 大模型推荐系统的进展现状,包括 LLM4Rec 和可信的 LLM4Rec
3. 大模型推荐系统相关的 Open Problems
4. 大模型推荐系统未来可能的研究方向
5. Thanks
6. 问答环节
分享嘉宾|王文杰博士 新加坡国立大学 研究员
编辑整理|吴叶国
内容校对|李瑶
出品社区|DataFun
Introduction
1. Background of RecSys
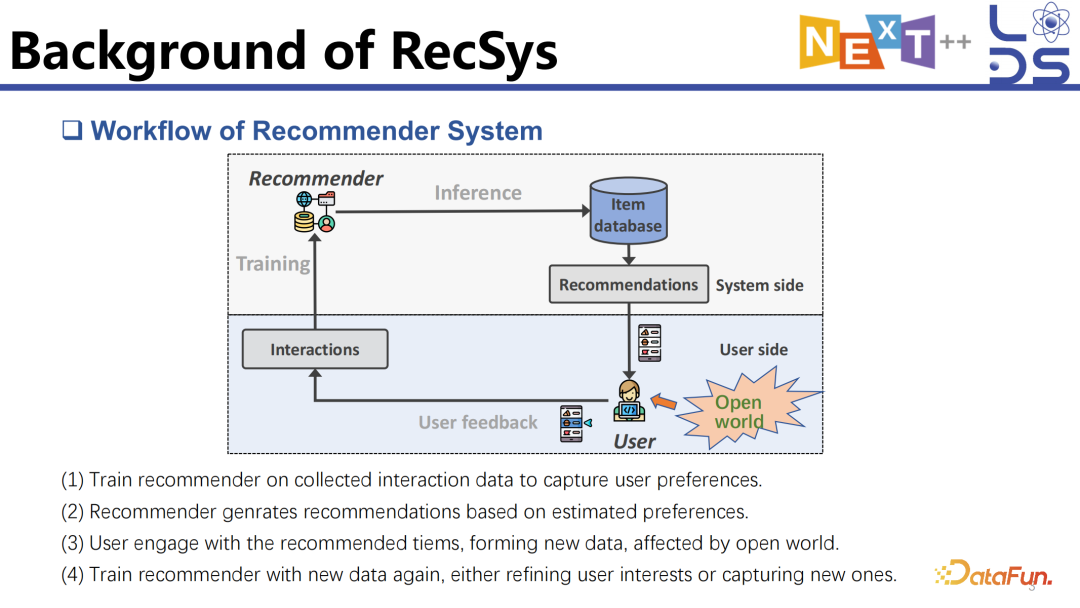
图示是一个推荐系统简化后的工作流程,反映了推荐系统如何与用户进行交互。
推荐系统通过多阶段或复杂的过滤体系,基于用户过去的交互历史、互动和上下文信息,为用户生成个性化的推荐列表。当用户与推荐列表进行交互时,他们会受到外部信息和周围环境的影响,对推荐列表做出一定的交互,比如点击、购买或收藏等。这些用户反馈会被收集起来,用于下一步推荐系统的训练,形成一个反馈循环。
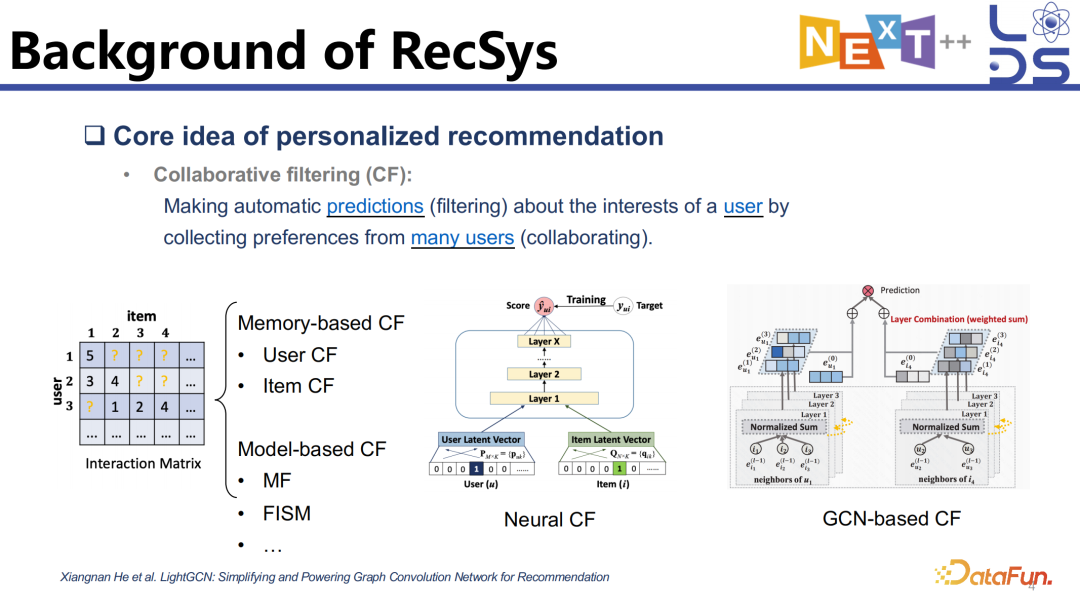
在以往的工作中,推荐系统生成推荐列表的过程会分为多个阶段。首先是进行召回,利用协同过滤(CF),使用矩阵分解等算法对 Item 进行召回,进行一个粗粒度的过滤。
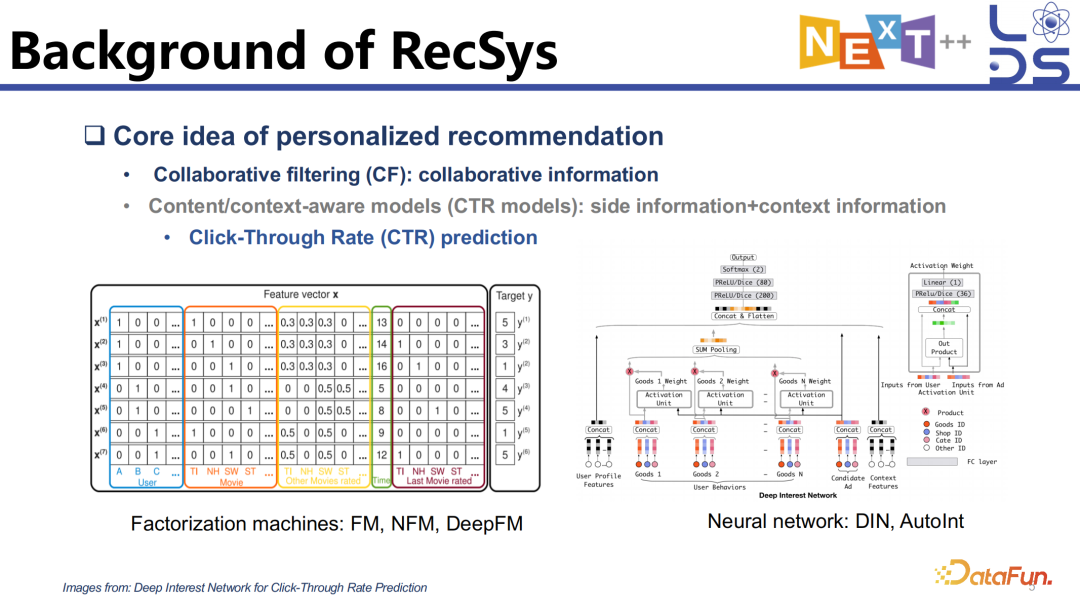
当然系统也会考虑更复杂的 context 信息以及用户和 item 的一些细粒度的特征,进行更细粒度的 ranking 和 reranking 等操作。
2. Benefit of LMs
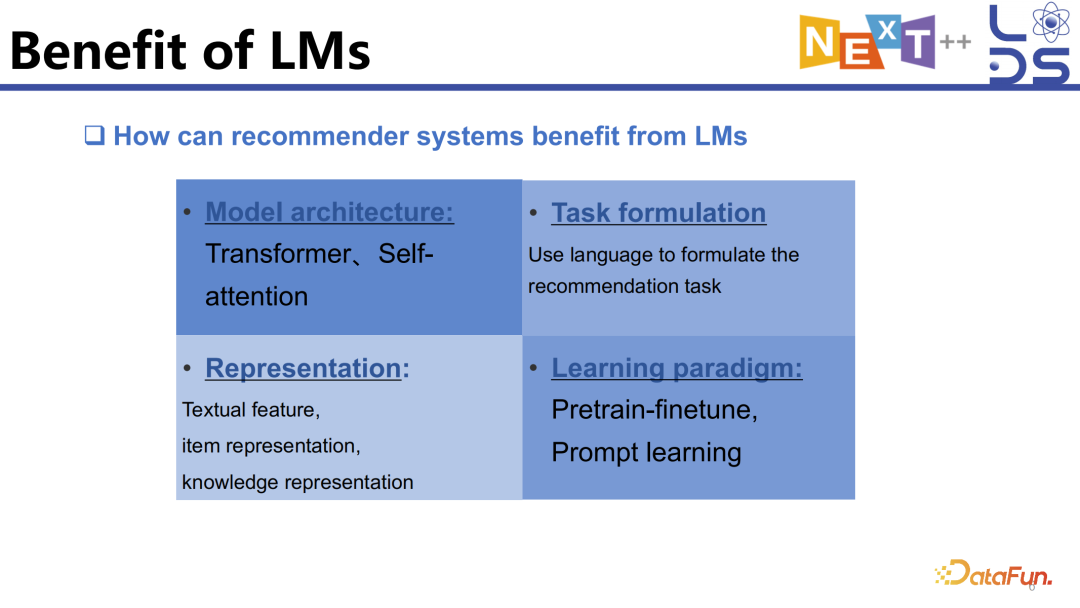
借鉴语言模型的 model architecture,用 transformer 实现对 sequential pattern 推荐的建模。
借鉴 BERT 的 task formulation 的形式去定制推荐任务。
利用语言模型的文本信息抽取能力,对用户的行为进行相应的表示学习和相关 context 的知识的利用。
在学习范式上学习语言模型,如 Pretrain-finetune、Prompt learning 等。

在大语言模型出现之前,语言模型为推荐模型的构建提供了相当多的启发,如:
利用 Architecture 的 BERT4Rec、SASRec 应用了 transformer 和 self-attention 的结构;
利用语言模型做 item encoder 进行语义信息抽取;
利用 language
model 来 unify 多个推荐任务,用同一个模型做不同的事情,比如 P5、M6-Rec 等都是用同一个语言模型 unify 多个推荐任务。

自从 ChatGPT 问世,人们发现当模型的规模扩大到一定程度,大模型会具有非常强的能力,尤其在语言理解、语言交互以及丰富的世界知识方面,与以前的语言模型相比有很大的区别。
大语言模型有很强的 In-context
Learning 的能力,以前的语言模型对话不够自然,也无法基于 Few-shot examples 学好用怎样一个推理的策略去回答问题。基于之前利用语言模型去 unify 多个推荐任务,研究人员也尝试利用大语言模型 unify 各个推荐任务,去做 recall、ranking、推荐的解释以及调用工具去辅助用户这些传统的推荐任务。
Progress of LLM4Rec
接下来介绍当前利用大语言模型做推荐的主要方向,及每个方向中的一些代表性工作。
1. LLMs for
Recommendation

前面提到,推荐模型可以从语言模型中学到很多东西,比如模型架构、学习范式、表示学习等等。更进一步,大语言模型在此基础上为推荐模型提供了更多可以借鉴的东西:
