导读 在当今数据驱动的业界,BI(商业智能)产品在企业决策支持中发挥着越来越重要的作用。本次分享将着重探讨 BI 产品的演化历程、当前面临的挑战,以及大模型实践在数据分析中的前瞻性探索。
1. BI 数据产品的演化之路
2. 精细化数据分析与数据产品困境
3. 突破困境:ABI 数据产品的应对策略
4. ⼤模型崛起:数据分析的新篇章
5. ⼤模型数据应⽤实践
6. 问答环节
分享嘉宾|黄聪飞 京东 数据产品架构师
编辑整理|蔡海鑫
内容校对|李瑶
出品社区|DataFun
BI 主要指商业智能,源自 DSS(决策支持系统)。DSS 是一套辅助用户通过人机交互进行结构化、半结构化数据分析决策的系统,核心在于数据库、知识库和模型库的串联,实现结构化的角色,类似于决策树的形式。

BI 产品首次出现,主要应用于中小型企业,面临数据孤岛问题和报告生成时间较长的挑战。数据技术发展,数据仓库、OLAP、ETL 技术成熟,但数据工作由产研部门主导,技术门槛高。BI 2.0 时期,提升了 BI 的开发效率和实时处理协作能力,用户自主性增强,但面临数据量爆炸性增长的挑战。BI 3.0 时期,智能分析崛起,BI 演变为 ABI(分析与商业智能),头部公司包括 PowerBI 和 Tableau,生成式 AI(GBI)结合大语言模型开始流行。
精细化数据分析与数据产品困境
精细化运营指的是基于成熟工具技术,通过深入分析和理解数据来提高运营决策效率和效果的管理模式。而数据驱动形成的前提是建立高效的数据决策和驱动体系。
在多渠道和多平台的电商环境中,数据的收集和整合是⼀个巨⼤的挑战。需要解决数据孤岛问题,实现整合及⼝径统⼀。市场变化快速,需要实时或近实时的数据分析来⽀持运营决策。处理和分析⼤量实时数据是对技术和资源的巨大挑战。当前的精细化运营需要快速响应分析课题,对运营表现给出解答,再通过有效的执⾏来实现运营优化和改进。数据分析如何触达业务表现也是一大挑战。市场拥有众多不同的品类(万级别),每个品类都有其独特的运营和市场特性。不同的品类需要不同的分析⽅法和指标。不同消费者有着不同的购物决策方式,不同的业务用户也有着不同的分析方法。BI 产品需要通过丰富的自定义能力来匹配不同用户群体,允许用户通过多种数据角度的进行运营。电商市场的竞争激烈,市场环境也在不断变化。现在市场上有多种销售模式和细分市场,通过不断地对市场进⾏快速分析,才能找到⾃身的竞争优势与劣势。2. 数据产品困境
上述挑战使数据产品面临着船小少载⼈、船大难掉头的困境。
典型数据产品,如看板式产品,具有标准化和易用性优势,⽽且基于其固定性的特点,可针对大数据量、实时场景实⾏针对性的解决⽅案。传统 BI 提供⾃定义的数据看板,在灵活性和个性化上有⽐较大的优势。⽤户可以⾃⾏接⼊数据源,进⾏数据处理和分析。
