导读 本文将探讨在 AI 应用数据处理场景,如何发挥大数据平台的规模优势,降低开发的复杂度,并分享阿里云在大数据 AI 一体化方面的实践经验。
1. 大数据 AI 开发范式的演变
2. 阿里云大数据 AI 一体化架构演进
3. Data+AI场景实践分享
分享嘉宾|刘一鸣 阿里云 实时数仓Hologres产品负责人
编辑整理|王跃辉
内容校对|李瑶
出品社区|DataFun
大数据 AI 开发范式的演变
近年来,机器学习备受关注,但开发流程上并没有本质的变化,依旧是从数据准备到预处理,到模型的开发、训练,再到评估、上线,依次反复迭代。流程没有本质变化,但在不同阶段所花费的精力和时间正在发生变化。
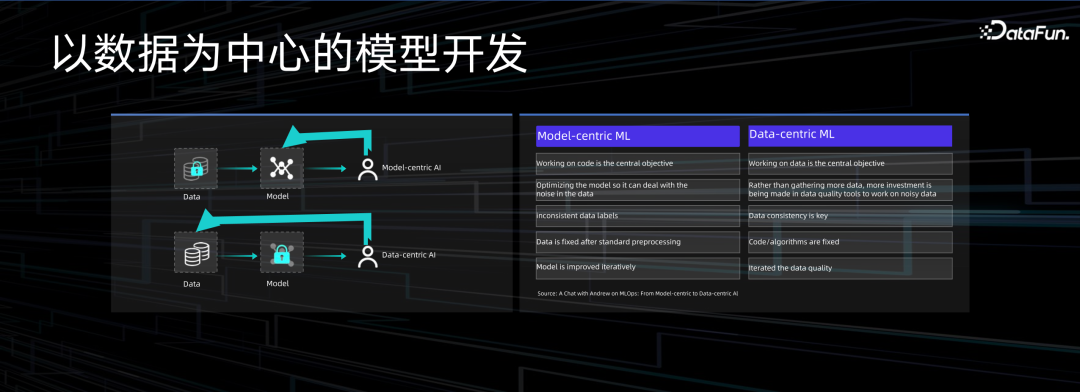
随着大模型等新型机器学习项目逐渐成为主流,机器学习项目从以模型为中心的开发范式,向以数据为中心的开发范式转变。在过去,计算的算力有限,没办法低成本处理大规模数据,更多是在模型上通过多次迭代调参处理各种过拟合、欠拟合等问题。当时的机器学习训练非常依赖于数据的准确性,依赖于标注数据的质量,而标注数据的成本是非常高的。在 Transform 模型出现之后,工程师精力的中心从模型的调优转向了数据质量的提升,不再完全依赖于标注数据的获取,这时数据平台的效率就成为了整个开发流水线中的关键瓶颈。
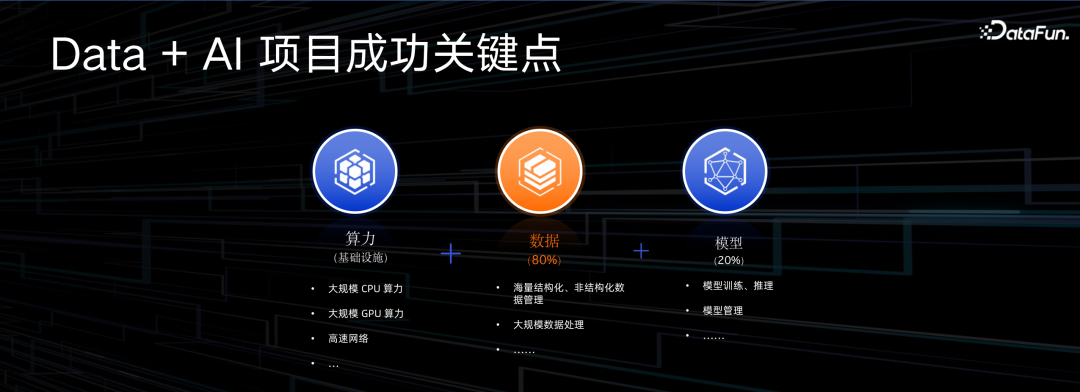
最近大家经常说,成功的机器学习项目,80% 来自于数据加工效率的改进,20% 来自于模型的优化。当然没有算力不行,但光有算力也不行,所以公式就变成了算力+数据+模型。数据部分包括结构化数据处理、非结构化数据处理、海量文件数据处理等等。
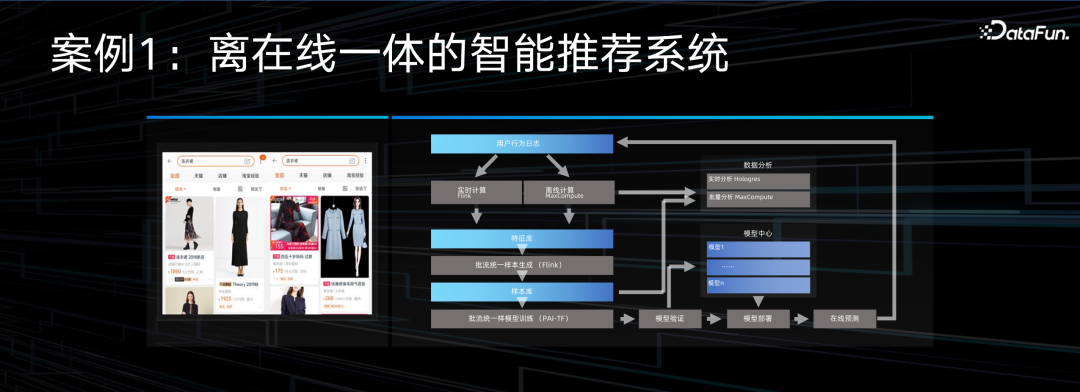
大数据 AI 一体化并不是今天才有的课题,已经发展很久了。很多公司都在做的推荐系统就是一个典型的大数据+AI 的工作,要通过数据做标签化,形成特征库,训练推荐模型。推荐模型分很多版本,要不断迭代,做各种 AB test,反复调整模型再持续上线。有些是离线的模型,有些是在线的,还有的是离在线一体的。
上图中就是典型的实现路径,也是阿里云上最经典的解决方案,包括用 Flink 处理标签实时加工,通过 MaxCompute 处理离线批量数据,然后通过 PAI-TF 进行在线训练。训练出的模型在线服务之后要做指标实时采集,以及多维度对比分析,多数交互式分析的场景使用 Hologres 这样的 OLAP 工具,支持秒级的快速查询响应。