大模型的强交互能力。可以为用户提供更好的交互体验,以前与用户交互的主要通过被动的 feedback,用户不愿意和推荐系统交互或者给出指令的一个很大的原因是用户不愿意花时间精力去提供信息,最好系统可以猜出来自己喜欢什么,而当模型非常聪明的时候,比如即使用户只提供很简单的信息也能够享受极大提升的用户体验,用户估计也会愿意提供一些简单的指令来帮助系统显著地提升推荐的准确性。在交互的方式上,未来的推荐模型会发生一定的变化。
大模型的泛化能力。大模型在多个领域有很强的泛化能力,Zero-shot 或者 Few-shot In-context Learning 的泛化能力,大模型能够利用自己的 World Knowledge 提升模型的泛化性。推荐中也有很多场景需要泛化,比如 cross-domain 的场景等都需要模型有基于世界知识进行推理和泛化的能力。
大模型的生成能力。我们希望推荐系统能够为用户定制个性化的内容,进行个性化的内容生成,既推荐人工生成的内容,也可以通过 AIGC 去生成内容,并且对推荐的结果进行解释。
2. Progress of LLM4Rec
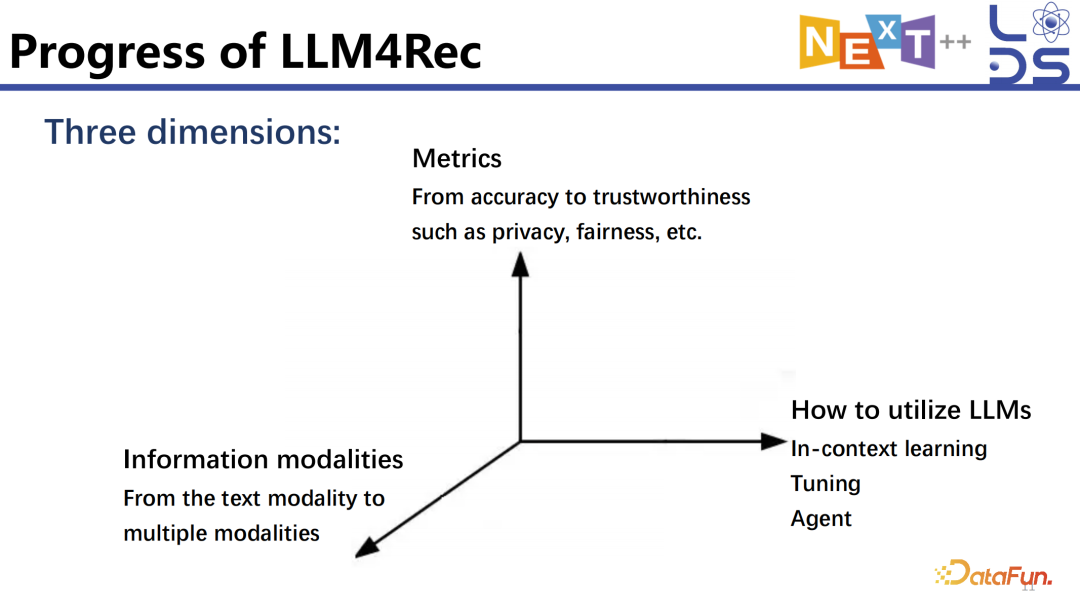
大语言模型做推荐是在优化哪些指标?因为不同工作的侧重点是不一样,推荐也在追求很多不同的目标。比如先去做最基础的优化 LLM4Rec 的 accuracy(准确度),进一步会考虑各种 trustworthiness(信任度)指标,比如 Fairness、Privacy、Safety 以及 OOD(Out-Of-Distribution)泛化能力等。
最基础的当然是 text 模态。对于推荐来讲,最早开始探索的就是怎样把 item 文本模态以及 context text 模态的信息利用起来,利用大语言模型进行 text 模态的推理。很多场景中用户侧的多模态的信息是比较固定的,比如用户可能有头像以及文本描述等,但是 item 每天都会产生很多 video、image,包括相应的 text 的描述、tag 等多模态的信息。多模态信息在很多场景里是很有用的,如何利用好 video 以及 image 模态的信息,怎么把这些多模态的信息结合到 LLM4Rec 的架构中,也是探索中的一个维度。
主要包括以下三类:第一个是 In-context
Learning,不需要 Tuning,直接利用经过 Pretraining 和 Instruction Tuning 的 LLM,可以给他几个 Few-shot 的 example,LLM 就能够学会基于任务的 input 去生成 output,在推荐中也是一样的,我们把推荐任务当成一个新的任务,然后利用一些 Few-shot 的 data sample 去 instruct LLM 做好推荐任务;第二个是 Tuning ,利用推荐的数据训练模型的参数,以更好地完成推荐任务;第三个是 Agent,Agent 是一个非常特殊的存在,会利用 In-context Learning、Tuning、RAG 之类的技术,之所以将其单独提出,是因为确实在推荐里有一定的独特之处,相关的工作与只做 accuracy 的工作还是有一些差别的,有一些工作专门用 Agent 去完成相应的推荐任务。
3. In-context learning
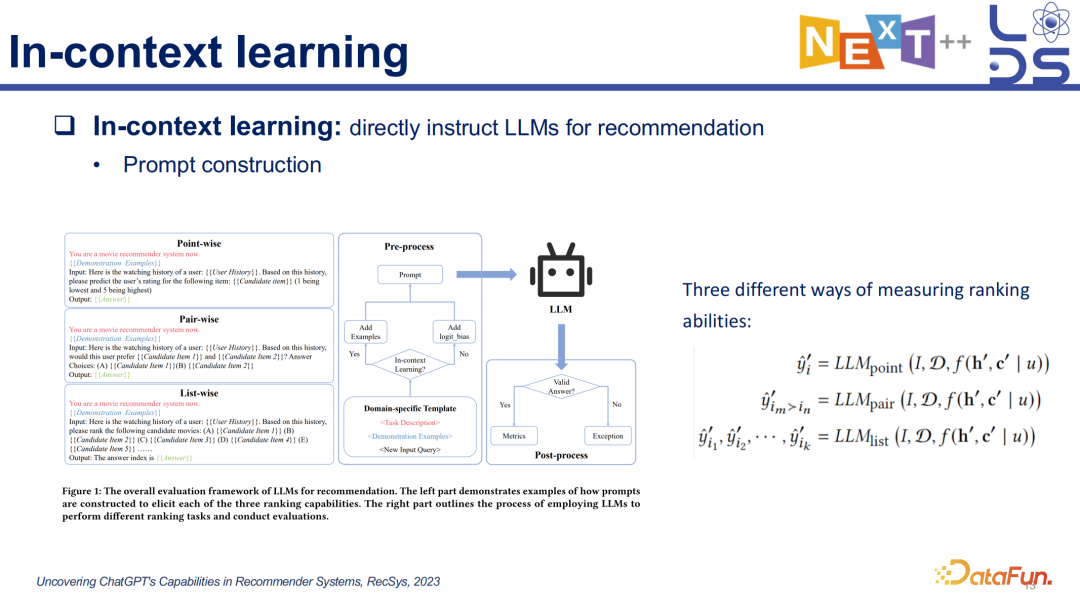
In-context learning 做推荐是比较简单的,最直白的思想就是把几个 data sample(用户历史的喜好数据)放到 prompt 里去 instruct LLM 生成用户是否喜欢,可以实现 Point-wise、Pair-wise、List-wise 等不同方式的输出。除此之外,还有一些工作是利用大模型的 In-context learning 方法去实现 data
