
在解决超级对齐问题中,强大的方法至关重要,但要信赖这些方法,我们同样需要理解它们何时以及为何有效。对从弱到强泛化能力的深入理解,有助于我们相信这种泛化能力在未来我们最为关注的高风险环境中也能持续发挥作用,并在此过程中助我们开发出更优化的方法。在本节中,我们将探讨与从弱到强泛化相关的两个现象:监督者错误的模仿以及强学生模型对任务的显著性。5.1 理解模仿现象
当我们使用弱监督来训练一个强大的模型以完成某项任务时,我们的期望是该模型能够尽可能出色地完成该任务,利用其从预训练中获得的潜在能力,显著超越弱监督者的表现。然而,我们可能无法实现这种期望的泛化能力的一个显著原因是,强大的模型反而学会了模仿弱监督者——预测弱监督者会如何对每个示例进行分类。特别是,如果弱标签中包含易于学习的系统性错误,强大的模型可能会学会模仿这些错误。这也是超级对齐理论研究中提出的一个关注点,即人类模拟器失效模式可能很重要:天真的人类监督可能导致超人类模型学会模仿人类会说的话,而不是输出其最佳预测(Christiano等人,2022)。
5.1.1 对弱监督的过拟合
模仿弱监督的失效模式与我们在前面提到的天真基线尤为相关,该基线直接训练学生模型去模仿监督者。在无限训练数据的情况下,天真地拟合弱标签应该会导致完美的模仿,且性能增益比(PGR)为零。但在实践中,我们仅在有限的数据上进行少量轮次的训练。然而,与典型的机器学习设置不同,我们即使在训练不到一个轮次时也可能观察到过拟合现象:强大的模型可能会过拟合到弱监督者的标签及其错误上,导致在训练过程中即使没有对任何特定训练示例的经典过拟合,真实测试准确性也会下降。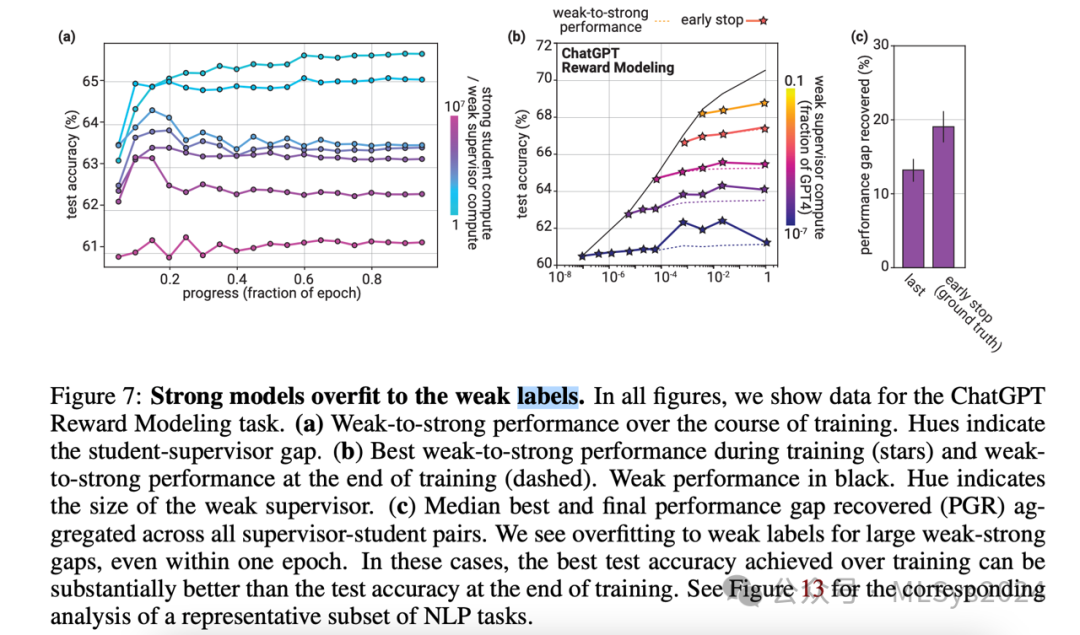
从经验上看,我们发现强大的学生模型确实似乎对弱监督者的错误产生了过拟合。在图7(a)中,我们展示了ChatGPT RM任务在训练过程中的真实测试准确性曲线,在图7(b)和(c)中,我们比较了最佳和最终的真实测试准确性(所有弱-强模型对的中位数)。我们发现,在弱-强差距较大的情况下存在过拟合现象。