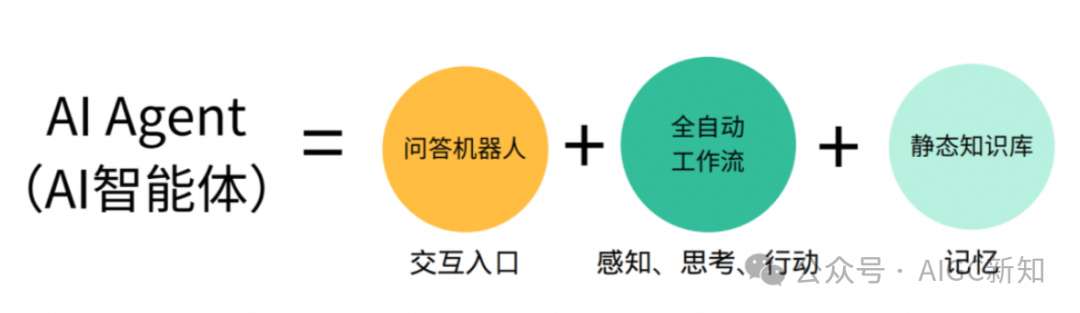
AI Agent(AI代理)是一种能够感知外部环境、进行自动决策和执行动作的智能实体。不同于传统的人工智能, AI Agent 具备通过独立思考、调用工具去逐步完成给定目标的能力。
受限于数据和算力限制, 想要实现真正智能的 AI Agents 缺乏必要的现实条件。
大模型、AI agent、RPA
大语言模型和 AI Agent 的区别在于 AI Agent 可以独立思考并做出行动,和 RPA 的区别在于它能够处理未知环境信息。
在AI领域,大语言模型与人的互动是基于一种称为“提示词”(prompt)的机制实现的。用户所提供的提示词的明确性和准确性对模型回答的质量具有直接影响。一些强大的AI工具也需要用户明确地描述任务需求,才能提供有效的解决方案。
AI智能体(Agent)只需为其设定一个目标,它便能够独立地进行思考和行动。AI智能体能够对目标任务进行详尽的拆解,制定出具体的执行步骤,依赖于外部反馈以及自身的智能处理能力,自主地生成执行任务所需的提示词(prompt),以实现预设目标。
RPA主要在既定规则和预设流程下执行任务,面对充满未知和不可预测的环境时,RPA的处理能力受限。AI智能体则能够通过与环境的互动,感知并适应新信息,进行相应的思考和行动调整,从而在复杂多变的环境中实现目标任务。
人类与人工智能(AI)之间的互动大体上可分为三种主要模式:- 嵌入式模式(Embedding Mode):大语言模型能够补充信息的空缺,执行一些子任务,例如信息摘要等。用户将对AI提供的信息进行筛选和整合,以完成最终的任务。
- 协同驾驶模式(Copilot Mode):AI能够根据用户定义的流程执行任务,如撰写文稿或根据特定需求进行编程。然而此模式对用户的指令(Prompt)提出了更高的要求。AI完成任务流程后,用户需要对结果进行审查和调整,以确保工作的正确性和有效性。
- 智能体模式(Agent Mode):用户需要为AI设定目标、定义角色,并提供完成任务所需的工具。通过更复杂的指令(Prompt),AI能够独立拆分任务、利用工具,并最终完成任务。用户的角色转变为设定目标、提供必要资源和监督任务的执行结果。