augmentation,比如对用户的信息做 misinformation 的补充,通过用户本身的交互历史和 profile 推理生成一段 text 描述,然后将这些数据增强后的数输入到传统的推荐模式中去。
4. Tuning LLM4Rec
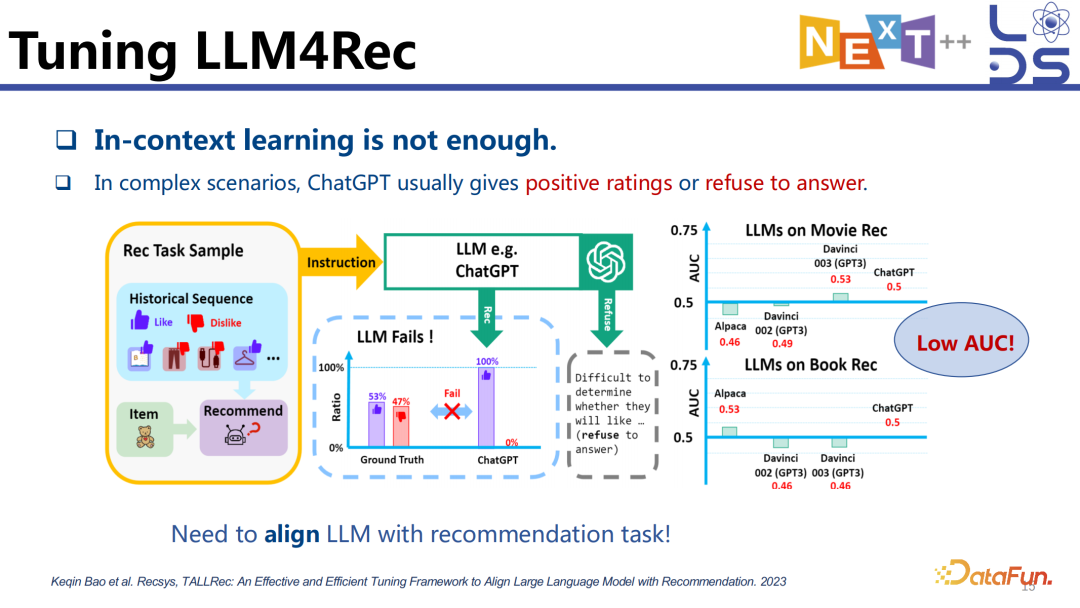
利用 In-context learning 做推荐的性能是不太好的,因为大模型的预训练和推荐任务是有 gap 的,大模型的预训练并没有 cover 推荐任务的 instruction 处理,也没有见过非常多的不同的推荐任务数据的格式,当我们直接用 In-context learning 的方法去做推荐任务时,会发现有时候会拒绝回答,或者是瞎猜着回答。

为了消除这个 gap,需要将大模型对齐到推荐任务上去。
现有的工作中有很多是利用大模型的 LLM4Rec,探究如何更好地训练一个大语言模型,使他不仅能够做好推荐任务并且能够利用好 Tuning 之前的大语言模型本身预训练阶段获取的知识。
现有的 Tuning LLM4Rec 相关工作基于任务层面可以分为两类:
第一类是判别式范式或者方法,就像传统的推荐任务一样,提供候选集,通过指令让大模型选择其中的一个。相应的 Prompt 可能是:这是用户的交互历史,请你帮我推荐一个用户可能会喜欢的 item,然后会提供 candidate,让大模型告诉我用户会不会喜欢这个 item,或者从下面两个 pair-wise 的 item 里边选一个,或者从一个 list 里边选一个,基本上都是给定 item 的候选让大模型去做一定的判断,所以我们认为从任务层面它是判别式的,虽然大模型确实是在 generate next token,但是从任务层面上就是通过给定历史和候选,判断用户喜不喜欢,更像是 CTR 的任务,给定用户和 item 的 pair 去预测用户喜不喜欢或者点击的概率是多少。
第二类是生成式的,不提供 item 的候选,在给定交互历史之后直接让大模型去生成用户下一个点击的东西或者喜欢的 item。这就需要大语言模型在待推荐的数据上训练过,知道大概有什么样的候选 item 在 proposal 中,这种是 generate 生成式的。
对于第一类,分为两个小的 subcategory,第一个是只训练部分参数的,比如可以接一个 Lora,或者只训练某一两层这种情况;第二个是对整个 LLM 的所有的参数重新训练,称为 Full tuning。
5. Tuning LLM4Rec:
TALLRec
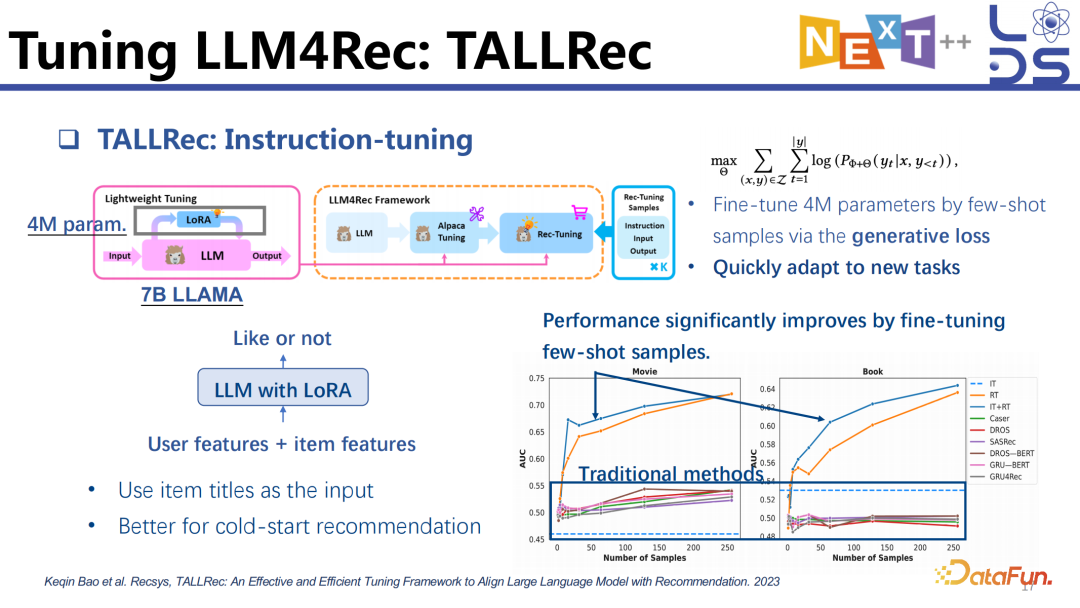
首先讲解一个只训练一部分参数的方案 TALLRec ,是我们发表在 Recsys’23 的成果。把一个比较大的 LLM,比如 7B 的 Llama 接一个 Lora 去做 fine tuning。Fine tuning Lora 的参数其实是比较少的,但是我们发现,只 tuning 这些比较少的参数,用不是特别多的 sample,甚至几十个 sample 就能够让 LLM 模型做推荐的效果提升非常大。只需要准备比较少的 sample 以及训练比较少的参数就能让 LLM 快速地 adapt 到新的推荐任务上。这也证明了,大模型泛化到一个任务上,只需要用一些 sample 告诉他应该怎样去 follow 这个任务的格式去做一定的推理就可以了。不仅不需要很多 sample,还能够利用本身 Pre-trained Knowledge。当然这里我们用的是 item 的 title 作为 input,它跟大语言模型预训练的文本信息在一个空间里。

