推荐语
掌握大模型时代的视频封面生成技术,提升内容电商转化率。
核心内容:
1. AIGC内容生成技术在手淘的规模化应用
2. 动态封面与静态封面的优化实践
3. 封面生成AIAgent在直播和视频场景的应用效果
杨芳贤
53A创始人/腾讯云(TVP)最具价值专家
作为一种新的商品表现形态,内容几乎存在于手淘用户动线全流程,例如信息流种草内容、搜索消费决策内容、详情页种草内容等。通过低成本、高时效的AIGC内容生成能力,能够从供给端缓解内容生产成本高的问题,通过源源不断的低成本供给倒推消费生态的建立。过去一年,我们通过在视频生成、图文联合生成、个性化文案、人设Agent等核心技术上的持续攻关,AIGC内容生成在手淘多个场景取得了规模化落地价值。本专题《淘宝的AIGC内容生成技术总结》是我们摸索出的一部分实践经验,我们将开启一段时间的内容AI专题连载,欢迎大家一起交流进步。
序言
淘宝近年来积极推进从传统货架电商向内容电商的战略转型。视频和直播作为内容电商的核心载体,旨在通过丰富的内容消费来促进用户订单的转化。然而,业务实践中发现,用户自主上传的封面质量参差不齐,低质量的封面直接影响用户的点击意愿,进而影响转化,尤其是有一些内容优质但是封面劣质的视频,由于没有优质的封面淹没在了内容的大海中,显得尤为可惜。
进一步分析,在不同的网络环境下,用户所展示的封面形式也有所区别:用户在移动数据流量环境下展示的是静态封面,而在WIFI环境下则展示动态封面。同时,封面存在于淘宝域内的多个业务场景下,不同业务场景对封面的需求有异有同,因此,如何在保证封面效果吸睛的同时,提升算法的多场景可迁移性,也成为我们需要考虑的问题。基于上述背景,我们设计了一个基于多模态大模型的封面生成AIAgent,面向直播和视频场景的动态封面和静态封面,提供灵活高效的解决方案,以期在封面中浓缩直播和视频内容中最有价值、最具有吸引力的信息展示给用户,提升站内内容的点击率,进而拉动整体的内容消费。▐ 1.静态封面
这里我们以搜索场域为例,列举了一些封面劣质的视频,并对比了优化前后的封面效果。
事实上,上述案例仅是淘内大量视频内容的冰山一角,这些视频内容或优或劣,但可能由于封面的质量不过关,在淘宝站内没有获得较好的分发。对比之下,我们优化后的封面中,商品主体清晰、构图美观、展示形式对用户具有较强的吸引力,并通过营销花字突出商品卖点,将核心信息快速传达给用户,从而能够发挥内容的最大上限。
