近日,一股AI行业走入小冰河期的论调甚嚣尘上。一个根本原因在于,整个AI行业似乎无法从根本上解决幻觉风险为0%这样一个扎心的事实,尤其是对于数据密集型的项目,泛化误差更是大到令人难以置信。我查找到最近的两篇关于幻觉的调查,这是目前比较权威且相对前沿的综合报告,或许可以让你看到初秋的暖阳。、
以下是去年年底的LLM幻觉调查,来自哈工大和华为研究团队,截至目前已被引用301次,算是比较权威的LLM幻觉调查,值得仔细研读!

今年年初的幻觉缓解技术调查,被引用80次,引用了上面的论文。

幻觉(Hallucination)这一概念最初源自病理学和心理学领域,指的是对不存在于现实中的事物或事件的感知。在自然语言处理领域,幻觉通常被定义为生成的内容看似合理但实际上与提供的源内容不符或毫无意义的现象。
在大语言模型(LLM)时代,幻觉的定义需要进行调整以适应LLM的特点。本文将LLM的幻觉定义为:生成的内容与可验证的真实世界事实不一致,或者偏离用户指令或提供的上下文信息。以下内容有点严肃,可能会引起您对教材的久违感,请酌情参考为宜。根据最新研究,我们可以将LLM中的幻觉分为两大类:
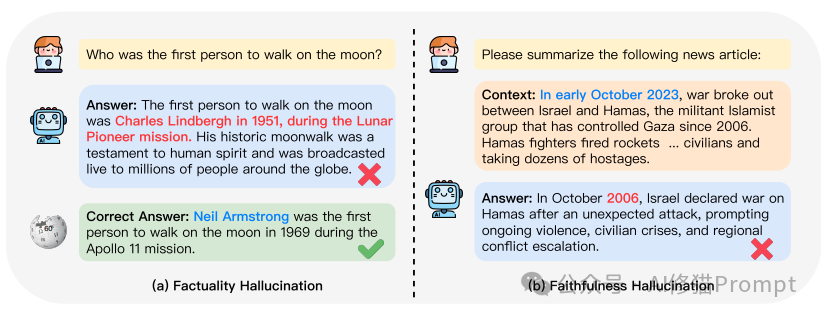 1. 事实性幻觉(Factuality Hallucination)
1. 事实性幻觉(Factuality Hallucination)
事实性幻觉指LLM生成的内容与真实世界的事实不符。根据生成的事实内容是否可以通过可靠来源验证,可以进一步分为两种:
- 事实不一致(Factual Inconsistency): LLM输出的内容包含可以在现实世界中验证的事实,但存在矛盾。这种幻觉最为常见,源于LLM在捕获、存储和表达事实知识过程中的各种问题。
- 事实捏造(Factual Fabrication): LLM输出的内容包含无法通过已知的现实世界知识验证的"事实"。这种情况下,模型完全虚构了一些看似合理但实际上不存在的信息。2. 忠实度幻觉(Faithfulness Hallucination)
忠实度幻觉强调LLM生成的内容与用户指令或提供的上下文信息不一致。可以进一步分为三种:
- 指令不一致(Instruction inconsistency): LLM的输出偏离了用户的指令。这里特指无意的偏离,而非出于安全考虑的有意偏离。
- 上下文不一致(Context inconsistency): LLM的输出与用户提供的上下文信息不符。
- 逻辑不一致(Logical inconsistency): LLM输出存在内部逻辑矛盾,常见于推理任务中。这可能表现为推理步骤之间的不一致,或者推理步骤与最终答案之间的不一致。
流畅性:尽管内容不准确,但幻觉通常表现为流畅、连贯的文本。
看似合理:幻觉生成的内容往往看似合理,难以被非专业人士识别。
上下文相关:幻觉的产生和表现可能与特定的上下文或任务有关。
不可预测性:幻觉的出现往往是不可预测的,增加了处理难度。
模型规模相关:一些研究表明,随着模型规模的增加,某些类型的幻觉可能会减少,而另一些可能会增加。
1. 训练数据的局限性:LLM是基于大量文本数据训练的,但这些数据inevitably会存在偏差、错误或过时的信息。
2. 模型结构的限制:尽管LLM非常强大,但它们本质上是基于统计模式的预测模型,无法真正"理解"信息。
3. 上下文理解不充分:LLM可能无法准确把握复杂的上下文关系,导致生成不恰当的内容。
4. 过度泛化:模型可能会过度依赖某些模式,导致在新情况下产生错误的推断。
5. 缺乏实时更新:LLM通常是基于静态数据训练的,无法及时获取最新信息。
LLM中的幻觉问题对其在实际应用中的可靠性和可信度产生了严重影响:
1. 信息污染:AI生成的虚假信息可能被广泛传播,加剧信息茧房和社会分裂。
2. 决策风险:在医疗、金融、法律等关键领域,AI幻觉可能导致错误的决策,造成严重后果。
3. 用户信任危机:频繁出现的幻觉会削弱用户对AI系统的信任,阻碍AI技术的广泛应用。
4. 伦理和法律挑战:AI生成的虚假信息可能涉及版权、隐私和责任归属等复杂问题。
5. 资源浪费:处理和纠正AI幻觉需要大量的人力和计算资源。
6. 推理能力受损:幻觉可能影响模型的事实推理能力,降低其在复杂任务中的表现。
