导读 本文将分享小米在 Agent 技术应用方面的一些工作。
1. Agent 简介
2. 技术框架
3. 未来方向
Agent 简介
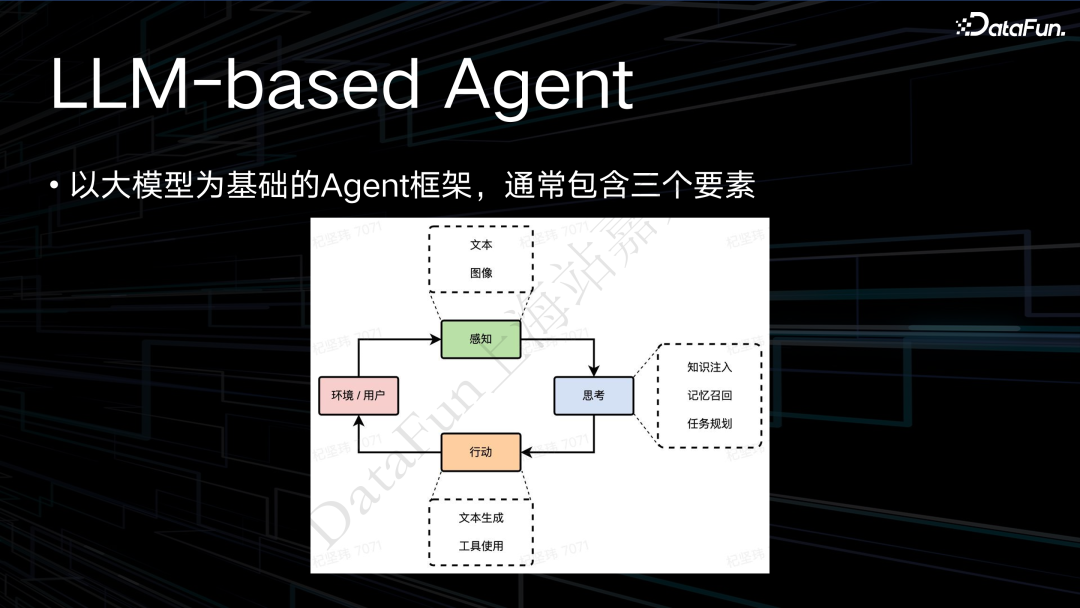
Agent 主要包括三个环节,即感知、思考和行动,所有 Agent 范式都大致一样。对于小米语音助手而言,环境变量主要来自于手机系统、家庭设备以及小米汽车的一些车载信息。来自用户的信息主要是小爱每天接收到的来自用户的各种查询请求。
在感知层,以前小爱只有文本的输入,随着大模型、多模态的发展,我们也在开展各种多模态输入的感知实验。比如提问小爱同学前面是什么车,这就利用到了图像的感知。在思考阶段,会有知识的注入,以及记忆的召回,例如前一轮看到了一些什么事情,在这一轮可能会用上,以及任务的规划。
在行动阶段,传统大模型的输出就是一段文本。这是在结果满足时最普遍的一种用法,将收集到的信息做一个整理,生成一个更智能的回复返回给用户。另外,我们也做了一些工具调用的实验,通过 plugin 的技术,去完成更复杂的任务,如帮用户去购买火车票,或制定出行计划,又比如在行车路上搜索沿途的宾馆,并按用户需求进行排序等等。
以上就是我们现在在语音助手中应用 Agent 的一些工作。
2. Agent for AI Assistant

我们的语音助手是一个和系统、环境结合很紧密的偏业务型的工程性的智能体。而模型是偏策略、偏算法的。将大模型和系统、环境去做一个紧密的融合是我们需要完成的第一个工作。最直观的做法就是把我们收集到的各种环境信息、系统状态,都作为 prompt 的一部分进行注入。但这对大模型的 context
learning 能力是一个较大的考验。所以我们也在思考,与语音助手相关的领域知识,是应该通过 RAG 的方式去做注入,还是通过二次训练的方式让大模型更深层次地理解领域中的一些知识,这是我们思考的第一个问题。
小爱是一款已经面世多年的产品,有非常多的历史积累,有自己的一套架构。我们肯定不希望把现有的这一套架构推翻,让用户的查询进来以后直接接入大模型的框架,而是希望能复用语音助手现有的一些 NLP 的能力,让大模型在其中去解决一些原有的传统 NLP 无法解决的问题,这样才能带给用户更好的体验。