但面临精细化运营的需求,则有着很多难以解决的问题。
当出现新业务和大型业务调整时,其改动牵扯较⼴,成本较大。
因为需要时间来调整和适应,往往难以跟上业务的变化速度。⽤户需要学习产品功能,并具备⼀定的数据能⼒,学习成本高。
像准备数据源和多源建模的工作,对于⼀般⽤户来说,难以⾃⾏完成。
灵活性是不够的,业务调整⼀个策略,可能就需要换多个视⻆分析,看板式数据产品很难满⾜。⽤户⾃⾏搭建看板和数据时,容易出现⼝径差异,影响分析结果。
突破困境:ABI 数据产品的应对策略
1. 数据产品定位
京东数据产品的定位是人人都能上⼿的数据⼯具。主要包括两个方向:数据效率提升和数据民主化。

将数据口径分成标准和非标准两类,标准口径由零售级的经分团队制定,非标准的口径由用户自建,多平台权限打通,形成个人数据资产。提供轻量级可视化建模的能力,用户通过简单交互即可实现多源建模和自助构建数据模型。业务数据全面实时化,在自助分析场景下,也能够支持业务按需即时分析和调整。
数据民主化,旨在提升数据分析普适性,让人人都能分析,会分析,人人都是分析师,以数据工具的便捷性促成数据驱动。借鉴内部一体化分析平台的产品经验,将其作为用户学习、使用的范式,降低学习成本。同时,剥离工作流中的依赖关系,使用户能够独立完成整个分析和应用流程,不再依赖产研或分析师的介入。在合规的前提下,支持用户动态分享结果。与传统的静态数据分享方式不同,分享的结果是一个动态的入口,用户可以通过办公应用分享给老板和同事,接收人可以在此基础上,进行进一步的分析和探索,从而提高效率。借助大模型进行 AI 分析,提升用户的分析能力,具体的辅助方式将在后文详细说明。2. 解决方案:现代数据栈结构下的生成式 BI 工具
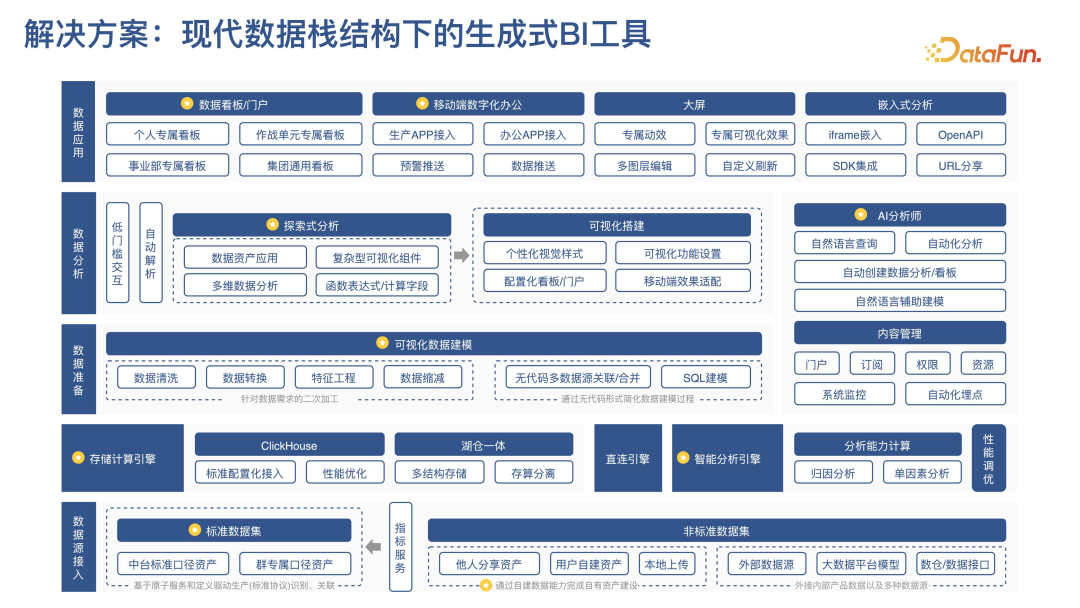
该解决方案构建了一个现代数据栈结构下的生成式 BI 工具。该解决方案参考了现有数据栈的定义结构,并结合前沿技术,以整体视角串联形成生成式 BI 工具。
其包含四个主要部分:数据接入、数据准备、数据分析、数据应用。数据可分为标准数据和非标准数据两类,依据口径要求区分。中台的指标服务提供封装口径的能力,使用户能够简便调用。同时提供维度关联能力,统一维度标准值,支持各生产方使用。用户也可以自行接入大数据平台的数据表。使用 CK 和湖仓一体,通过配置方式将口径注册到指标服务,实现标准化流入。以直查数据湖配合服务加速优化的方式,解决自由分析实时数据的性能问题。整合中台的统计分析能力,支持业务调用。根据查询场景进行智能路由,根据条件选择高性能的接口服务、查询引擎等。包括可视化建模、数据加工、特征工程,以及维度关联和 SQL 建模。降低用户的学习成本,通过规范的交互路径,并对用户选择的内容进行自动解析实现。提供多维数据钻取、联动分析和表达式计算字段能力。引入复杂报表类的可视化组件,能更灵活地呈现业务分析结果。