7. 安全隐患:在自动驾驶、机器人控制等领域,幻觉可能导致严重的安全问题。
因此,解决LLM的幻觉问题对于提高AI系统的可靠性和实用性至关重要。这需要从数据质量、模型架构、训练策略和推理方法等多个角度进行综合考虑和改进。
根据最新研究,我们可以将幻觉缓解技术分为以下几大类:
1. 提示工程(Prompt Engineering)
2. 模型开发(Developing Models)
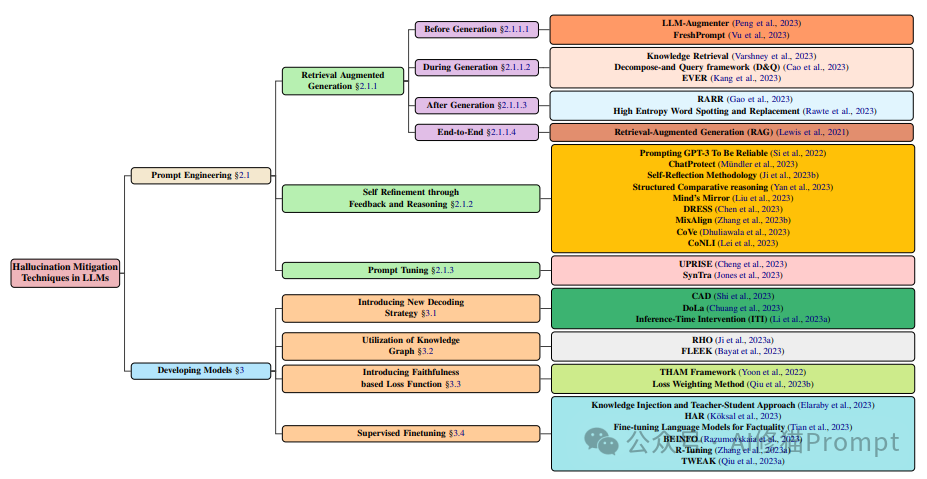
1. 提示工程(Prompt Engineering)
提示工程技术主要通过优化输入提示来引导LLM生成更准确的输出。这类方法的优势在于它们通常不需要对模型进行重新训练,实现起来相对简单。
1.1 检索增强生成(Retrieval Augmented Generation, RAG)
RAG技术通过引入外部知识来增强LLM的输出。根据检索时机的不同,可以进一步分为以下几类:
- 工作原理:使用一组即插即用(PnP)模块来增强黑盒LLM,使其生成基于外部知识的响应。
- 局限性:可能增加响应时间,因为需要多次查询LLM。
- 工作原理:利用搜索引擎将相关和最新的信息纳入提示中。
- 局限性:依赖Google搜索API,主要适用于简单的英语问题。
- Knowledge Retrieval: 知识检索
- 工作原理:在生成过程中检测和减少幻觉,使用logit输出值来识别可能的幻觉。
- 局限性:某些只通过API提供的模型可能无法获取logit输出值,这类问题较常见。
- Decompose-and-Query framework (D&Q): 分解查询框架
- 工作原理:引导模型利用外部知识,同时将推理限制在可靠信息范围内。
- EVER (Real-time Verification and Rectification): EVER (实时验证和纠正)
- 局限性:主要关注文本归因,可能忽视其他类型的幻觉。
- RARR (Retrofit Attribution using Research and Revision): RARR (使用研究和修订的改造归因)
- 工作原理:自动化归因过程,将内容与检索到的证据对齐。
- High Entropy Word Spotting and Replacement: 高熵词识别和替换
- 工作原理:识别高熵词并用低幻觉脆弱性指数的LLM替换它们。
- 优势:有效减少与生成傀儡或缩写歧义相关的幻觉。
- Retrieval-Augmented Generation (RAG):
- 工作原理:将预训练的序列到序列转换器与Wikipedia的密集向量索引集成。
- Prompting GPT-3 To Be Reliable:
- 工作原理:引入简单有效的提示来提高模型的可靠性。
- 优势:在所有可靠性指标上超越了小规模监督模型。
- 工作原理:提出了一个三步骤管道来推理自相矛盾。
- 优势:有效暴露和检测自相矛盾,适用于黑盒LLMs。
- Self-Reflection Methodology: 自反思方法
- 工作原理:引入交互式自反射方法,整合知识获取和答案生成。
- 优势:系统地提高生成答案的事实性、一致性和蕴含性。
- 局限性:仅限于英语医疗查询,可能不适用于其他语言或领域。
- Structured Comparative (SC) reasoning: 结构化比较推理
- 工作原理:通过生成结构化中间比较来预测文本偏好。
- 工作原理:将LLMs的自我评估能力蒸馏到小型语言模型中。
- 局限性:主要使用单一教师模型(GPT-3.5)和学生模型(T5-Base)。
- 工作原理:使用自然语言反馈来改善大型视觉语言模型的对齐。
- 优势:在helpfulness、honesty和harmlessness指标上有所改善。
- 工作原理:通过与用户和知识库交互来澄清用户问题与存储信息的关系。
- 局限性:额外的澄清步骤可能增加计算负载和时间消耗。
- Chain-of-Verification (CoVe): 验证链 (CoVe)
- 工作原理:模型生成验证问题并独立回答以进行事实核查。
- 局限性:仅处理直接陈述的事实不准确,计算成本增加。
- Chain of Natural Language Inference (CoNLI): 自然语言推理链 (CoNLI)