对于较小的弱-强差距,弱到强的性能通常在训练过程中单调增加。但对于较大的差距,弱到强的性能最初会增加,但随后在单个轮次结束前就开始下降。通过真实测试的早期停止(通过评估真实测试标签并在最优步骤停止来“作弊”)通常可以带来大约5个百分点的PGR提升。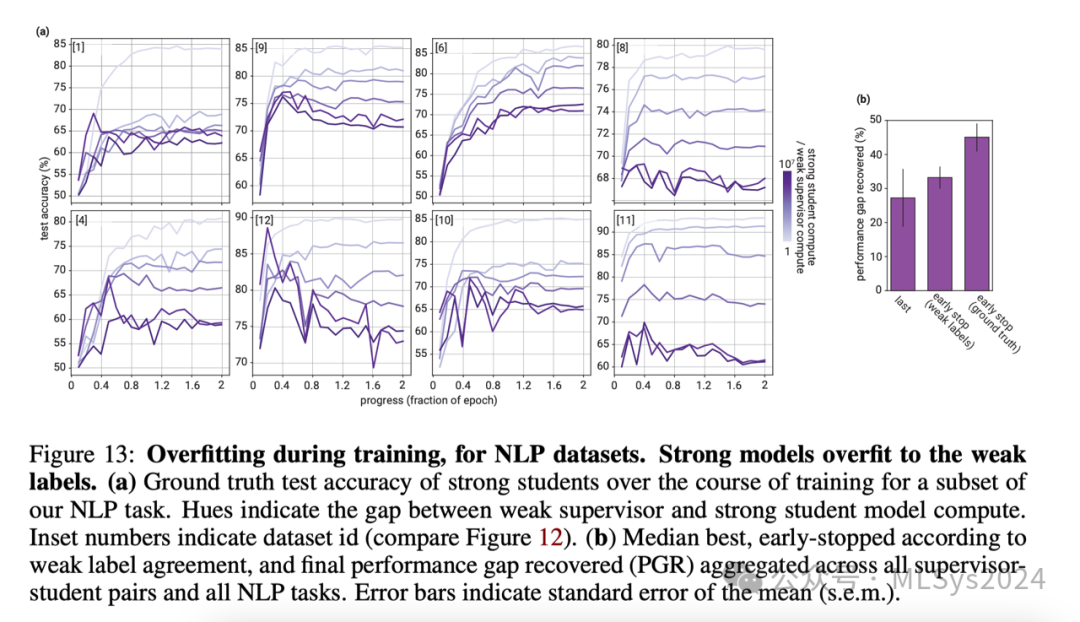
在图13中,我们在自然语言处理(NLP)任务中也观察到了相同的现象。在NLP设置中,我们发现基于真实测试的早期停止“作弊”比训练结束时的模型在PGR上提高了15个百分点,而与非“作弊”的基于弱标签的早期停止相比,PGR提高了10个百分点。不幸的是,使用真实标签作为早期停止准则并不构成一个有效的方法。然而,上述结果表明,在我们的设置中,模仿弱监督者错误可能是一个重要现象。此外,这些结果表明,通过减少对弱标签及其错误的过拟合,更好的早期停止或正则化策略可能能够显著改善弱到强的泛化能力。实际上,我们在图13中看到,辅助置信度损失显著减少了NLP任务中对弱标签的过拟合。在弱-强差距较大的情况下,使用天真方法时,基于真实测试的早期停止相比基于弱标签的早期停止在PGR上提高了15%,但使用置信度损失时,这一提升仅约为5%。5.1.2 学生与导师的一致性协议
衡量模仿效果的另一种方法是直接测量学生与导师之间的一致性:即在学生(假设为较强的模型)与导师(假设为较弱的模型)的预测中,有多少测试输入结果是相同的。请注意,如果一致性达到100%,那么从弱到强的准确率将等同于导师的准确率,且性能增益比(PGR)将为0。
一般而言,我们观察到,对于我们的基础微调模型,学生与导师之间的一致性始终较高,且往往显著高于导师本身的准确率。这表明学生在一定程度上模仿了导师的错误。这一现象在所有任务(包括自然语言处理任务、国际象棋和奖励建模)和所有模型规模下,对于基础方法均成立。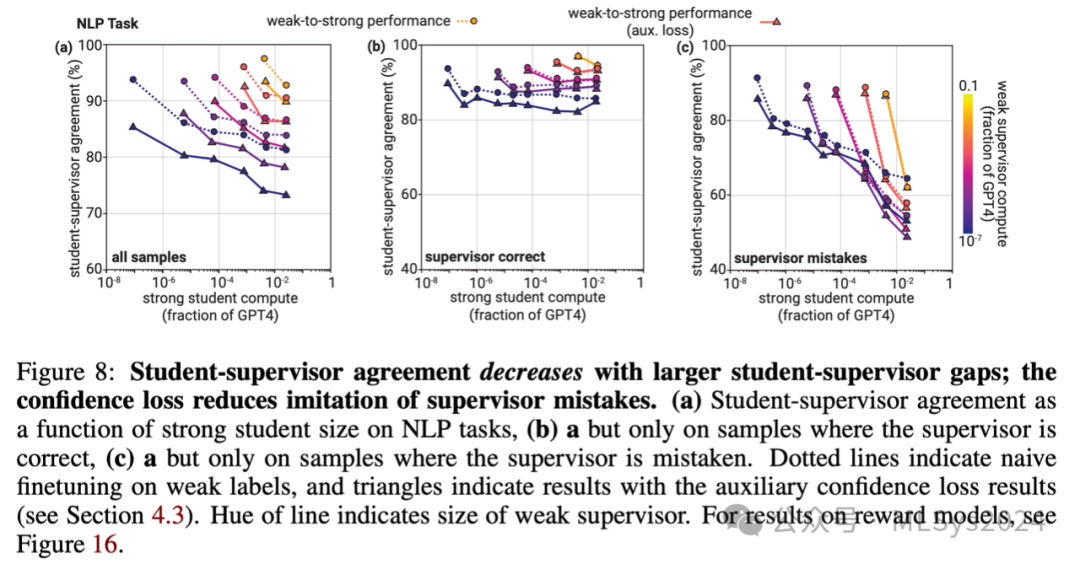
