本文简介:在大数据和大模型的加持下,现代数据技术释放了巨大的技术红利,通过多种数据范式解除了数据的桎梏,使得应用程序达到了“心无桎梏,身无藩篱”的自在境界,那么现代应用有哪些数据范式呢?这正是本文尝试回答的问题。韦伯总结了现代社会的四个本质特征,其中很重要的一点,现代社会是一个祛魅社会,其本质就是科学性。科学性在于可证伪性,不可证伪的不能称为科学理论,从而用科学理论驱散了世界的神秘主义。类比于此,现代数据技术最大的特征也可以说是祛魅,通过数据范式解除了数据的桎梏,使得应用程序达到了“心无桎梏,身无藩篱”的自在境界。
本文将会介绍现代数据技术如何对数据祛魅,重点不会侧重于数据库技术的演进,而是侧重于从应用视角来审视数据库功能和数据架构的演进。借用时髦的观点,现代应用的数据范式是一个从大数据到大模型的数据范式。现代数据具有4V特性,规模性(Volume)、高速性(Velocity)、多样性(Variety)、价值低(Value)。规模性表示数据量的爆炸性增长,使得单机数据库达到性能瓶颈和容量瓶颈;高速性表示数据产生和处理的速度要快,本质是业务系统对数据实时性的诉求;多样性表示数据类型的多种多样,从结构化数据、到半结构化数据和非结构化数据,本质是业务系统对异构数据存储的诉求;价值低表示数据的总体价值大,但价值密度低,本质是业务系统对数据成本和数据分析提出的诉求。
数据4V特性对企业数据基础设施带来了很大的挑战,传统数据架构很难应对这些挑战。企业必须升级其数据基础设施以能够很好的存储、检索和分析现代数据,从而释放数据的商业价值。- 数据存储:需要能够应对数据海量、数据多样性的存储挑战
- 数据分析:需要能够应对数据量大及价值密度低的分析挑战
下面章节将尝试回答现代数据架构如何解决以上挑战,如果本次没讲清楚,且听下回补充。 传统关系型数据库
传统关系型数据库
数据库作为应用程序存储和检索数据的核心工具,在信息化时代得到了蓬勃发展。关系模型由于其易理解性和完备的数学理论基础从层次模型和网状模型中脱颖而出,成为传统数据库的主流数据模型。关系模型将现实世界中的实体抽象为一张张表格,通过表格之间的关联关系来描绘实体间的联系。在 Codd 发表了《A Relational Model of Data for Large Shared Data Banks》论文后,诞生了一系列伟大的关系型数据库产品,例如 Oracle、MySQL、SQLServer 等。关系型数据库的最大价值在于将应用代码和数据库物理存储结构解耦,这种耦合在论文中被称为“Data Dependencies”。关系型数据库是一项非常成功的数据管理技术,以行和列的方式组织数据,ACID 和 SQL 是其最显著的特性。ACID 提供了数据持久化、数据完整性、事务等特性。SQL 是基于关系代数的查询语言,具有复杂语义的表达能力,能够提供复杂的查询能力(例如 join、聚合、排序等),并为业界广泛接受和运用。
 NoSQL 的兴起
NoSQL 的兴起
随着应用数据量的爆炸式增长和应用模型的复杂化,传统关系型数据库遇到了诸多局限和限制:应用开发者需要为海量数据量进行架构升级,需要处理业务数据与数据库关系模型日益不匹配的问题。这些局限与限制引入了极大的架构升级成本和业务逻辑复杂度,应用开发者将大量精力消耗在业务逻辑以外的地方,这些额外消耗使得应用架构和数据库产品发生了转变。应用架构方面,由数据作为集成点,转变为将数据封装到应用程序中并以服务作为集成点,也就是从数据集成到服务集成的转变。数据库产品方面,促进了数据模型的转变,并产生了诸多不同于传统关系型数据库的 NoSQL 产品。2010 年兴起的的 NoSQL 运动就是数据模型转变的过程,起源于两篇论文,分别是 Amazon's Dynamo 和 Google's BigTable。前者由 Amazon 创建,用于其内部的收藏夹场景,在数据中心故障情况下依然能够提供写入和读取服务,是一个分布式、内置容错能力的 KV 存储,适用于 OLTP 场景。