▐ 2.动态封面
以下是我们为直播频道页直播卡生产的高光动态封面案例。
直播卡在WIFI网络环境下默认展示给用户的是直播实时流,实时流的优势是所见即所得,但问题是可能会出现无商品展示的空镜,或者主播实时展示商品的片段不够吸引人的情况,从而影响用户进入直播间的意愿。我们将实时流替换为商品展示的10秒高光片段,作为直播间的动态封面。AB实验表明,我们的方案相比其他两路动态封面方案,获得了最为显著和有效的点击率提升。
在大模型蓬勃发展之前,已有许多算法自动化生产的封面投入应用。但是这些方案存在明显的通病,依据技术路线的不同,可以总体分为以下两类:
定制化小模型组合方案:针对每个业务需求定制开发并训练多个评估小模型(如人脸检测、人眼检测、商品检测等),综合多个小模型的结果选择封面。此类方法依赖的模型数量多,对于业务个性化需求的迁移能力差,难以适应快速变化的业务需求。
黑盒端到端方案:直接通过黑盒模型的方式端到端产出封面,实现技术上的优雅,但在实际应用中的可解释性较差。当不同业务方的实际需求存在差异时,模型的迁移难度和成本较高。
为了解决上述问题,我们提出了一套基于多模态大模型的封面生成AIAgent系统。该系统采用模块化的Agent架构,融合了多模态大模型的能力,通过各个模块的协同工作,系统能够以白盒、灵活、高效的方式支持不同的业务需求,实现高质量封面的自动化生产。
封面生成AIAgent包含以下核心模块:
Planning-规划模块:基于大语言模型,解析复杂的业务需求,制定封面生成策略和工作流。
Memory-记忆模块:基于内容理解得到的优质封面特征,构建知识库,存储封面生成的规则和评价标准,指导封面的个性化生产。
Action-行动模块:执行封面生成的具体操作,包括长视频处理、智能选帧、营销花字生成与自动布局等功能。
Reflection-反思模块:利用评价模型,对生成的封面进行质量评估,反馈优化建议,形成闭环,不断提升封面质量。
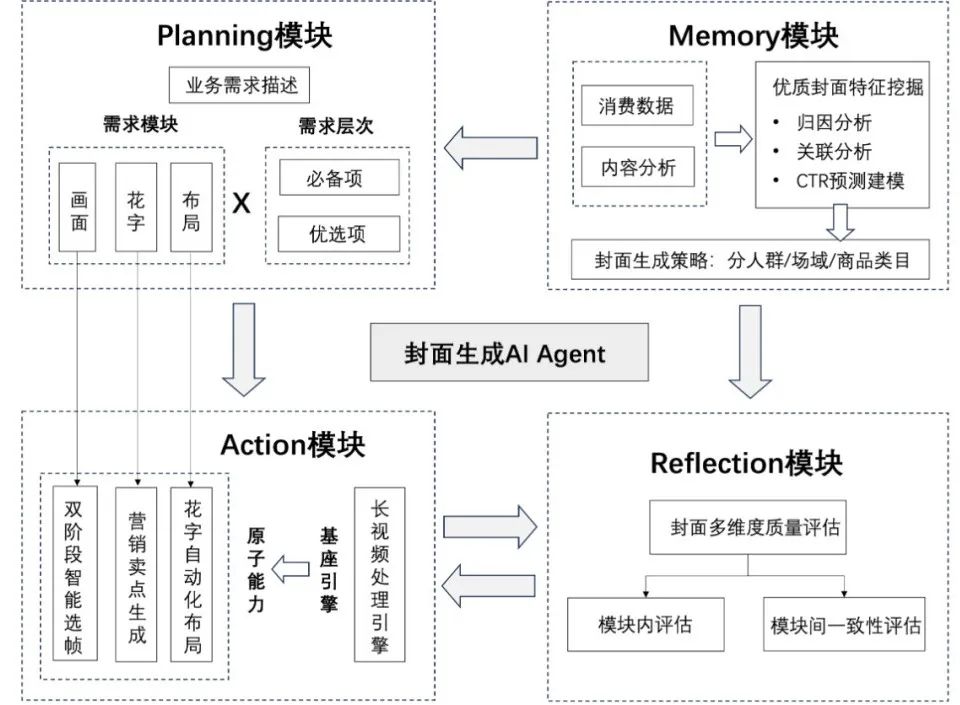
接下来,我将详细介绍各个模块的技术实现以及模块之间的协同。
▐ 1.Planning-规划模块
