推荐语
DeepSeek模型引领AI技术新浪潮,打破传统大模型局限,开启强化学习新范式。
核心内容:
1. DeepSeek模型的快速崛起及其对AI行业的颠覆作用
2. DeepSeek基于强化学习实现Time Scaling Law的新范式
3. DeepSeek出圈背后的核心技术解码及行业影响分析
杨芳贤
53A创始人/腾讯云(TVP)最具价值专家
现在DeepSeek是风光无两的当红炸子鸡,不懂DeepSeek都不意思跟人聊天了,为了紧跟时代进度的步伐,做一个懂AI的IT从业人员,积极学习了一下“先进”生产力,做好自我“反思”,回馈圈内外好友。
0x01:AI 科技起义,DeepSeek魔童闹海
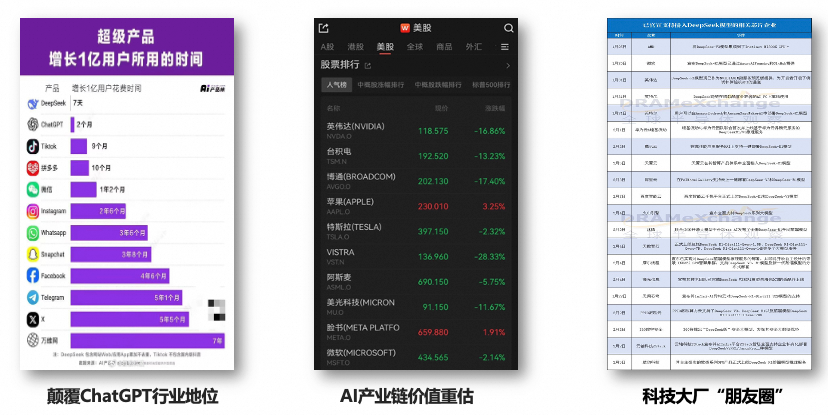
数据表现
- 如同坐上了火箭般的速度全球风靡,在全球最快达到亿级用户积累,实现七日登顶,超过ChatGPT2个月的成绩;
- Deepseek 爆火之后,英伟达股票出现大幅震荡,引发了ai 价值链的重塑;
- 奉行着“打不过就加入”的原则,国内外的GPU厂商、云服务提供商等各类科技大厂纷纷合作;
- 某些公司或机构觉得自己不得不放弃基础大模型了,现在觉得自己又行了,因为希望是个好东西;
DeepSeek这种挑战AI霸权,掀桌子式的科技起义,颇有“抗美援朝”的慷慨,也有哪吒魔童闹海的气势,难得的在科技领域,尤其AI对抗的领域中给国人提气,毕竟老被人掐着脖子,憋气。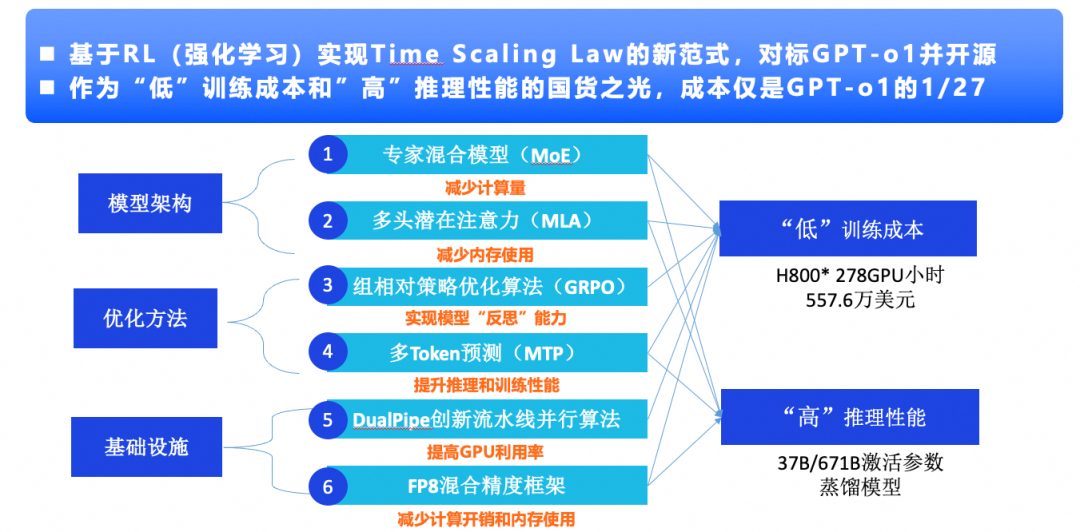
在广泛调研和定向请教之后,我总结了DeepSeek火爆出圈的两个原由(非专业视角,仅做参考)
创新1:基于RL(强化学习)实现Time Scaling Law的新范式,对标GPT-o1并开源在此之前,炼丹一个大模型不得不“大力出奇迹”,必须堆算力猛火烹制,必须垒数据老道秘法,但是DeepSeek离经叛道的第一个表现是,他不单纯的迷恋大力,而是开拓了一条新的的路径:通过RL(强化学习),让模型内卷,不停照抄有解题步骤的那种作业(CoT数据),学会检查作业(反思能力),学会延迟交卷( Time Scaling),直到答案还挺高质量的时候再交卷,进而量变引发质变,然后模型就突然顿悟,进化出了“智力”。另外,之前的模式都是按部就班的先SFT,再RHLF,他就绕开了SFT这个传统节目。