上周在Microsoft AI Day上被微软的老同事们一顿安利,感觉上也挺有搞头的,就来介绍一下吧,微软的Phi-3 Vision。这款开放式多模态模型,以其42亿参数的轻量级设计,实现了性能与效率之间的完美平衡,为广泛的应用场景提供了一个吸引人的选择。
Phi-3 Vision作为Phi-3家族中的首款多模态模型,不仅继承了前辈们的优势,更通过语言与视觉输入的无缝融合,拓展了其功能边界。它拥有12.8万Token的上下文长度,大多数场景都能用了,支持复杂而微妙的交互,无论是在设备上运行还是提供离线操作,都显示出了极高的性价比。
在多样化的应用场景中,Phi-3 Vision展现出了其多功能性。无论是光学字符识别(OCR)、图像字幕、表格解析还是扫描文档的阅读理解,它都能以高质量的推理能力,推动创新,引领可持续的新应用开发。想象一下,通过分析汽车镜头来评估车辆损坏,Phi-3 Vision能够即时向用户提供反馈,在微软技术中心里你能看到保险领域只需要客户围着车拍一圈,基本定损情况已经测量好了,这是个刚需啊,有一次我作为众多大聪明中的一员在高速堵车中被人追尾,下来之后人家要跟我800块私了,我也没啥经验(谁没事儿有这个经验啊),但是多了个心眼拍了两张照片给4S店,结果4S店说估计不够,然后又来来回回耽误了一个多小时说还是报保险吧因为可能很贵,结果...真的很贵。(如果你在广州、北京、上海的话,微软技术中心中有这个Demo)。
当Phi-3 Vision与更大的LLM如GPT-4o结合时,它们共同构建的混合工作流程,将Phi-3在简单任务上的高效率与GPT-4o在复杂任务上的强大能力相结合,为多步骤流程提供了最佳解决方案。
市场趋势与Phi-3 Vision的崛起
人工智能市场正迅速演变,Phi-3 Vision在这样的背景下,成为了一个值得关注的趋势引领者。它不仅代表了微软在多模态AI能力上的重大飞跃,更以其开源的特性,促进了一个以社区为驱动的创新生态系统的繁荣。
多模态AI模型的崛起,得益于它们对文本和视觉数据的双重解读能力,这不仅增强了用户与数字内容的互动,也为数据分析和可访问性开辟了新的道路。随着企业和消费者对更直观、更强大的AI解决方案的需求日益增长,多模态模型的重要性预计将持续上升。
效率与边缘计算的结合
Phi-3 Vision的紧凑而强大的架构,体现了市场对更高效AI模型的需求,这些模型能够在计算能力有限的设备上运行。随着市场对成本效益高、计算密集度低的AI服务的需求增加,Phi-3 Vision的市场关注度也在不断上升。
跨行业整合的未来
Phi-3 Vision的适应性和性能预示着,高级AI模型将被整合到各行各业中。从文档数字化到高级自动化解决方案,Phi-3 Vision和类似的模型将通过提高生产力和降低运营成本,改变各个行业。
竞争力分析
尽管Phi-3 Vision的规模相对较小,但它展现出的性能却与更大的模型不相上下,是具有多模态能力的最小LLM之一。甚至有些能力超过了GPT-4V,要知道GPT-4是个万亿参数的模型啊。看下面这个表吧。
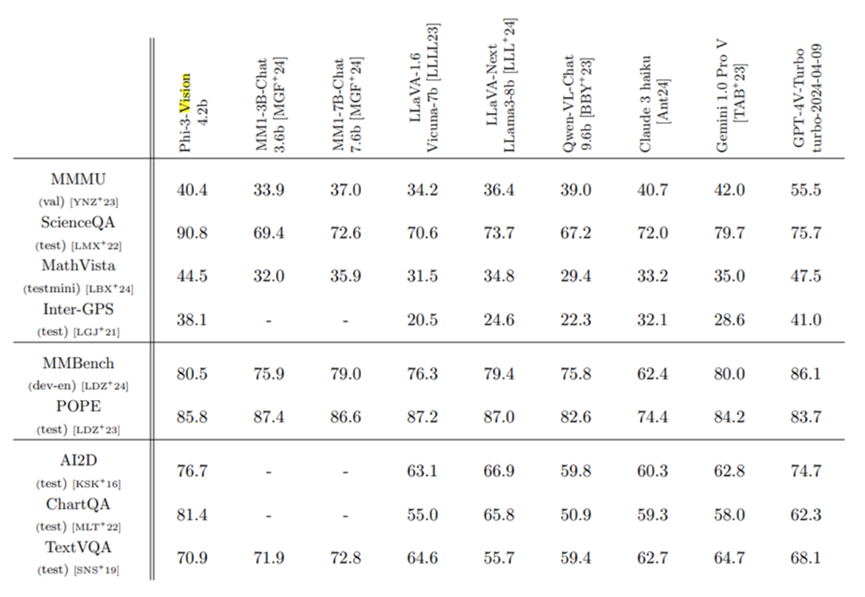