置信度损失显著降低了学生与导师之间的一致性(如图8所示),这主要是通过减少模仿导师错误来实现的(如图8c所示)。该损失鼓励强大的学生模型做出自信的预测,即使这些预测与导师的预测相矛盾。在少数最成功的情况下,置信度损失将学生与导师之间的一致性降低到了强学生模型的测试准确率(即弱到强的性能)以下,这意味着最终模型对真实概念的拟合优于其训练时所用的弱标签。5.1.3 模仿导师的逆尺度效应
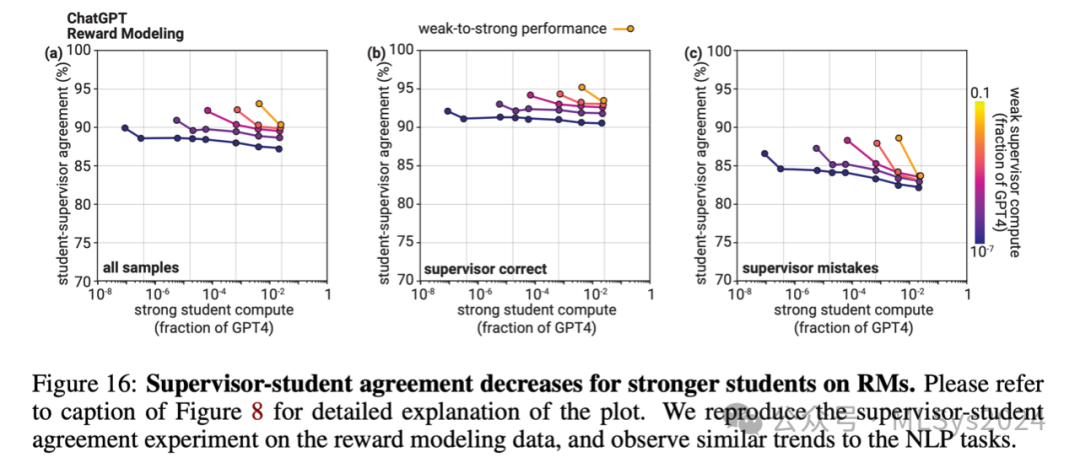
接下来,我们研究了学生与导师之间的一致性如何随强模型规模的变化而变化(见图8和图16)。令人惊讶的是,我们发现了逆尺度效应(McKenzie等人,2023):尽管大型学生模型被训练来模仿导师,且没有使用早停法,且容量大于小型学生模型,但它们与导师错误的一致性却显著低于小型学生模型。
如果我们仅在导师预测错误的数据点上评估一致性(如图8c所示),这一趋势尤为明显,并且即使使用交叉熵损失代替准确率来衡量,这一趋势也依然存在。这些结果表明,在数据相对有限的微调设置中,预训练模型可能难以拟合其他(较小)预训练模型的错误。Stanton等人(2021)和Furlanello等人(2018)在知识蒸馏的背景下报告了相关观察结果:即使模型有足够的容量,它们也很难拟合其他模型的预测。一个自然的假设是,(尤其是基础的)弱到强泛化在很大程度上取决于弱导师的错误结构以及这些错误被模仿的难易程度。我们展示了初步实验,测试不同类型的弱监督错误如何影响强学生模型的学习。我们的结果表明,对于学生难以模仿的错误,会导致更强的基础弱到强泛化能力,但即使这些错误易于模仿,置信度损失也能提供帮助。5.2 强模型表征中的显著性
当弱到强的泛化成为可能时,一个直观的感受是,我们想要激发的任务或概念在强模型内部是“显著”的。在本节中,我们将研究与学生模型试图激发的概念显著性相关的几种现象。
5.2.1 使用提示激发强模型知识
我们在第4节中观察到的高性能增益比(PGR)的一个可能原因是,激发强模型所掌握的知识相对容易。特别是,强大的预训练模型可能仅通过简单的提示就能以零样本的方式解决许多相关任务。