传统的语音助手下面都会分不同的垂域,如天气、信息工具等等。以前要展开一些跨垂域理解,都是比较难的一些任务,用户如果直接问今天上海的天气是什么,这个其实大多数的语音助手都很好解决。但如果用户问的今天上海的天气适合穿什么样的衣服,可能就需要更多的策略的融入,需要去先查询到天气,然后根据天气的状态,再结合一些常识的背景信息,去做更复杂的计算。这种跨垂域的应用,在传统 NLP 中不太容易去解决,这也是我们希望引入 Agent 去处理的一些问题。
技术框架
接下来介绍我们基于上述问题和思考所构建的技术框架。
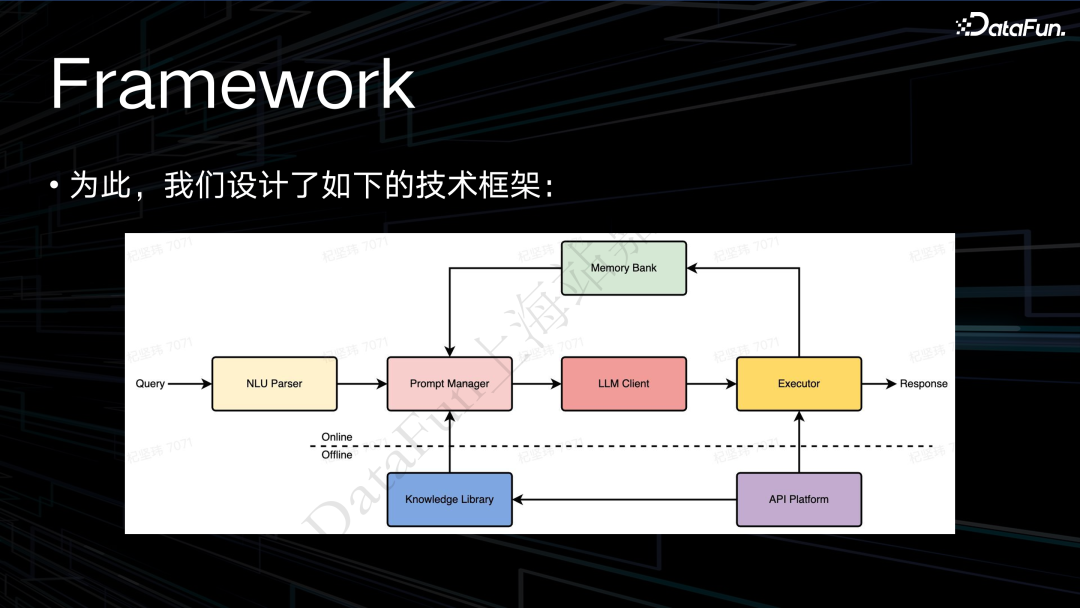
最前面的 NLU Parser 是我们的语音助手中比较特殊的一个模块,在后面还会做详细介绍。接下来是构造 prompt,接着去请求大模型。然后会有一个执行器,执行器所能执行的各种功能来自于下面的 API Platform。执行器执行的结果,会存到 memory bank 中。后续会从记忆池中召回有用的信息,来继续去做下一轮任务的规划。这就是整体的系统框架。
下面就来介绍一下其中独特的模块 NLU
Parser。
2. NLU Parse
(1)Agent 项目在冷启动时缺乏场景信息,大多难以完成规划
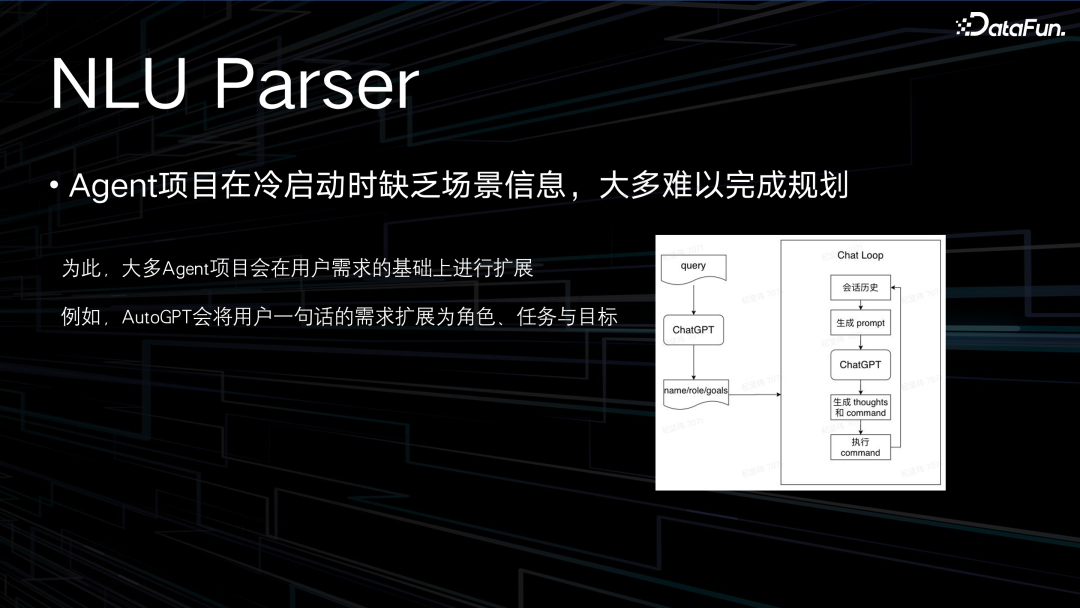
我们在调研其它 Agent 产品时观察到,在完全冷启动的情况下效果通常不是很理想。我们将冷启动定义为,调用一个大模型时,给它布置一个任务,让它直接输出我需要做的事情,产生一段任务规划。因为在做 prompt 工程时很重要的一点就是要给大模型介绍一个背景,甚至要给它安插一个人设,这样它才能帮你去很好地完成这个业务。
例如 AutoGPT 在完成一个任务时,就会首先要求你告诉它现在的任务是什么,你给它的角色是什么,以及你给它定了哪些目标,带着这些信息去做接下来的任务规划和任务执行,我们把这些称之为启动的场景信息。在 AutoGPT 中会让用户去手动填,如果没有手动填,它会拿着你的问题去请求 ChatGPT,让 ChatGPT 去输出信息。
