大模型自问世就得到了广泛关注,并迅速引发了业内的热潮。从行业应用的角度来看,金融行业的渗透率应该是最高的。对于券商行业而言,传统业务模式存在诸多瓶颈,尤其在提升工作效率、服务效率、服务质量及降低人力成本等方面存在较大改善空间。此外,作为受监管极其严格的行业,提高企业风险控制水平,确保合规性也是我们关注的重点。因此,我们期望借助大模型的能力突破这些瓶颈。
对于大模型可以提供的帮助,我们主要有以下几个需求。
第一,借助大模型的能力,实现更为智能化的信息处理与理解,这也是我们的首要目标。
第二,期望大模型能够在客户服务场景下,提供更为复杂的交流与互动,从而更好地理解客户的需求和利益。
第三,期望大模型自动化地生成报告和文件,提供个性化的投资建议和资产配置方案,为用户制定投资决策提供有力支持。
第四,在中后台业务中期望大模型能协助有效管理风险并确保合规性。
然而经过一年的深度研究和实践,我们不得不承认大模型的实施并未达到我们的预期目标。尽管GPT模型优点明显,但在实际运用中仍面临诸多挑战。大模型所提供的结果尚未完全符合预期,未能达到理想中的优越表现。那么说到底大模型究竟是一种有效的工具,还是只能说是一种“玩具”呢?当我们在讨论大模型的潜力与可能性时,实际上是否等同于其实际应用能力?针对这个问题我们做了深入思考,同时借鉴了许多专家的分析意见。

大模型可以划分为两大类别。首先是通用大模型,像这样的模型通常由大型科技公司开发。通用大模型旨在一个模型中解决多种问题,然而在回答许多专业性问题及与我们的业务相结合时,可能会存在一定的误导性。因此,为了更好地应用于真实业务场景,我们希望整个生态系统或合作伙伴能够更多地关注和研究垂直大模型,这才是能够与业务需求相匹配而且更为紧密贴合的方向。相比之下,垂直大模型专注于捕捉特定领域中更为复杂的特征和关系,包含大量专业性的语料,以及专业的微调和优化。我们希望将这个大模型运用到垂直领域进行深度整合,使其应用更加贴近我们的行业,使其更加契合我们的应用,进而实现大模型从创意工具向真正生产工具的转变。回到金融领域,这个领域下的垂直大模型,运行速度最快的是BloombergGPT,因为它有着海量的金融市场数据,因此无论是从综合评价还是用户试用反馈来看,BloombergGPT在金融领域的表现最为出色,但很可惜的是它并不开源。除此之外,FinGPT、FinBERT、聚宝盆等开源垂直领域的模型都各具特色,但相较于BloombergGPT还有显著的差距。02 山西证券AI与大模型应用实践
了解了金融市场的大模型情况后,我们再来看看山西证券推进大模型过程中的尝试和探索。从2022年11月30日ChatGPT的发布,到2023年3月13日,我们内部进行了一次关于大模型的汇报,也认为证券行业落地大模型是一项极具创新性,甚至可能引发生产力革命的事情。为此,我们一直在跟踪、学习和调研。八月份随着通用大模型的开源,百模大战就此打响。这对于开展垂直领域的大模型是一个极好的机会,我们不需要重新构建一个垂直领域的大模型,可以立足于现有的通用大模型之上,将我们的金融数据灌输其中。正式开始实践后,我们将自身的优势业务与之相结合。山西证券在固收业务方面在整个金融行业内表现得相当出色,因此我们首先在固定收益领域开启了大模型的探索之旅,十一月份,我们又开启了合规领域的探索。下面重点讲两个案例。第一个案例是关于FICC的场景。对于固收债券交易,只有在双方达成共识后才能进行交易。因此,该市场的主要业务模式还是依赖于声讯与电讯等途径,且以电讯为主,通过这种业务模式达成交易目的。为提高交易量及服务质量,山西证券推出了AI数字助理(AI固收债券交易机器人)。这是一个可以进行债券交易的数字化机器人,能够为我们的客户群体,自动推送服务信息。基于这些服务信息,我们还能推送山证自己的报价,从而与客户建立起在线交易的意愿。在此过程中,我们发现大模型的引入可以有效地协助我们提升交易效率。