后者由 Google 创建,用于网络爬虫场景,写入抓取到的海量网页数据,然后再由 MapReduce 创建索引,BigTable 提供了高效的 scan 能力,原生支持 MapReduce 计算框架,适用于大数据的实时查询和分析场景。Dynamo 是一个内置容错能力的分布式KV存储系统,面向只需主键访问的业务场景,使用一致性 hash 将数据按主键分布和复制到多个节点上。通过数据版本和应用辅助的方式控制数据访问的一致性,从而提供了松散的一致性语义 — 最终一致性。综上,Dynamo 通过在某些容灾场景下(网络分区或服务器故障)牺牲数据一致性的方式提供了 “always writable” 的服务可靠性,这就是 Dynamo 要解决的 Amazon 电商业务遇到的大规模集群的可靠性挑战,从而可以服务于 mission-critical 的核心业务场景。BigTable 是一个管理结构化数据的分布式存储系统,它维护了稀疏的、分布式的、持久化的、多维的、有序健值对,并提供了多种数据访问的模式(相比而言,Dynamo 只提供了主键访问的模式)。BigTable 支持单行事务,从而允许对单行数据执行原子的“读-修改-写”的序列操作和单行多列操作。BigTable 将各列数据排序存储,并按范围分布到多个节点上,通过 lsm-tree 提供极高的写入吞吐量,通过 COW 技术提高读写性能,通过自动分区分裂实现容量的水平伸缩性。综上,这就是 BigTable 要解决的大规模数据量场景下存储系统的扩展性挑战,从而可以可靠的在数千台机器上处理 PB 级的数据。Dynamo 和 BigTable 都是为了解决各自业务场景所遇到的数据挑战而提出的,两者都有着丰富的设计思路和技术实现。这些设计和实现为后续的很多 NoSQL 产品所借鉴,并经常搭配使用,从而解决业务场景的各种挑战。例如 HBase 借鉴了 BigTable 的数据模型、Cassandra 借鉴了 BigTable 的数据模型和 Dynamo 的分布式设计。主要的非关系模型有KV模型、宽表模型、文档模型、图模型、时序模型等:
- KV模型:主要特征是将每个数据值与唯一的键关联起来,适用于OLTP场景,例如 Amazon's DynamoDB
- 宽表模型:主要特征在于动态列、多版本、TTL,其自动分裂的特性和基于lsm-tree的存储引擎提供了强大的水平伸缩性和写入吞吐量,特别适用于稀疏数据集的海量写入和查询场景。业界主流产品是 BigTable 和 HBase,HBase 是 BigTable 的开源实现
- 文档模型:主要特征在于提供了最接近于真实的业务对象模型的 JSON/BSON 存储格式,是一种对开发非常友好的存储模型。业界主流产品是 MongoDB,其与 Express、Angular、Node.js 等开源技术栈一起构成了 MEAN Stack
- 图模型:主要特征在于提供了点和边的存储语义,可以高效执行跨节点和边的网络查询,易于描述实体间的关系。业界主流产品是 Neo4J
- 时序模型:主要特征在于提供了时间序列数据的建模能力,将时序数据抽象为指标、标签、时间戳三个维度。业界主流产品是 InfluxDB、Prometheus、OpenTSDB 等,InfluxDB 与 Telegraf、Chronograf、Kapacitor 等组件一起组合为 TICK Stack
NoSQL 本质上舍弃了传统关系型数据库的一些功能,从而可以实现更加灵活的特性。这些丰富的灵活的特性简化了应用程序的数据操作,极大简化了业务逻辑。NoSQL 并不是某种特定的数据库产品,甚至没有一个明确的定义,而是一种区别于传统关系型数据库的数据模型和数据管理模式,社区赋予了其更包容和多样化的含义。借用《NoSQL Distilled》中总结的 NoSQL 的共同特征:- Not using the relational model
- Built for the 21st century web estates