(2)语音助手本身的 NLU 能力可以作为 Prompt 构建提供依据

在语音助手里面,在之前的传统 NLU 理解里面,这些 prompt 信息是比较容易获取的。因为传统语音助手本来在做的就是意图分类和槽位抽取,所以传统的语音助手可能不擅长于规划任务,但比较擅长去找到一个 query 中的主题信息,所以我们可以快速地用一些轻量级的模型去找到用户 query 可能包含的意图,以及里面包含的槽位。
在传统的 NLU 的理解下,需要去对这些意图或者槽位做一些结果的融合或实体的连接。但是现在可以让大模型来代替我们去做这种复杂的工作。我们只需要识别出用户意图,然后通过运营同学配置的一些模板,即可作为场景启动的注入信息。
(3)基于更丰富的 Prompt 模版,模型规划更符合产品需要

我们发现仅仅给定这样一段 prompt,希望大模型来将用户的需求拆解成各种待执行的问题,输出一个任务列表,很多时候大模型输出的结果可能和我们产品的需求是不太相匹配的。当用户有更丰富的需求时,也难以及时响应。因此我们会添加一个场景模板的概念。根据 NLU 理解的结果,再去召回运营预先配置的模板,从而让大模型输出的结果在一个可控的范围内。小爱作为一个面向用户的产品,我们希望它输出的内容是可控的,才能搭配上我们未来的一些产品的策略。
在这个例子中当我给定了场景模板后,它输出的任务计划会更贴合我们在产品设计之初的需求。3. Prompt Manager
(1)综合语义理解、知识注入、记忆召回,构建 Prompt
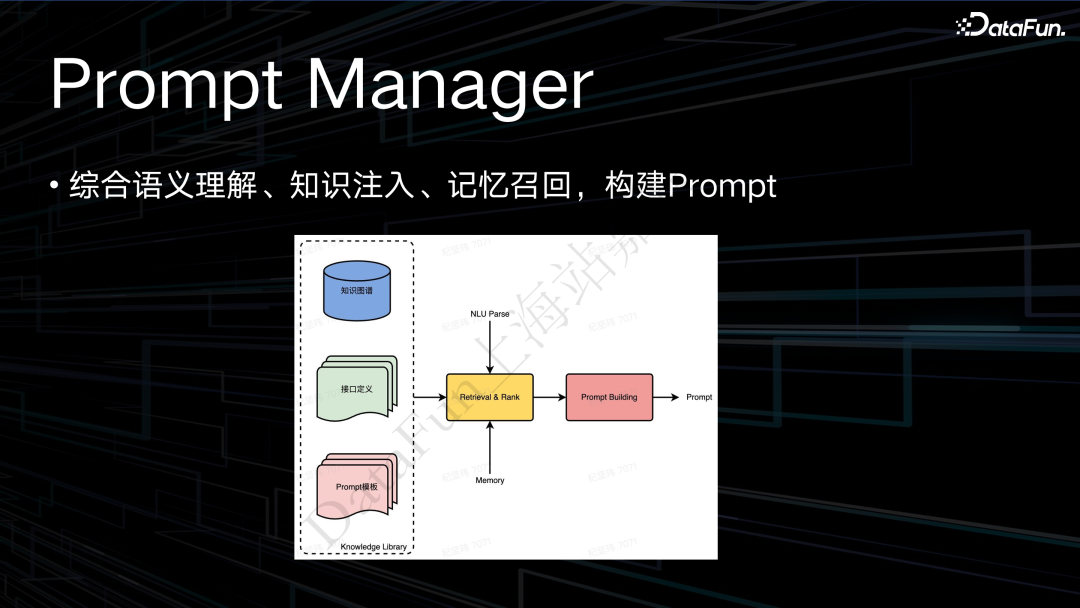
在整个系统中最主要的模块是 Prompt Manager,其主要作用是从我们已经建设的知识图谱、定义好的接口或者 plugin,以及预先定义好的一些 prompt 的模板中,去做一个召回和排序。通过 NLU Parser 得到结果,从中选择有用的信息来构建 prompt。在此过程中比较复杂的就是 retrieval 的工作。