我们发现用 item title 经过 few-shot tuning 的方法也能够很好地泛化到一些跨领域的推荐上。比如可以在 movie 上训练然后在 book 上测试,或者在 book 上训练在 movie 上测试,也能够有不错的效果,再次证明了其泛化能力。
6. Tuning LLM4Rec:
InstructRec
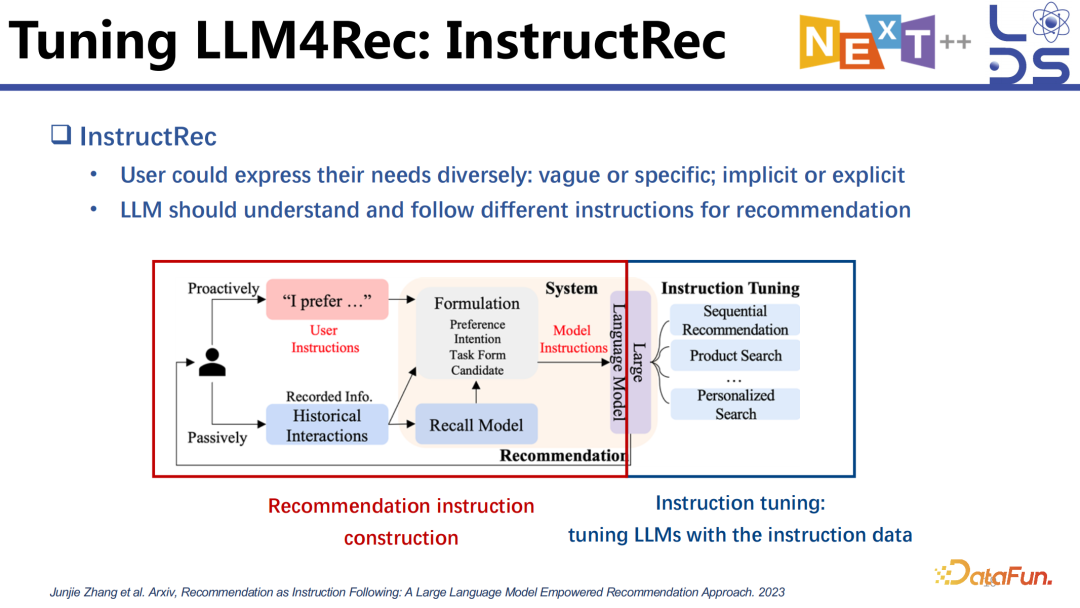
这里介绍一个 full tuning 全参数训练的模型 InstructRec。与 TALLRec 相比,除了训练的参数有区别,还有其他一些不一样的点。InstructRec 认为用户的 instruction 是非常多样化的,有比较明显的 instruction,也有比较隐晦的 instruction,不同的 instruction 代表了不同的需求。这个工作首先去构建了非常多样化的推荐 instruction,然后通过构建好的 instruction data 训练模型去 follow 不同的 instruction 去做不同的任务,比如 Product Search、Personalize Search,以及 Sequential Recommendation 等任务。不同的任务会涉及到不同的 instruction,当然同一个任务也有不同的 instruction,比如有的用户说得比较明显一点,有用户说得比较隐晦一点。
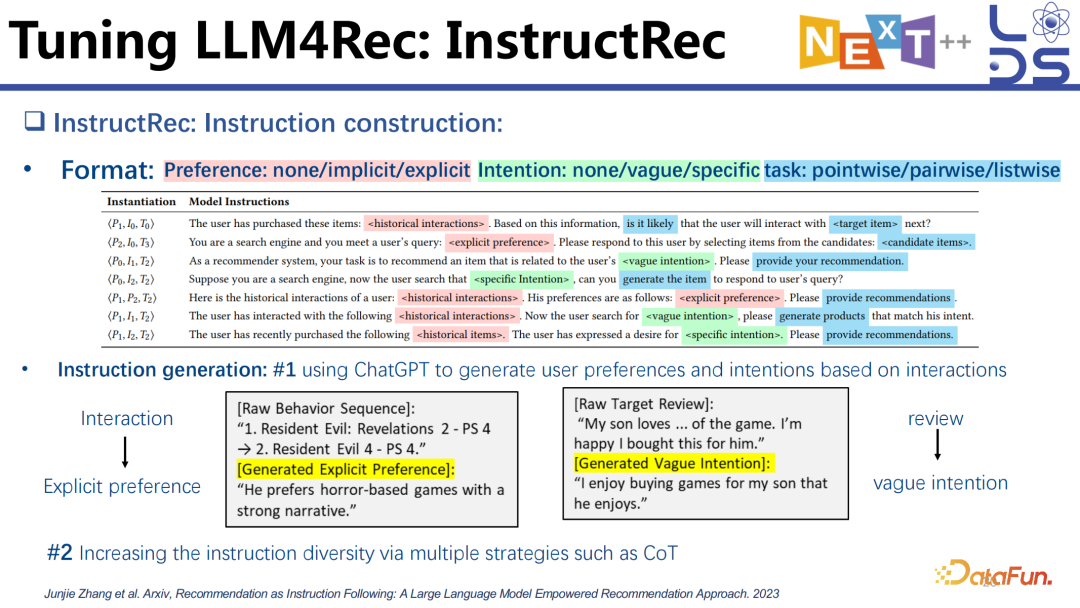
这个工作设计了很多 template。首先构建好上面的三元组,有用户的 Preference(偏好),也有用户的 Intention (意图),到底是 vague (模糊) 的还是 specific (具体) 的,还有用户的 Task(任务),任务到底是 pairwise 的还是 listwise 的等。利用 template 就可以去组合出来很多不同的 instruction。
有了这些 instruction 之后,就可以基于用户的历史 interaction 数据造一些 instruction tuning 的 data 出来,再利用生成出来的 instruction 去训练模型。
7. Tuning LLM4Rec:
BIGRec
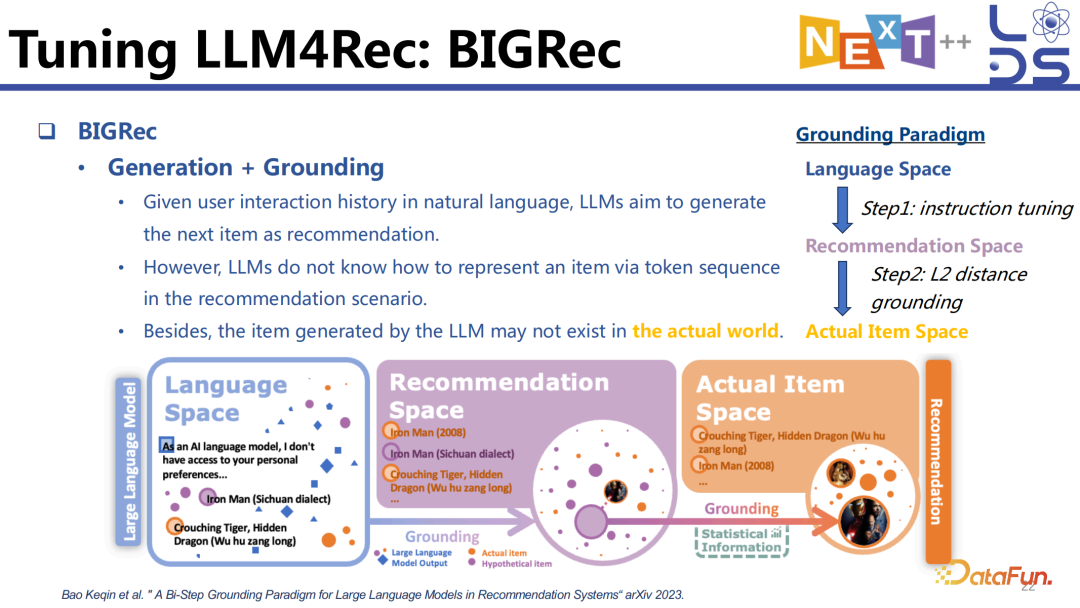
生成式方法就是给定历史之后,直接去生成下一个 item 是什么。这就会有一些问题,比如当我们把用户的交互历史用自然语言的形式描述出来作为 input 的时候,大模型要生成下一个 item,就必须要知道怎么去表示 item,并且需要通过 token sequence 的形式表示出来。
我们可以将每一个 item 的 item title 当作一个 identifier(标识符),这时可以利用用户的交互历史组织成自然语言去和下一个 item 的 title 组成一个 pair 做训练。这样做带来的问题是怎样让大语言模型知道什么样的 sequence 是一个可用的 title,虽然我们可以通过 instruction tuning 实现,但是在推理的时候大语言模型还是会不可避免地生成一些不存在的 title。
一种是先 free generation 再加 grounding 的形式,先让大模型任意地生成 item title,因为大模型已经经过 instruction tuning 训练过,因此它生成的这些 token sequence 是已经在 item title 的 space 里的或者已经比较近似了,虽然仍然可能有某些词,比如 10 个词中有 3 个词生成的不对,但是我们会加一个 grounding 的 stage,将其匹配到某一个最相似的 item 上。
