
广泛采用的对齐技术,如基于人类反馈的强化学习(RLHF),其核心在于依赖人类来监督并评估模型行为,如是否严格遵循指令或输出安全性。然而,面对未来复杂多变的超人类模型行为,人类的评估能力将显得力不从心,仅能提供弱监督。我们构建了一个类比情境来探讨:利用弱模型的监督,是否能充分激发远胜于其的强模型之全部潜能?通过在一系列NLP、国际象棋及奖励建模任务中,运用GPT-4家族内的多种预训练语言模型进行测试,我们发现了有趣的现象——“从弱到强的泛化”:即便仅依据弱模型生成的标签对强模型进行微调,这些强模型的表现仍显著优于其弱监督者。然而,令人遗憾的是,仅凭这种基础微调手段,我们尚无法完全解锁强模型的全部能力,这预示着RLHF等现有技术若不加以改进,或将难以适应未来超人类模型的需求。但值得庆幸的是,我们发现了一些简单而有效的策略能显著提升这种“从弱到强”的泛化效果。比如,在GPT-4的微调过程中引入GPT-2级别的监督者及辅助置信度损失,便能在NLP任务上实现接近GPT-3.5的性能表现。综上,我们的研究表明,在应对超人类模型对齐这一核心挑战上,我们已迈出坚实的实证步伐,未来可期。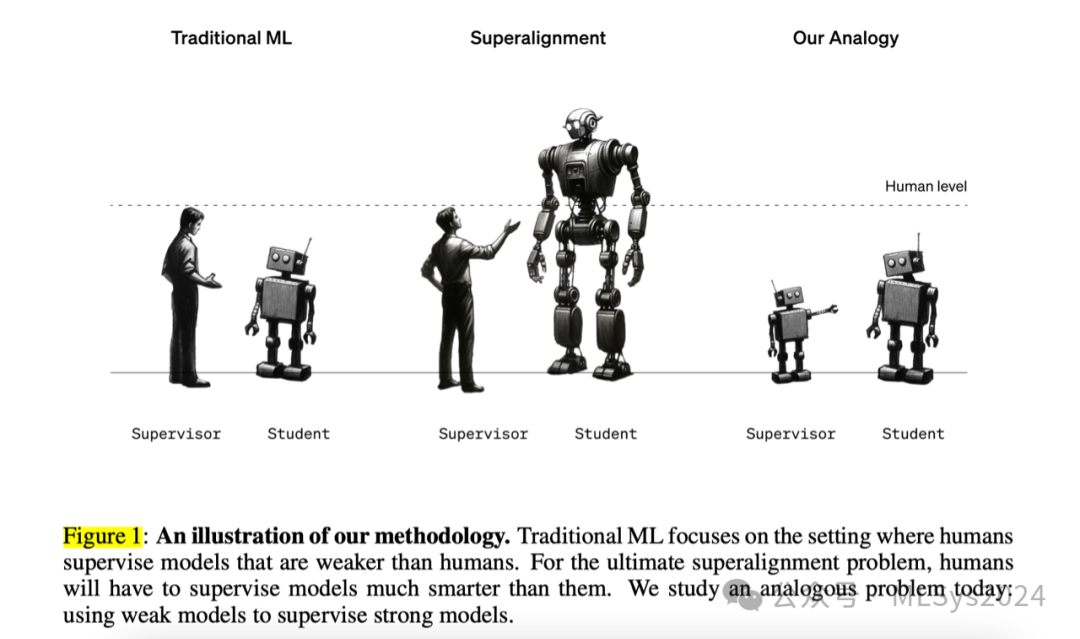
1 引言
当前,我们主要通过基于人类反馈的强化学习(RLHF)来引导或对齐模型:我们强化人类评估者评价高的行为,并惩罚评价低的行为(Christiano等人,2017;Stiennon等人,2020;Ouyang等人,2022;Glaese等人,2022;Bai等人,2022a)。当人类评估者能够判断模型行为的好坏时,这一方法非常有效,并且是训练现代语言模型助手(如ChatGPT)的核心部分。然而,超人类模型将具备复杂且富有创造性的行为,这些行为人类可能无法完全理解。例如,如果一个超人类助手模型生成了数百万行极其复杂的代码,人类将无法为关键的对齐相关任务提供可靠的监督,包括代码是否遵循用户意图、助手模型是否诚实回答有关代码的问题、代码执行是否安全或危险等。因此,如果我们使用人类监督在奖励建模(RM)或安全分类任务上对超人类模型进行微调,那么该模型如何泛化到人类自身无法可靠监督的复杂行为上,这一点尚不清楚。这引出了一个关于对齐超人类模型(超级对齐)的基本技术挑战:弱监督者如何控制远超自身智能的模型?尽管这个问题至关重要,但目前却难以进行实证研究。大多数关于对齐的先前工作要么直接面对这一核心挑战,但仅限于理论框架和简单问题(Irving等人,2018;Christiano等人,2018;Leike等人,2018;Demski & Garrabrant,2019;Hubinger等人,2019),要么仅实证研究了人类对当今模型的监督,而没有解决超人类模型可能带来的核心挑战(Christiano等人,2017;Wu等人,2021;Ouyang等人,2022;Bowman等人,2022;Saunders等人,2022)。