在以 Spanner、OceanBase 为代表的 NewSQL 出现后,关系型数据库也能提供非常好的水平扩展性,关系型数据库与 NoSQL 之间的水平扩展性差异大幅缩小。但灵活的数据模型依然是 NoSQL 的独特价值。从应用程序视角,NoSQL 等同于 “Non Relational” 或者 “Non Transactional”,意味着灵活的数据模型和访问接口、可定义的放松的数据一致性,从而提供了关系型数据库以外的另一种选择。且其运行于分布式集群之上,天然具备极好的水平扩展性,能够更好的适用于大数据场景。数据库产品面向 OLTP 业务需要提供的特性可以总结为三类:ACID、水平扩展性、数据模型灵活性,NoSQL 和 关系型数据库各有擅长:
因此,关系型数据库与 NoSQL 具备非常好的特性互补,应用程序往往搭配使用并形成了标准的数据架构。关系型数据库提供 ACID 能力,保证数据持久性和数据完整性,用于 mission-critical 的关键业务场景。NoSQL 提供水平扩展性和灵活数据模型,用于创新场景和大数据场景。两者间的数据划分,可以由应用程序分别写入,也可以通过 event stream/change stream 的方式从关系型数据库流向 NoSQL。- 更灵活的数据模型以提升研发效率:应用开发者的很大一部分精力在于将业务数据的内存结构映射为传统数据库的关系模型,而 NoSQL 提供了诸多可以直接表征业务数据的数据模型,极大简化了业务逻辑
- 更优的数据处理规模和性能以简化应用架构:随着业务的发展,应用程序需要处理更多的数据,需要更快的处理数据,从而让数据更有价值。在传统数据库上处理,会带来更多的应用开发成本和硬件成本,甚至很难搞定,而 NoSQL 被设计为在大规模集群上运行,从而可以很好的应对此类挑战
 NoSQL 的数据范式
NoSQL 的数据范式
NoSQL 的兴起使得业务数据的建模能力得到了加强,使得业务数据不再被其存储形式束缚。NoSQL 与关系数据库一起构建了更立体的数据架构,使得现代应用解除了传统关系模型的局限性,更好的专注于业务逻辑。
关系型数据库对应用程序提供了非常关键的 ACID 能力,使得数据可以安全的完整的持久化,可以安全的并发访问。但关系型数据库并不能适用于所有的企业数据和场景,因此应用程序往往同时使用 NoSQL 应对不同的数据存储需求。两者共同构建了企业在线业务的数据架构 —— Polyglot Persistence,应用程序使用多种数据库产品处理不同类型数据,从而在面临具体数据时可以选择最合适的产品。Polyglot Persistence 非常适合于复杂应用,从而为各种业务数据选择最合适的数据模型。Polyglot Persistence 在提供便利性的同时也引入了架构复杂度,需要在收益和复杂度之间做好权衡。以蚂蚁业务为例,不同类型的业务数据有着各自最合适的数据库产品。交易域业务的数据,模式基本固定,且数据一致性要求很高,非常适合由关系型数据库提供服务,我们会选择 OceanBase;客户域业务的数据,一般跟用户ID直接关联,且是一个典型的读多写少的场景,非常适合由 KV数据库提供服务,我们往往选择 TBase;风控域业务的数据,模式灵活、请求量大、且对数据实时性和查询性能要求很高,非常适合由宽表数据库提供服务,我们往往选择 HBase。CQRS
Polyglot Persistence 是一种数据职责分离的范式,为不同的数据类型选择最合适的数据库产品。另一种数据职责分离的范式是 CQRS(Command Query Responsibility Segregation),将写入操作和读取操作分开。写入操作(Command)通过规范化的关系模型来提供,从而保证数据完整性和数据一致性。读取操作(Query)通过非规范化的数据模型来提供,从而可以获得灵活性和极致性能。两者之间的数据通过异步机制保持最终一致性,可以通过应用程序的异步消息,也可以通过数据库系统的 CDC(Change Data Capture)机制。以蚂蚁的某关系业务为例,该业务通过 MsgQueue 订阅上游业务的事件消息,并把事件数据写到关系型数据库保证数据持久化。然后再通过订阅关系型数据库的 change stream,构建为图模型的关系数据后写入图数据库,图数据库提供关系数据的查询服务。大数据分析与服务