可视化搭建,支持视觉样式自定义和看板门户建设。通过大语言模型能力,支持自然语言创建看板和辅助建模。分为看板门户搭建、数字办公优化、大屏场景和嵌入式分析四大块。
大模型崛起:数据分析的新篇章

大语言模型是一种特殊的人工智能,通过大量文本训练,能够理解和生成原创内容。与先前的语言模型相比,主要区别在于规模和数据量。截至 2023 年,市场上主要有 OpenAI 的 GPT-4 和 GPT-3.5、Google的 Bard、Facebook 的 Llama、Claude 等,还有专为中文设计的 ChatGLM 和百川。
用户可根据场景选择适用的模型,没有一个模型能完成所有任务,选择应基于任务需求。例如,Claude 支持 100K,可单次处理大量文本。GPT-4 具有较强的逻辑推理能力,适用于需要按步骤推理的任务。
- 自然语言处理和理解,帮助用户更快地理解数据内容,处理非结构化数据如评价和媒体信息,并推断具体内容或主题。
- 智能推理和预测,能根据数据表现推理出差异、销售趋势和需关注的问题。
- 代码生成和自动化,大语言模型可通过自然语言转换 Python 和 R,降低技术门槛。
- 新的交互形式,使用语言交互方式降低使用门槛,无需学习多功能的使用,只需清晰表达问题即可。
大模型数据应用实践

接下来介绍我们内部的一个应用 ChatBI,它旨在通过对话方式完成 BI 工作,定位为专属于用户的 AI 数据分析师,基于 GPT 实现。用户可通过自然语言对话解决复杂的数据问题,其使用体验就像与真实数据分析师合作一样。
- 信息获取难:新生业务定义、专有名词和内部知识难以获取。
- 数据分析难:欠缺数据分析思路及分析能力,一线业务很少具备代码能力。
解决方案为 GPT 大语言模型+公/私域知识库+数据分析应用扩展。
通过大语言模型做入口,自然语言对话即查询、分析,可有效降低使用门槛。另外,将沉淀的业务信息通过外挂知识库的形式,提供给大模型,从而获得更加准确的回答。集成中台的应用能力,通过 LangChain 的 agent 能力调用对应的数据工具去解答问题。
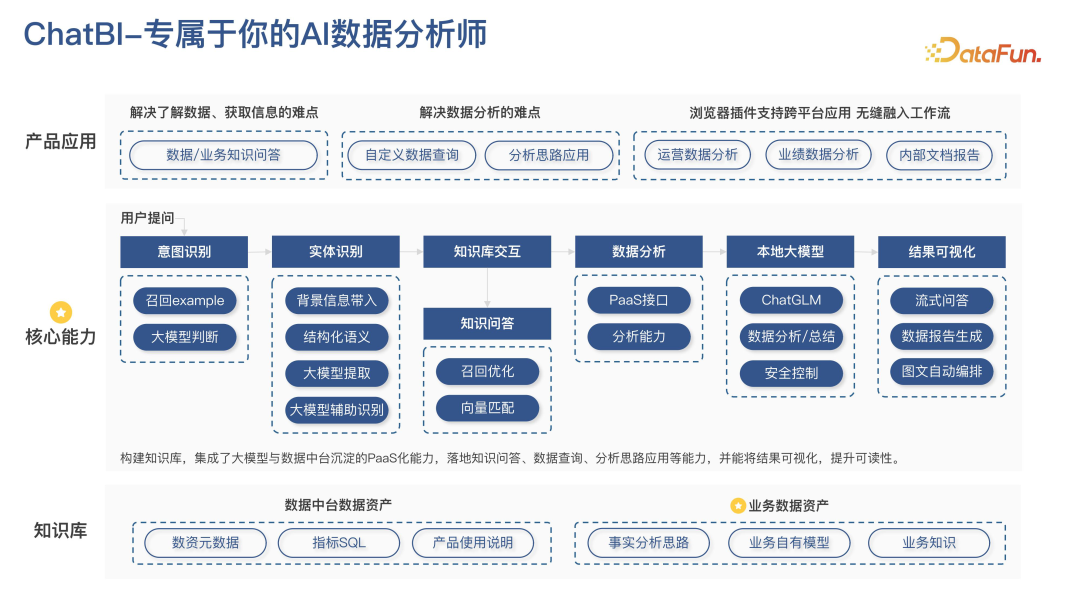
知识库主要使用 Langchain 进行大语言模型的开发。知识库分为两部分,一部分是数据中台的数据资产,包括数据的元数据、指标 SQL 和产品使用说明;另一部分是业务资产,包括业务自有模型和业务知识。