相比之下,我们理想中的研究设置应既能捕捉未来超人类模型对齐的核心挑战,又能让我们在今天就能取得迭代的实证进展。我们提出了一个简单的研究框架,通过类比的方式来探讨人类如何监督超人类模型的问题:我们能否利用弱模型来监督强模型?我们可以通过在小(弱)模型生成的标签上微调大(强)的预训练模型,并观察其泛化情况来进行实证测试。正如人类监督超人类模型的问题一样,我们的研究框架也是我们所称的“弱到强学习问题”的一个实例。为什么弱到强学习是可能的呢?一方面,强模型可能会简单地模仿弱监督者的行为,包括其错误,因为这是我们最初训练它的方式。另一方面,强大的预训练模型应该已经对我们关心的对齐相关任务有了良好的表示。例如,如果一个模型能够生成复杂的代码,那么它应该也能直观地知道这段代码是否忠实地遵循了用户的指令。因此,在对齐的目的下,我们并不需要弱监督者来教授强模型新的能力;相反,我们只需要弱监督者来激发强模型已经具备的知识。这让我们有理由相信,强模型能够超越弱监督的局限,解决那些弱监督者只能给出不完整或有缺陷训练标签的难题。我们将这种现象称为“弱到强泛化”。我们通过微调来自GPT-4系列的基准(即仅预训练的)语言模型(OpenAI,2023),在三个不同场景下研究了我们的弱到强学习框架:一组广泛使用的自然语言处理(NLP)基准测试、国际象棋谜题以及我们内部的ChatGPT奖励建模数据集。我们的主要发现包括:- 如果我们简单地使用弱模型生成的标签对强模型进行微调,它们通常会一致性地超越其弱监督者。例如,在NLP任务中,如果我们使用GPT-2级别的模型标签对GPT-4进行微调,我们通常能够缩小两个模型之间大约一半的性能差距。
- 尽管存在积极的弱到强泛化现象,但使用弱监督微调的强模型与使用真实监督微调的强模型之间仍存在显著差距。在ChatGPT奖励建模方面,弱到强的泛化尤其不佳。总的来说,我们的结果为这样一个经验性证据提供了支持:如果没有额外的工作,简单的RLHF(强化学习与人类反馈循环)很可能无法很好地扩展到超人类模型。
- 通过鼓励强模型做出自信预测的辅助损失、使用中间模型引导监督以及通过无监督微调改进模型表示,我们可以提高性能。例如,在NLP任务上,当我们使用GPT-2级别的模型和辅助置信损失来监督GPT-4时,我们通常能够恢复弱模型与强模型之间近80%的性能差距。