现代应用有着数据实时性的需求,需要实时对海量数据进行分析,从而提供更有价值的数据视图,帮助快速决策。现代数据的4V特性促进了实时数据分析架构的演进,典型的分析技术有 Lambda 架构、HTAP、HSAP 等,代表着若干着不同的设计理念和适用场景。Lambda 架构是一种大数据分析与服务范式,将历史数据的分析和近期数据的分析分别交由不同的系统实现。历史数据的分析由专门的离线环境承担 —— 数据仓库或者大数据系统,离线环境的数据由在线系统的数据导入,分析产生的数据回流在线系统供在线业务访问,往往由擅长高吞吐高性能的点查负载的 NoSQL 承担。由于数据导入、数据计算、数据回流都需要时间,离线环境的数据不是实时的,因此在线系统往往会搭配一套实时计算引擎做近期数据的实时分析,或者直接由在线数据库承担轻量 AP 负载。Lambda 架构使得应用程序能够对海量数据进行实时分析,且提供面向在线业务的优异的访问耗时。以蚂蚁的风控业务为例,当用户发生金融行为时,需要基于该用户的历史行为数据和本次行为数据进行实时分析并作出风险决策,其风险决策的数据分别来自于离线分析链路和实时分析链路,是个典型的 Lambda 架构。 传统检索技术
传统检索技术
传统数据库存储的是标量数据,标量原来是物理上的概念,指只有大小而没有方向的物理量,在数据库这里用标量来表示一类数据类型,例如数字型、字符型、日期型、布尔型,针对该类数据类型可以使用精确匹配的方式进行查询,例如传统关系数据库的 SQL,该检索方式称为标量查询。全文检索是指在非结构化的文本数据中基于特定单词或者文本在全文范围内进行检索。常见的搜索引擎就是对全文检索技术的实现,例如 Lucene、Solr、ElasticSearch 等。我们在网络上使用搜索引擎检索特定内容的数据也是用到了全文检索技术。全文检索是一种非常重要的信息检索技术,可以帮助我们对文本数据进行检索。标量查询和全文检索本质上是关于标量数据或关键字的精确匹配,其查找结果与输入目标之间是完全相同的关系。这与我们下文即将介绍的面向非结构化数据的向量检索的近似匹配有着截然不同的区别。数据库索引是一种用于加速数据查找的数据结构。计算机科学有着丰富的数据结构帮助快速查找,例如红黑树、跳表、位图、布隆过滤器等。对于标量查询和全文检索,常见的索引类型有 B+树/B树、hash树、倒排索引:- B+树:是一种 N 叉排序树,每个节点通常由多个子节点,叶节点存储数据,相邻叶节点通过指针相连,叶节点的数据按序存储。B+树支持两种查找方式:从根节点开始一直到叶节点、通过叶节点的指针顺序查找。B+树与B树的最大区别是B树的每个节点都可以保存数据,而B+树只有叶节点保存数据,因此B+树的范围查找效率更高。B+树适用于点查和范围查找的场景,例如数据库的数据索引和文件系统的元数据索引。MySQL 和 NTFS 采用了B+树,MongoDB 和 ETCD 采用了B树
- Hash树:是一种保存了索引键到存储位置的映射的数据结构,通过哈希函数直接定位到数据存储位置,理想情况下仅需要一次比较就能定位到数据,避免了类似于 B+树结构的多次比较,从而提高查找效率。Hash树适用于需要极致点查性能的场景,不支持范围查找,存在哈希冲突和内存消耗的局限性
- 倒排索引:是一种保存了单词到文档的映射的数据结构,可以根据单词快速获取到包含该单词的文档列表。倒排索引适用于全文检索的场景,能够实现复杂的全文查找功能和文档相关性计算
 非结构化数据的机遇和挑战
非结构化数据的机遇和挑战
白皮书《IDC:2025年中国将拥有全球最大的数据圈》指出:- 2018至2025年全球数据圈将增长5倍以上,将从2018年的33ZB增至2025年的175ZB
- 中国数据圈将从7.6ZB增至48.6ZB,占全球数据圈的27.8%,中国将成为全球最大的数据圈