背景
在淘宝域内,封面存在于多类业务场景,业务场景对封面的需求存在较高的复杂度和多样性。具体地,不同的业务场景对封面的需求有异有同,如直播频道页要求封面中出现主播,但视频封面则不对此强制要求。即便是在同一业务场景下,由于面向行业的不同,也存在需求上的细粒度的差异。如搜索场域希望服饰行业的视频可以展示整体的穿搭效果,美妆行业的视频希望更侧重展示使用效果。
我们希望构建起支持业务自定义需求的可配置的业务规则引擎,支持业务输入一段任意的封面要求定义文本,系统自动解析、拆解并执行。
方案设计
针对业务需求的复杂性和多样性,我们设计了Planning模块。该模块利用大语言模型强大的拆解和规划能力,支持业务方对封面的复杂需求描述输入,自动解析需求并制定封面生成策略。具体来说,它将需求拆分为画面、文案、布局三大类,并根据需求的重要程度划分为必须满足(HavetoHave)和最好满足(BettertoHave)两类,然后路由至各个Action执行模块(如智能选帧、文案生成、自动布局)。
之所以将需求分为“必须满足”和“最好满足”两类,是因为需求的严格程度不同,需要在Action执行模块和Reflection模块中采取不同的处理方式。某些质量要求必须达成,例如图片清晰、无模糊,若有人物则需要眼睛睁开。而某些质量要求在最佳情况下满足即可,若无法满足也可接受。例如,关于上身穿搭展示服饰的要求,可能视频中仅有主播手持服饰展示的画面,在这种情况下,可以适当放宽此要求。
通过上述设计,Planning模块能够灵活、高效地处理多样化的业务需求,确保封面生成符合业务期望,并提升系统的可配置性和扩展性。
▐ 2.Memory-记忆模块
背景
由于业务场景复杂,业务方可能难以制定完善、合理且有效的封面选帧质量评估体系。若能基于域内不同封面的后验消费数据,分析优质封面的特征,为业务提供先验知识,将有效指导业务方制定评估体系,并指导封面生产策略。
方案设计
我们在封面AIAgent中设置了Memory模块,存储了一套预定义的封面选帧质量评估体系。该评估体系利用内容分析Agent,通过对优质封面的细粒度内容分析,得出先验结论。具备这些特征的封面通常具有更高的点击率,可在业务方封面质量需求不明确的情况下作为参考。