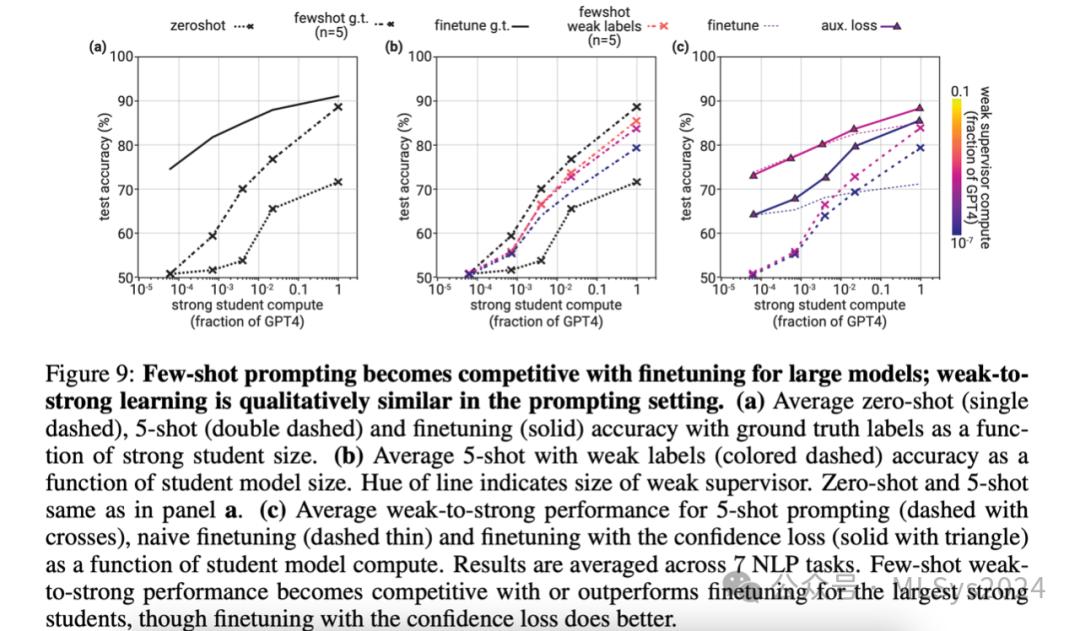
在图9a中,我们考虑了7个具有代表性的自然语言处理(NLP)任务,并比较了微调、零样本提示和五样本提示的效果。对于这次初步实验,我们在微调和五样本提示时使用了真实标签,而非弱标签。对于零样本和五样本基线,我们使用了表2中总结的特定任务提示。我们发现,对于大多数模型规模,零样本和五样本测试准确率较低,但正如Brown等人(2020)所述,随着模型规模的增大,准确率显著提高。特别是,对于最大的模型,五样本提示在许多任务上的表现与微调相当,这表明激发这些非常大模型的任务相关知识相对直接。我们还对少样本提示背景下的弱到强学习感兴趣。为了研究这一设置,我们构建了一个少样本提示,其中标签由弱导师提供。我们在图9b中报告了结果。与我们在微调设置中的发现一致,使用弱标签进行少样本提示的性能比使用真实标签进行少样本提示的性能更差。这表明,在提示设置中,弱到强的学习同样是一个非平凡的问题。与微调设置类似,对于更强的导师,少样本弱到强性能有所提升。与我们的弱到强微调基线(图9c)相比,对于较小的学生模型,少样本提示的弱到强性能较差,但对于最大的强学生模型,其性能变得具有竞争力,甚至超过了微调。然而,带有置信度损失的弱到强微调通常仍然优于弱到强少样本提示。总体而言,这些结果为我们关于弱到强泛化的研究提供了重要参考。它们表明,对于最大的模型规模,通过提示可以相对容易地激发解决许多任务所需的知识。然而,我们当前的设置可能在提示方面与微调存在更大的不同;我们的许多NLP任务可能在预训练期间已被隐式观察,我们推测这对提示的益处大于微调。5.2.2 生成性监督提升RM弱到强泛化
如果所需任务的显著表征对弱到强泛化有用,那么我们或许可以通过增加任务对强模型的显著性来提升泛化能力。一种无需真实标签即可增加任务显著性的方法是,使用与任务相关的数据进行无监督微调,以语言建模为目标(Dai & Le, 2015)。例如,通过无监督方式在在线评论上微调语言模型,可以使情感在模型内部得到显著表征(Radford et al., 2017)。