大模型没有壁垒,结合多年深耕的场景和数据处理技术才是王道。
由于大模型的出现,目前市面上AI+BI类的产品层出不穷,可谓百花齐放,为什么在B端市场如此火爆,先来看看GPT4是怎么说的:
近期我调研了一些厂商的AI+BI技术路线,汇总之后还是有比较惊喜的发现,在此分享出来。最终谁好谁差,是平分天下还是只留下头部玩家,交给市场来投票吧。回到技术分析,除了Text2Sql是大家公认的路径之外,还有哪些呢,我们一一来看。Text2Sql简单说,就是输入一句话,自动翻译为Sql代码,省去了我们写Sql查数的过程。
Text2Sql可能是基于大模型做数据分析时,最为流行的一种技术,但想做好并不容易,前不久我的一位好朋友在AiDD大会上的一个技术分享,他从模型基座、构造数据、领域训练、精准评测 4个部分详细介绍了Text2Sql整个系统的搭建过程,干货很多。 《ChatBI—NL2SQL领域大模型的研发及在数据分析产品中的落地》
《ChatBI—NL2SQL领域大模型的研发及在数据分析产品中的落地》
分析的终点是决策,也就是图中所说的“指导型”,是数据真正产生价值的落脚点。和Text2Sql的区别是,大模型不是将自然语言翻译为关系型数据库Sql语句,而是图数据库查询语句,比如常见的查询RDF的sparQL语句、NebulaGraph图数据库里的Cypher查询语言。一般使用这种方案的企业,底层一定是图数据库,比如,欧拉智能。这种方案的好处是能发挥图数据库的多跳推理优势,在遇到复杂推理问题时,比sql多表关联查询的性能要高很多。下面截取Neo4j公司在社交场景里做的传统关系型数据库和图数据库的查询性能对比,在一个包含100万人、每人有50个朋友的社交网络里找最大深度为5的朋友。可以明显看出图数据的查询性能优势。https://tech.meituan.com/2021/04/01/nebula-graph-practice-in-meituan.html把自然语言翻译为查询语句功能过于单调,面对复杂的分析场景怎么办呢,干脆“聘请”一位不仅会写Sql,还会写Python的数据分析师,随时随地通过编写代码来满足客户的需求。举两个例子,一个是开源社区作品Data-Copilot;一个是商业产品,九章云极的TableAgent。GitHub地址:https://github.com/zwq2018/Data-Copilot《Data-Copilot: Bridging Billions of Data and Humans with Autonomous Workflow》
Data-Copilot主要分为两个阶段,第一个阶段是离线过程,通过self-request来构建大量接口,也就是预先生产了大量工具(例如图形渲染、数据查询、排序、数值计算等等),供在线过程的调用;第二个阶段是类似autoGPT的任务规划和工具调用。整体流程如下:
《Data-Copilot: Bridging Billions of Data and Humans with Autonomous Workflow》九章云极前段时间刚刚发布了TableAgent数据分析智能体,在官网可以适用Demo。个人感觉和Data-Copilot非常像,不多做介绍,感兴趣可以上手体验,我截一张自己尝试的过程图,供参考: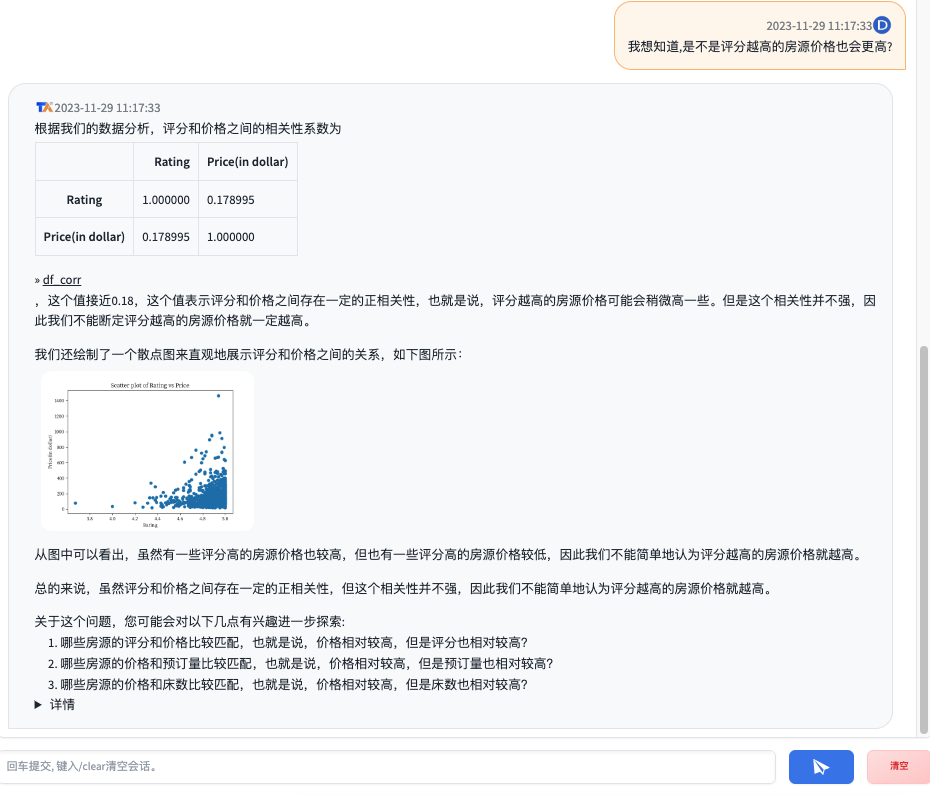
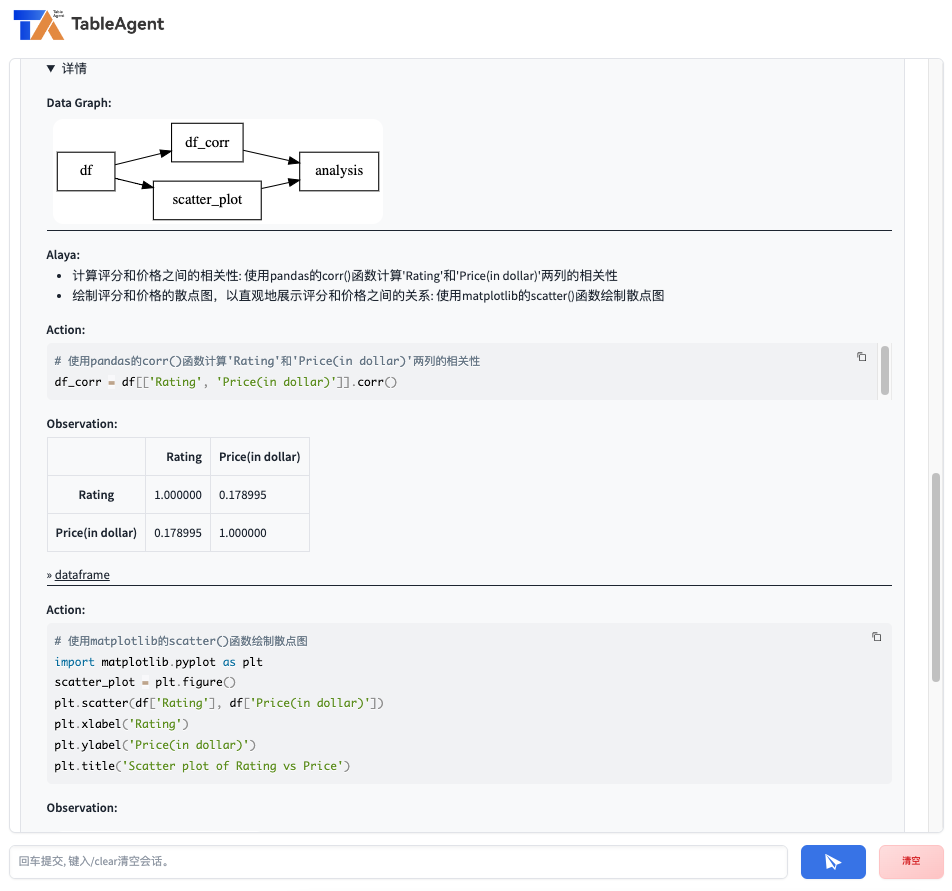
它的优点是能够将Agent思考过程、数据流图、代码编写过程清晰地呈现出来。整体除了界面还比较简陋之外,感觉最大的问题是数据源只能通过上传Excel来实现,猜测内部只能对Python的Dataframe对象来编程,如果遇到企业级数据库对接,这套流程可能不适合。前不久“爱分析”主办的《大模型+数据分析》主题网络研讨会 也明确提出过这种方案:
这种技术方案适合于已经在指标层有过一定技术积累的厂商,因为这一层要解决语义统一(什么叫“销售额”,口径怎么算的)、体系构建(销售额如何拆解、如何关联其他指标)、指标管理(今天张三建了一个指标,明天李四又建了一个)、查询优化(一个查询需求有多种实现路径,哪种最快最好)等一系列基础性问题,但这些功能往往散落在系统各处,大模型的出现将各类基础能力有机链接到一起并主动呈现在业务人员的面前。数据虚拟化不是AI/BI领域特有的产品,而是在大模型出现之前,为缓解业务快速发展和数据有序增长二者不平衡问题的一种技术手段,这里引用Aloudata技术团队对“数据虚拟化”的讲解:虚拟化是一种设计思路,它尽可能对使用者屏蔽物理运转细节,将原先需要使用者给出的指令,由机器通过恰当的规则和算法进行自动化实现。虚拟化本质就是在绝大部分场景中让用户可以按业务本身的需求去操作,而不需要为物理引擎的特性去做额外的优化操作。
Aloudata技术团队《数据无序增长的终结者-数据模型虚拟化》数据虚拟化存在于物理数据层和用户接口层的中间,所以沿着这个思路,大模型的位置也就自然落在了用户接口层和虚拟层的中间,虚拟层为上层的业务屏蔽掉了底层表的过多的细节。那么“数据虚拟化”和“指标平台”是什么关系呢,我觉得两者不冲突,“指标平台”更多地解决业务侧问题,“数据虚拟化”专注解决底层表无序增长问题,两者可以做个融合,诞生第六个技术方案。大模型的出现,都将各数据智能厂商原有的核心竞争力进一步放大和增强,所以在开头提到,仅依靠大模型本身,无法形成壁垒,结合多年深耕的场景和数据处理技术才是王道。每种方法都有各自的优势和适用场景,而大模型的出现好像改变了很多东西,又好像什么都没改变。就像在这个突然降温的季节,外界的温度似乎在提醒我们自然界的沉默与恒定,万物虽在变化,但有些东西永远不会改变。在技术的世界里,一股暖流正在悄然升起,它是人类智慧的火花,在自然的包容中闪耀,和宇宙长河亘古定律和谐共生。

































 粤ICP备17114055号
粤ICP备17114055号