- 其中超过80%的数据都会是处理难度较大的非结构化数据,如文档、文本、图形、图像、音频、视频等。非结构化数据在大数据时代的重要地位已成为共识
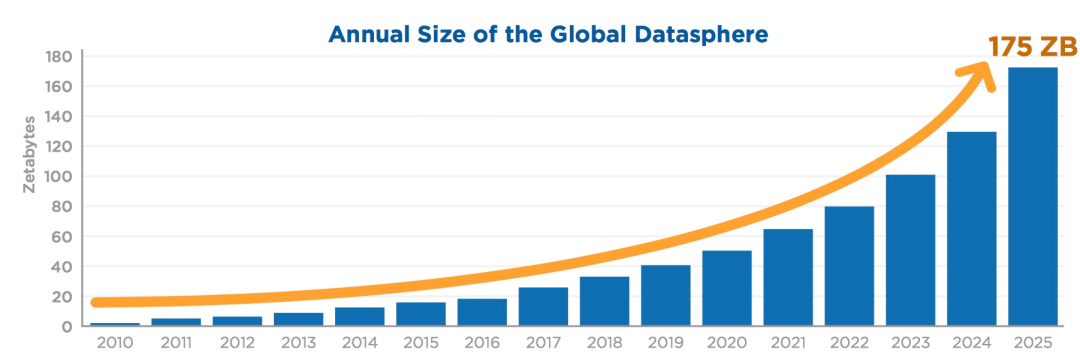
来源:《The Digitization of the World From Edge to Core》传统数据库的标量查询解决了结构化数据的检索问题,但非结构化数据不遵循传统数据库的数据模型,因此传统数据库的检索方式无法处理该类数据,使得企业难以分析非结构化数据。根据调查显示,极少数公司能够有效利用非结构化数据,而非结构化数据往往能够提供更为全景化的视图和整体化的理解,因此挖掘非结构化数据中的信息对于企业发展至关重要,能够带来更大的机遇。 非结构化数据的语义表征
非结构化数据的语义表征
由于数据圈中的数据大部分都是非结构化数据,有效分析非结构化数据将会给企业带来巨大的机遇。我们虽然能够高效存储非结构化数据,例如文件存储、对象存储等,但计算机尚不能按照人的方式来理解图片或者文本中的语义信息。因此将非结构化数据中的语义信息转换为计算机可理解的方式是有效分析的第一步。现代 AI/ML 技术的发展提供了一种从非结构数据中提取语义信息的方式 —— embedding。区别于前面提到的标量类型,embedding 是一种向量类型 —— 由多个数值组成的数组,因此 embedding 又被称为向量或者矢量。embedding 是非结构化数据的数值表示,能够将非结构化数据映射到其“含义”空间,使得计算机能够理解非结构化数据的语义信息。embedding 是区别于传统数据库(包括关系型和 NoSQL)的崭新领域,通过 embedding model 将非结构化数据转换为 embedding。embedding model 本质上是一种数据压缩技术,通过 AI/ML 技术对原始数据进行编码,使用比原始数据更少的比特位来表示数据。压缩后的数据就是原始数据的“隐空间表示”,压缩过程中,外部特征和非重要特性被去除,最重要的特征被保存下来,随着数据维度的降低,本质上越相似的原始数据,其隐空间表示也越相近。因此,隐空间是一个抽象的多维空间,外部对象被编码为该空间的内部表示,被编码对象在外部世界越相似,在隐空间中就越靠近彼此。基于以上理论基础,我们可以通过 embedding 之间的距离来衡量其相似程度。数据的隐空间表示包含了原始数据的所有重要特征,学习原始数据的特征并简化表示的过程,称为表征学习(Representation Learning)。表征学习将原始输入数据映射到隐空间表示,以便更有效的分析和处理,并可以发现原始数据中的隐藏模式和结构。表征学习包括从原始数据中发现特征并表示的一组技术,现代技术主要是深度学习。针对不同的非结构化数据,业界有着丰富的深度学习模型,例如用于文本处理的 Word2Vec、Universal Sentence Encoder、GLoVE,用于图片处理的 ResNet50、MobileNet、CLIP,用于视频处理的 OpenCV,用于音频处理的 PANNs 等。因此,embedding 是非结构化数据的统一语义表征,是现代 AI/ML 的通用语言。有了非结构数据的语义信息的数值表示,接下来我们将直面第二个挑战:如何构建高效的 embedding 检索服务 —— 向量检索服务。 非结构化数据的检索
非结构化数据的检索
向量检索服务是专门存储、索引和查询由机器学习模型生成的非结构化数据的向量表征的服务。本节我们将介绍向量检索服务的核心技术和产品形态。区别于标量数据的精确匹配,向量检索是一种基于距离函数的相似度检索,由于向量间的距离反映了向量的相似度,因此通过距离排序可以查找最相似的若干个向量。向量检索算法有 kNN 和 ANN 两种:- kNN(k-Nearest Neighbors)是一种蛮力检索方式,当给定目标向量时,计算该向量与候选向量集中所有向量的相似度,并返回最相似的 K 条。当向量库中数据量很大时 kNN 会消耗很多计算资源,耗时也不理想。