由于很多信息是异构的,如知识图谱、接口的定义和 prompt 可能采用不同的数据形式,我们会做一个多路的召回。对于上述信息,会人为做一些标签,通过这些标签进行召回。基于多路召回,根据对每一条请求预理解的标签,以及这个 query 本身的 embedding,可以从模板库和接口里面去召回我们希望的信息,然后基于一个策略去进行排序,再进行注入。

我们会为各种场景去设置状态的模板和运营模板。这里主要介绍状态模板。将 Agent 的整个运作过程切分成不同的状态,比如制定一个可执行的计划,还有工具的选择、反思、总结等等。如果让大模型一次来完成业务,通常会不太可控,可能出现很多杜撰的问题。因此通过切分,每一个模型在这个场景下只完成一个规定的任务,从而保证整体流程的稳定性。
(3)接口定义,采用 JSON Schema 来注入 Plugin

对于接口定义,我们也尝试过比较多的方法,有直接注入函数名和一段简单的介绍,或者是函数名加上它的一些注释信息。最终选择 Json 的形式去注入 plugin,这与模型预训练和做对齐时所使用的一些预设格式是息息相关的。因为 Jason 本身是一个比较常见的格式,因此效果会比较好,但其缺点是比较消耗 token。

在历史注入方面,我们一开始是把上一轮模型输出的内容直接原封不动地注入到下一轮的 prompt 中。在这种情况下,我们发现模型非常容易重复生成,即直接 copy round
0 的内容当作本轮的生成。卡伊的 agent 有提到,像 ChatGPT 模型会倾向于在明明已经知道这个信息的情况下,还会再次尝试去获取这个信息,出现这种重复生成的问题。
因此我们对历史注入进行了改造,会把它刚才得到的这一段结果做一个总结,把总结的内容当作上一轮已经了解到的情况。还有一个 memory bank 的操作,总之就是不让它在上文中直接看到之前那一轮输出的结果。这样生成就会更加的稳定,而不是倾向于直接从输入的信息中去 copy 一段内容出来。

对于输出,我们希望对结果可以轻松地进行解析。输出格式也是采用 Json 格式。并且参考了现在业界常用的 react 的思想,让每一轮输出时都去输出它当前的思考以及它选择的工具和参数。基于输出结果,下游的执行器在拿到这个结果之后,可以直接调用已经注册的 plugin,操作对应的动作。