我们的工作存在重要局限性,我们的方法在任何环境下都无法持续有效,尤其是在奖励建模(RM)设置中,我们仍然远远未能弥补弱模型与强模型之间的全部性能差距。因此,我们的方法更多是作为弱到强泛化可行性的概念验证,而非我们当前推荐部署的实际解决方案。此外,我们的实验设置与对齐超人类模型之间仍存在一些我们尚未解决的重要差异;不断优化我们的基本设置对于确保当前研究持续取得真正进展,以对齐我们未来开发的超人类模型至关重要。尽管我们的工作存在局限性,但我们发现结果非常鼓舞人心。我们证明,显著的弱到强泛化不仅可能,而且实际上是一种普遍现象。我们还表明,通过非常简单的方法,我们可以显著提高弱监督者从强模型中提取知识的能力。如果在这方面取得更大进展,我们或许能够使用弱监督者可靠地从更强模型中提取知识,至少在我们关注的一些关键任务上。这可能使我们能够开发出超人类奖励模型或安全分类器,进而用于对齐超人类模型。对齐超人类模型对于确保其安全性至关重要;人们日益认识到,未能对齐这些强大的模型可能会带来灾难性后果,使其成为世界上最重要的未解决技术问题之一(CAIS)。我们认为,现在比以往任何时候都更容易在解决这一问题的过程中取得快速迭代的实证进展。2 相关工作
我们致力于研究如何利用深度神经网络的泛化特性来解决弱到强学习问题。我们的问题设定和方法与许多现有研究领域紧密相连。弱监督学习:弱到强学习是弱监督学习的一种特殊类型,在这种设定下,模型利用不可靠的标签进行训练(Bach等人,2017;Ratner等人,2017;Guo等人,2018)。关于从带噪声标签中学习的相关问题,也有大量文献(Song等人,2022)。常见方法包括引导学习(Reed等人,2014;Han等人,2018;Li等人,2020)、抗噪声损失(Zhang & Sabuncu,2018;Hendrycks等人,2018;Ma等人,2020)和噪声建模(Yi & Wu,2019)。与大多数关于标签噪声的研究不同,我们弱监督中的错误比均匀标签噪声更难处理,因为它们具有“实例依赖”性(Frénay & Verleysen,2013)。半监督学习(仅部分数据有标签)也与我们的问题密切相关(Kingma等人,2014;Laine & Aila,2016;Berthelot等人,2019)。我们还可以在半监督设置下研究我们的问题,即“容易”子集由弱监督者提供可靠标签,而“困难”子集则是弱监督者无法可靠标注的无标签示例,我们称之为“易到难泛化”(见附录C)。师生训练框架:首先训练教师模型,然后在教师的伪标签上训练学生模型的框架在半监督学习(Laine & Aila,2016;Tarvainen & Valpola,2017;Xie等人,2020)、领域自适应(French等人,2017;Shu等人,2018)和知识蒸馏(Hinton等人,2015;Gou等人,2021;Stanton等人,2021;Beyer等人,2022)中广泛应用。与大多数先前工作不同,我们关注的是学生模型能力远超教师模型的情况。Furlanello等人(2018)和Xie等人(2020)也考虑了学生模型至少与教师模型一样能干的情况。