检索增强生成(Retrieval Augmented Generation, RAG)是大语言模型应用构建的常用技术。RAG将专有知识检索与通用文本生成相结合,根据用户输入的查询,从专门搭建的外部知识库中检索出相关信息,并将其作为附加的上下文输入到大语言模型中,从而生成更加符合特定语义场景,信息丰富、语义连贯的响应输出。这项技术显著提高了预训练大语言模型在非训练集领域对话、问答、知识抽取等任务中的表现,有效减少了预训练模型的幻觉缺陷,RAG已成为今天企业大语言模型应用开发的关键技术之一。
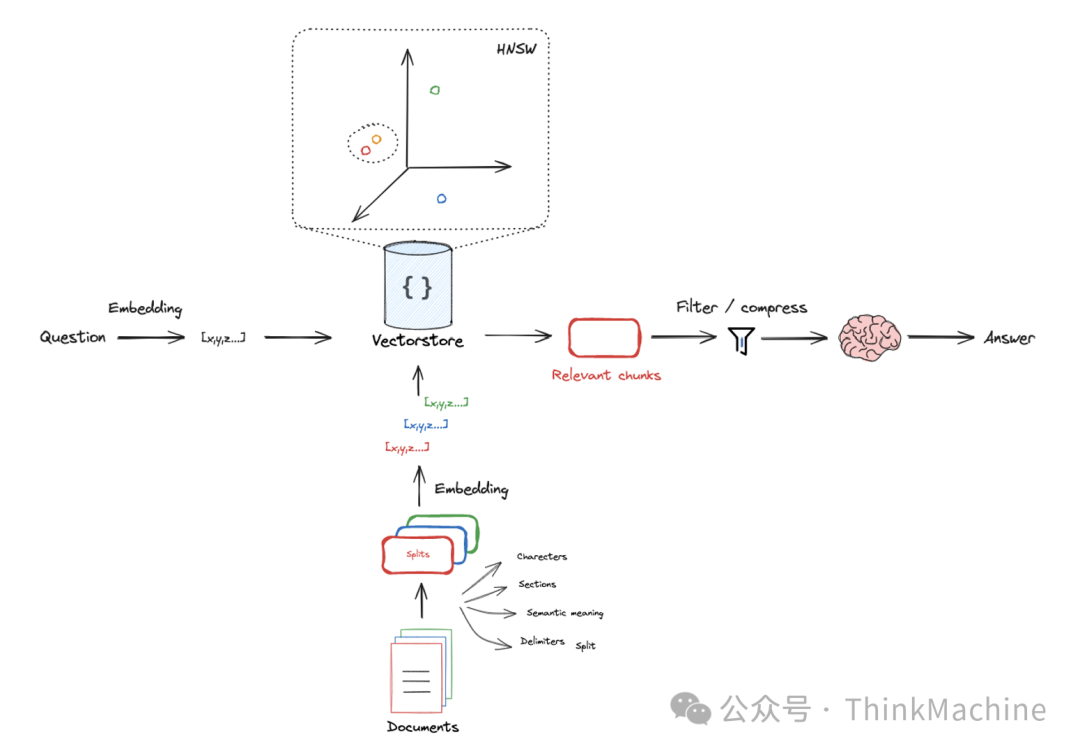
开发RAG应用的一个关键步骤是对需要检索的文档,进行分块(Chunking)预处理,将文件划分为适当大小的文本片段,以便于后续的大语言模型处理。高质量的文档分块可以帮助大语言模型更好地理解和利用检索到的知识,提高生成结果的相关性和连贯性。如果分块不当,很可能会导致上下文信息不完整、语义断裂等问题,进而严重影响RAG应用的性能体验。
 1. 传统的文本分块方法在自然语言处理领域,文本分块是一项基础而重要的任务。传统的文本分块方法主要基于文本的格式结构特征,如标点符号、换行符等,将文本划分为句子、段落等单元。常见的方法包括:(1)基于标点符号的分块:根据句号、问号、感叹号等标点符号将文本分割为句子;(2)基于换行符的分块:根据"\n"、"\n\n"等换行符将文本分割为段落或列表项;(3)固定长度的滑动窗口:使用固定大小的字符数或单词数窗口在文本上滑动,生成重叠或不重叠的文本块。这些方法实现简单,但往往忽略了文本的语义结构,容易将完整的语义单元切分开,导致信息丢失或语义不连贯。2. 基于文档结构的语义分块HTML/PDF/Doc等文件中,包含丰富的格式和布局信息等结构化特征,反映了文档的语义结构。利用这些结构化信息,可以将文档解析为一系列的文档元素(Document Elements),如标题(Title)、正文(NarrativeText)、表格(Table)等。每个元素对应文档中一个完整的语义单元。在分块时,预处理管道程序需要优先保留这些语义单元的完整性,避免被切分开。在实际分块过程中,RAG Chunking预处理管道引入了两个关键的处理机制:
1. 传统的文本分块方法在自然语言处理领域,文本分块是一项基础而重要的任务。传统的文本分块方法主要基于文本的格式结构特征,如标点符号、换行符等,将文本划分为句子、段落等单元。常见的方法包括:(1)基于标点符号的分块:根据句号、问号、感叹号等标点符号将文本分割为句子;(2)基于换行符的分块:根据"\n"、"\n\n"等换行符将文本分割为段落或列表项;(3)固定长度的滑动窗口:使用固定大小的字符数或单词数窗口在文本上滑动,生成重叠或不重叠的文本块。这些方法实现简单,但往往忽略了文本的语义结构,容易将完整的语义单元切分开,导致信息丢失或语义不连贯。2. 基于文档结构的语义分块HTML/PDF/Doc等文件中,包含丰富的格式和布局信息等结构化特征,反映了文档的语义结构。利用这些结构化信息,可以将文档解析为一系列的文档元素(Document Elements),如标题(Title)、正文(NarrativeText)、表格(Table)等。每个元素对应文档中一个完整的语义单元。在分块时,预处理管道程序需要优先保留这些语义单元的完整性,避免被切分开。在实际分块过程中,RAG Chunking预处理管道引入了两个关键的处理机制:- (1)元素合并:为了得到足够大小的文本块,会将多个连续的文档元素合并为一个Chunk。合并过程在满足预设最大Chunk尺寸(如字符数上限)限制的前提下,尽可能填充每个Chunk。
- (2)超长元素分割:当单个文档元素的长度超过最大Chunk尺寸时,需要进行二次分割。分割时采用滑动窗口的方式,生成多个Chunk。为了缓解在任意位置切断元素可能带来的语义断裂问题,应该在Chunk之间引入一定的重叠(Overlap),就是在下一个Chunk的开头包含前一个Chunk的结尾部分。