- ANN ( Approximate Nearest Neighbor)是一种更为高效的检索方式,其基本思想是预先计算向量间的距离,并将距离相近的向量存储在一起,从而在检索时可以更高效。预先计算就是构建向量索引的过程,向量索引是一种将向量数据组织为能够高效检索的结构。向量索引大幅提升了检索速度,但返回的是近似结果,因此 ANN 检索会有少量的精度牺牲。
向量的相似性度量基于距离函数,常见的距离函数有欧式距离、余弦距离、点积距离,实际应用中选择何种距离函数取决于具体的应用场景:- 欧式距离衡量两个向量在空间中的直线距离。欧式距离存在尺度敏感性的局限性,通过归一化等技术可以有效降低尺度敏感性对相似度的干扰。欧式距离适用于低维向量,在高维空间下会逐渐失效
- 余弦距离衡量两个向量之间夹角的余弦值。余弦距离存在数值敏感性的局限性,因为其只考虑了向量的方向,而没有考虑向量的长度。余弦距离适用于高维向量或者稀疏向量
- 点积距离通过将两个向量的对应分量相乘后再全部求和而进行相似度衡量,点积距离同时考虑了向量的长度和方向。点积距离存在尺度敏感性和零向量的局限性。
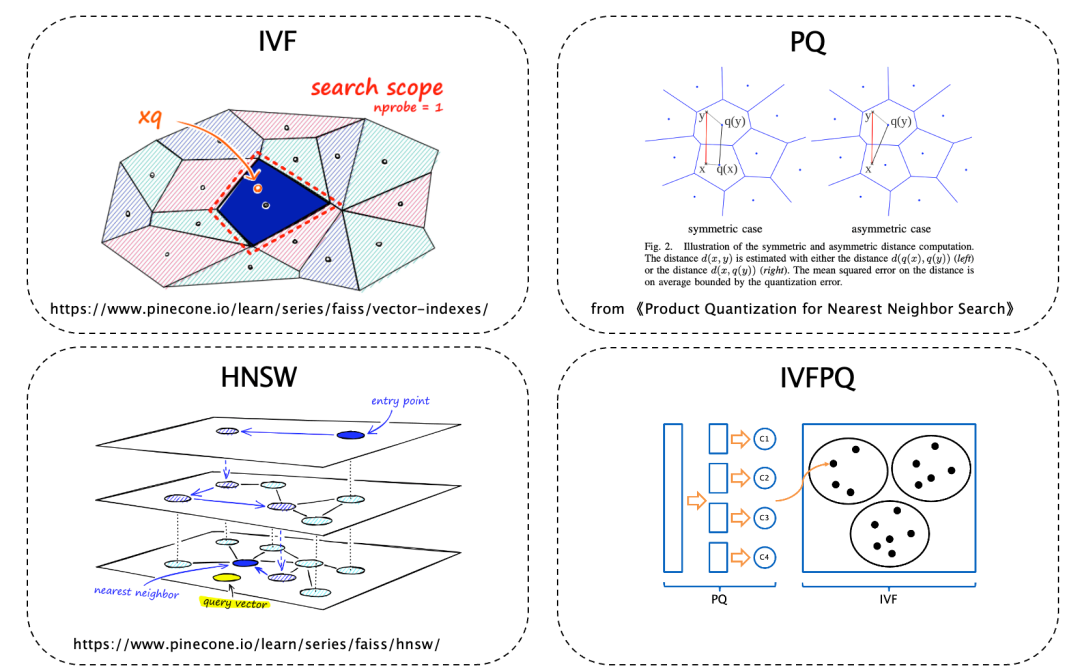
来源:https://www.restack.io/p/similarity-search-answer-image-similarity-cat-ai对于向量检索,常见的 ANN 索引类型有 IVF、HNSW、PQ、IVFPQ:- IVF(lnverted File):将候选向量集基于 k-Means 进行聚类,类簇数在建立索引时通过 nlist 参数指定。检索时遍历与目标向量距离最近的若干个类簇下的所有候选向量并计算目标向量与候选向量之间的距离。遍历的类簇数通过参数 nprobe 指定,扩大 nprobe 可以提高检索精度,但会增加耗时。
- HNSW(Hierarchical Navigable Small World):一种类似于跳表的数据结构,最底层包含候选向量集中所有的向量,层次向上节点数逐渐减少,遵循指数衰减的概率分布,节点加入时依据概率函数得出最高投影到第几层,该层往下每层都包含该节点。检索时从最高层的进入点出发,搜索距离目标向量最近的点,收敛后进入下一层继续搜索,直至到达最底层。
- PQ:一种量化技术,将高维向量切分为若干段维数相等的子向量(由参数 M 指定),然后对所有候选向量(假设总数为 N )的相同段的子向量进行聚类,最后把每个候选向量用其每段子向量的簇心来表示,从而将高维向量映射为 M 个簇心的 ID,通过该方式能够大幅优化内存。查询时将目标向量同样切分为 M 个子向量,并计算每个子向量与对应段所有簇心的距离,距离值用于后续计算相似度。衡量目标向量与某个候选向量的相似度时,查询目标向量每个子向量与候选向量对应段映射到的簇心的距离并求和,总和即为两个向量间的距离。PQ 对向量查询进行了优化,将一个 N 次高维向量计算优化为 M 次低维向量计算及 M*N 次查表操作,从而大幅优化查询耗时和内存消耗。
- IVFPQ:PQ 对衡量相似度的计算过程进行了优化,如果候选向量集很大,查询效率依然不够。因此可以将 IVF 与 PQ 技术相结合,首先通过 IVF 技术优化为仅需选取候选向量集的一部分进行比对,再通过 PQ 技术优化衡量目标向量与候选向量之间相似度的过程。IVFPQ 使得查询时需要比对的候选向量个数大幅减少,也使得每次比对的计算消耗和内存消耗大幅优化,从而获得查询效率的提升。
- kNN 是蛮力检索方案,适用于对检索精度较高的业务场景,例如生命科学、金融等,kNN 也可以用来衡量 ANN 算法的召回率;ANN 是近似检索方案,牺牲一定的检索精度以加速检索,适用于对实时性要求较高的业务场景,例如流计算、实时推荐等,ANN 算法有 IVF、HNSW、IVFPQ 等。