另一类手段叫做受限制的生成(constrained generation)。

在当前用 item title 的工作中,我们发现它也可以用非常少的 sample 实现还不错的推荐效果,因为让大语言模型去理解 item title 大概代表的意思相对是比较容易的。
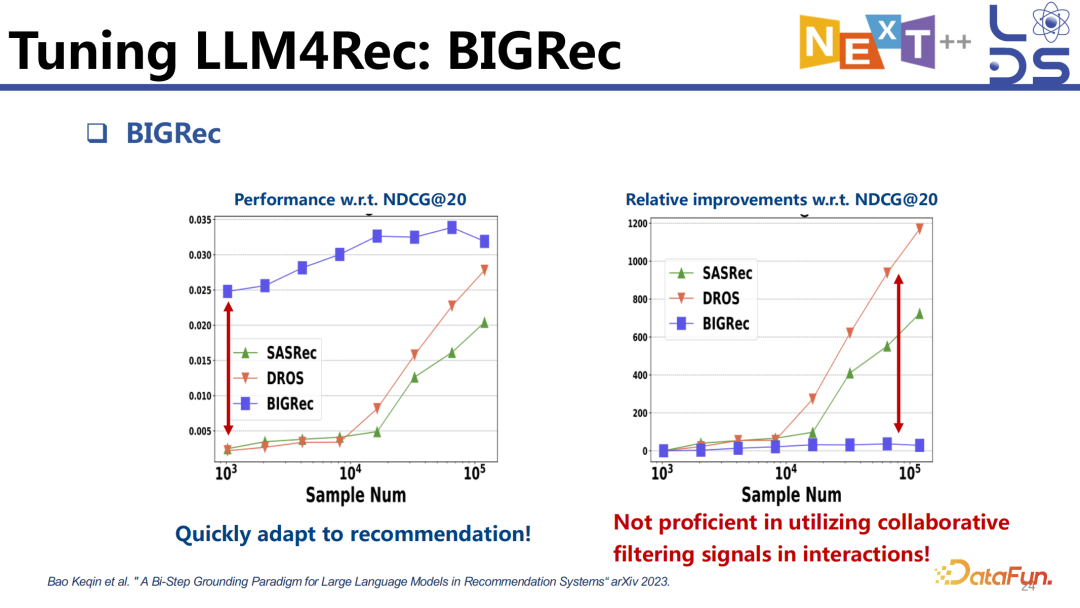
工作中也发现,大模型应用很少的 sample 就能够很快 adapt 到推荐上去,但是再给它增加 sample,提升就不明显了,没有像传统模型一样,当数据增加到一定的规模效果就会猛地提升,它的这个坡就比较缓,每一个比前面一个提升的百分比是非常少的。当数据变多的时候,传统推荐模型能更好地利用协同信息,比如什么样的人会喜欢什么样的 item,这也是为什么只有当数据积累到一定的量传统推荐模型才会做得比较好。但是 BIGRec 的效果提升没有那么显著,一个原因就是它没有很好地利用交互历史中的 collaborative filtering 信息。
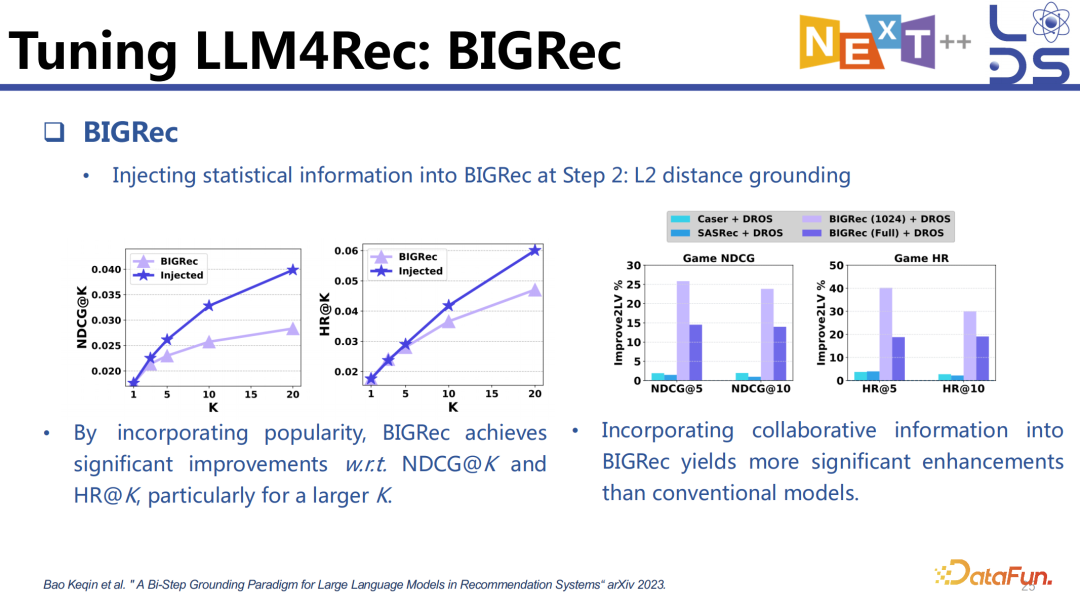
我们可以计算 item 的 popularity,让 BIGRec 做推理的时候考虑到 item 的统计性信息,比如 popularity、什么样的人会喜欢什么样的item 等,注入统计信息与没有注入统计信息相比推荐效果会有显著的提升。
8. Tuning LLM4Rec:
TransRec
下面讲一下前面提到的 constrained
generation 怎样去生成合法的 item identifier (标识符)。
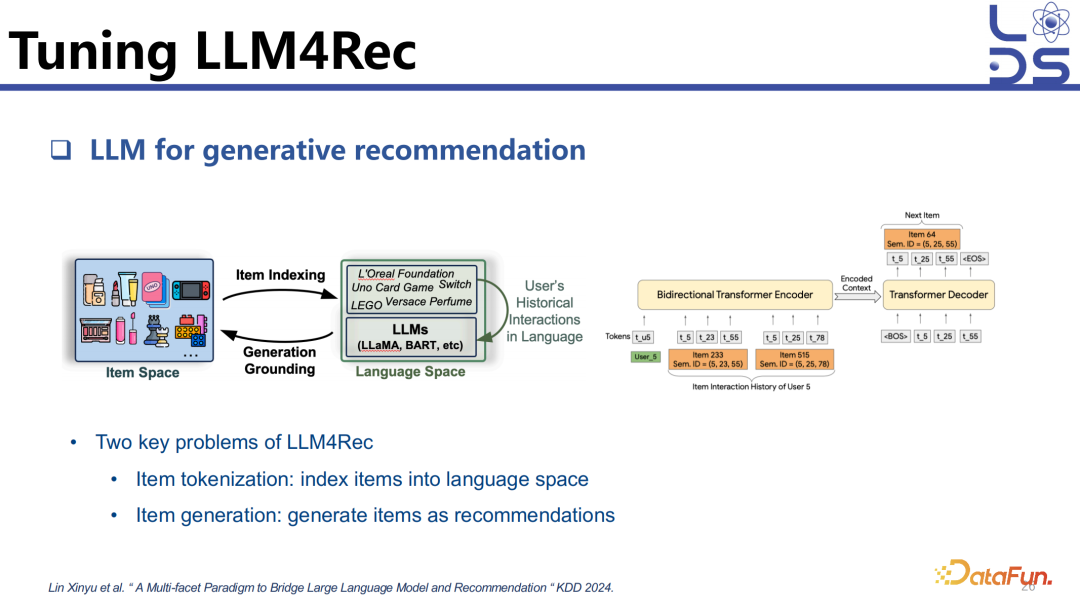
应用 LLM4Rec 去实现有两个比较关键的步骤:
(1)怎样把 item index 到 language model,让模型知道这个 item。item indexing 目前有很多种方法,text base 可以用 item title、item attributes 和 description 以及 ID-based,直接像以前传统推荐模型一样去生成一个 ID,当然这种情况就需要大量的数据去做训练。还可以用 codebook 的形式去生成 item 的 identifier。
(2)怎么去 generate 下一个 item,就是 Generation Grounding 的步骤。可以直接生成 item title,生成 item identifier,也可以直接接一个分类层去做判别。
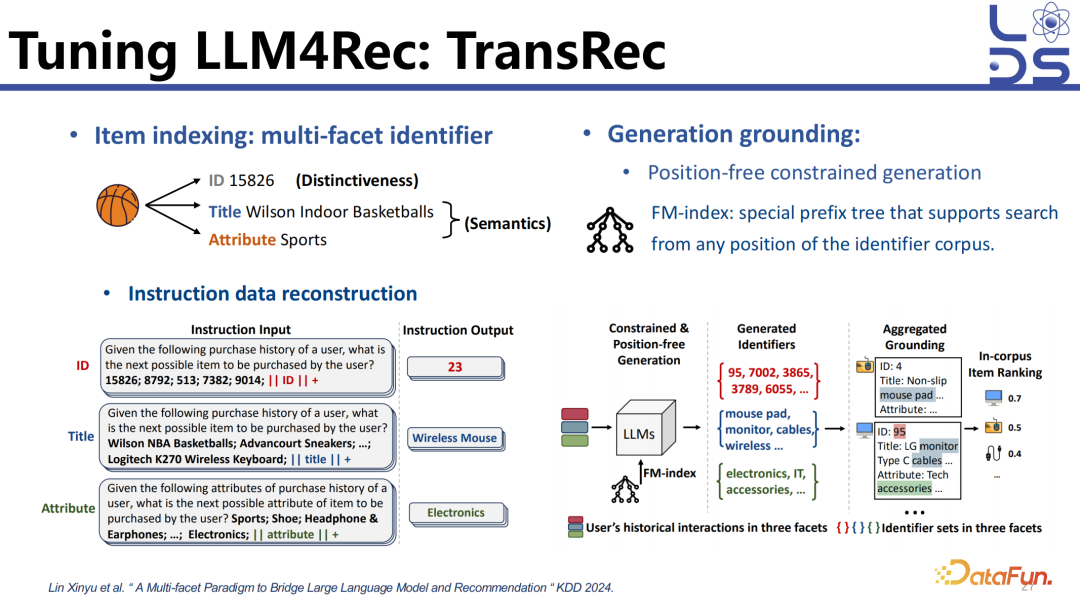
这项工作的思路是可以从多个侧面去表示一个 item,构造一个多侧面 (multi-facet) 的 identifier,这样可以利用 ID 去捕捉 item 之间细微的区别,可以利用 item title 去涵盖 item 的语义信息并且能够跟大模型的预训练知识进行对齐,也可以利用 Item attributes。生成的时候就应用了前面说到的 constrained generation,直观理解的话,可以用树去限制模型在做 token 生成的时候只生成合法的路径,比如在 Beam Search 的时候,先生成第一个 token,再生成第二个 token,在生成第一个 token 之后就有限制第二个 token 只能够生成哪些东西,只可以在合法的 item 标识符集合上进行生成。这个工作用了一个技术叫 FM-index,可以保证从任意位置的 item identifier 进行生成,并在树的基础上去加强限制。
9. Tuning LLM4Rec:
LC-Rec
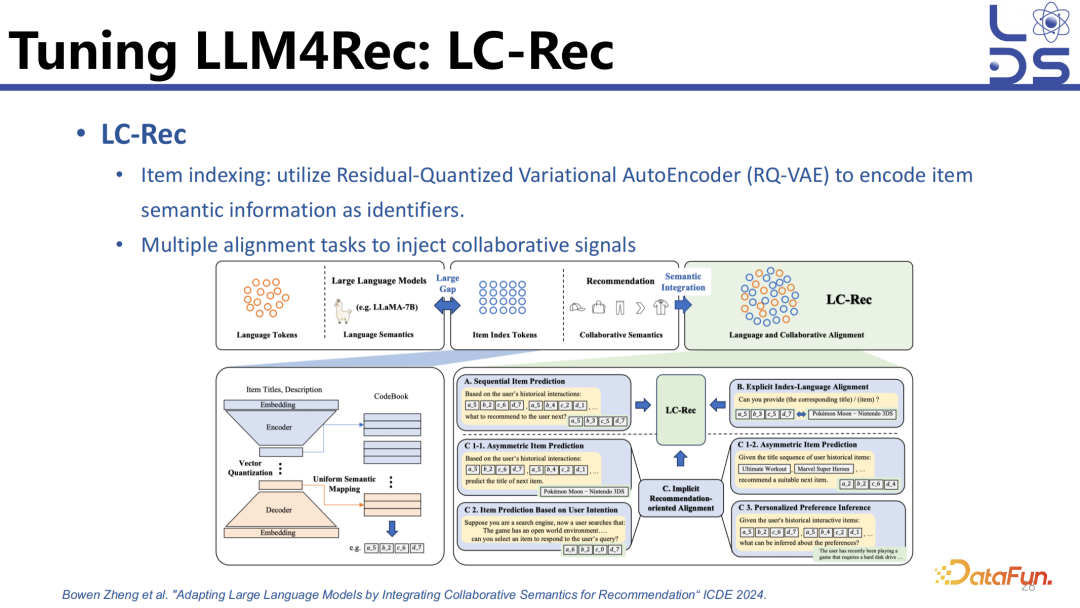
Item index 有三类,一类是 ID 的,一类是 text 的,还有一类是 codebook 的。Codebook 可以利用 item 的多模态信息或者 text 信息、语义信息,可以用 AutoEncoder(RQ-VAE) 的形式,将这些信息编码成多个 code 组合,也就是一个 codebook 里面预存了很多 vector,这些 vector 就像一个 embedding 矩阵一样,并且这个 embedding 是可以学习的。比如输入一个 text 描述,可以用语言模型先把它转化为 dense vector,然后再用 AutoEncoder 进行压缩,压缩的过程中去计算输入的 dense vector 可以拆成 codebook 里哪些 vector 的组合,比如 vector1 加 vector3 加 vector4 等于压缩出来的 vector,那它的 code 就是 134。这种 codebook 的形式就需要大量的数据去训练了,因为 code 所代表的含义大模型是不知道的,只能通过多个任务的训练投喂足够多的数据,才能够实现推断。
10. Agent for
Recommendation

上面我们讲了怎样用 tuning 的方法做好 accuracy,主要利用的还是 text 模态的信息,接下来简单介绍一下 Agent 相关的工作。
一类是 Agent
as User Simulator,通过模拟用户的行为,做 interactive evaluation,作为一个 evaluator 去 evaluate 推荐算法的效果。这个方向上有很多工作,上图中列举了两个代表性的工作。
另一类是 Agent for Recommendation,直接用 Agent 做推荐。这样能够利用 Agent 的一些特性,比如交互性,能够通过自然语言交互以及额外的交互手段,另外 Agent 可以调用 tool,像总控大脑一样去调用各种 tool 满足用户的各种信息需求,比如 RecMind 就是属于这类似思路的工作。当然也可以利用 LLM 的其他能力,比如规划的能力等。
11. Agent: BiLLP
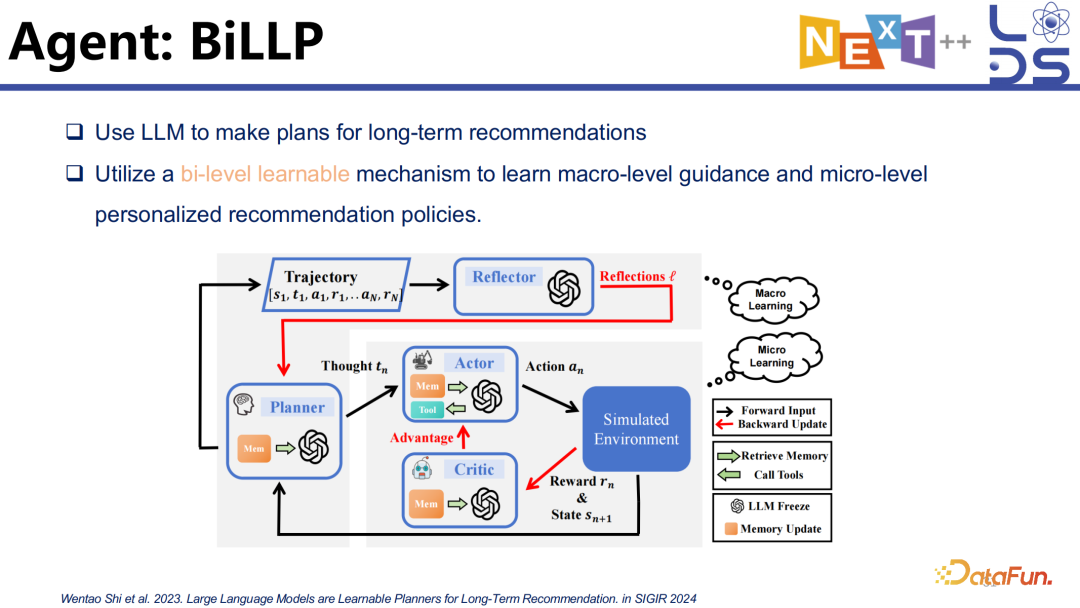
推荐是有长期目标的,比如优化用户的留存率就是多轮推荐上的长期目标,再比如在多轮推荐里去保证推荐的多样性和公平性等也是长期目标。
BiLLP 是 SIGIR’24 的一个工作,将怎样优化长期指标分为两个阶段:一个是宏观层面的规划,一个是微观层面的学习。
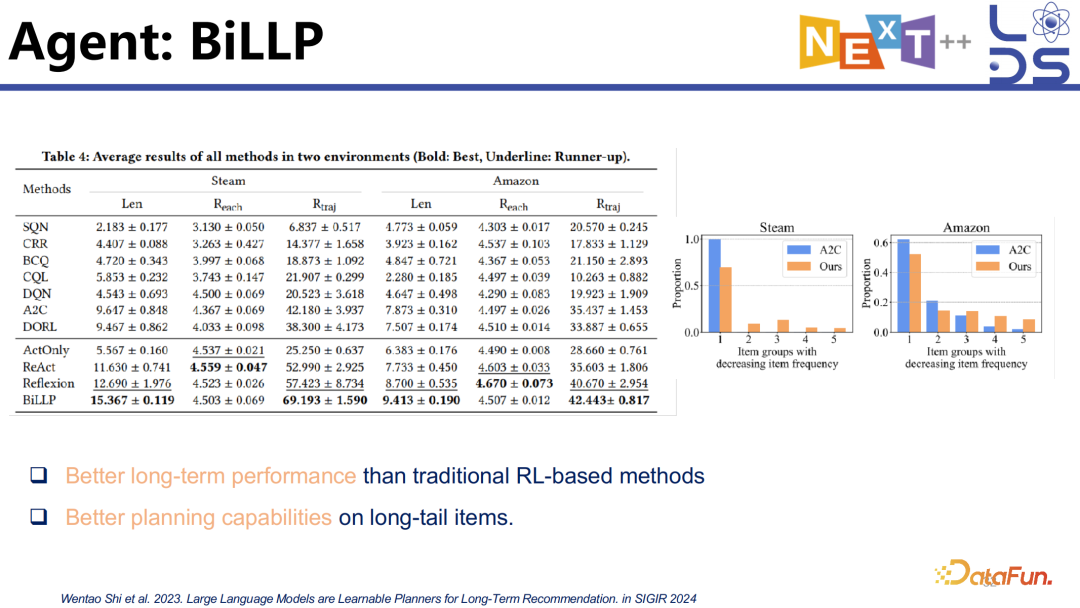
实验中通过多轮 evaluation 的手段发现了该方案在长期推荐上的效果。
12. Trustworthy LLM4Rec

除了优化 accuracy,也有一些工作在做大语言模型对齐方面的工作,比如优化 Fairness,考虑 Privacy(利用 model unlearning 以及联邦学习的方法),以及考虑 Attack、Explanation 和 OOD 的工作。我们把相关工作列在这里,大家如果感兴趣可以去深入阅读。
Open Problems
1. Open Problems
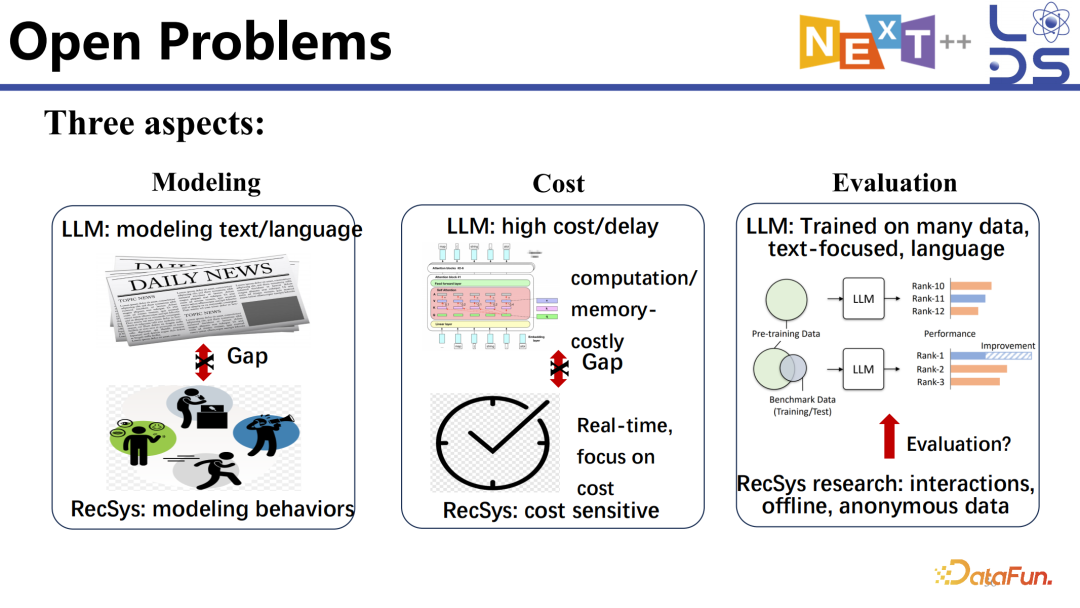
这里简单介绍一些可能存在的 open
problems,重点讲一下我对这个事情的理解。
2. Modeling
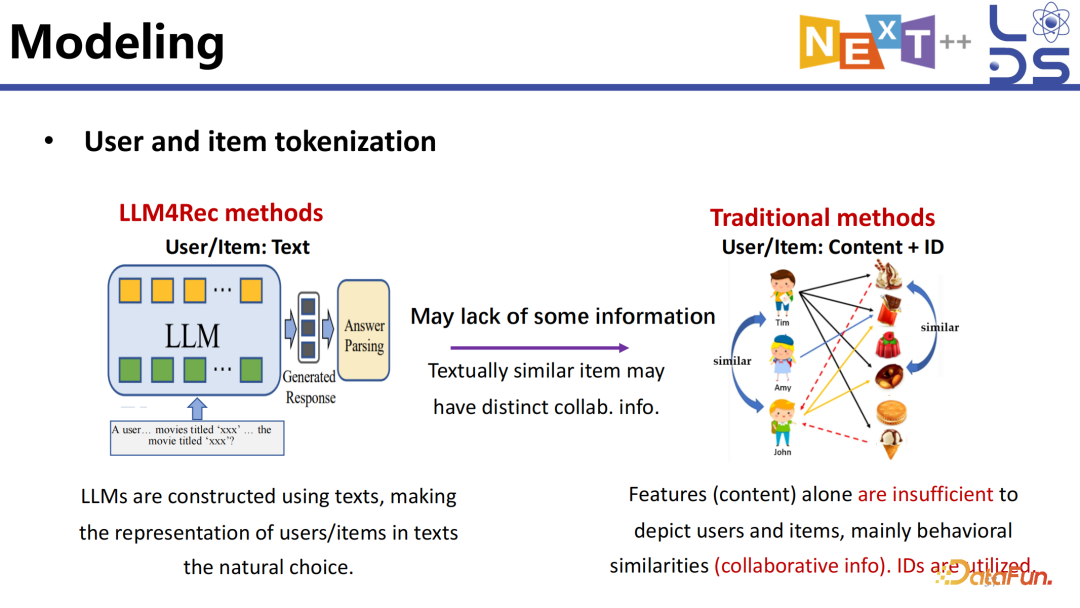