- 工作原理:使用自然语言推理链进行最先进的幻觉检测。
- UPRISE (Universal Prompt Retrieval for Improving zero-Shot Evaluation):
- 工作原理:训练一个轻量级和通用的检索器,自动为给定的零样本任务输入检索提示。
- 局限性:对直接formulated为语言建模的任务影响有限。
- 工作原理:使用合成任务来优化LLM的系统消息。
因为论文的发表时间在年初,之后又有很多Prompt调优的方法,您可以参考2. 模型开发(Developing Models)这类方法从模型架构和训练过程入手,试图从根本上减少幻觉的产生。
- Context-Aware Decoding (CAD): 上下文感知解码 (CAD)
- 工作原理:使用对比输出分布来放大有无上下文时模型输出概率的差异。
- Decoding by Contrasting Layers (DoLa): 对比层解码 (DoLa)
- 工作原理:通过对比后期和早期层的logit差异来获得下一个token分布。
- 优势:提高了LLaMA系列模型的truthfulness。
- 局限性:未探索在其他维度(如指令遵循)上的表现。
- Inference-Time Intervention (ITI): 推理时干预 (ITI)
- 工作原理:在推理过程中移动模型激活,以提高"真实性"。
- 优势:显著提高了LLaMA模型在TruthfulQA基准上的性能。
- 工作原理:利用知识图谱中链接实体和关系谓词的表示来生成更忠实的响应。
- 优势:有效编码和注入来自上下文相关子图的知识信息。
- 局限性:模型无法感知因果性、层次结构等抽象关系。
- 工作原理:使用从外部知识检索的证据进行事实错误检测和纠正。
- 局限性:依赖LLMs生成的初始响应集,实验基于小规模数据集。
- 工作原理:引入信息论正则化来减轻特征级幻觉效应。
- Loss Weighting Method: 损失加权方法
- 局限性:使用机器翻译构建训练数据,可能限制其他语言的可行性。
- Knowledge Injection and Teacher-Student Approaches: 知识注入和教师-学生方法
- 工作原理:通过微调注入领域知识,利用更强大的LLM指导较弱的LLM。
- 优势:增强较小LLM的知识,无需依赖昂贵的指令。
- 局限性:仅包含一个弱开源LLM示例(BLOOM7B),仅集中于NBA领域分析。
- Hallucination Augmented Recitations (HAR): 幻觉增强背诵 (HAR)
- 工作原理:利用LLM幻觉创建反事实数据集,增强归因。
- 优势:显著改善文本基础,优于在事实数据集上训练的模型。
- Fine-tuning Language Models for Factuality: 针对事实性的语言模型微调
- 工作原理:利用自动事实检查方法和基于偏好的学习来微调模型。
- 工作原理:应用"行为微调"来增加信息寻求对话的忠实度。
- 工作原理:教导LLM在问题超出其能力范围时拒绝回答。
- 工作原理:将生成的序列及其未来序列视为假设,根据它们对输入事实的支持程度进行排名。
- 局限性:与基线方法相比,在推理过程中增加了计算成本。
作为一名Prompt工程师,在开发AI产品时,你可以采取以下措施来减少幻觉的影响:
1. 多源验证:不要仅仅依赖单一的LLM输出。尝试使用多个模型或结合外部知识源进行交叉验证。
2. 设置置信度阈值:要求模型输出其置信度,并只采用高置信度的回答,你可以在下面推荐的文章中看到示例。3. 分步推理:将复杂任务分解为多个子步骤,每一步都进行验证。
4. 上下文增强:提供充分的背景信息,帮助模型更好地理解任务需求。5. 定期更新:确保使用最新版本的模型和知识库,以减少过时信息导致的幻觉。
6. 领域适配:针对特定领域,收集高质量的数据进行微调,提高模型在该领域的表现。
7. 提示词工程:精心设计提示词,引导模型产生更加准确和可靠的输出。
8. 多用底层算法设计提示词:例如变分推理、梯度递减、递归内省等等

































 粤ICP备17114055号
粤ICP备17114055号