- IVF 和 HNSW 是两种常用的 ANN 索引算法,前者基于聚类算法,后者基于图算法。在 topK 比较小的情况下(数百级别),HNSW 的召回率较高。在 topK 比较大的情况下(数千级别),IVF 的召回率较高。因此需要基于场景选择合适的索引算法,例如推荐场景选择 HNSW 比较合适,广告场景选择 IVF 比较合适。
- PQ 和 IVFPQ 是基于压缩的索引算法,使用 PQ 技术对向量进行有损压缩,以节省内存。PQ 是基于压缩的蛮力检索算法,IVFPQ 是基于压缩的近似检索算法。
以上我们介绍了向量检索服务的核心技术,包括检索算法、相似度度量算法、索引构建算法。应用程序在实际运用中并不需要从头构建,业界有着丰富的支持向量检索的产品,主要由三种产品形态,分别是向量检索库、专用向量数据库、支持向量检索的普通数据库:最后来个总结,向量检索服务基于 AI/ML 技术计算目标向量与候选向量集中向量的相似度,并返回最相似的若干条向量。ANN 算法提升了查询速度,使得查询耗时对应用程序更友好。ANN 算法在大幅提升查询速度的同时,有少量的查询精度牺牲,如果对查询精度要求更高,可以选择 kNN 算法查询。上节介绍的 embedding 解决了非结构化数据的“语义”难题,本节介绍的向量检索服务解决了 embedding 的“检索”难题,两者一起提供了区别于传统数据库的面向非结构化数据的检索方案。 非结构化数据检索的数据范式
非结构化数据检索的数据范式
现代 AI 技术的发展使得非结构化数据的检索能力得到了空前加强,进而使得现代应用解除了非结构化数据的桎梏,应用程序有了更多基于非结构化数据的数据范式。混合检索
传统检索技术和面向非结构化数据的向量检索技术是两种完全不同的检索技术:- 传统检索技术:包括传统数据库的标量查询和全文检索。标量查询提供了面向标量字段的过滤功能,是一种精确查询。全文检索提供了面向文本数据全文的基于单词或者文本的精确匹配功能,相对于标量查询,全文检索能够容忍拼写错误、同义词、前缀查询、模糊查询等问题,从而允许使用不完整的信息进行检索。全文检索虽增加了查询的模糊性,但本质上依然是精确查询,因此传统检索技术最本质的特征在于“精确性”。
- 向量检索技术:向量检索是一种 AI 驱动的检索方式,提供了面向非结构化数据的语义检索能力,能够用人脑理解知识的方式去检索数据,其最本质的特征在于“语义性”,是一种“相似性”检索。
传统检索技术善于精确查询,但缺乏语义理解。而向量检索技术能够很好的识别用户意图,但在精确检索方面召回率大概率不如传统检索技术,两种技术都不完美。对于特定的检索场景,两者结合能够提供更准确的检索结果:混合检索正是将传统检索技术与向量检索技术相结合的艺术,从而可以博采众长,相辅相成。它将传统检索技术的按关键字检索与向量检索技术的按语义检索的能力相结合,提升了最终结果的准确性与全面性,更适合面向现代多元化数据的检索场景。混合检索有效的结合了多种检索技术,以提升检索召回率,但提出了对多个结果集重新排序的难题。全文检索返回的结果集基于TF-IDF、BM25等文档相关性评分排序,向量检索返回的结果集基于距离函数的相似性评分排序,应用程序需要对两者的结果进行重新排序(Re-ranking)。重新排序指将来自多种检索技术的有序结果集进行规范化合并,形成同一标准的单一有序结果集。单一有序结果集能够更好的供下游系统处理和分析。常见的重新排序算法有 RRF、RankNet、LambdaRank、LambdaMART 等。检索技术是现代计算机科学解决的主要课题之一,传统的检索技术主要基于倒排索引技术,应用程序可以基于此技术构建全文检索的功能。现代 AI 技术的发展使得检索技术的能力得到了空前加强,能够对更多的非结构化数据进行更强大的语义检索,检索技术彻底解除了非结构化数据的桎梏。应用程序在检索技术红利的加持下得到了功能加强,或者从零到一破土而生,例如搜索引擎、推荐系统、问答系统等,能够处理更加多样化的非结构化数据。RAG