但在他们的设置中,学生模型是随机初始化的,并且可以访问真实标签。此外,与大多数过去的工作相比,我们专注于定性上非常弱的监督。例如,我们关注于从“三年级水平”的监督者到“十二年级水平”的学生模型的巨大泛化飞跃。尽管与过去的工作存在这些差异,但我们期望许多来自半监督学习和领域自适应的方法能够适用于我们的设置。例如,我们发现在,一种类似于过去工作的置信度辅助损失(Grandvalet & Bengio,2004)提高了弱到强的泛化能力。预训练与微调的鲁棒性:许多论文表明,在大量且多样的数据上进行预训练可以获得更鲁棒的特征表示,从而更好地实现域外泛化(Hendrycks等人,2019;2020b;Radford等人,2021;Liu等人,2022)。微调通常能提高域内泛化能力,但在域外表现往往不佳,有时甚至低于零样本提示的性能(Kumar等人,2022;Wortsman等人,2022b;Awadalla等人,2022)。为解决这一问题,近期的方法包括权重集成(Wortsman等人,2022b;a)、仅微调部分层(Kirichenko等人,2023;Lee等人,2022a)或减轻微调对预训练特征产生的扭曲效应(Kumar等人,2022)。我们在初步探索中并未发现与这些方法类似的显著结果,但我们期待通过更深入的探索,利用这些或来自鲁棒微调文献中的其他想法,可能能够取得更强的结果。去偏:在弱到强泛化中,弱标签包含一种特定形式的偏差,这是由于弱模型能力不足所致。关于从有偏训练数据中学习的研究文献相当丰富(Bellamy等人,2018)。然而,大多数工作关注于已知偏差,例如我们知道模型在少数群体上表现更差。对于已知偏差,常见方法包括群组分布鲁棒优化(Sagawa等人,2019)、对抗训练(Zhang等人,2018)和模型编辑(Santurkar等人,2021;Meng等人,2022)。相比之下,我们的设置可以视为一个特别困难的去偏问题,其中偏差是未知的。一些能够自动发现和减轻偏差的方法包括聚类(Sohoni等人,2020)、损失方差减少(Khani等人,2019)以及对高损失组进行审计和再训练(Kim等人,2019;Liu等人,2021)。模仿学习与偏好学习:对齐的目标是引导已具备能力的模型按照我们的期望行事。比如,基础GPT-4模型擅长根据预训练分布生成文本,但不太容易遵循指令。当前,为了对齐预训练语言模型,我们采用模仿学习(Bain & Sammut, 1995; Atkeson & Schaal, 1997),通过人类演示对其进行微调,或者利用如从人类反馈中强化学习(RLHF)(Christiano et al., 2017; Stiennon et al., 2020; Ouyang et al., 2022; Glaese et al., 2022; Bai et al., 2022a)等方法。