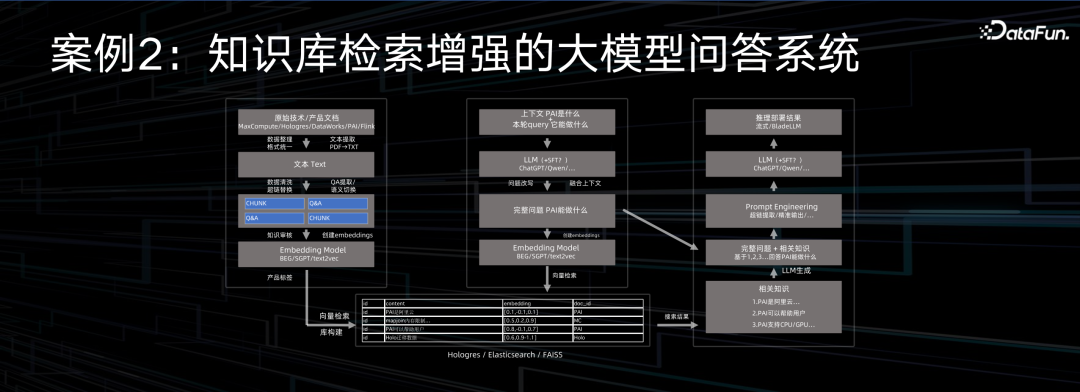
近一年时间里大模型成为焦点,使用大模型的一个典型场景是各种公司都在建设专属知识库。阿里云的网站也做了类似的工作,在每个工单控制台会有一个提问按钮,以前提问的背后都是真人在服务,服务响应时间无法保证,现在工单第一轮会是智能机器人在服务,它可以针对上下文和产品知识库,为用户提供最有相关性、更准确、更及时的回答。
具体做法是把相关的技术文档、产品使用文档做向量化处理,输入到向量数据库。当用户提出问题,会把问题做一定的改写使其上下文更加丰富,并与向量数据库做近似度匹配计算,把问题最相关的上下文文档信息抽取出来,再把这些文档一起喂给大模型,让大模型基于这些上下文相关文档输出一份准确的、可理解的、有上下文的、可解读的回答。在这个基本的流程中涉及到的技术包括了文本处理、向量数据库、大模型等等。
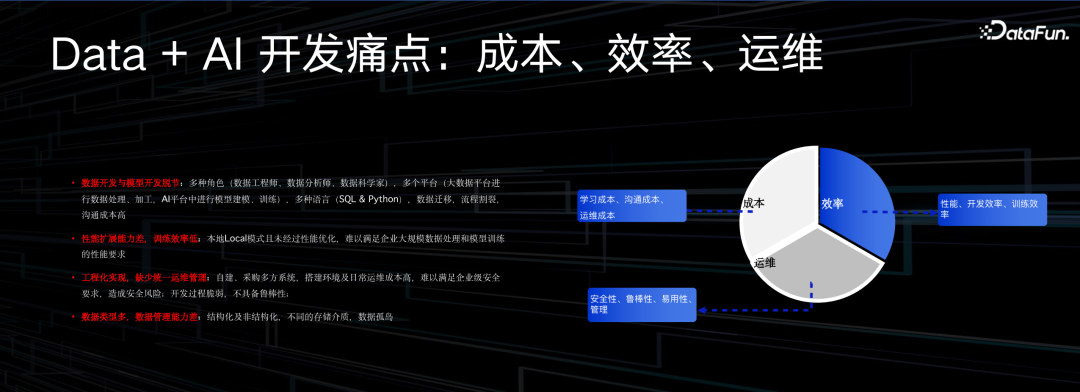
然而实现这样一个系统并不容易,要同时考虑成本、效率、运维等多方因素,会遇到很多问题。第一个问题是研发阶段割裂感非常强,做数据的人和做 AI 的人往往属于不同的团队,使用不同的平台和不同的开发语言,大家互相交流很困难。数据人喜欢做数仓、做结构化,聚焦元数据生产。而AI 同学往往基于 Python 开发语言在单机上做开发,开发之后与数据不再做闭环交互,导致这份数据往往是单向流动,造成很多的数据割裂。
其次,效率也是个问题。大数据同学非常擅长处理并行化分布式的问题,AI 同学往往更擅长怎么把模型调参,在单机上跑足够好。但如今重要的点不再是模型是否要反复调优,而是数据处理的量要上几个数量级,这时单机的算子是否还能适合新的场景,就是很大的问题,可能会遇到性能的瓶颈。
第三个是工程化的问题。过去公司数据平台,AI 平台往往是因为不同的场景,不同的目的采购不同的供应商,平台之间很难打通。很多公司采购了很多系统,用不同账号,不同权限,被不同人运维,这样会把公司平台的脆弱性全部暴露出来。
最后是数据管理能力,这是整个项目的核心。由于系统上的割裂,很难看到一个全局的、统一的数据的治理能力。大数据平台和 AI 开发平台的元数据割裂也是不容易解决的问题。
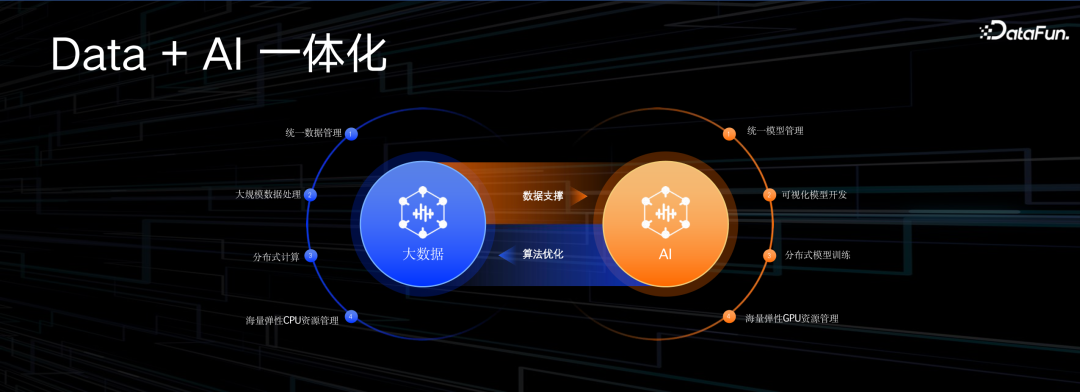
大数据 AI 一体化就是要解决上述问题。大数据平台要做好几件事情,包括统一的元数据管理,大规模的数据处理能力,分布式计算的算子,以及提供丰富的、海量的、弹性的计算资源。AI 平台要提供统一的模型管理,可视化的建模流程,分布式的训练环境,以及丰富的 GPU 的资源。大数据与 AI 的结合就是一个互相支撑的过程,大数据平台要为 AI 平台做好数据支撑,AI 平台则通过智能化的算法,让数据平台更好用。接下来将介绍阿里云在数据支撑和算法优化上所做的工作。