我们在奖励建模设置中测试了这一想法,其中,使用演示所需行为的基线进行模型初始化是标准做法(Stiennon et al., 2020)。在我们的案例中,我们重用了ChatGPT对比数据,而不是引入新的监督数据集。对比数据包括一个前缀(用户与助手之间的单个请求或对话)和至少两个候选完成项。我们忽略完成项之间的人类偏好,仅对所有前缀-完成项对使用语言建模损失来微调基础模型。
请注意,这些对包括被人类评估者评为最差的完成项,因此,从原则上讲,这个过程不应该泄露弱到强模型不应访问的真实偏好标签的任何信息。另一方面,由于完成项可能来自人类或更强大的模型,因此可能存在类似预训练泄露的类似泄露。即使在这种设置中,奖励建模任务也极具挑战性,我们将解决这种不同步(例如,仅从较弱的模型收集完成项)的工作留给未来。我们发现,在RM数据上进行额外的生成性微调可以提高弱到强的性能。由于这一过程也改善了使用真实RM数据训练的模型性能,因此我们将新的弱到强性能与也经过相同方式生成性微调的强大“天花板”模型进行了比较。即使调整了这一天花板,我们也发现生成性监督将PGR提高了约10-20%。我们在图10中报告了结果。
此外,生成性微调带来的改进与真实早期停止(一种“作弊”方法,用于说明如果我们能最优地提前停止,则可能实现的潜在性能,见第5.1.1节)带来的改进相结合。当我们结合这两种技术时,我们可以实现约30-40%的PGR,这将使RM任务上的结果与我们在NLP和国际象棋谜题任务上观察到的弱到强泛化相媲美。我们可以将使用相关数据进行生成性微调以提高任务显著性的想法应用于所有设置,并相信这可能是未来研究的一个有前途的方向。5.2.3 弱监督微调以增强概念显著性
衡量概念显著性的一个可能指标是任务在何种程度上是线性表示的。具体而言,我们可以通过训练一个基于模型冻结激活的线性探针(逻辑回归分类器)来评估其性能。如果最优解可以通过线性探针近似恢复,这将极大地简化我们的问题;我们可以专注于线性探针方法而非微调方法,从而大大减少我们需要考虑的以引出所需泛化能力的搜索空间。在我们的工作中,我们仅关注在嵌入层之前的最终激活中,任务是如何线性表示的。