新开辟的这条路径就是“ Test Time Scaling ”,也有叫“ RL Scaling ”的,是“用时间换效果”的一种路径。这条路径OpenAI一定已经有所发现,且应用在了O1、O3上,但它是个商业化公司,就不告诉你。DeepSeek牛就牛在他验证了这条路的可行性,而且效果上对标O1。创新2:作为“低”训练成本和”高”推理性能的国货之光,成本仅是GPT-o1的1/27第二个离经叛道的表现是因为性价比,因为加量不加价,因为在同样的表现下用了少了很多倍的资源。这个时候我想起了我的授业恩师以及他给我较印象深刻的一个词“集成式创新”。集成式是相对突破式创新而言的,不做技术的从0到1,而是把其他场景的方式和方法,在新的场景进行验证,然后组合式运用,集成式验证,释放出新场景价值,其实DeepSeek也是这个模式,把模型架构、优化方法和基础设施方面相对优势的技术集成式创新。Moe架构改变了FFN全连接的模式,降低了沟通的复杂度,减少了内耗,另外这种架构也可以让模型规模变大,规模代表的是知识规模,懂得更多还沟通和计算的效率更好,MHA是Transform架构的核心,也是吃显存的大户,所以有多改进手段比如GQA,MLA相比之前的MHA、GQA等,他占用的KV Cache大幅度降低。这都是是典型的马儿跑得快,马儿还吃的少。你说这样的牛马,谁不喜欢?主要是GRPO对PPO的进步,中心思想就是简化了结构,不用专用的外部评价模型,把自然进化交给喂给大模型的饲料和强化学习自己评价体系,饲料都是有营养的,配料均衡的,吃得不好他还要自己去思考为啥不好。多Token的预测更简单了,就是三步并作两步走,在别人刚迈出第一步的时候,他已出门了,所以更早的抵达终点。DualPipe流水线的核心思想是不让卡闲着,用更全面和高效的调度把训练过程中前向传播和梯度回传的计算以及内部通讯任务做更加高效的调度,让卡上的每个计算单元,物尽其用。FP8混合精度框架针对加法、乘法等不同场景,结合计算需要,在效果和存储空间中去取得一个比较微妙的平衡。不过这个格式也是在英伟达H系列上的表现更好,国产卡的支持效果上普遍还没跟上。通过这些集成创新的手段,让模型在训练和推理成本上大幅度降低,同时推理的效果又比较良好,这样在成本原先是让大家退而却步的情况得到了极大的改善,不论是捉襟见肘的科技小厂,还是缺卡少钱的甲方,都有了AI盛宴的参与感,也都有奋起直追的勇气,这也可以称之为是通常意义上的AI平权,或者普惠AI。当然,还有一个“离经叛道”的点,非技术原因,那就就是匹夫无罪怀璧其罪,因为DeepSeek是中国人的知识成果,还是一群没有喝过洋墨水的人做出来的,所以给DeepSeek增加了更多的民族色彩。0x03:DeepSeek-R1模型训练及蒸馏技术链路