阿里云大数据 AI 一体化架构演进

上图展示了阿里云所提供的解决方案,包括了基础的资源层,中间的大数据 AI 一体化 PaaS 平台服务层,上层的模型服务层,最后是应用层。其中大部分应用和模型来自于我们的合作伙伴,蓝色的部分是阿里云原生的产品和服务,本文重点介绍的是其中数据平台的部分,在丰富的计算资源之上提供一个易用的可扩展的数据处理平台,同时和 AI 机器学习平台 PAI 集成、打通。
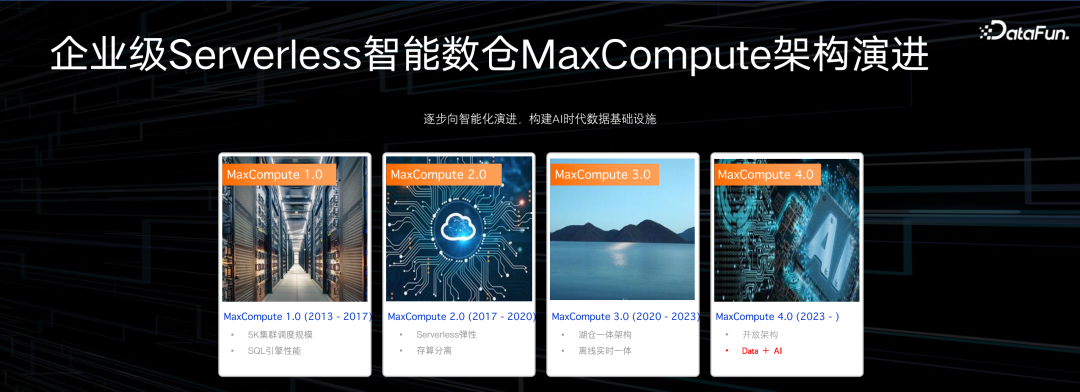
数据平台核心的部分是 MaxCompute,以前的名字叫 ODPS,即 Open Data Processing Service,其中包含两个主要的引擎,一个就是离线数仓 MaxCompute,另一个是实时数仓 Hologres。MaxCompute 是一款比 Spark 更易用,执行效率更高,企业级能力更丰富的大数据平台。
MaxCompute 经历了 15 年的迭代发展,在不同阶段,着力解决的重点问题是有差异的。最早 09 年开始做这款产品的时候,是因为阿里集团内部有海量的数据要做分析,既要替换 Oracle 降低成本,又需要很强的扩展性,支持当时业务的快速发展。当时做了 5K 项目,也就是单集群超过 5000 个节点,解决集群的可扩展问题,从此数据量不再是瓶颈。
17 年之后,开始做公有云服务,做 Serverless,这实际上是对运维方式的一个本质性变革。其背后的挑战非常大,比如升级怎么做到业务无感,无中断,怎么做到流量分配均衡,怎么做到灰度和回滚等等。Serverless 背后是租户体系的改革,一个集群服务一个 Region 所有的用户,所有类型的作业。
第三个阶段是湖仓一体的改造。这个时候我们发现结构化数据已经无法满足用户的灵活性需求,有很多非结构化、半结构化的数据需要管理和加工,有很多第三方的 Hadoop 集群需要被托管,需要更有质量的数据治理,我们提出了湖仓一体的架构,可以把基于开放存储,使用开放格式的数据统一纳管到 MaxCompute 的元数据体系下。同时也做了离线实时一体,一个在线的交互式分析引擎 Hologres 和一个离线数据加工引擎 MaxCompute 之间的元数据和数据之间的集成。