这三种模式展示了从用户主导到AI主导的连续统一体,每种模式都适用于不同的应用场景和需求。AI智能体的构建以大型语言模型(LLM)为核心,并通过四个关键模块来实现其功能: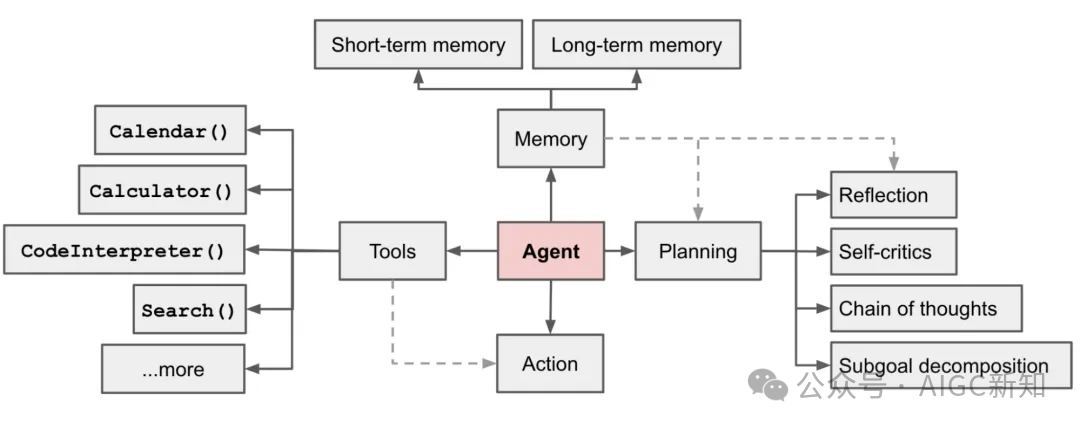
- 记忆模块:智能体如同人类一样具备记忆能力,能够保留所学知识和交互习惯。这种记忆机制使得智能体能够在处理相似任务时借鉴以往的经验,减少用户的重复性工作。
- 短期记忆负责处理即时的上下文信息,与我们日常和ChatGPT的互动类似;
- 长期记忆则存储知识和历史交互,使智能体能够提供基于丰富数据和经验的、更为专业和个性化的服务。
- 规划模块:智能体能够将复杂的任务分解为多个子目标,并逐一规划和解决。在完成每个任务后,智能体会进行自我反思,评估和总结执行过程中的问题,如内容的重复输出或在某个子目标上花费时间过长,并将这些经验教训纳入长期记忆中,以避免未来犯同样的错误。
- 工具模块:智能体能够利用各种工具来补充自己的能力,特别是通过调用外部应用程序接口(API),来扩展自己的功能。可以调用访问互联网的API来获取最新的信息。
- 行动模块:智能体将通过一系列有序的步骤来实施计划。它首先回顾以往的工作经验和记忆,然后规划出实现子目标的策略,并选择合适的工具来解决问题,最终将结果呈现给用户,并进行最后的反思。
这四个模块共同构成了智能体的框架,使其能够在自动化、个性化服务等方面发挥关键作用。构建一个高效的提示词(Prompt)是实现理想AI输出的关键,它应当遵循以下几个原则:1. 明确性:一个优质的提示词首先需要设定一个清晰的任务目标,包括预期的成果和效果。这为AI提供了一个明确的执行方向。2. 指导性:提示词应当提供具体的指引和限定条件,这可能包括给出一些示例或明确界定回答的范围,以引导AI模型生成恰当的输出。3. 简洁性:使用的语言应该直接而明确,避免冗长和复杂。一个清晰的提示词有助于AI更准确地把握用户的意图。4. 