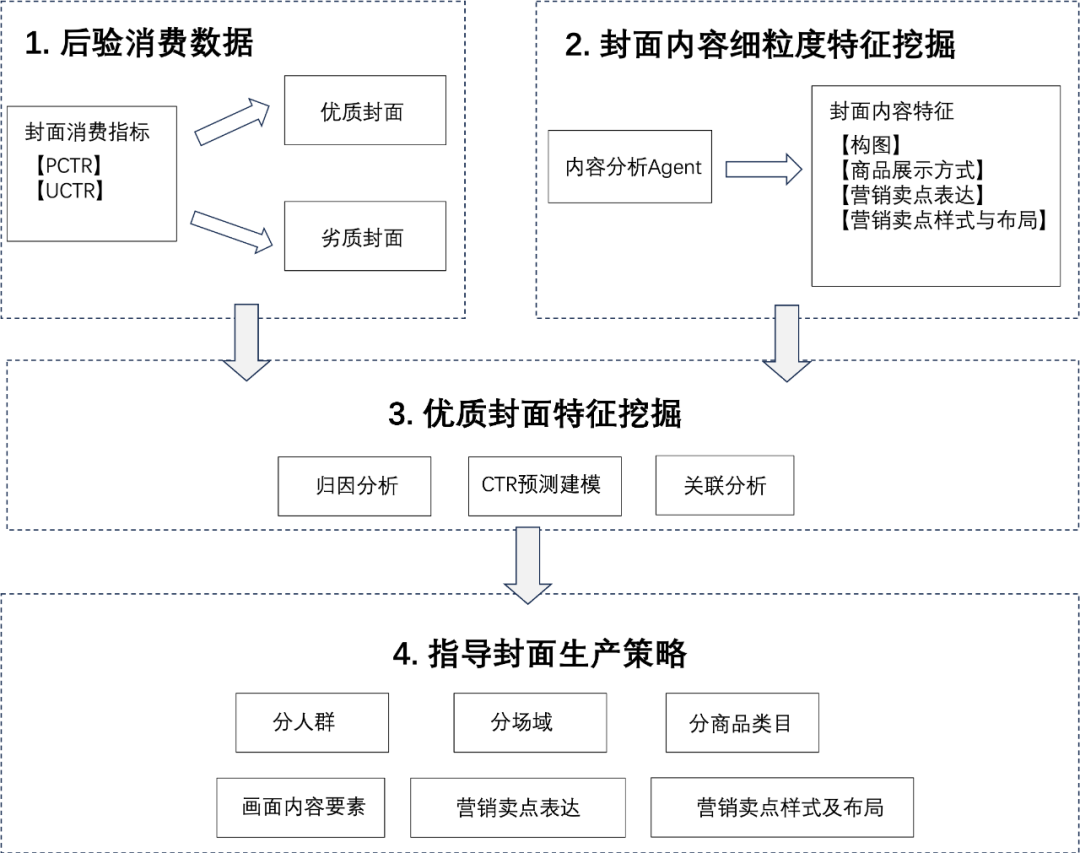
▐ 3.Action-执行模块
行动模块是整个系统的核心,负责具体执行封面生成的各项任务,包括:
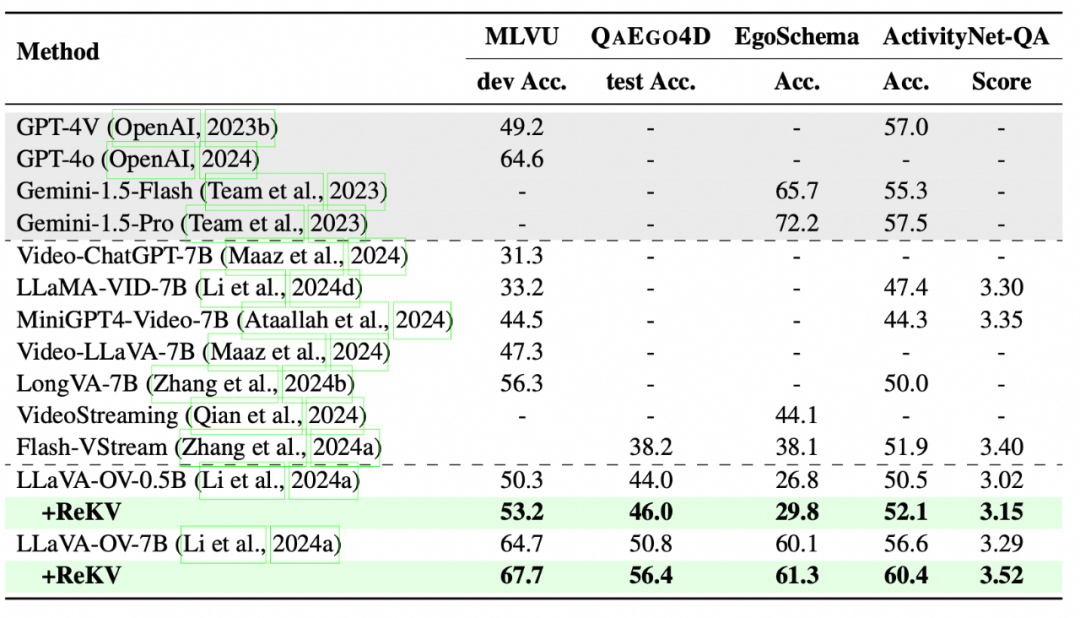
3.1.1视频流处理引擎:基于ReKV的流式+长视频处理架构
背景
由于资源限制,传统的视频理解模型在处理长视频时受限于输入帧数,往往影响封面的选帧效果。
方案设计
为此,我们构建了基于ReKV的流式长视频处理引擎,主要特点包括:
高效推理:采用滑动窗口注意力机制减少计算开销,通过视频KV-Cache管理系统存储处理后的缓存并按需加载到GPU,仅检索与问题相关的视频KV-Cache进行计算,从而支持对长视频进行高效的流式分析。相比传统模型,显著提高了推理效率,降低了计算开销。
全局选帧:流式分析支持使用更高的FPS处理视频,从而在全局范围内选取更优的帧。
即插即用:可与任意视频/多图的大语言模型无缝集成,实现高效的长视频问答。
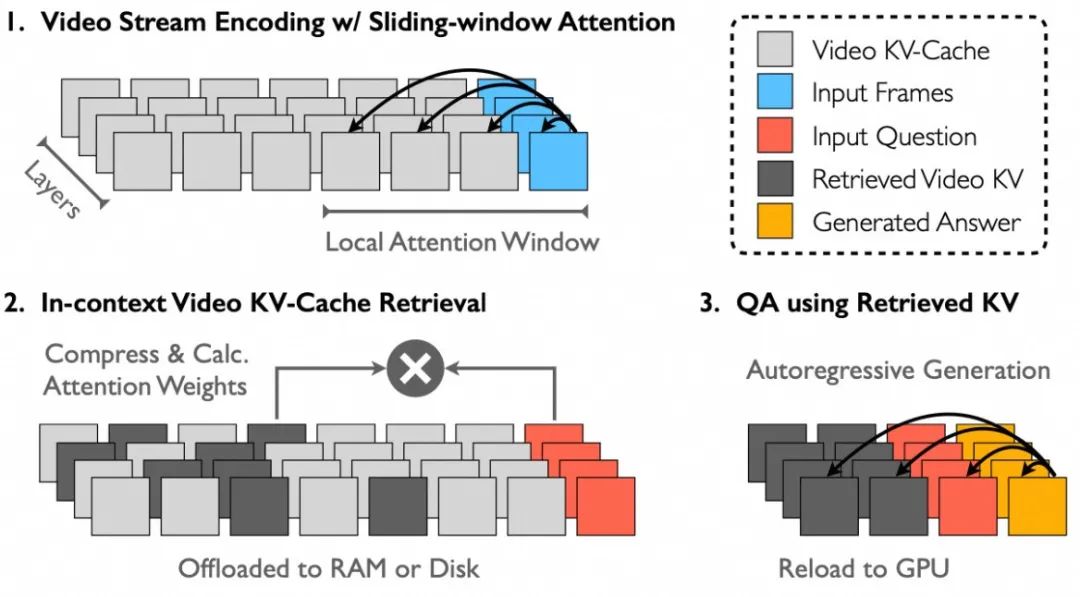
方案结果示意
实验结果显示,基于ReKV的流式视频处理架构相比现有的视频问答模型,显著提高了计算效率,降低了计算开销,且验证能够在封面选帧任务中取得更优的效果。相关研究成果已投递ICLR(2025)。
| Video QA的Accuracy、latency和GPU Memory对比 | Benchmark测评结果 |
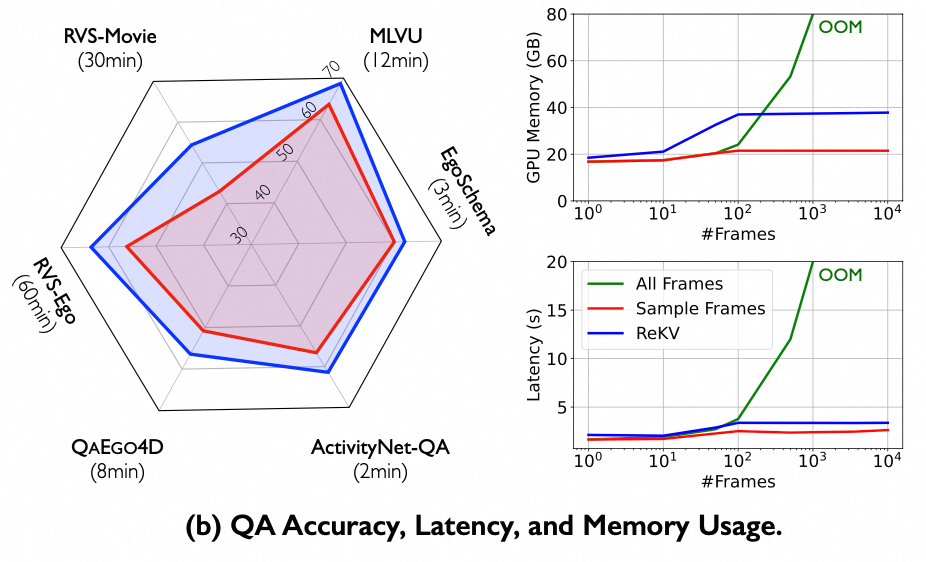
| 
|
3.1.2 双阶段智能选帧 pipeline
背景
在一段视频中选择某个符合特定要求的帧,属于经典的视频VQA问题,通常可利用视频/多图理解模型实现。但是,由于资源限制,实际场景中能部署起来的视频和多图理解模型往往是7B/8B尺寸,其Instruction Following能力较差。而业务对选帧的需求往往较为复杂,因此仅利用预训练的视频和多图模型,通过Prompt Enginnering进行选帧,经验证难以达到质量要求。
方案设计