尽管宪法AI(Constitutional AI, Bai et al., 2022b; Lee et al., 2023)利用AI反馈来对齐语言模型,但它仍需要初始的RLHF阶段。然而,模仿学习与偏好学习均假设高质量的人类监督,这让人不确定它们是否能适用于超越人类水平的模型。可扩展的监督技术:可扩展的监督技术旨在提升人类对模型进行监督的能力。例如,人类可以要求模型评估其他模型的输出(Irving et al., 2018; Saunders et al., 2022),或使用模型协助将问题分解成更简单的子问题(Leike et al., 2018; Christiano et al., 2018; Lightman et al., 2023)。这些技术通常利用问题的特殊结构,如可分解性或评估比生成更容易的特点。与提升人类监督能力不同,我们专注于超越人类监督的泛化能力,确保模型即使在无法可靠监督的环境下也能表现良好。此外,我们的弱到强学习设置可用于比较可扩展监督方法、基于泛化的方法等。该设置还类似于一种被称为“三明治”的测量可扩展监督进展的提议,该提议使用弱监督与强监督的人类评估(Cotra, 2021; Bowman, 2022)。知识诱导与诚实性:Christiano等人(2022)提出了一个理论问题——诱导潜在知识(ELK),其目标是在最坏情况假设下,从超越人类水平的机器学习模型中诱导出潜在知识。例如,ELK的一个特例是诚实性(Evans et al., 2021),即模型应报告其真实信念。Wentworth(2020)假设神经网络有发展出更易于诱导的“自然抽象”的倾向。近期关于ELK的实证研究包括测量篡改基准(Roger et al., 2023)、发现潜在知识的方法(Burns et al., 2023)以及对诚实性的研究(Li et al., 2023; Pacchiardi et al., 2023)。我们的设置可以被视为一种通用方法,用于跨广泛任务范围实证研究ELK和诚实性等问题。3 方法
超级对齐的核心挑战在于,人类需要监督比自己聪明得多的模型。这恰好是我们所说的“弱到强学习问题”的一个特例:一个较弱的监督者如何能有效监督远超自身的模型?在本文中,我们通过一个简单的类比进行研究,即将较弱的人类监督者替换为较弱的模型监督者。对于某一特定任务(包括数据集和性能指标),我们按以下步骤进行:- 创建弱监督者:在本文的大部分工作中,我们通过在真实标签上微调小型预训练模型来创建弱监督者。我们将弱监督者的性能称为“弱性能”,并通过弱模型在保留集上的预测来生成弱标签。
- 使用弱监督训练强学生模型:我们利用生成的弱标签来微调一个强大的模型。这个模型我们称之为“强学生模型”,其性能称为“弱到强性能”。