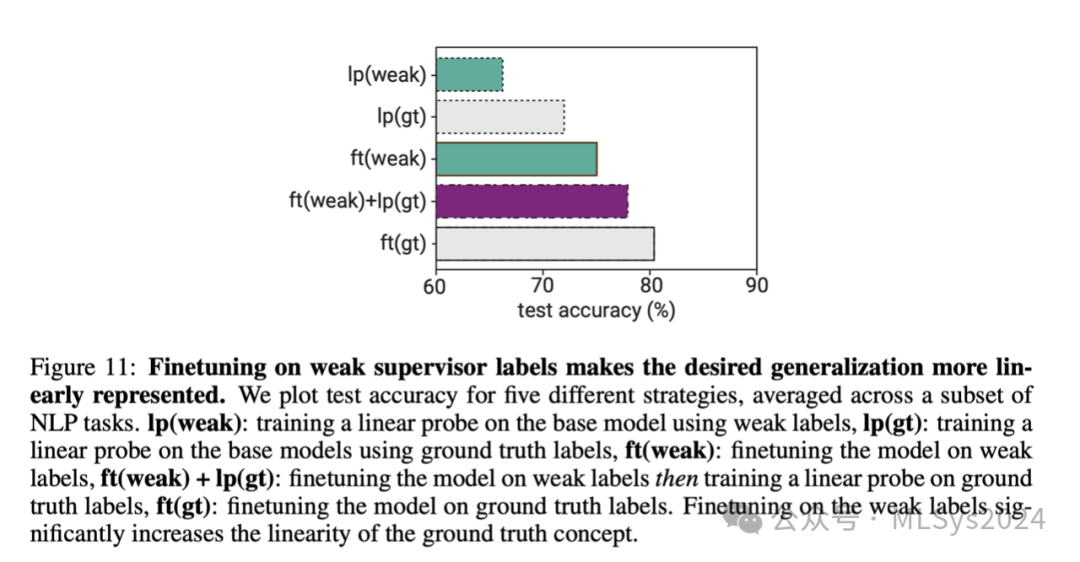
在图11中,我们针对我们NLP数据集的一个子集,绘制了几种不同组合(1)微调或线性探针,使用(2)弱标签或真实标签的平均测试准确率。首先,我们展示了使用真实标签训练的线性探针(平均准确率为72%)的性能低于使用真实标签的微调(平均准确率为82%),这表明大多数任务的最优解在强大模型的最终激活中并非完全线性表示。作为对比,我们还报告了使用弱标签进行线性探针和微调的结果,这些结果验证了它们的表现不如使用真实标签。然而,我们发现,首先使用弱标签对模型进行微调,然后使用真实标签进行线性探针,可以显著提高性能。换句话说,当我们使用弱标签对强大模型进行微调时,即使对于真实标签,表示也变得更加线性。事实上,先在弱标签上进行微调,然后在真实标签上进行线性探针,可以达到78%的准确率,缩小了真实标签线性探针与微调之间60%的差距。这也明显优于简单的弱到强微调基线。这一现象与Kirichenko等人(2023)在虚假线索文献中报道的最新发现密切相关。他们发现,在有偏见的监督下对模型进行微调可能会导致模型产生非常偏见的输出,但出乎意料的是,这些模型对所需概念的线性表示却非常强。这些结果表明,提高弱到强泛化能力的一种替代方法是先“线性化”所需概念,例如通过简单地在弱标签上进行微调。然后,我们可以使用更简单的基于线性探针的弱到强方法来引出所需概念。6 讨论
在本文中,我们提出了一个简单的类比来研究对齐超人模型的核心挑战,并表明在这个问题上取得显著进展是可行的。然而,我们的设置仍然存在重要的非类比性,我们现在将详细阐述。然后,我们概述了未来工作的一些有前景的方向。6.1 剩余的非类比性
模仿显著性:超人模型可能很容易模仿弱错误。未来的模型很可能非常擅长预测人类会思考和说什么,尤其是如果它们以与当前模型类似的方式在人类数据上进行训练。因此,如果我们天真地用人类监督来训练这样的超人模型,它可能会简单地模仿弱监督者,输出人类水平的能力,而不是其潜在的超人能力(Christiano等人,2022)。