从 2023 年开始走向下一个阶段。这一阶段的一个特征是我们提出了开放架构,我们希望数仓应该是开放的、多元的,在数仓存储层提供一个 MaxCompute Storage API,第三方的计算引擎可以直接以原生的、底层的、高吞吐的方式访问数仓里的数据。过去数仓是为性能优化设计的,但今天不再是封闭的。其次我们也提出了 Data+AI 这样一个解决方案,稍后会大家做进一步解析。
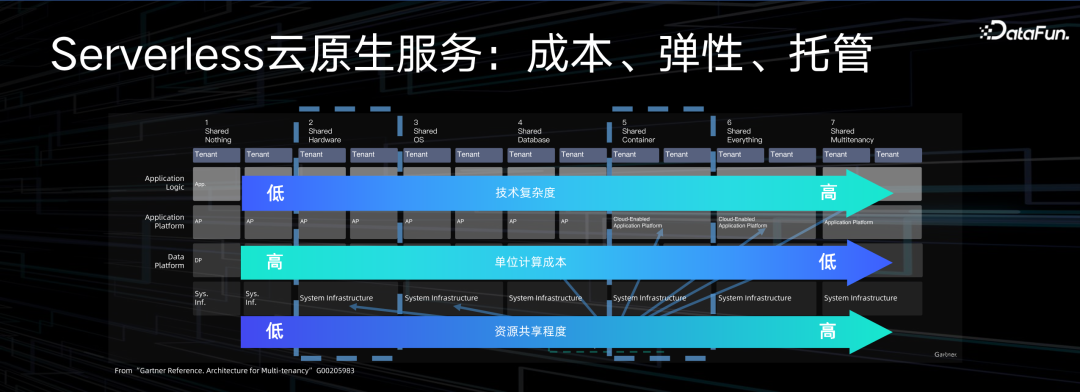
MaxCompute 的核心形态是完全的 Serverless。上图是来自于 Gartner 的分析报告,Serverless 分很多级别,体现在对资源共享的力度不同。从最原始的机器层面上的机器资源共享,到后来操作系统层面的共享、容器层面的共享、应用层的共享、租户的共享。一层层共享力度的提升,背后对于服务提供方来说,技术难度都是一个指数级的提升,但是对用户来说,收益则会越来越大。通过资源复用,有机会把整个服务的成本降得足够低,给用户更低价格的计算服务。这对资源隔离要求更高,做系统升级的难度也更大。
MaxCompute 从设计之初就被定位为一个 serverless 的产品,只有把运维效率解决好,提高资源利用率,才能提供更有竞争力的数据计算服务。除了成本之外,还有另外一个好处就是弹性。特别在机器学习场景下,只在部分时间有大量的资源需求,如果采购一台机器,有大部分时间闲置,是巨大的浪费。所以机器学习场景下对 Serverless 服务有很强的诉求。

接下来给大家讲讲 Data+AI 的解决方案,MaxCompute 针对 AI 场景的创新主要包括以下几大方面。- 首先是在数据管理层面上。数仓是很擅长处理结构化数据的,但是在机器学习场景下,有大量的非结构化数据、文件数据、图像数据等等,所以我们在非结构化数据的管理上有了一些创新,引入了 Object Table 这种新型的表类型。
- 其次是计算框架,我们推出了针对 Python 开发的分布式执行框架 MaxFrame。过去数据平台往往是提供 SQL 接口来开发,但数据科学家们最习惯使用 Python 及各类 Python 开源工具包。通过 MaxFrame,MaxCompute 数据平台提供了 SQL+Python 双引擎的能力,Python 成为数据平台的一级开发语言。
- 第三是提供了交互式的 Notebook 开发环境,这也是 AI 同学非常喜欢的开发环境,在 Notebook 里边可以做交互式的验证和作业分享。
- 最后是镜像管理。Python 开发中版本管理、镜像打包等一系列的工程问题也是效率的关键。
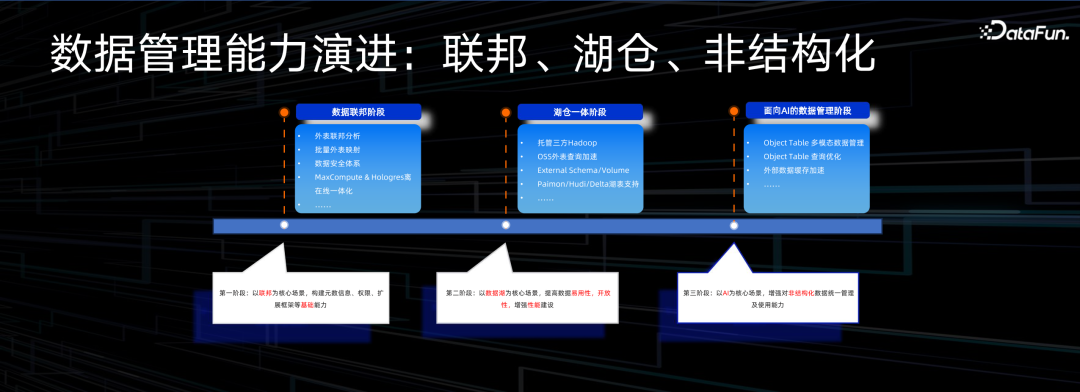