- 使用真实标签训练强模型作为上限:最后,为了比较,我们使用真实标签来微调一个强大的模型。这个模型的性能我们称之为“强上限性能”。从直觉上讲,这代表了“强模型所知道的一切”,即强模型将其全部能力应用于该任务。
通常,弱到强性能会介于弱性能和强上限性能之间。我们定义了“性能差距恢复”(PGR)作为上述三种性能(弱性能、弱到强性能、强上限性能)的函数,如下图所示。
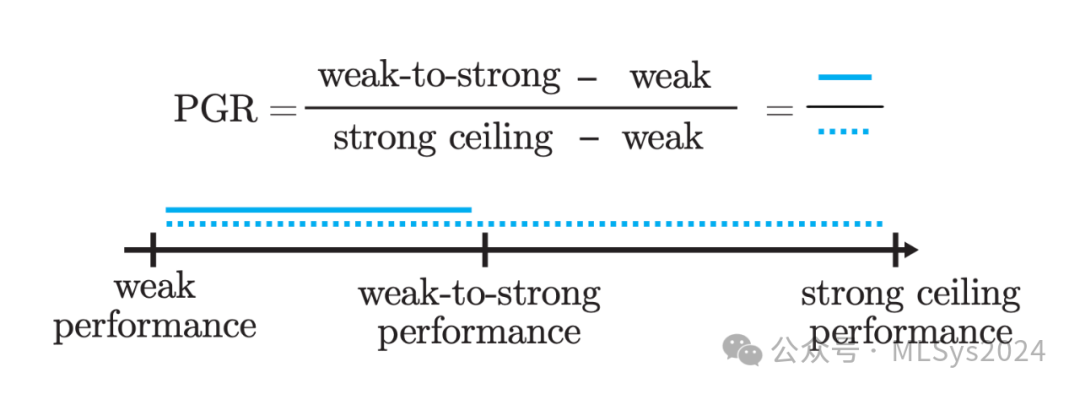
PGR衡量的是我们在弱监督下能够恢复的性能差距(即弱模型和强上限模型之间的性能差异)的比例。如果我们实现了完美的弱到强泛化,PGR则为1。如果弱到强模型的性能并不优于弱监督者,那么PGR则为0。- 灵活性:可以适用于任何弱模型和强模型的组合,便于研究扩展规律,且无需使用昂贵的最先进模型。此外,它不需要人类参与,因此反馈循环更快。
- 广泛适用性:可以针对任何感兴趣的任务进行研究,便于在多种设置下进行实证测试。
- 即时实用性:即使在开发超人模型之前,成功的应用也具有实际意义。例如,如果我们找到仅通过弱人类监督或仅通过GPT-3级别的监督来对齐GPT-4的方法,那么这将使当前的模型对齐工作更加便捷。
局限性:我们的设置与最终的超人模型对齐问题之间仍存在重要差异。我们认为我们的设置消除了先前工作中的一些主要差异,但并未提供一个最终、完全相似的设置。剩余的两个主要差异包括:- 模仿显著性:未来的超人模型可能具有显著的人类行为表征,但我们的强模型可能尚未学习到与模仿弱模型预测相关的特征;因此,在我们的设置中,简单地模仿弱监督者可能更容易避免失败模式,而在未来则可能更为困难。更一般地说,当前弱模型所犯的错误类型可能与人类在未来尝试监督超人模型时所犯的错误类型不同。
- 预训练泄露:我们的预训练数据隐式地包含了人类监督。因此,在我们的设置中,激发强模型的能力可能相对容易,因为它们直接预训练为观察强大的(人类级别的)性能。而超人级别的性能可能无法以同样的方式直接观察到——超人知识可能更加隐晦,例如,因为它是通过自监督学习获得的——因此,未来从超人模型中激发这些知识可能更加困难。更一般地说,我们尚不清楚超人模型将如何构建,但它们可能会发展出与当前模型在性质上截然不同的归纳偏差。我们认为,在未来工作中,不断优化我们的方法以产生更加相似的设置是一项关键任务
4 实验结果
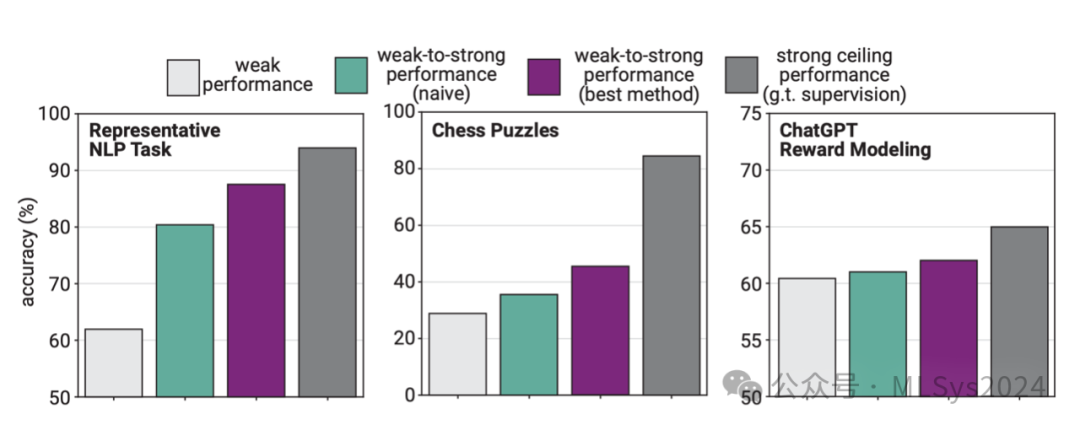
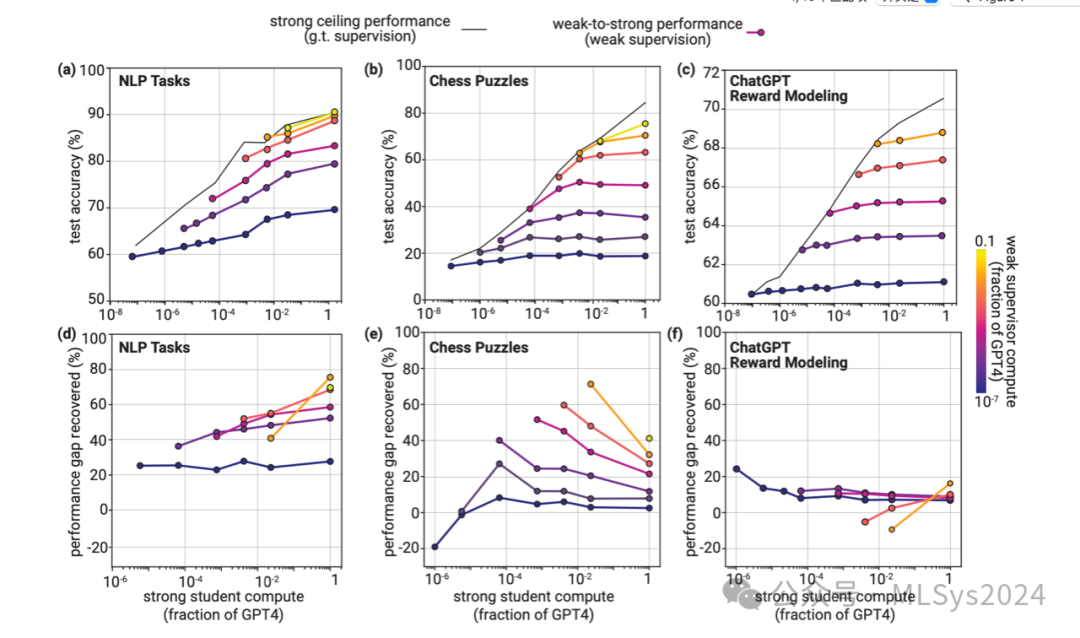