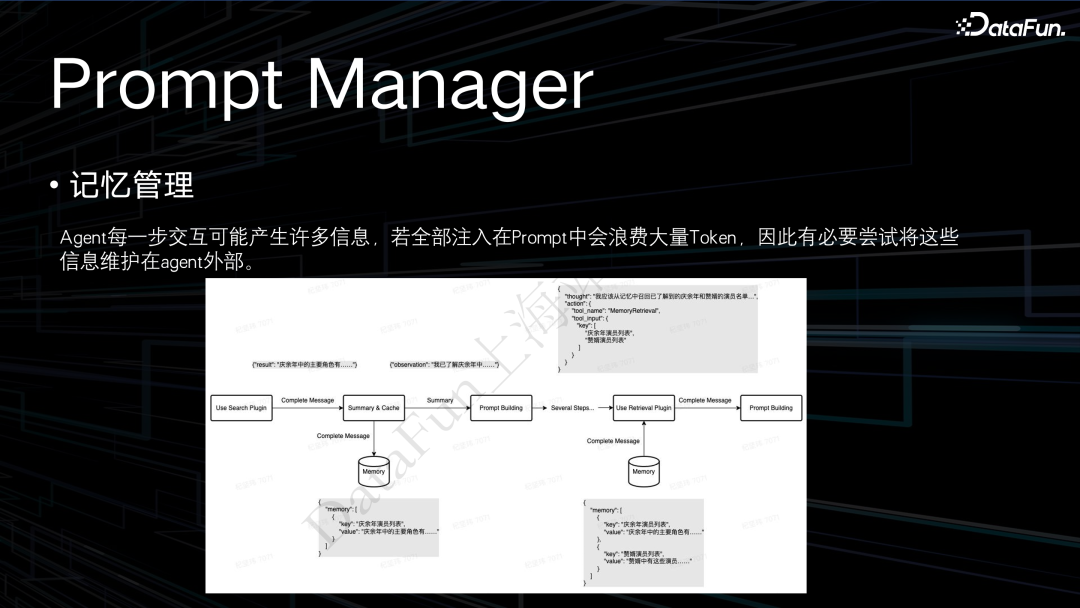
再来介绍一下前面提到的记忆管理的问题。例如 query 是想知道《庆余年》和《赘婿》两个电视剧中重复的演员都有谁。在这个场景中,会先去查询《庆余年》中的演员列表,再去查询《赘婿》的演员列表,然后做一个对比。我们之前的发现是,它在查询了《庆余年》的演员列表之后,如果把它持续地装在 prompt 中,是非常消耗 token 的,还会导致重复生成或者一些不稳定情况的出现。所以我们进行了改进,现在查询之后,会有一个总结的动作,之后把总结的内容当作上轮的查询结果注入到 prompt 中,然后告诉它上轮已经知道了这些信息,这些信息以一个约定的 key 存储在记忆库中。我们又设立了一个新的 plugin,名为 retrieval。这个 retrieval plugin 的描述就是已知在记忆库中有哪些信息是以前知道的,可以调用这个 retrieval plugin 从记忆库中召回你想知道的信息。
在这种设计下,可以简化历史中的注入,同时在最后一轮它准备去做信息的总结时,就会使用 retriever plugin 从 memory bank 中去召回我们需要的信息,再执行下一轮的对比操作。

总结一下前面介绍的各个模块,我们完整的 prompt 如上图所示。包含了以下几个部分:System Prompt(代表当前希望 Agent 做的事情);Scenario Prompt(为了保证生成稳定性所提供的场景信息,即预理解的结果);User Request;History(经过总结的历史);Output Format(输出的格式)。以上就是完整的 prompt。
4. Executor & API
Platform
(1)Executor 主要负责解析大模型输出,并处理异常情况

执行器的部分,在拿到大模型的生成结果以后,期望是 Json 的输出格式,会尝试去解析,有一个后处理的校验环节,对输出的 Json 去做一些归一化的处理。因为大模型不可避免地会存在一些杜撰的问题。另外还有日期等信息并不适合大模型直接去理解。如 query 可能是说我明天要去武汉,但是在我提供给 API 接口时,需要对这个信息进行格式化处理,大模型输出的可能就是明天,但是在后处理归一化校验中会把它解析成我们与 API 约定的一个标准的时间格式。