RAG应用的分块过程最终会输出以下三种类型的Chunk:(1)CompositeElement:由一个或多个文档元素合并而成的复合元素,是最常见的Chunk类型;(2)Table:由单个表格元素构成的Chunk;(3)TableChunk:对超长表格元素进行分割后得到的子表Chunk。每个Chunk都继承了相应文档元素的属性等元数据,同时还保存了构成该Chunk的原始元素,以便后续可以基于这些元数据,对原始信息进行查询、还原和追溯。
3. 分块策略与可调参数
RAG Chunking预处理管道需要设计一些可调参数,用于控制自动化分块预处理管道的行为和输出结果。比如:- max_characters参数指定了单个Chunk的硬性字符数上限。在分块过程中,任何Chunk的字符数都不会超过该值。当单个元素的字符数超过该上限时,会对其进行二次分割,生成多个子Chunk。该参数的默认值为500。
- new_after_n_chars 软性字符数上限new_after_n_chars参数指定了单个Chunk的软性字符数上限。当当前Chunk的字符数已经超过该值时,即使下一个元素的字符数在硬性上限以内,也会开启一个新的Chunk。该参数可以与max_characters配合使用,设置一个"首选"的Chunk大小。
- overlap参数指定了在对超长元素进行文本分割时,相邻子Chunk之间的重叠字符数。引入重叠可以缓解在任意位置切断元素可能带来的语义断裂问题。该参数的默认值为0,即不引入重叠。
- overlap_all参数是一个布尔值,指定是否对所有Chunk都引入重叠,而不仅仅是对超长元素分割产生的子Chunk。由于普通的Chunk都由完整的元素构成,具有清晰的语义边界,对它们引入重叠可能会"污染"Chunk的语义完整性。用户需要根据具体应用场景权衡是否启用该选项。该参数的默认值为False。
RAG Chunking预处理管道一般有两种分块策略:Basic和By-Title。- Basic策略按照元素在文档中出现的顺序,将它们依次合并到Chunk中,尽可能填充每个Chunk,同时遵守max_characters和new_after_n_chars参数的限制。对于超过max_characters的单个元素,Basic策略会将其隔离(不与其他元素合并),并对其进行文本分割,生成多个子Chunk。表格元素(Table)始终被隔离,不与其他元素合并。超长的表格元素会被分割为多个TableChunk。如果指定了overlap参数,那么在对超长元素分割时,以及在overlap_all为True时的所有Chunk之间,都会引入相应的重叠。
- By-Title策略在Basic策略的基础上,额外考虑了章节和页面的边界。
- By-Title策略将Title元素视为章节的开始标志。在遇到Title元素时,会结束当前Chunk,开启一个新的Chunk,即使Title元素可以放入当前Chunk。这样可以保证一个Chunk不会跨越章节边界。
- By-Title策略可以通过multipage_sections参数选择是否保留页面边界。当multipage_sections为True(默认值)时,页面边界不会触发新Chunk的开启。当其为False时,位于不同页面的元素会被分配到不同的Chunk中。
- 在某些文档中,partitioning过程可能会将列表项或其他短小的段落误识别为Title元素,导致生成过多过小的Chunk。By-Title策略通过combine_text_under_n_chars参数提供了缓解这一问题的机制。该参数指定了一个字符数阈值,当连续的小节的字符数总和不超过该阈值时,它们会被合并到一个Chunk中,直到充满该Chunk为止。该参数的默认值与max_characters相同,即默认允许对小节进行合并。将其设置为0会禁用小节合并功能。
4. 工程实践与分析