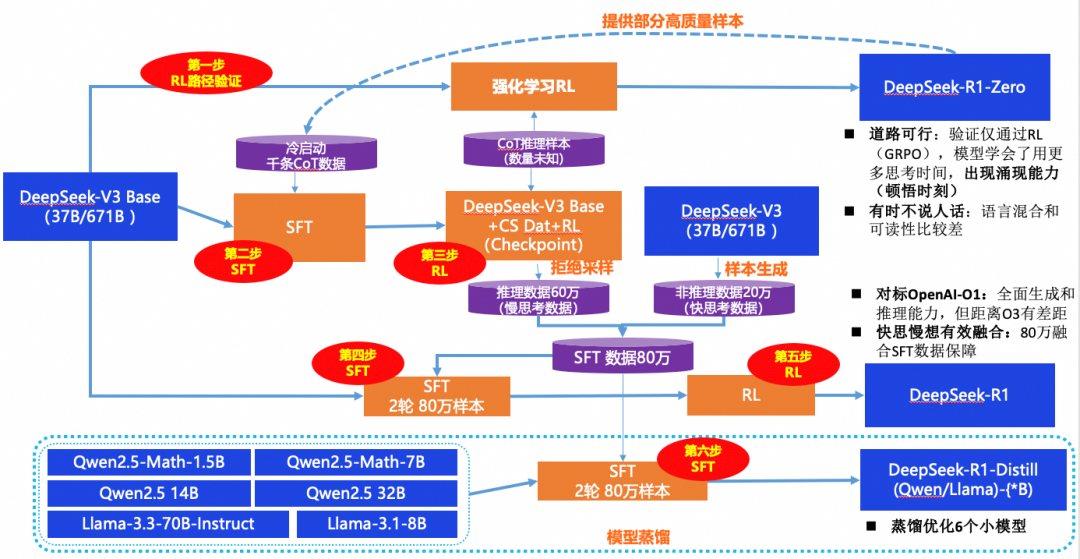
过程:模型训练及蒸馏
这块把训练和蒸馏过程讲解一下:得到一个R1和一堆蒸馏模型,只需要四阶六步。这个也是DeepSeek最重要的价值,他验证了强化学习的路径可行性,在没有经过任何SFT的过程直接进行训练(第1步),并在这个过程中产生了R1-zero。 R1-zero意想不到具备了大模型的泛化和涌现能力,但是关键的问题是有些时候不说人话,一会说英语一会说法语,一会像哲学家,一会像大夫,所以输出上很不稳定。为了解决R1-zero的问题,在训练数据和方式要及时进行调整,增加了一个冷启动的过程,也就是一次SFT(第2步),训练规模很小,才千级,相比整体参数量那就是沧海一粟,但有了铺地的数据,可能会让模型有点好的基础表现。在训练过程中,通过拒绝采样(第3步),进一步又收集了60万的数据,因为是推理模型的产出,所以带着思维过程,也都是高质量的,但模型的回答也不见的都需要思深度思考,针对快问快答的场景再搂一笔数据也未尝不可,这样就凑齐了80万之巨的SFT数据。紧接着,再经过两轮的SFT(第4步)和RL(第5步)就生成了最终的R1。这个时候的模型有了比较惊艳的表现,思辨能力升维,可以跟O1叫板了,这个最终的训练过程中有80万的数据加持,而且做了数据类型的,充分支持快问快答以及深思熟虑两种模式。这个完全属于搂草打兔子,80万的数据已经就位了,闲着也是闲着。把Qwen及Llama的模型来蒸馏一下,简单经过2轮的SFT(第6步)就可以用了,另外也可以缓解自己模型太大,太吃部署资源的问题。纠正一点:虽然我说得简单四阶六步,但其实训练还是很难的,想一想要让一个600多B的模型收敛,总会有很多意想不到的问题,要不也不会2次的RL,2次的SFT,另外可能还有很多步骤论文没说。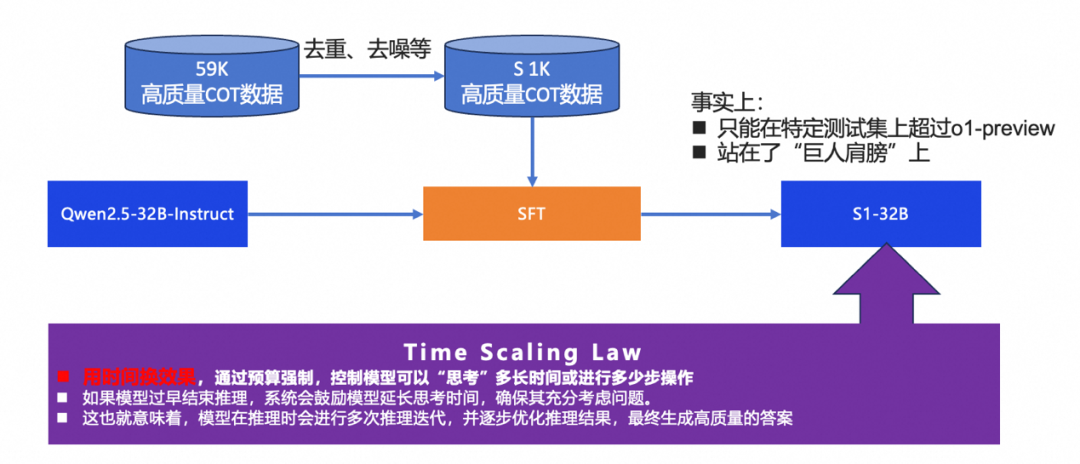
DeepSeek爆火后,讨论和研究的很多,大多是蹭热点,当然也包括我,但一则新闻尤其炸裂,李飞飞团队用1K数据和不到50美元的成本复现R1。很多业内人士对其进行分析,其实结论也有点言过其实,只是在某个特定数据集上超过了o1-preview(本来也不是很top级的模型),其实是搞研究常用的套路,在多个维度中的1个维度上超过了就可以生产一篇文章。