(2)API Platform 需要隔离大模型与具体业务

API Platform,有些系统中定义为 Plugin Library。定义时有两个主要的方法,一个是根据 plugin 的名字和一个参数列表,直接来调用已注册的 plugin;另外一个就是通过 get_description 的方法去获取已定义 plugin 的一些注释,这些注释可能会用于直接生成注入给 prompt 里面的 plugin 的描述。注册也非常简单,会通过预定义的接口来实例化一些 plugin。后续要添加其它这样的工具,就直接继承我们设计好的一个基类,按照定义的接口去实现其中的方法。Plugin 定义和 Agent 整个流程是相互隔离的,只要注册了一个新的方法,大模型就可以直接感知到,这是我们设计 API Platform 的核心思想。
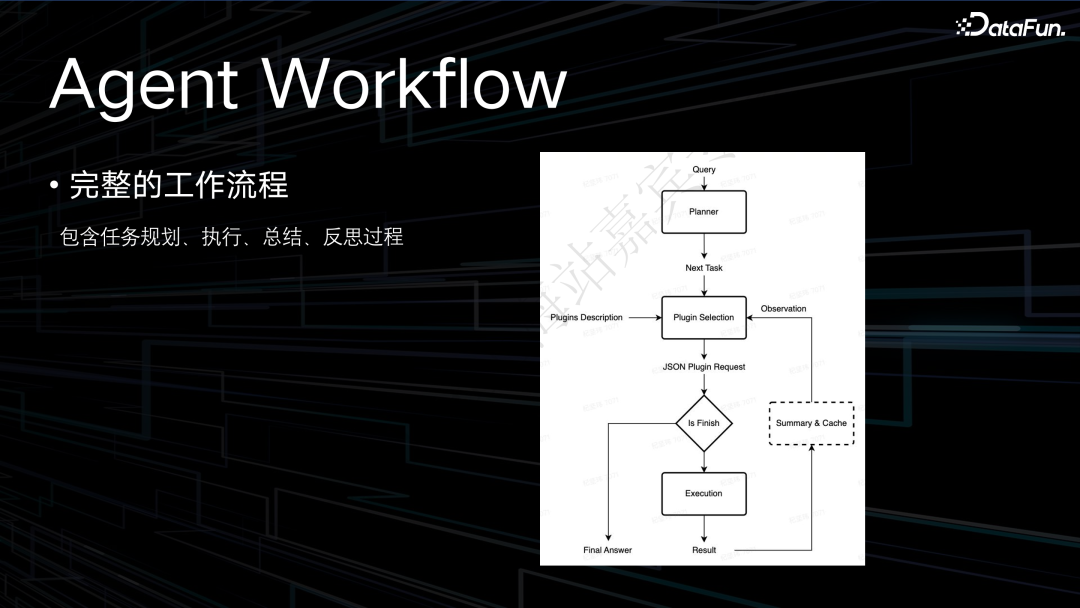
上图中展示了 Agent Workflow 完整的工作流程。当收到一个 query 以后,(此处省略了 NLU Parser 这一步)首先会由一个 planner 去输出待执行的任务,这些待执行的任务会依次经过工具的选择,判断它现在是否是 finish 的状态,如果是 finish 就会直接返回最终的结果,如果不是就会去执行器做一些真实的与接口之间的交互,得到交互结果后进行总结和缓存,再把这个结果信息返回给规划的流程。依此往复,帮助用户解决一个实际的需求。
接下来介绍我们对 Agent 整体框架之外的一些优化工作。一个工作是把整个大模型完成任务规划、工具选择、信息总结等任务拆成多个 Agent,一起来协作完成这件事情。我们在做了第一版 demo 后,在公司内部进行了内测,效果比较好,但等待时间过久。因为之前调用的都是千亿级的模型,推理速度较慢,尤其是输出的 Json 格式的执行函数,需要反复请求大模型才能得到最终的结果。