可迭代性:由于一次给出的提示词可能无法完全达到预期的效果,因此用户需要根据AI的反馈持续对提示词进行调整和优化,这是一个动态的迭代过程。通过遵循这些原则,用户可以更有效地与AI进行交流,从而获得更加准确和有用的回答。单一智能体与多重智能体各自拥有独特的优势,并适用于不同的专业领域。单一智能体的运作依赖于强化学习,其理论基础是马尔可夫决策过程。涉及到三个核心要素:状态集(S)、行动集(A)、奖励(R)。智能体的下一个状态和获得的奖励仅取决于它前一个动作,而与之前的历史状态无关。这种学习机制鼓励智能体通过尝试和错误来探索环境:当某个行为策略导致正面的奖励时,智能体将增加采取该策略的倾向。其最终目标是在特定环境中采取行动,以获取最大的累积奖励。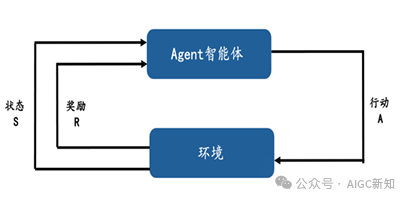
这种类型的智能体在许多领域都有应用,如在赛车游戏的AI训练中,智能体需要学习如何操作方向盘、油门和刹车等,通常可以通过DDPG、A3C、PPO等算法进行决策。同样,在像围棋这样的策略游戏中,AlphaGo智能体就是通过Q-Learning等算法来决策的。
多智能体系统涉及更复杂的互动,其中每个智能体的决策不仅受自己的行为影响,还受到系统中其他智能体行为的影响。在这种系统中,至少有两个智能体相互作用,它们可能处于合作或竞争的关系之中。这种模型被称为马尔科夫博弈,其中状态转移符合马尔可夫性质,而智能体之间的关系符合博弈论的原则。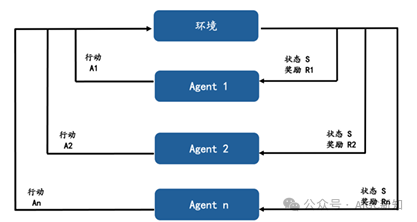
在多智能体模型中,每个智能体都试图找到最优策略,以确保在任何给定状态下都能获得最大的长期累积奖励。由于这种模型的复杂性和众多的干扰变量,目前市场上的商业化多重智能体产品还相对较少。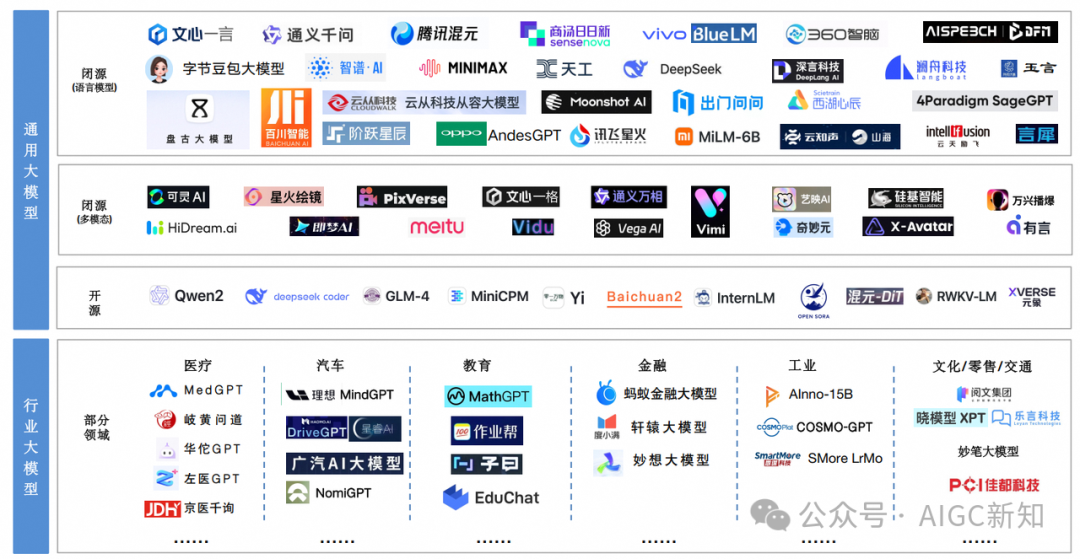
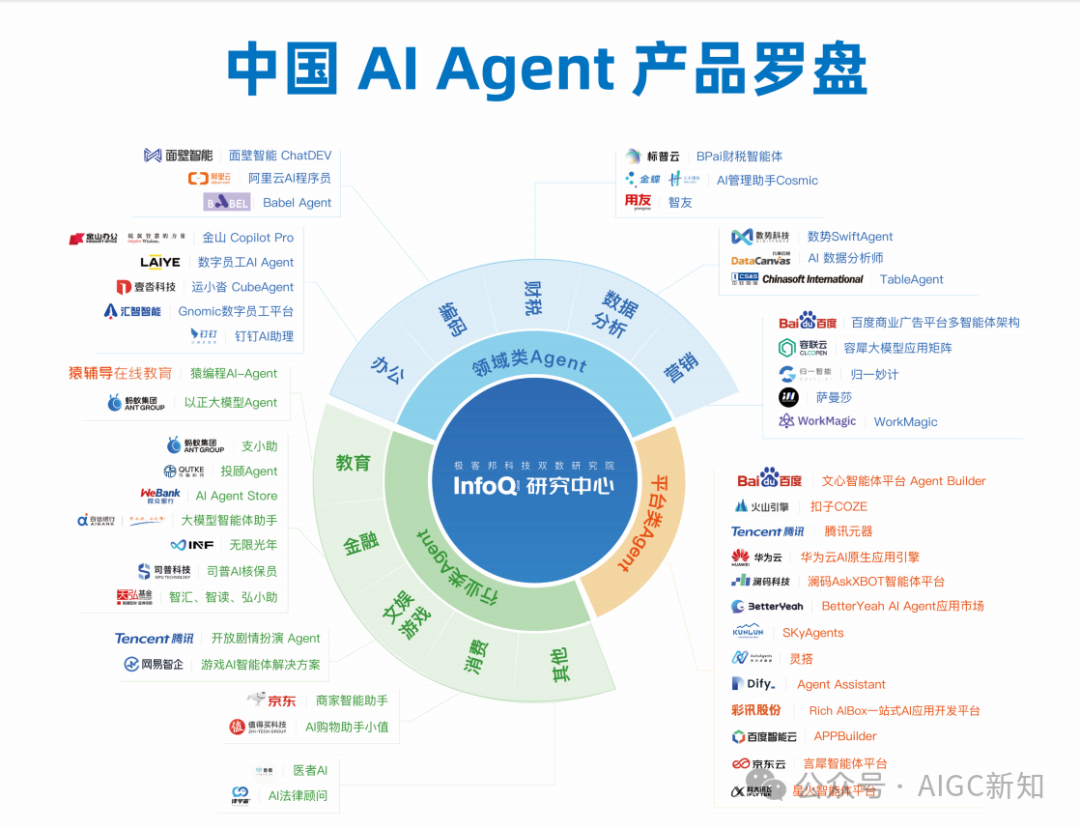
AI Agents地图


































 粤ICP备17114055号
粤ICP备17114055号