第一个阶段解决联邦问题,当数据交互双方使用不同引擎时,数据是否可以兼容,让数据不搬迁,就可以实现联邦查询。希望以联邦为中心,打通元数据管理,给用户统一的元数据视图和权限管理。
第二个阶段,仅有联邦不够,希望不同的存储格式,可以放在湖上提供一份数据多引擎的能力,所以第二阶段做了湖仓一体的能力,提高数据的易用性,提供原生的查询的能力和元数据的管理能力。
第三个阶段,越来越多的用户提出非结构化数据管理的需求。大量非结构化数据作为输入给很多 Python library 进行向量化转化,但是这些文件背后缺乏一个元数据管理能力,也很难进行分布式计算,因此我们做了 Object Table 来解决这个问题。

Object
Table 是一种新的表类型,用来处理非结构化数据。其中存储的是非结构化数据的元数据,而不是数据本身。存储的元数据包括文件的路径、文件名、文件的大小、更新时间等等,还有不少可扩展的 tag 值。
基于这些元数据可以做很多提升开发效率的事情,假如有 1000 万个文件,要交给一个大数据平台,希望平台可以并行化处理这些文件,从 PDF 文件抽取文本。一种简单的做法是一个文件启动一个进程,但是对于 1000 万个文件就要启动 1000 万个进程,调度上开销非常大。如果这些文件里边有些文件可以跳过,可以忽略,比如太小的文件不打开,很长时间没人动的文件可以跳过,其实有很多需要对元数据过滤的场景,过去没有元数据信息,很难做这件事情,但现在表里面有元信息就可以处理。
还有就是并行化处理的问题,一个进程处理一个文件,还是一个进程处理 10 个文件,对吞吐的影响是非常大的,过去没有元信息很难做,但现在有元信息之后 worker 可以进行判断。假设一个 worker 可以处理 100 兆数据,就可以把 100 兆数据以批量的形式作为输入传给一个进程 worker 并行化处理,这样整体处理的吞吐量会有本质性的提升,这也是工程化非常常见的做法。
除了这些元数据管理之外,还有很多性能上的优化,比如在海量小文件、碎片文件处理上有几十倍的提效,在单一大文件的访问 IO 上的也做了提效。

第二大创新是 MaxFrame,把 Python 的开发体验做到原生化。我们希望给用户的心智是,在单机上本地开发的 Python 程序,基于主流的 Pandas 接口开发的,可以 100% 透明的迁移到 MaxFrame 平台之上,可以享受平台上可扩展的计算算力,MaxFrame 提供并行化的计算能力。