RAG (Retrieval-Augmented Generation)是检索技术与大模型技术相结合的数据范式 —— 在知识库中检索与用户查询最相关的内容,然后将其提供给大模型用于知识生成,使得大模型能够利用最新数据和私域数据。如果没有 RAG,那么大模型的知识生成就只能完全基于预训练的数据,会面临“幻觉”、缺乏特定领域知识或私域知识、大模型的数据新鲜度不够等问题。Fine-tuning 也能部分解决这些问题,但召回率不够,且代价高昂。RAG 非常完美的解决了这些问题,其本质上是一个私有搜索引擎,使得大模型生成的知识更准确更新鲜,使得企业能够基于私域数据建立大模型应用,使得能够建立垂直行业的大模型应用。RAG 经业界不断探索,架构经过多轮调整,最完整的架构如下图所示,其结合了关键词检索、图检索、语义检索等多种检索技术,及重新排序算法,从而提供更准确的检索结果和生成结果。应用程序在实际运用中并不需要完整搭建这个脚手架,社区有着丰富的框架直接使用,例如 LangChain、LlamaIndex 等。来源:https://github.com/langchain-ai/rag-from-scratch/blob/main/README.mdVectorDB 就像海马体,负责信息提取。LLM 就像大脑,负责新信息的生成。两者解决了如何基于已有知识生成新知识的问题,而 Agent 负责执行,从而对物理世界产生实际影响。LLM、VectorDB、Agnet 是 AI native 应用的智能基础设施,VectorDB 是其中最重要的组成部分。The most important piece of the preprocessing pipeline, from a systems standpoint, is the vector database. It’s responsible for efficiently storing, comparing, and retrieving up to billions of embeddings (i.e., vectors).
- https://a16z.com/emerging-architectures-for-llm-applications/
本文的副标题是“从大数据到大模型”,最后再点下题:信息化时代定义了关系型数据库的数据范式。关系型数据库的本质特征在于 ACID,对应用程序提供了数据持久化、数据完整性、事务等应用语义,使得应用程序可以将数据管理的职责完全交给数据库。更重要的是,相比于层次模型和网状模型,关系模型的存取路径对应用透明,从而使得应用代码从具体的数据格式中解耦出来,极大简化了应用开发过程。关系型数据库是信息化时代的数据范式,解除了数据存储的桎梏,推动了信息化时代的蓬勃发展。谷歌的老三篇 GFS、Map Reduce、BigTable 开启了大数据时代,大数据时代定义了 NoSQL 的数据范式。传统数据库在大数据场景下面临水平扩展性不够、数据模型单一等局限性,而 NoSQL 弥补了关系型数据库的这些不足。NoSQL 首先提供了非常好的水平扩展性,能够可靠的在数千台机器上处理 PB 级的数据;其次提供了灵活的多样化的数据模型,使得应用程序能够所见即所得的将业务数据映射为数据库的存储模型。获得扩展能力的同时,可能会牺牲一定的数据一致性,因此往往与关系型数据库搭配使用。NoSQL 是大数据时代的数据范式,解除了数据规模和业务数据复杂性的桎梏,推动了互联网时代及移动互联网时代的发展。2022年底,OpenAI 的大模型 ChatGPT 正式发布,开启了生成式 AI 时代,生成式 AI 时代定义了 LLM + VectorDB 的数据范式。传统数据库擅长处理结构化数据,面对非结构化数据时心有余而力不足。LLM + VectorDB 提供了非结构化数据的语义理解和检索能力,而数据圈超过80%的数据都是非结构化数据,从而使得这些数据中的信息得以释放变成实际的生产力。LLM + VectorDB 是生成式 AI 时代的数据范式,解除了非结构化数据的桎梏,推动了 AI navive 应用的发展。

































 粤ICP备17114055号
粤ICP备17114055号