为了评估不同分块策略和参数对RAG任务性能的影响,我们在多个数据集上进行了实验和测试。
首先,我们对比了Basic和By-Title两种分块策略生成的Chunk在以下方面的特点:(1)语义完整性:By-Title策略生成的Chunk在章节和页面边界上更加完整,而Basic策略可能将跨越边界的内容合并到一个Chunk中,导致语义断裂。(2)信息重叠:在使用overlap参数时,By-Title策略在章节和页面边界处产生的重叠信息更加自然,不会引入过多冗余;而Basic策略在任意位置引入的重叠可能会导致部分Chunk包含大量重复信息。(3)Chunk长度分布:By-Title策略生成的Chunk长度分布更加不均衡,在章节和页面边界处容易产生较短的Chunk;而Basic策略生成的Chunk长度较为均匀,更接近指定的目标长度。(4)元信息保留:由于By-Title策略更多地保留了原始元素的边界,其生成的Chunk中元信息的丢失相对更少,更易于从metadata.orig_elements中恢复。我们评估了不同分块参数对RAG模型在下游任务中性能的影响。主要考察了以下参数:(1)max_characters和new_after_n_chars:较大的值可以产生更长的Chunk,减少Chunk的数量,提高处理效率;但过长的Chunk可能超出语言模型的最大输入长度,导致部分信息被截断。较小的值可以产生更细粒度的Chunk,更好地保留原始信息,但会增加处理开销。(2)overlap和overlap_all:引入适度的重叠可以缓解Chunk边界处的语义断裂问题,提高RAG模型的表现;但过多的重叠会引入冗余信息,降低处理效率。overlap_all参数在某些任务上可以提升性能,但在其他任务上可能有相反的结果。(3)multipage_sections和combine_text_under_n_chars(By-Title策略):保留页面边界有助于减少Chunk内的信息不一致问题,但可能产生过多过短的Chunk。启用小节合并功能可以缓解这一问题,但可能导致部分边界信息丢失。工程实践结果表明,不同任务对分块策略和参数的敏感程度是不同的。在实际应用中,需要根据任务的特点和需求,对分块策略和参数进行适当的调整和权衡,以达到最佳的性能表现。5. 总结本文研究了文档分块策略在检索增强生成(RAG)任务中的重要作用。合理的分块策略可以帮助RAG模型更好地理解和利用检索到的知识,提高生成结果的相关性、连贯性和信息完整性。不同的分块策略和参数设置会导致生成Chunk的特点差异,进而影响RAG模型在下游任务中的性能表现。从我们的工程实践中可以发现,并不存在一种全局最优的分块策略和参数组合。在实际应用中,需要根据具体任务的特点和需求,权衡不同分块策略和参数带来的效果差异,选择最适合的配置。以下是我们总结的一些常见场景下的经验法则:- (1)对语义完整性要求较高的任务(如问答、对话生成等),优先考虑使用By-Title策略,并适当降低max_characters和new_after_n_chars的值,以获得更细粒度、信息更完整的Chunk。
- (2)对处理效率要求较高的任务(如大规模文本分类、信息检索等),优先考虑使用Basic策略,并适当提高max_characters和new_after_n_chars的值,以获得更长、数量更少的Chunk。
- (3)对信息重复较为敏感的任务,谨慎使用overlap和overlap_all参数,避免引入过多冗余。
- (4)对Chunk内信息一致性要求较高的任务,优先考虑启用multipage_sections参数,以保留页面边界信息。
文档分块策略的设计和实现是RAG应用开发环节中数据工程团队的重要工作内容之一,数据工程师需要充分理解业务场景和技术需求,并在分块策略的选择和参数调优上进行反复试验,以获得性能与效果的最佳平衡。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