在以下三个场景(NLP任务、国际象棋谜题和奖励建模)中,我们评估了强学生在弱监督者生成的标签上进行简单微调后的泛化能力。我们研究了GPT-4系列(OpenAI, 2023)的预训练语言模型,这使得我们能够研究学生和监督者之间计算量差异极大的情况。我们发现,在所有我们研究的场景中,以及几乎所有学生和监督者规模下,PGR(性能差距恢复率)几乎都是正的——即学生表现优于其监督者(上图)。在流行的NLP基准测试中,我们发现了特别有前景的弱到强泛化现象:使用弱监督训练的强模型往往能够泛化到远高于弱模型本身的性能水平。即使是非常弱的监督者和计算量高出多个数量级的强模型,我们也能恢复超过20%的性能差距。PGR随着弱监督者规模和强学生规模的增加而增加;对于最大的学生模型,PGR通常超过50%。在国际象棋谜题设置中,我们观察到的结果更为复杂。特别是当使用最小的弱模型时,PGR接近零,测试准确率曲线趋于平缓。然而,随着弱监督者规模的增加,PGR显著增加;在监督者与学生规模差距较小的情况下,PGR可以超过40%。与NLP设置不同,在国际象棋谜题中,给定弱监督者,PGR并不随强学生规模的增加而增加,反而减少。相应的测试准确率曲线呈凹形,可能表现出强学生规模上的逆扩展性(McKenzie等人,2023)。最后,我们发现在ChatGPT奖励模型设置中,弱到强的泛化能力默认较差。我们通常只能恢复弱监督者和强学生之间大约10%的性能差距。即使弱模型和强模型之间的计算量差距相对较小,PGR也几乎从未超过20%。总的来说,在所有我们研究的场景中,我们都观察到了弱到强的泛化现象:强学生始终如一地超越了其弱监督者。这本身并不显而易见——尤其是仅通过简单的微调——这让我们对弱到强学习是一个可解决的问题抱有希望。同时,我们的结果也表明,单纯使用弱、人类级别的监督来对齐强大的超人模型将是不够的;我们需要全新的技术来解决超级对齐问题。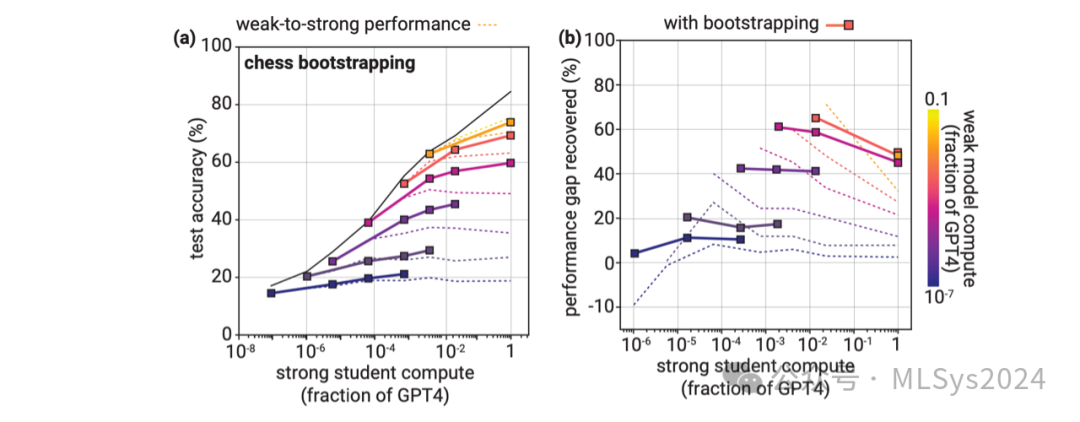
引导对齐(Bootstrapping)是长期以来在对齐领域中的一个重要思路:我们不必直接对齐那些远超人类的模型,而是可以先对齐一个仅略高于人类的模型,然后用它来对齐一个更智能的模型,以此类推(Christiano, 2019; 2018; Leike & Sutskever, 2023; Worley, 2021)。我们的设置使我们能够实证检验这一思路。具体而言,我们可以构建一系列模型大小逐渐增加的序列 M1 → M2 → ... → Mn。然后,我们使用 M1 生成的弱标签来微调 M2,再用 M2 生成新的弱标签来微调序列中的下一个模型 M3,依此类推。
我们在国际象棋谜题设置中评估了引导对齐的效果。当我们直接在国际象棋的弱标签上进行微调时,我们发现当监督者与学生之间的差距较小时,性能差距恢复率(PGR)较高,但差距增大时,PGR 则较低。因此,在这种设置下,采取多个小步骤(每一步的 PGR 都应较高)可能比一步到位更为有效。在每一轮引导对齐中,我们进行了三轮弱到强的学习迭代,即我们在最终微调序列中最大的模型之前,使用两个中间模型大小来引导弱监督。