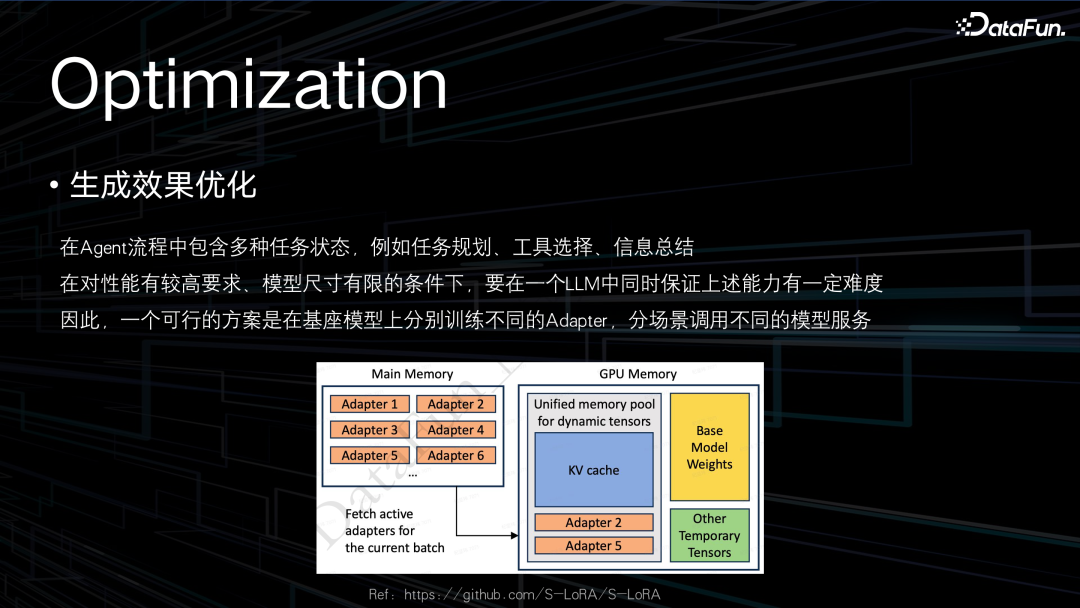
为了提高速度,我们当时的一个朴素的想法就是能否用更小的模型来完成这件事情。我们尝试了百亿级的模型,发现要在模型尺寸有限的条件下去完成任务规划、工具选择、信息总结这些事情,会有一种此消彼长的情况,在做指令微调时也不那么容易平衡各个数据的比例。因此我们又尝试利用 Lora Adapter 的方法,去训练多个子模型,让每一个专家模型来完成固定的一个任务。这样性能上得到了提升,同时也保证了整体流程的稳定性。
为了节约部署服务的计算资源,我们会采用一个服务中挂载多个 Lora Adapter 的方式去部署服务,这样虽然计算上不能节约,但是在部署模型服务消耗的实例会大大减少。这也是我们后续在部署这种大模型服务时的一个主要的方案。
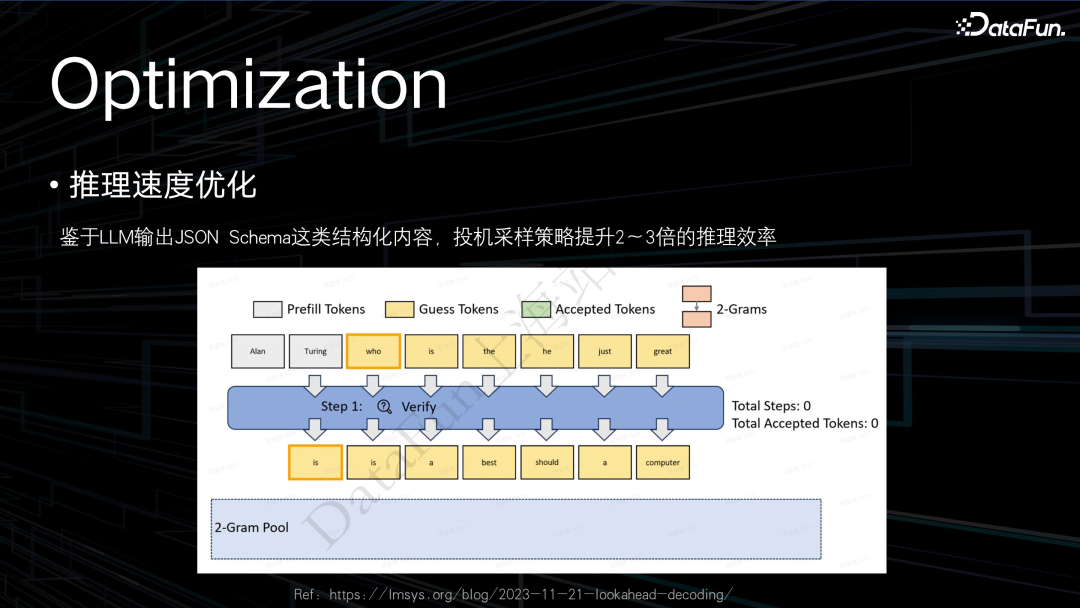
推理速度方面,当时投机采样还是一个比较新的方法,现在它已经是一个很常见的推理优化的加速方法。当时本身输出的就是一个 Json 结构的结果,里面确实有非常多的模板性质 token,只要输出结果带有很多模板性质的 token,就非常适合用投机采样的方法。
对于这种 Json 结构,如我们现在一般会用一个 n-grams 模型来作为小模型去做候选词的生成,它去被大模型采纳的概率是非常大的,在评估中,一般都能提升二到三倍的推理速度。后续也会考虑其它的优化方案。

下面介绍评估 Agent 时会采用的一些评测指标。
首先是成功率。为了评估 Agent 在执行某些工作的稳定性,我们会将同样的一个 query 反复调用多次,因为采样的不同,每次输出不会完全一样,我们通过多次执行中的成功比率来考量整体的稳定性。
第二个是相对效率。在设计一个任务时,产品经理会预想 Agent 需要分哪几步来完成一个动作,但是 Agent 可能并不会按照我们设想的这样来一步一步地完成,其中可能会有一些冗余,因此我们会去衡量 Agent 完成一个任务时花费的步数和人工执行所需步数的比值。