但李飞飞团队的研究也有很大的一个可取之处,那就是充分验证了“用时间换效果”的模型,让模型强制思考,反复得内部输出,直到结果满意,就跟让学生一直检查考卷,不考90分不让交卷。另外还有一点, 业务人士也在复现S1-32B的模型,发现用其他的原始模型进行蒸馏效果并不好,所以得出了一个结论S1-32B的优秀,主要还是因为他有一个更好的被蒸馏模型,也就是说Qwen是其“巨人肩膀”。我们不知道DeepSeek发布的时机,以及海内外的传播是否有无形的力量在推波助澜,但是国人把这么先进的模型开源还是很有情怀的一件事情,他不仅冲击了人工智能的行业,也颠覆了人们对大模型在算力、算法以及数据方面的认知,也从很大层面上改变了市场的格局,所以说开源是很高明的手段。但是,我们也要看到很多不透明的细节,尤其是数据以及数据背后的逻辑,用于RL的 CoT数据是个黑盒,80万的SFT数据也是DeepSeek蒸馏各种模型的关键生产原料,在技术透明度很高的现在,数据成为制胜的法宝之一。当然,技术的组合是know-how,人才及其密度也是关键要素,一个大模型诞生的要素也是不可偏废的。0x05:安全有时候是不需要的,需要的时候是不安全的
假期期间,DeepSeek遭受DDos攻击和网络渗透闹得沸沸扬扬(安全方面恰好我也略懂),很多国人以及红客们群情激愤,争先恐后要去守卫DeepSeek的安全,但DeepSeek把ClickHouse暴露在公网上也是事实,其实这是业务发展过程中常见的问题,业务优先忽视安全,导致安全滞后于业务,又拖累了业务,毕竟好长一个时间段不能注册和使用,甚至回答的过程中直接中断,这次DeepSeek只是犯了大多数公司都会犯的错误而已。其实在业务不发达的时候,往往没有被坏人盯上,安全不是那么急迫,所以优先级会被降低,但这种意识会导致一旦出现安全问题,爆发的都是很难挽回的后果。另外,大模型的安全相比传统的安全存在很大的差别,除了系统级的安全以外,还要更加重视输出的内容安全。还有,大模型在交互的过程中,存在被攻击者扭曲“认知逻辑”的风险,在某些大型活动中是被广泛验证过的。所以大模型一旦胡言乱语,甚至说出不和谐的言论,对于涉面广泛的C端场景就是灭顶之灾。

































 粤ICP备17114055号
粤ICP备17114055号