我们在上图中报告了结果(包括每轮引导对齐中的所有中间弱到强模型)。与基线相比,引导对齐提高了PGR,特别是对于较大的学生模型。使用直接方法时,随着弱强差距的增大,迁移准确率曲线趋于平缓;而使用引导对齐,准确率则持续单调提升。虽然在国际象棋设置中的结果令人鼓舞,但在初步实验中,我们观察到在NLP任务和RM设置中,引导对齐仅带来了微小的改进,甚至在某些情况下没有改进。这从直觉上来说是合理的:与在国际象棋设置中,随着监督者与学生之间差距的增大,直接PGR下降不同,在NLP和奖励建模设置中,随着差距的增大,直接PGR要么增加,要么大致保持不变。总体而言,这些结果表明,引导对齐是探索改善弱到强泛化能力的一个可行途径,并且在某些设置下可能有所帮助,但仅凭引导对齐本身并不足以使模型对齐到远超其监督者的智能水平。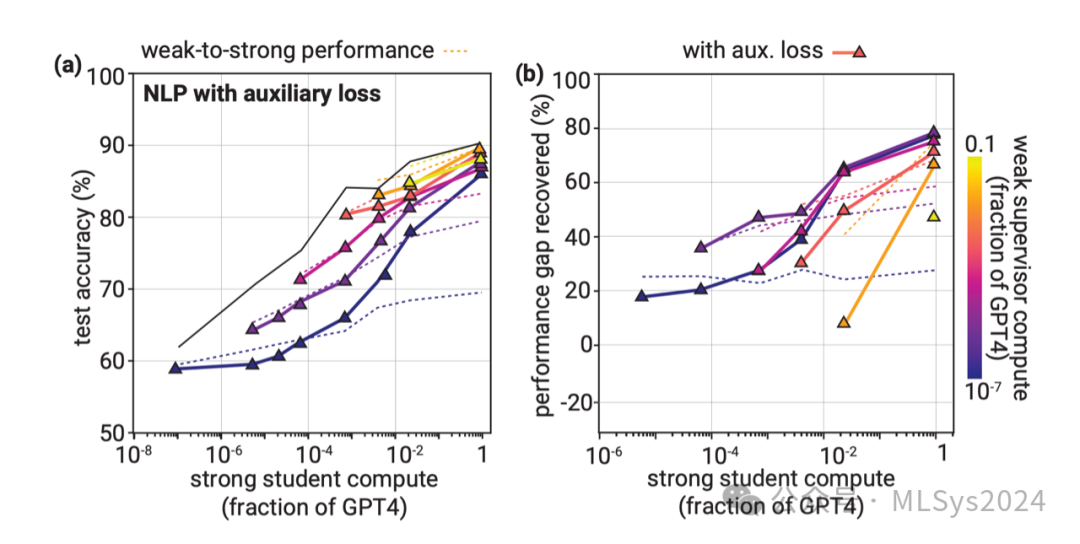
在我们的基线结果中,我们直接对强大的学生模型进行了微调,使用的是弱监督者提供的标签。由于我们直接训练强大的学生模型去模仿弱监督者,它可能也会学习到监督者的错误。直觉上,我们希望避免这种失败模式,并为学生模型提供额外的正则化,使其更加符合强大预训练模型内部已有的知识:我们希望学生模型学习监督者的意图,而不是模仿其错误。
为了实现这一直觉,我们在标准的交叉熵目标函数中增加了一个辅助的置信度损失项。这种方法与条件熵最小化(Grandvalet & Bengio, 2004)密切相关,是半监督学习中的一种重要技术。具体来说,我们增加了一个额外的损失项,用于增强强大模型对其自身预测的置信度——即使这些预测与弱标签不一致。我们在附录A.4中对该方法进行了详细描述。在上图中,我们绘制了使用该方法在NLP任务上的准确率和PGR曲线。我们发现,虽然对于较小的强大学生模型,其性能略逊于简单的基线方法,但在弱模型和强模型之间计算能力差距较大的情况下,它显著提高了泛化能力。在最小的弱监督者和最大的强学生模型组合下,置信度损失将中位PGR从约25%提升至近80%。此在某些情况下,置信度损失并未带来太大帮助或甚至降低了性能,例如当弱监督者和强学生模型之间的差距较小时,或者数据集特征在即使使用真实监督的情况下也呈现逆缩放时。但置信度损失在大多数NLP数据集上显著提高了性能,对于许多数据集,我们几乎实现了完美的泛化,即使使用最小的弱监督者,也能恢复强模型的大部分性能。最后,我们找到了与置信度损失的动机直觉相一致的证据(允许强大的学生模型自信地不同意其弱监督者):辅助损失减少了强学生模型对弱错误的模仿,并减轻了弱标签过拟合的问题。5 理解
从弱到强的泛化:弱监督激发强大能力(下)






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