第三个是成功执行步数和整体步数的比值。在生成时会执行一些步骤,但可能执行失败,这一般是大模型的一些杜撰的问题,或者没有合理地构造 plugin 的调用,或者也有可能由于接口本身的一些稳定性问题,会导致执行失败。所以我们会用成功执行的步数与总步数去取一个比值,理想情况下就应该是百分百,但是大多数情况都会有一些损耗。
以上就是我们在评估 Agent 这个项目时会采用的一些计算方法。

我们的内测 demo 构建了三类评测集,一个是时新问答,就是调用搜索引擎,根据搜索引擎的结果去做一些回复;第二个是和我们产品需求贴合得比较紧密的旅游出行,看起来比较复杂,但它毕竟是一个串行的流程,只需要按步骤完成任务,最后做一个总结,对于大模型并不属于复杂任务;我们定义的复杂任务,是需要对拿到的信息去做一个总结或对比才能得到答案的任务。
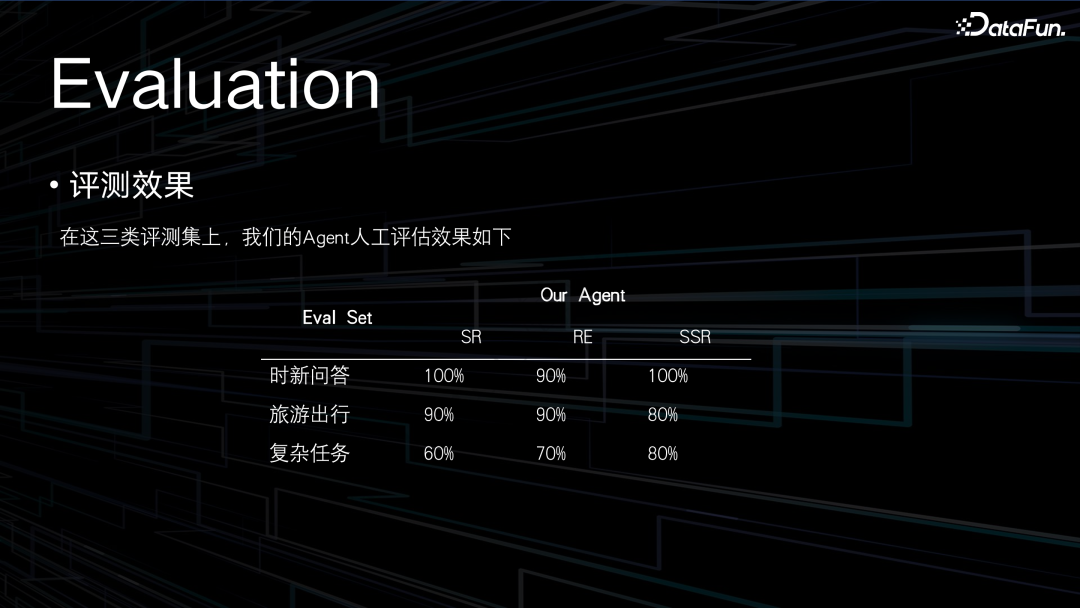
基于这些评测集,在上述介绍的框架下做了一些评测,结果如上图所示。
未来方向
最后分享一下未来 Agent 或小爱同学这一款产品的发展方向。

首先是和系统更紧密地融合。在做 Agent 项目的过程中,我们发现 Agent 到底能带给用户多大的惊喜,其实和它能与外界产生多大的交互有着非常紧密的关联。如果 Agent 能做的仅仅是去网站上搜索一些内容,再来总结给用户,其实能带给用户的惊喜是比较小的。所以我们现在正在做的一个工作就是在去梳理小米内部的 SPEC 的定义。包括手机系统的应用,米家设备的调用,以及车载设备接口的情况,我们希望设计一套整体的 SPEC 的定义,方便大模型去感知到小米整个体系下所有它可以操纵的设备和可以感知到的信息,从而为用户带来更好的使用体验。
其次是希望加强跨垂域和跨设备协同的能力。现在在做的还是以手机设备为主的预言性质的实验。未来,手车协同和人车家的概念会涉及到很多跨设备的操作,就会涉及到更复杂的架构的设计。
另外,我们现在有专门的团队在研究多模态方向的一些工作,希望打造一个机器人平台,由 Agent 作为其大脑的核心模块,来指挥其完成各种行为。
































 粤ICP备17114055号
粤ICP备17114055号
 支持私有化部署
支持私有化部署