模型微调的方案对数据有标注量的要求,且不同业务对封面的要求有差异,可能需要面向不同的业务训练并部署多个模型。相比之下,我们选择采用Training-Free的方案,面向不同业务场景时无需多次训练和部署模型,实际应用起来更为灵活。具体实现层面,我们通过增加图片质量评估模块,检查图片的细节信息,弥补视频/多图模型Instruction Following能力差的缺陷。
综上所述,我们设计了双阶段智能选帧方案。通过两阶段的处理,既能保证选帧的全局性,又能够兼顾到图片细节的高质量。
第一阶段:视频模型初筛
利用预训练的视频/多图理解模型,对视频进行初步的优质帧选取。我们调研了目前开源的SOTA的视频/多图理解模型(包括Mantis、LLaVa-NeXT-Video等),经过在业务场景下测试,最终选用Mantis-8B-Idefics2作为视频选帧的基座模型。
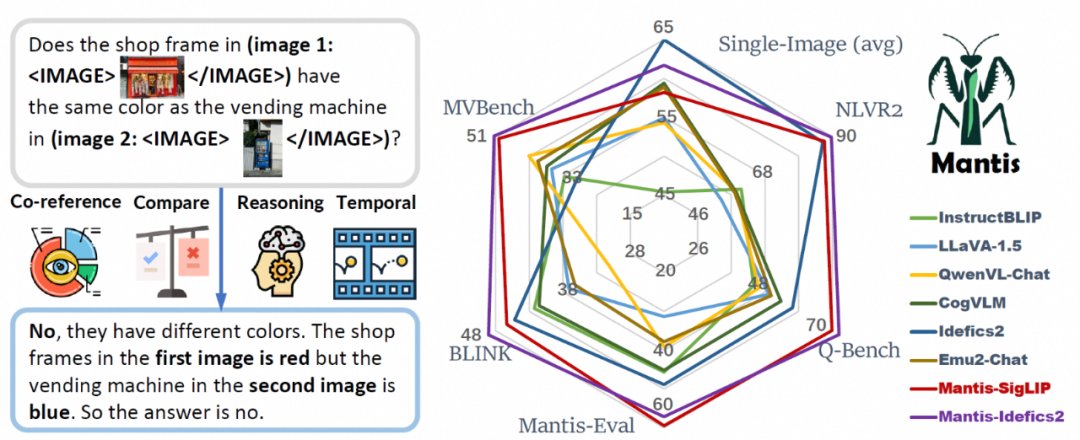
由于视频模型的 Instruction Following 能力有限,仅利用其进行全局选较优,针对业务需求中的“Better to Have”指标,进行全局性的帧排序和筛选。
第二阶段:图片质量评估
图片质量评估模块中,由于模型不需要同时看到多帧,因此我们可引入尺寸更大的单图多模态模型,对上一阶段初筛得到的帧进行质量评估,检查图片是否符合Memory模块中定义的图片质量标准。
多模态模型对于一些常规问题可以较好解决,但封面图片评估标准中,有一些涉及到对图片细节的理解,如人物表情细节的判定、图片细节模糊的判定。目前实际业务中可部署的单图多模态理解模型,对于这些图片细节信息的理解能力有限,往往难以识别准确。经过测试,通过Prompt Enginering仍难以达到较好的效果,在此背景下,以往通常采用模型微调/小模型训练的方案解决。
我们选用Traing-Free的方案,通过 Chain-of-Thought(COT)提升模型的推理性能,通过多模型集成(Ensemble)进一步保证质量的通过率,在实际业务中验证能够满足业务对图片细节的质量要求,满足业务“Have to Have”的硬性要求。
我列举了一个典型的案例:在这个视频中,主播全程都在讲解商品,没有任何纯展示商品的定点画面。在淘宝平台内,有许多短视频都是主播密集讲解商品,对于这类视频,要选出一张主播表情正常的封面非常困难。尤其是在我提到的这个案例中,经过测试,直接采用当前业务中资源可部署、效果较佳的InternVL-40B-AWQ 进行推理,判断下表中间图片中的人物眼睛是睁开的。通过 COT(Chain-of-Thought)和 模型Ensemble 方法后,可以有效地过滤掉这类情况。