实际上,我们就是希望大模型能帮助我们做出精准的判断,了解交易对手方的真实意图,以便确定他们是想要获取信息、进行交易,还是目标在于了解我们的报价。判断意图之后,为了符合合规要求,我们不能直接地自动完成这笔交易,而需要实时地向我们本方及对方交易员反馈相关情况,以便进行后续交易操作。在此过程中,由于整个流程都有电子化的记录,过去因为合规要求的存在,在没有大模型介入的情况下,该流程常常会被某些合规审查因素所打断,从而导致一些效率低下的环节出现。因此,我们期望大模型能够在确保合规要求得到满足的前提下,快速构建起合规屏障,以保障系统安全。正如前文所述,我们的主要目标是从客户以及交易对手方的角度出发,让用户输入某些业务场景下的文本信息,而后通过大模型分析出客户的真实意图,进而自动提供客户所需的答案。在此过程中,无论用户是享受了服务或是完成了交易,都是我们进行设计的主要动机。我们使用的是开源的ChatGLM的最新版本,因为这个版本在同等效果下对资源的占用较为合理。第二个是一个关于合规的案例。在开展这项工作之前,我们内部已经围绕着员工如何合规地拓展业务进行了讨论。我们创建了一个名为合规宝典的工具,这实际上是集合了我们的合规数据库以及合规知识库。我们让知识库对大模型进行学习训练,并基于Langchain与ChatGLM等大语言模型的本地知识库进行了问答应用的实现。我们将知识库内容通过大模型呈现给员工,针对他们提出的问题机器人会以对话的形式展示出答案,而且答案后还配有一个指针,只需点击便可了解该答案源自哪个数据,以及知识库中相关的具体内容和相应的法规规定。这样的工作模式实际上大大节约了员工大量的检索时间,极大地提升了工作效率。它采用本地对话模型ChatGLM2与Embedding,以此来生成相对准确的答案。通过查看答案所对应的原有知识库内容,确保了答案的精确性,使用人可以进行初步的判断,避免虚假答案的出现,进一步满足了合规部门的需求。通过这两个实例我们可以看到,虽然距离理想状态仍有距离,但与人工手动检索相比,效果确实有所改善。03 AI与大模型问题和思考
对于我们整个金融行业领域,无论是作为大模型的使用方,还是站在合作伙伴的角度而言,都将面临三个重要的考量因素,分别是算力、模型以及数据。算力、模型及数据是一个类三角形的关系,模型优化程度越高,其依赖的数据和算力越少,其余两者也是同样的逻辑。因此,在这个过程中,我们必须处理好算力、数据和模型之间的平衡。我们期望能够在某些方面找到突破口,例如BloombergGPT那样,在数据类别方向上具备独特的优势;或者可以如同开源的ChatGLM那样,在模型性能方面、原创性方面投入更多,在这种情况下也能具有优势。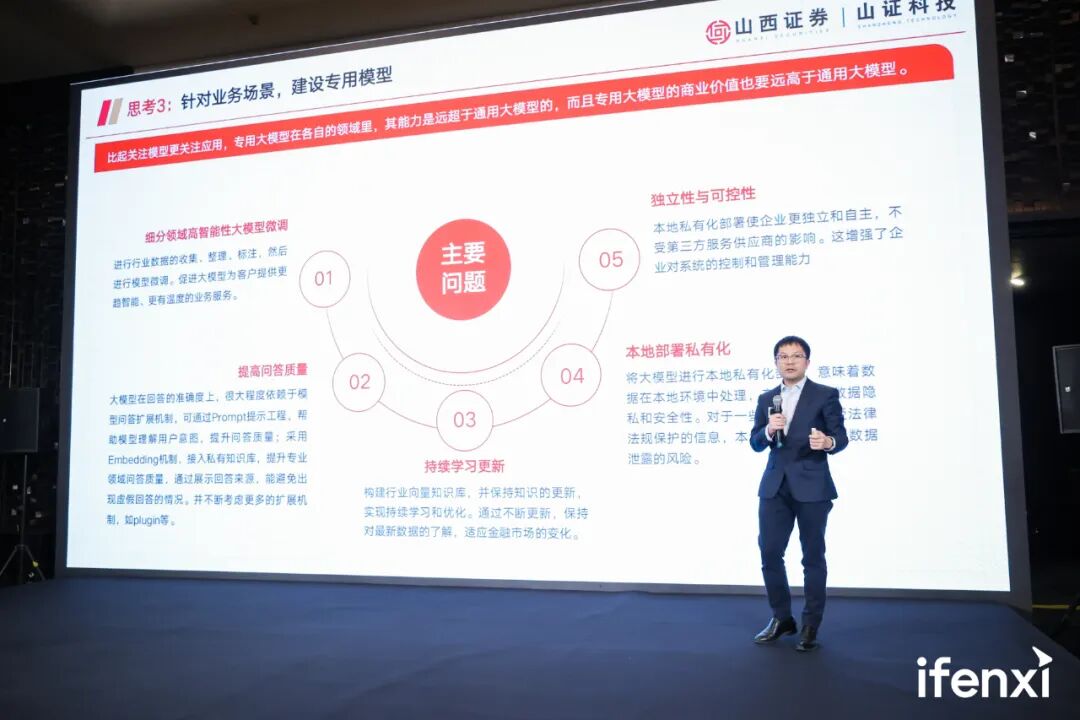
这三个考量因素涉及我们对大模型价值来源的看法。首先,由于大模型本身的特点,它能够利用人来反馈,但这也使得它很容易受到意见领袖的影响。因此,如何区分长尾客群的真实意图非常重要,这也是我们需要注意的一个问题,所以保证价值取向其实涉及各方面的工作。一个大模型只有在性能优秀的基础上且能妥善解决伦理问题,才能从竞争中脱颖而出。最后我们归纳出这五个问题,也是在业务场景下,垂直大模型要解决的五个问题。第一,如何在细分领域做好高智能性大模型的微调;第二,如何提高问答质量;第三,如何保证大模型知识的持续学习,这也牵扯到第四个问题,如何做好本地部署私有化。通常情况下,我们需要交付本地化部署的产品,在金融行业更是如此。目前,大多数垂直领域的模型在实现本地化部署后并不具备持续学习能力;第五,如何保证企业对于大模型的独立性与可控性。以上就是我们在大模型方面的一些思考,以及长期以来的探索与实践介绍。

































 粤ICP备17114055号
粤ICP备17114055号