怎样去 tokenize 推荐的数据相对困难,因为推荐是一个关系型数据而不是 fact 数据或者说不是一个纯 text 的数据。为了描述关系,比如有 N 个实体就是 O(N^2) 的复杂度,怎么描述他们的关系是很复杂的事情,尤其是还要建模好协同的信息等。
3. Cost: Training

在不断对推荐模型进行重新训练的过程中,怎样保证 Data-efficient 降低 cost 也是一个值得关注的问题。怎样利用更少的数据更好地对推荐大语言模型进行 fine tuning,做好推荐任务是一个有代表性的工作。
4. Cost: Inference
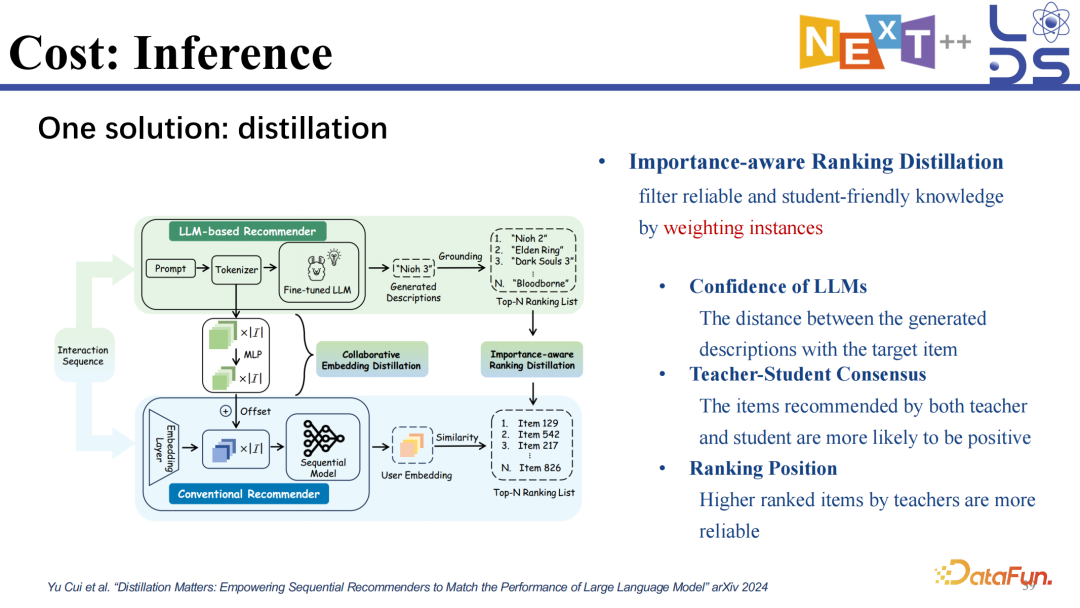
除此以外,inference 加速也很重要。现有的一些想法是先训好一个大模型,再蒸馏成一个小模型,然后在推理阶段用小模型进行推理。
5. Evaluation: Data
Issues

目前有很多推荐数据集,但很多都不太适合做 LLM4Rec 任务。因为我们对非匿名化的语义信息的需求是比较高的,在大模型出来之前,很多数据集都比较老了,有一些大模型在训练的时候已经见过一部分推荐数据了,虽然不能说全见过,但是应该见过其中一部分了,这样怎么去保证公平的测试就是一个问题。我们需要一些新的包含语义信息的没有被大模型见过的评测数据。
另外一个问题是如何去评价交互性,比如在对话式推荐中是需要交互的,当不同的 intervention 之后 policy 是怎么变的,用户的行为是怎么变的,这样一个交互式推荐的 evaluation 也很难,包括多轮推荐里怎么 evaluate 长期指标的实现也是一个比较难的问题。
Future Direction
& Conclusions
接下来简单介绍一下除了这些 open
problems 之外,还有哪些 future direction 是值得做的。
1. Generative
Recommendation Paradigm
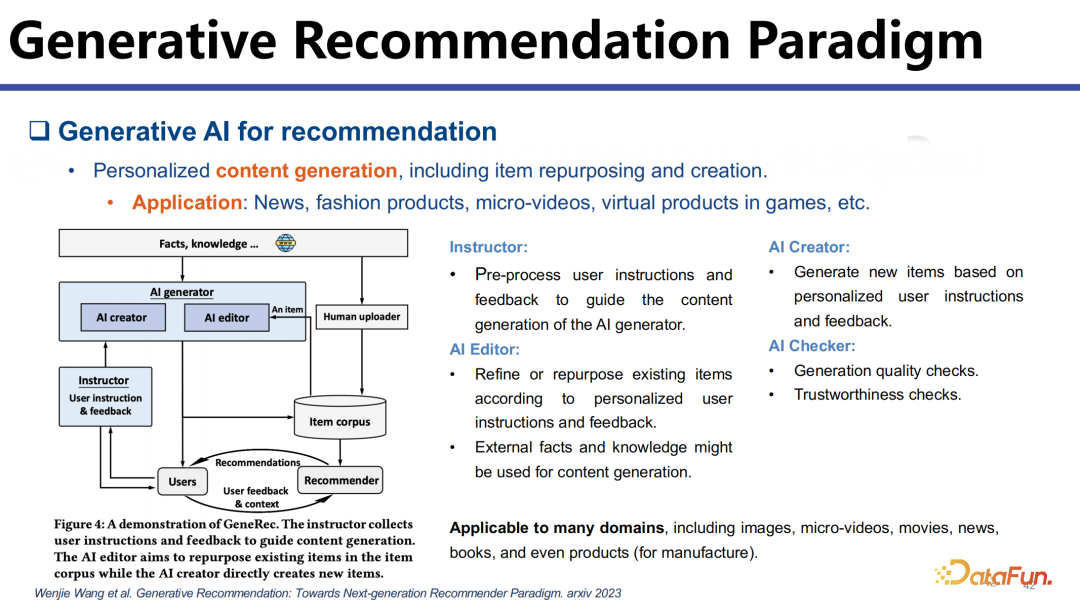
以往推荐里的内容都是人生成的,是专家或用户生成的内容,比如专家生成的新闻、用户上传的短视频等等,但我们认为未来 AI 生成的内容会进一步丰富推荐生态。
一方面,AI 可以去帮助创作者进行创作,现在已经有工具可以帮助用户制作短视频,未来利用 AI 的能力可以帮助创作者和专家生成更加多样化和个性化的东西。比如同样一个做菜的视频,可以为每个人生成不同的版本,比如为老年人生成精简的版本而为年轻人生成更细致的版本。AIGC 大大降低了创作的门槛,未来个性化的内容生成将是一个重要的研究方向。
2. Rec4Agentverse
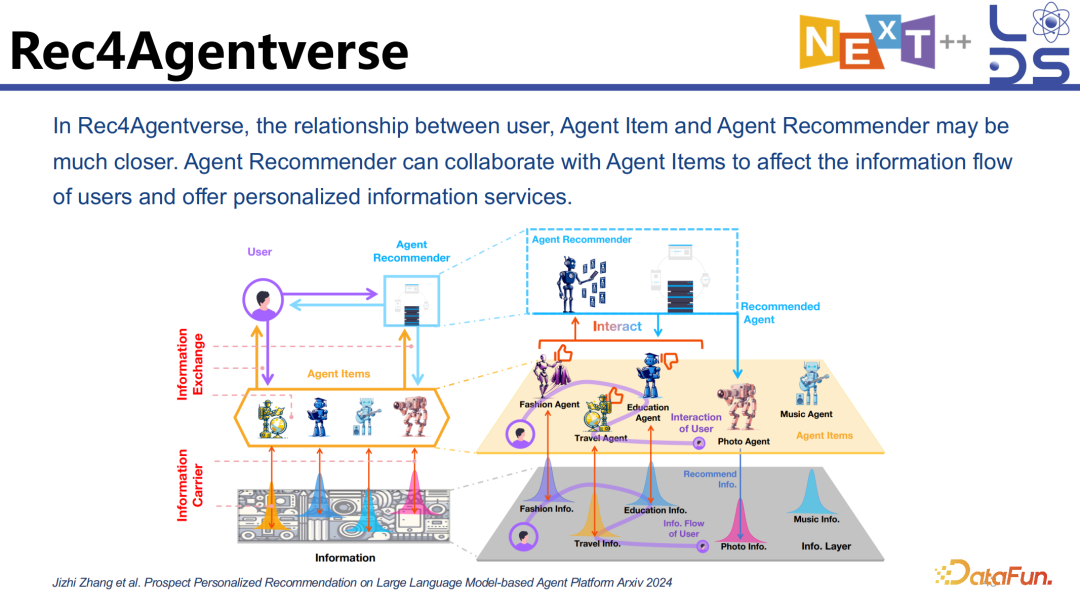
另外一个就是 Rec4Agentverse。在 OpenAI 的智能体平台 GPTs 上,越来越多人开始贡献多种多样的智能体,每个智能体都有自己擅长的部分。未来可能会出现不同的公司都 develop 有自己特色的智能体,这些智能体将构成一个非常多样化的智能体宇宙,有的擅长 fashion 的推荐,有的擅长旅行的规划。那怎样在这么多的智能体中进行个性化的过滤,也就是用户需要什么样的智能体,哪个智能体能为他提供更加个性化的服务,就需要一个 Agent Recommender,能够进行 Agent 的个性化推荐,能够和 Agent 进行交互,像调用 tool 一样让他们来为用户进行个性化的服务。
3. Action Speaker Louder
than Words
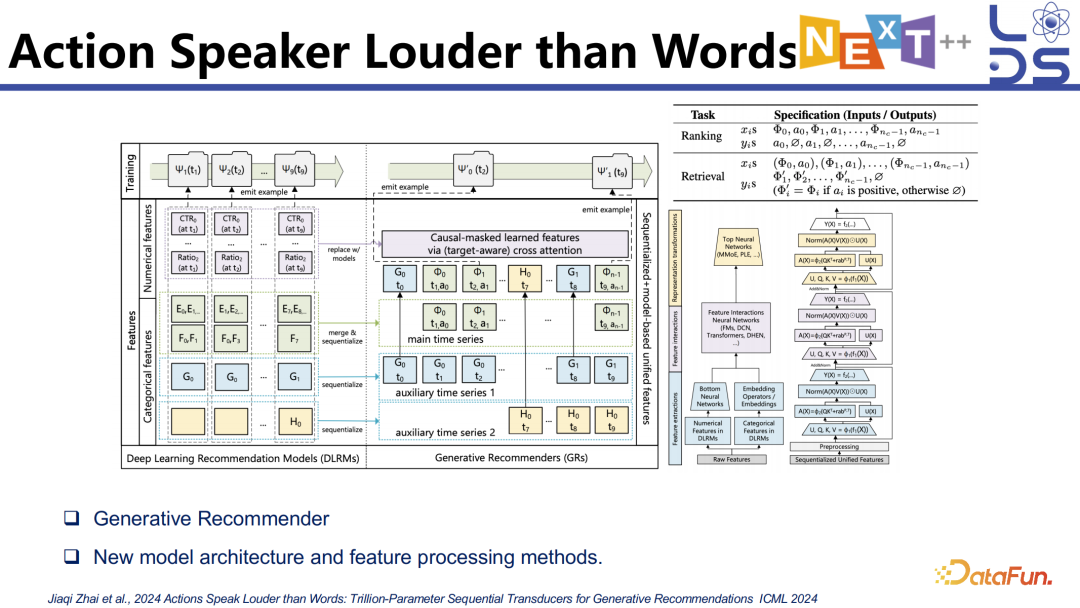
推荐里面的 function model 也有相关探索,这是 Meta 在做的一个 Generative Recommender 的架构。