用户写的 Python code 并不是针对分布场景,而是针对单机场景写的。但数据的输入来自于 MaxCompute 表的输入,MaxFrame 会将算子并行化,运行在不同的分布式节点之上,这也意味着在单机上跑的 Python 的作业,以前要运行几十个小时,现在可能仅需几十分钟,甚至更快。MaxFrame 的核心理念就是让使用 Pandas 接口开发的数据分析、数据加工的程序,可以无缝的、透明的迁移到大数据平台上。同时平台做到了跟 MaxCompute 底层数据的原生打通,可以高吞吐、高效率的方式访问所有数据,不只是读也包括写。

上图左侧是 Pandas 算子,包含表连接、关联、过滤、聚合等等,几乎所有的数据分析常见的 Pandas 算子都支持。右边是机器学习平台数据处理部分的 55 个算子,有大量的文本处理、文本过滤、文本去重、文本计数等等,都是 MaxFrame 原生支持的算子。这些算子背后都做了性能和可扩展性支持,用户使用起来会非常简单。
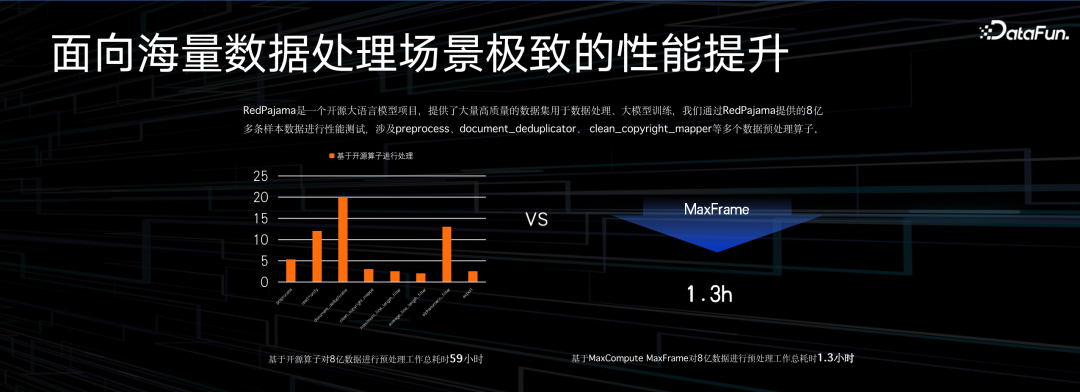
这里是一个对比的例子,左侧是开源的 RedPajama,在大模型场景下,端到端的,从数据的采集加工处理,到产出结果等七八个环节,每个环节有不同算子,以前是单机运行,跑这一流程得需要 59 个小时。转成 MaxFrame 之后仅用 1.3 小时即可跑完,对效率提升是非常明显的。
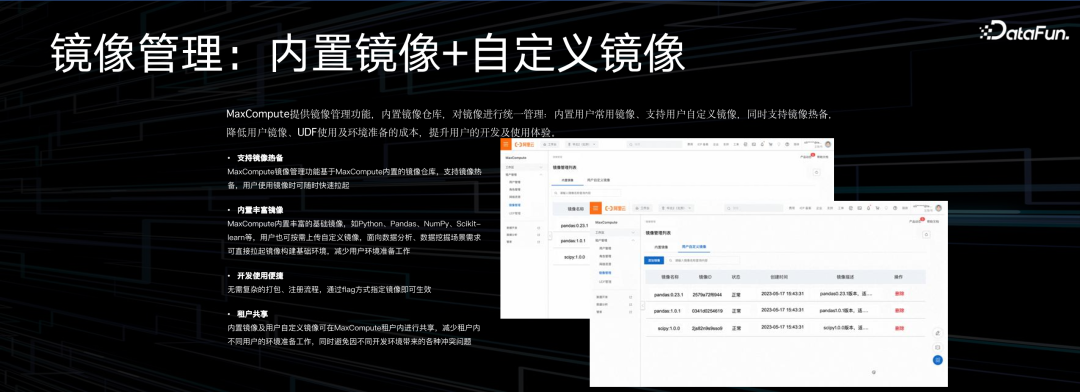
Python 开发非常依赖于不同的版本管理,镜像管理。一份作业里会依赖几十个不同的 library,所以我们做了一套镜像管理,包含内置镜像和自定义镜像。内置镜像部分把很多主流的常见的数据分析,数据加工用到的 Python library 都做了内置化,用户引用就可以了。

讲完加工的环节之后,接下来介绍数据服务环节,以向量检索服务为例。这两年向量数据库特别火,但业界常存在一个困惑就是每家公司是应该采购一个专属的向量数据库,还是选一款带有向量扩展能力的通用分析数据库。我们看到主流的云厂商大多采用后者,数据库增加向量化检索能力,通过与原生的 OLAP 能力结合,场景更丰富、开发更易用,用户使用门槛更低。阿里云也是采用这种方式。
Hologres 是一款分布式的高性能的 OLAP 引擎。在 2020,Hologres 与达摩院合作,将高性能的向量化引擎 Proxima 集成到 SQL 引擎中,提供 SQL 查询接口。Proxima,性能优异,精度也高,计算效率非常快,内置多种检索的算法。
当 Proxima 和 Hologres 结合在一起的时候,就能够把 Hologres 强大的性能充分发挥出来。Hologres 是一个面向高并发、低延迟场景设计的一个 OLAP 引擎,性能可以做到毫秒级的响应。同时也满足了易用性要求,因为不需要学习新的接口,就是 SQL 接口,对于数据同学来说非常容易使用。