背景
为了增强封面的吸引力,我们在封面上添加营销花字,目的是在封面中突出商品的核心卖点,让用户一目了然获取信息。
方案设计
我们构建了一套数据生成pipeline,并使用构造得到的数据SFT Qwen2.5-7B,得到封面卖点生成模型。该模型能够基于视频内容和商品信息,简明扼要概括商品核心卖点,让用户一目了然获取信息。
1. 数据构造阶段:
- 我们综合应用多种Prompt Enginering技巧,设计了Prompt模板,模板中包含风格控制、限制条件、Few-Shot示例、商品信息、视频的ASR+OCR信息。
- 通过大语言模型生成卖点标题,结合人工的打分反馈进行多轮Prompt模板的优化。
- 如此,我们获取了一批高质量的内容-标题数据pair对。
2. 模型训练阶段:我们选用Qwen2.5-7B作为基础模型,通过SFT微调,结合AWQ量化,得到面向内容的封面标题生成模型。

3.3.1 图片贴纸和字幕擦除
背景
视频和直播中大多存在一些凌乱的贴纸和字幕,如牛皮癣、ASR字幕等,会影响整体的美观度。如果直接拿原始截帧得到的图片添加花字作为封面,可能会导致整体画面要素过多,影响美观度,也会导致营销卖点花字不够突出。
因此,我们需要擦除截帧得到的封面图中的杂乱花字,提供一张整体较为干净的封面图片,用于花字布局。
方案设计
图片贴纸和字幕擦除属于图像处理的Image Inpainting领域,在我们的业务场景中,我们需要擦除除了商品文字外的其他文字,具体可拆解为如下三种情况:
1. 如果文本框与商品有重叠,并部分超出商品范围,通常是ASR字幕/品牌等文字,需要以段落文本的形式全部擦除;
2. 如果文本框全部在商品范围内,则保留,这是为了防止擦除商品上的文本信息;
我们将封面的以上诉求进行梳理,对接商家智能团队,调用其字幕和牛皮癣擦除能力,在实际业务中取得了较好的效果,也通过在实际场景的应用,助力了兄弟团队算法的优化与进步。
方案结果示意
| 擦除前 | 擦除后 |

| 
|
3.3.2 花字自动布局
背景