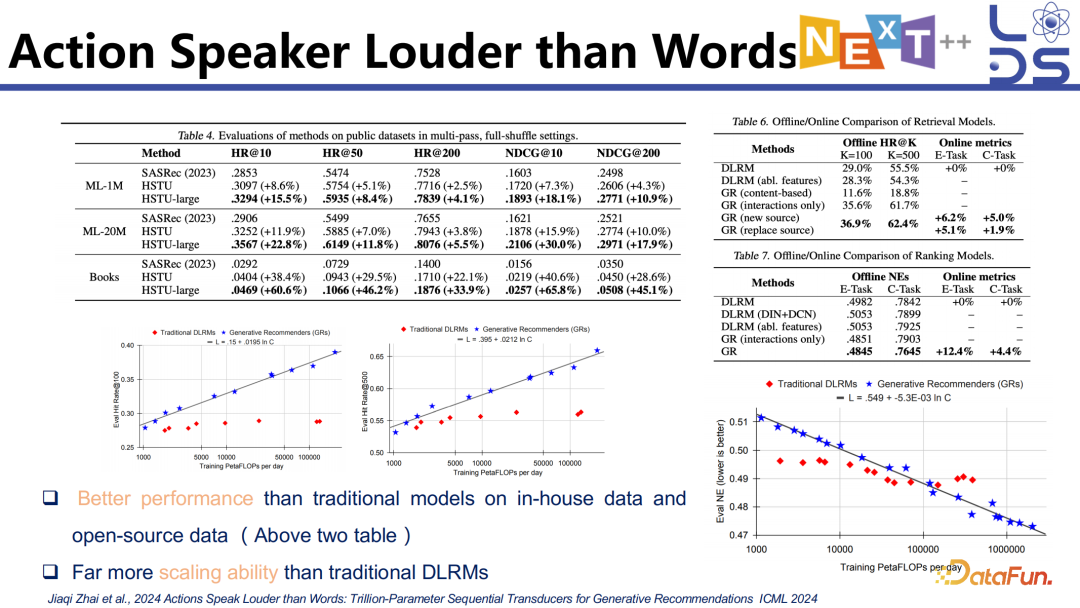
他们发现用生成式模型做推荐,当数据量和参数量增加之后能够实现比传统模型更好的效果。在一些开源的和 Meta 自己的数据上都发现了这样的效果,并且验证了一定的 Scaling Law。
4. Large Behaviour Model

关于 Large Behaviour
Model ,我们已经知道了一些事实,比如 Scaling Law 在某些场景下是存在的,并且能够有比较好的泛化能力。
怎样整合世界知识做推荐,有没有真的利用好预训练的知识。
怎样 tokenize 用户的行为,用户的行为既包含 item,又包含用户的行为类型,还包含不同的 context,能不能和预训练的信息进行一定的对齐也是未来需要探索的一个关键问题。
怎样 model 短期的和长期的行为以及规划短期和长期的目标,也是未来 Large Behaviour Model 需要考虑的问题。
理解用户并且准确地预测好用户的下一个行为,是非常困难的,可能涉及用户的行为建模,但是这个问题的瓶颈在哪里呢?是因为输入的信息不够,还是因为对用户信息的理解不够,还是模型的推理能力不行,还是建模数据的 pattern 太多样化了,到底瓶颈在哪里是未来值得探索的一个问题。如果能够做好 Simulation,能够很好地 predict 用户的下一个行为,我们认为它就可以近似地去做 Ranking 也就是推荐了,因为二者一定程度上是等价的,就是当我能够很好地预测用户的下一个行为的时候,我就能够知道推荐什么东西对用户更好,它们之间是相辅相成的关系,这也是未来推荐大模型值得考虑的一个问题。
Thanks

如果有兴趣获得更多相关信息,可以浏览上图中给出的 tutorial 以及我们的公众号“智荐阁”,我们也会在 SIGIR'24 继续介绍最新的工作。
问答环节
Q1:Action
Speaker Louder than Words 这个工作所用到的用户行为大概是多长或者是怎样的量级?具体是来自于哪些场景的数据?
A1:这个工作是 Meta 的,他们在 paper 里没有讲具体是什么场景,这可能涉及到 Meta 的隐私政策。大概猜测就是 Meta 主要的社交平台,有 micro video 和 image 的信息,包括 post 等。
A2:现在工业界可能更多的是应用 LLM 来增强现有的推荐算法或者推荐模型,工业界不会完全推翻已有的推荐算法,一般都是版本迭代。完全用 LLM 也不太现实,毕竟确实 cost 是比较高的,比如说 Meta action 那个工作也不是用的经典的 LLMs,会做架构和训练方式上的修改。
Q3:LLM 如何帮助推荐系统激励用户产生更好的内容?
A3:这是个很好的问题。在推荐的生态中内容生成是很重要的。但是从学术界来讲对这方面的关注度比较低,学术界认为推荐内容是给定的或者既有在那里的,但其实对一个平台来讲内容还是非常重要的,因为算法进行一定的过滤,首先得保证有好的内容,好的内容在推荐生态里是非常重要的一环。包括很多平台像小红书等都非常注重内容,在这种情景下,我们觉得大语言模型,包括多模态模型,未来肯定能够很好地帮助用户去更容易地生成更 fancy 的内容,比如同样一个视频可以轻易的低成本地去生成很多不同版本的视频。
现有一些工作是在做 personalized
content generation,我们有一个工作发表在今年的 SIGIR'24 上。华为也有一个工作叫做 PMG,在做 Personalized Multi-modal
generation。

































 粤ICP备17114055号
粤ICP备17114055号