重点是业务的事实分析思路,分析师有能力解决很多业务问题,但是其能力很难沉淀下来进行复用,很难把每个分析师的思路都做成产品,也很难把分析思路直接交给采销或者一线业务。而大语言模型让这些变为了可能。用户提问后,首先进行意图识别,识别用户是否想要获取知识、进行分析,或者仅仅是聊天。通过实体识别获取用户提问中的实体信息,比如时间、指标、维度等,同时会通过用户背景信息,包括权限、部门等,去做辅助判断。如果意图是知识问答,则会与知识库进行交互,并通过嵌入优化来提升问答效率。对于数据分析场景,调用接口能力并将数据传入本地大模型进行安全的数据分析和总结,最后形成可视化结果。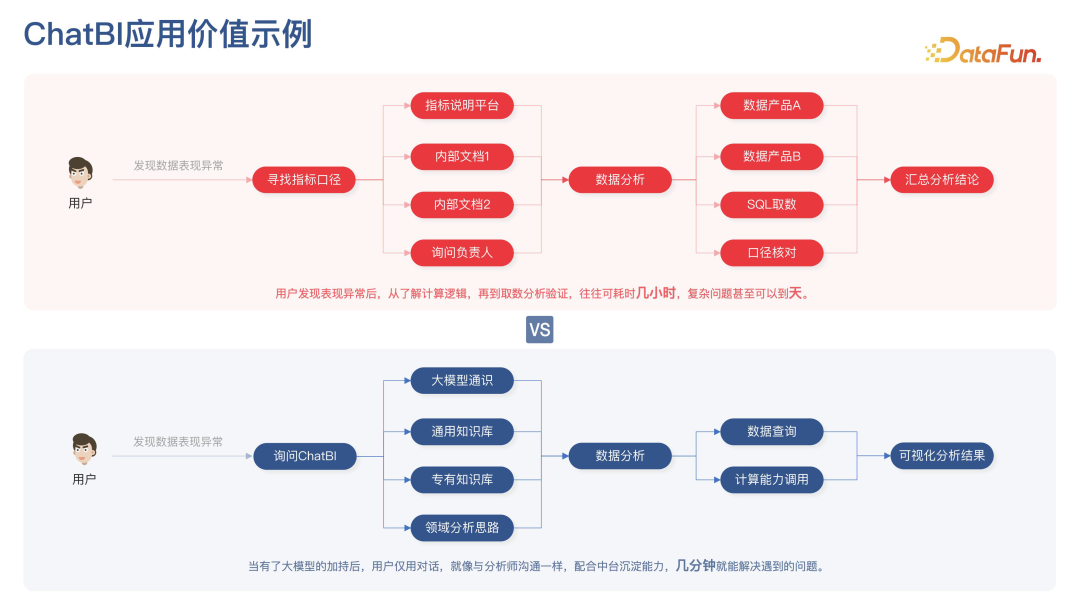
在使用 ChatBI 之前,用户发现数据表现异常,需要寻找指标口径,可能涉及多个平台、多个文档,找到后再进行数据分析,可能又会涉及多个产品,以及 SQL 取数,进行口径核对,最后汇总分析结论。整个过程可能会花费数小时甚至数天。
如果使用 ChatBI,用户在 ChatBI 中与大模型对话,大模型结合各种能力,通过通识知识库和编译思路筛选总结,调用数据接口和分析能力进行自动数据分析,最后生成可视化结果。有了大模型的加持,用户只需要以对话的形式,几分钟即可解决问题。
问答环节
A1:可视化平台注重可视化能力,例如低代码平台允许直接调用组件套用数据,而数据分析平台专注于分析和结果洞察。
A2:本地大模型是 ChatGLM2,CNCC2023 上现已有 ChatGLM3,后续可以更多关注大模型的迭代,新的模型会具有更强的或服务特定领域的能力。
A3:大模型很难做到百分百准确,首先需要丰富、沉淀更多的分析思路,覆盖更多的场景,再通过引导、背景信息读取去进行增强匹配,最后要为用户提供一定的调整能力,以此来解决匹配不准确的问题。
A4:涉及统一口径问题的数据,是通过指标服务实现的,而指标服务确保了口径的一致性。严格口径下,使用 SQL 或 Python 直接查询数据模型,会比较容易出现口径问题。
A5:ChatBI 分为两部分,一部分使用 OpenAI 接口,另一部分使用本地大模型,对部分强场景进行了微调。
Q6:流转角度数据接入准备分析,全流程端到端的分析?
A6:数据接入包括生产数据清洗、关联维表等步骤,随后通过可视化方式展示数据,进行同环比、对比和多维度分析,最终生成可视化效果。
Q7:ABI 类似 Tableau、Quick
BI?
A7:是的,因为 Tableau 和 Quick BI 本身就是 ABI,它们在数据工作流上有很多相似之处,可视为同一类产品。
A8:分析结果的准确度,属于长期课题,首先作为基底的分析思路要保证质量,再通过自评体系和用户反馈机制去进行不断地优化。

































 粤ICP备17114055号
粤ICP备17114055号