这种高效率使其特别适合在计算资源有限的设备上部署,如智能手机。此外,模型的ONNX格式优化版本确保了在不同平台上,包括服务器、桌面和移动环境的CPU和GPU上加速推理。
模型架构与能力
Phi-3 Vision基于Transformer模型架构,这一架构在各种NLP任务中已经证明了其卓越的成功。它包含图像编码器、连接器、投影仪和Phi-3 Mini语言模型。模型能够支持高达128K令牌的上下文长度,仅有42亿参数,可以广泛进行多模态推理,擅长从复杂的视觉输入(如图表、图形和表格)理解和生成内容。它集成到行业标准的Transformers Python库的开发版本中,进一步简化了其在AI驱动应用中的采用。
训练数据与质量
Phi-3 Vision与众不同的因素之一是其训练数据。与许多仅依赖人类生成数据的模型不同,Phi-3系列模型的训练数据集是使用先进的合成数据生成技术和高度整合的公共网络数据创建的。这种方法旨在最大限度地提高训练数据的质量,特别注重帮助模型发展高级推理技能和解决问题的能力。这种训练数据集有助于提高模型的鲁棒性和多功能性,使其在各种视觉推理任务中的表现远远超出预期。
目标用例与适用性
在更广泛的AI行业中,随着AI构建者寻求优化其GenAI用例,用Phi-3等更高效的模型取代GPT-4o等更大的模型是一种强烈的趋势。一种常见的模式是启动一个具有强大的LLM(如GPT-4o)的用例,一旦解决方案投入生产,就考虑将更高效的SLM(如Phi-3)纳入一些不那么复杂和复杂的应用中。这也意味着GPT-4o生成的第一批生产数据可用于微调Phi-3模型,以较低的成本提供与大型模型相当的精度。
鉴于这一趋势,Phi-3具有可用于许多用例的潜力,涉及内存/计算受限环境、延迟限制场景、一般图像理解、OCR、图表和表格理解等。微软还给了几种Phi-3的应用场景,我怎么说呢,是的,这几种是挺常见的,也挺有效的,但是也太乏味了。
Phi-3 Vision的应用场景谱系
KYC文档和图像分析:通过结合文本提取和图像分类来简化“了解你的客户”(KYC)流程,自动化验证身份证明文件,加快KYC进程。
增强的客户支持和产品退货:使用文本和图像分析来增强客户支持,包括产品退货管理,通过高效处理退货或换货实现快速解决。
社交媒体内容审核:集成文本和图像分析来识别和调节社交媒体平台上的不当内容,维护社区标准,确保用户安全。
汽车和家庭保险的视频片段分析:分析视频片段以评估汽车和家庭保险领域的损失并验证索赔,帮助快速、准确地进行索赔解决。
教育工具的视觉内容分析:利用文本和图像分析来开发交互式和自适应教育工具,根据学生的文本和视觉输入提供定制内容和反馈。
随着去中心化计算的趋势,智能手机、平板电脑和物联网设备等边缘设备的用户需要能够在有限的计算资源下运行的轻量级人工智能模型。Phi-3 Vision在较小设备上高效运行的能力使其对这一群体具有吸引力。通过利用ONNX Runtime Mobile和Web,看出来微软正在努力在从智能手机到可穿戴设备的各种设备上启用Phi-3 Vision。

































 粤ICP备17114055号
粤ICP备17114055号