这个问题在我们的设置中只被部分捕捉到。虽然我们的强大预训练模型确实在一定程度上模仿了弱监督者,但它们并没有明确地被预训练来模仿弱模型,而且我们第5.1.3节的结果表明,更大的强大模型甚至可能更难进行这种模仿。因此,“模仿弱监督者”在我们的设置中可能不像在最终的超级对齐问题中那样是一个大问题。这可能会夸大当前的泛化性能。我们认为,对这一问题的更深入研究是未来工作的一个重要领域。预训练泄露:超人知识可能是潜在的,不可观察的。我们在这项工作中考虑的许多任务可能已经在预训练中至少间接地被观察到,例如通过在线论坛上的问题或对任务的轻微重构。例如,很有可能SciQ NLP任务中类似的简单科学问题以某种形式隐含地存在于我们的GPT-4系列预训练数据集中。然而,未来的超人模型可能永远不会直接观察到与超人对齐相关的能力;这些能力可能主要是“潜在的”,例如通过自监督学习或强化学习而不是通过模仿学习来学习。直觉上,潜在能力可能比模型在预训练数据中观察到的能力更难引出。这种非类比性可能导致我们的结果过于乐观。我们推测,这种非类比性对提示性能(第5.2.1节)的提升作用比对微调性能的提升作用更大;直觉上,提示可能在模型认为观察概率较高的任务上尤其有效。如果是这样,那么在我们的设置中,提示将比微调更不具有类比性。我们希望在未来的工作中验证这一推测。在附录D.1中,我们展示了一个概念验证,即弱到强的泛化仍然可以引出在预训练期间从未明确观察到的潜在能力,即使在不可能进行提示的情况下也是如此。特别是,我们使用AlexNet(Krizhevsky等人,2012)来监督使用DINO(Caron等人,2021)预训练的模型,DINO是一种在计算机视觉中学习的强大表示的自监督方法。我们发现,尽管学生在预训练期间从未观察到任何分类标签,但强大的学生模型的泛化能力仍然显著超出了AlexNet的性能。未来的工作应更系统地研究和缓解这种预训练泄露的非类比性。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