向量这件事情其实并不复杂,是把文本、图片等转化为向量数组,存储在数据库表中的一个字段,Hologres 在底层自动构建各类向量索引。向量计算广泛应用在推荐引擎,大模型推理等。
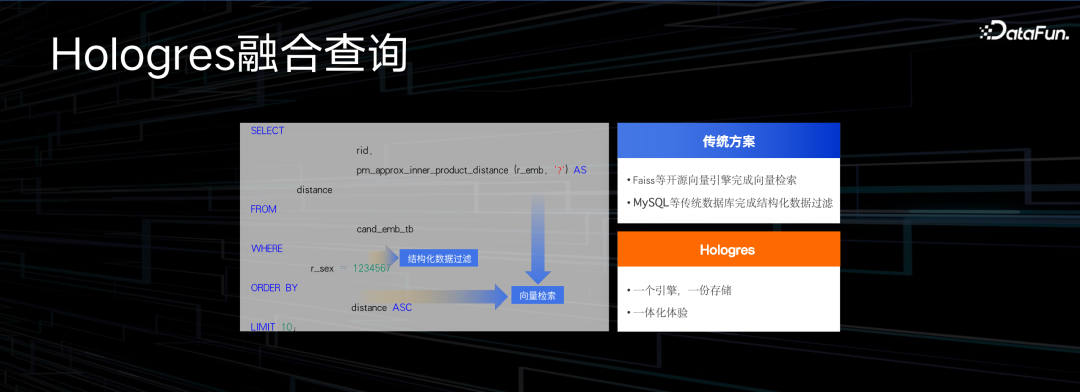
数据库和向量融合在一起的好处在哪里呢?以前向量引擎只能做向量查询,数据库只能做结构化查询,现在把向量和数据库放在一起,既可以做结构化的过滤,也可以做向量化检索,所以 SQL 语句写起来就很简单,很多以前必须在专业的向量数据库里做的事情,现在在一个通用数据库里面就做好了,一个 SQL 实现向量检索、过滤、排序、去重等操作,真正实现了一个引擎,一份数据,多个场景。
以上介绍了数据平台如何为 AI 提供支持,是 Data for AI 的视角,那么反过来 AI 平台怎么让数据平台变得更好用呢?今天所有的数据分析都在从 BI 演化到 BI 加 AI 的场景。
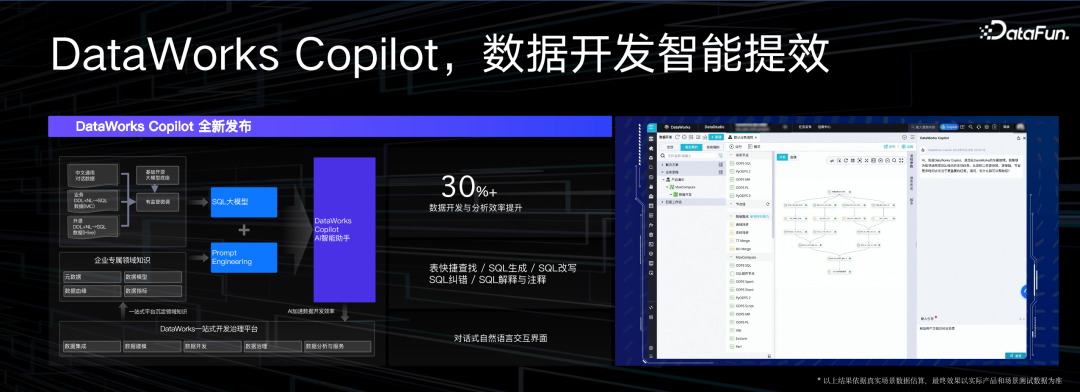
Copilot 从去年开始变为主流,NL2SQL 是常见场景,它可以帮用户写 SQL,帮助用户找表,帮助用户更容易地诊断出 SQL 的错误。阿里云推出了 DataWorks Copilot,在背后,工程师把很多 SQL 语料喂给 Copilot 的模型,希望产出一个好用的,更智能的 SQL Copilot 能力。

除了写 SQL 的开发阶段之外,分析阶段更为重要,所以 DataWorks 和 DataV 也在做合作实现增强分析,这意味着过去以经验为主的分析范式,将转化为由机器做推断。增强分析,可以自动生成各种洞察,不同的报表,不同的视图,不同的看数角度。
Data+AI 场景实践分享
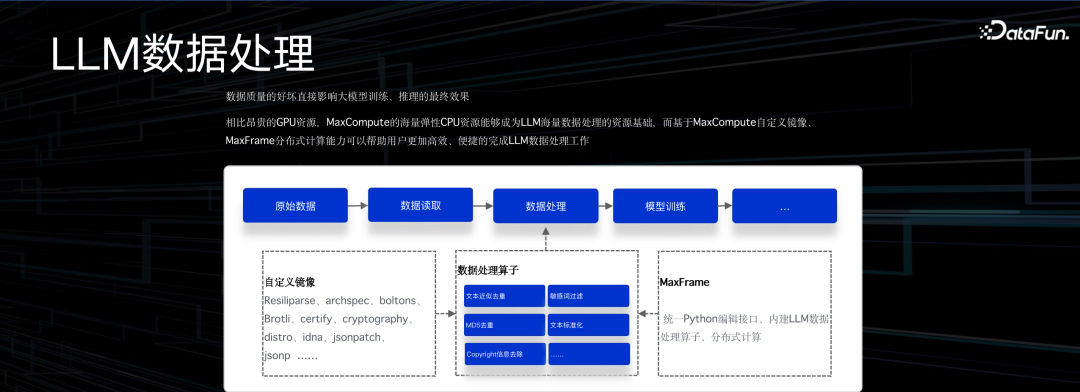
这是通义大模型的一个加工场景的简化版本,主要是在处理文本去重。主要环节包括数据采集、读取、处理到模型训练。中间有很多小的环节,比如文本的去重、敏感词的过滤、copy write 删除、文本标准化等等,依赖了很多不同的 Python
library。
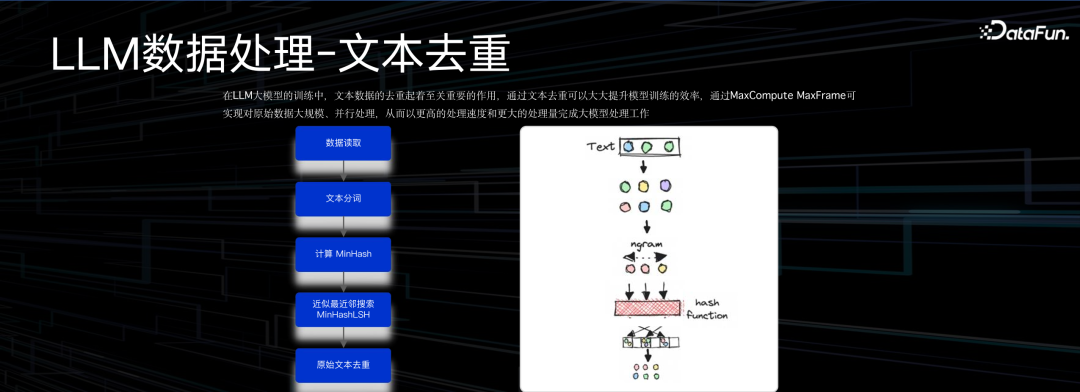
文本去重的基本流程是,先做分词,之后计算哈希值,然后求哈希近邻。
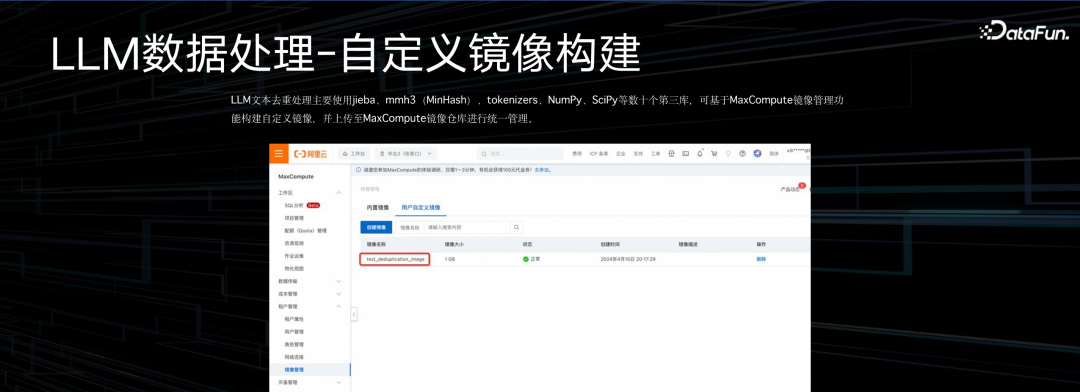