在生成营销卖点后,需要基于图片构图,确定花字的最佳摆放位置与排版方式(横排/竖排等),确保花字不遮挡重要信息(人脸、商品等)。同时,还需要综合图片商品主体及背景的颜色,选择匹配的花字样式和颜色,以保证花字在整体中布局的和谐与美观。
方案设计
方案结果示意
▐ 4.Reflection-反思模块
背景
上述多个执行模块之间既相互耦合,又保持相对独立性。然而,不同模块的执行结果可能会出现冲突。例如,商品在画面中占据了绝大多数空间,实际可放置花字的区域较小,导致过长的花字难以实现合理、美观的布局;又如,封面花字中提到的商品颜色可能与截帧中展示的商品颜色不一致。
方案设计
为确保各模块执行的协调性,我们在封面生成Agent中引入了反思模块。该反思模块会读取记忆模块(Memory)的质量评估要求,基于多模态大模型,逐项评估和审查各项是否达标。通过不断的反思与优化,提升封面、花字和布局模块之间的协同度,从而提高封面的整体质量。
举一个典型的案例:在某个视频中,商品信息包含黑色款式。初次生成封面时,营销花字和画面中的商品颜色不一致。经过反思模块的优化后,我们在标题中去除了颜色信息,最终得到了新版本的封面。
总结
我们通过构建基于多模态大模型的封面生成 AI Agent,成功实现了在淘宝视频和直播场景下的高质量封面自动化生产。该系统采用模块化的 Agent 架构,融合了规划、记忆、执行和反思等核心模块,充分利用大语言模型的强大能力,灵活应对业务方对封面的复杂需求。
在技术实现方面,我们引入了 ReKV 流式长视频处理技术,解决了长视频处理中的效率瓶颈,支持全局范围内的优质帧选取。通过双阶段智能选帧策略,既保证了选帧的全局性,又提升了封面图片的细节质量。我们还利用大语言模型的能力,自动生成符合商品特点的营销花字,并通过智能布局算法,实现了花字的最佳摆放和美观呈现。反思模块的加入,使系统能够不断自我优化,提升各模块的协同效果。
实际业务落地证明,该方案显著提升了封面的点击率,增强了用户的内容消费意愿。同时,模块化的设计使系统具备了高可扩展性和迁移性,能够灵活满足多样化的业务需求,为淘宝内容生态的发展提供了有力支持。

































 粤ICP备17114055号
粤ICP备17114055号