我们的做法是,首先把依赖镜像做一个好的镜像管理,这个镜像里边的用户很多依赖第三方的 library。不同的 python 的版本,不同 library 版本,大家要有共享的开发环境,所以首先要做镜像管理,把这些依赖镜像做成一个团队内可以共享的。
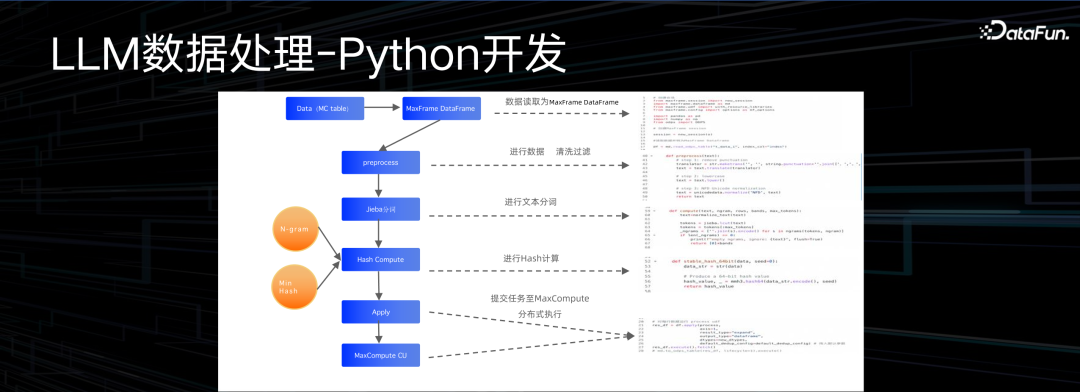
之后是开发环节。右侧部分是一段 demo 代码,这段代码最后不超过 100 行。初始化依赖 4-5 行代码,初始化框架资源,身份认证,就可以有几行代码做数据过滤,再有几行代码做分词,背后通过 Pandas 开发接口。Pandas 接口里边有各种各样的数据转换逻辑。这 100 行代码,可以跑在几乎无限扩展的计算平台之上,我们希望实现的效果是可以用小代码快速迭代的方式,在更规模化计算平台上处理规模化的问题。分布式怎么调度,怎么容错,数据该怎么切分,怎么做并行化的切分,大量类似的工程化细节都由底层的大数据平台来完成,可以大大提升效率。
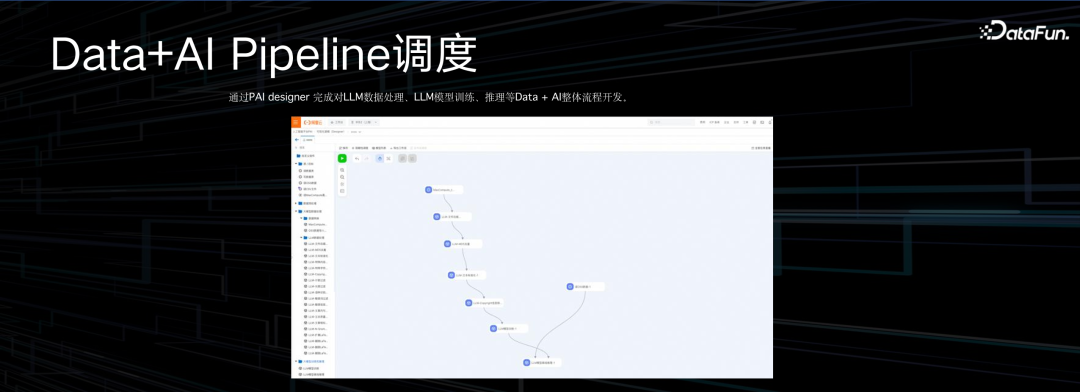
如果不喜欢写代码,也可以用拖拽的方式,平台提供了一个可拖拽的 pipeline 的组合方式,可以把整个计算流程中不同的算子以拖拽的方式组合在一起。
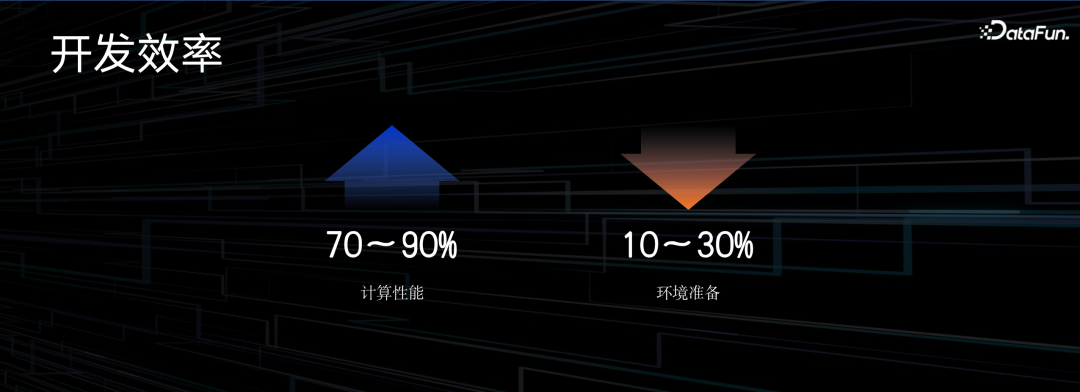
从通用场景来看,绝大部分性能都有 70% 到 90% 的提升,数据量越大,提升越明显。同时环境准备方面,我们反复强调工程一定要提效率,效率不一定都是计算效率,往往开发、调试、环境准备会占用大量的精力,我们希望通过平台来减少这部分的工作量,我们的数据平台在这方面也实现了很好的效果。
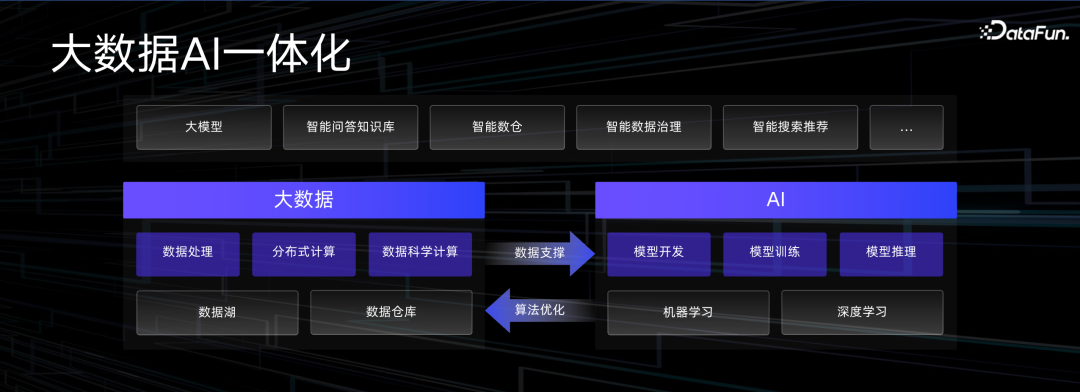
最后对大数据AI 一体化的工作进行一下总结。在本次分享中没有专门讲大数据做哪些事,也没有专门讲 AI 做哪些事,更多的是讨论二者如何更好地集成。阿里云大数据平台 MaxCompute 做了非结构化的元数据管理,支持 Python 开发语言,也让 Python 可以跑在并行化的运行环境里边。还做了大量 IO 的优化,调度的优化,提供了很好的 notebook 交互式的开发环境,提供了镜像管理的能力。这些工程化能力实现之后,可以实现大数据和 AI 之间的数据一体化、权限一体化和开发界面上的一体化。通过这些一体化,可以让 AI 同学更熟悉数据平台,也让数据平台同学可以更快地上手 AI 应用。这正是我们希望实现的效果。

































 粤ICP备17114055号
粤ICP备17114055号