数据分析领域如何应用大模型和RAG技术,以及如何实现相关应用的落地。在数据分析领域,应用大模型的方向相当广泛,今天将主要聚焦于对话式BI,这是大家可能最常听说的方向。
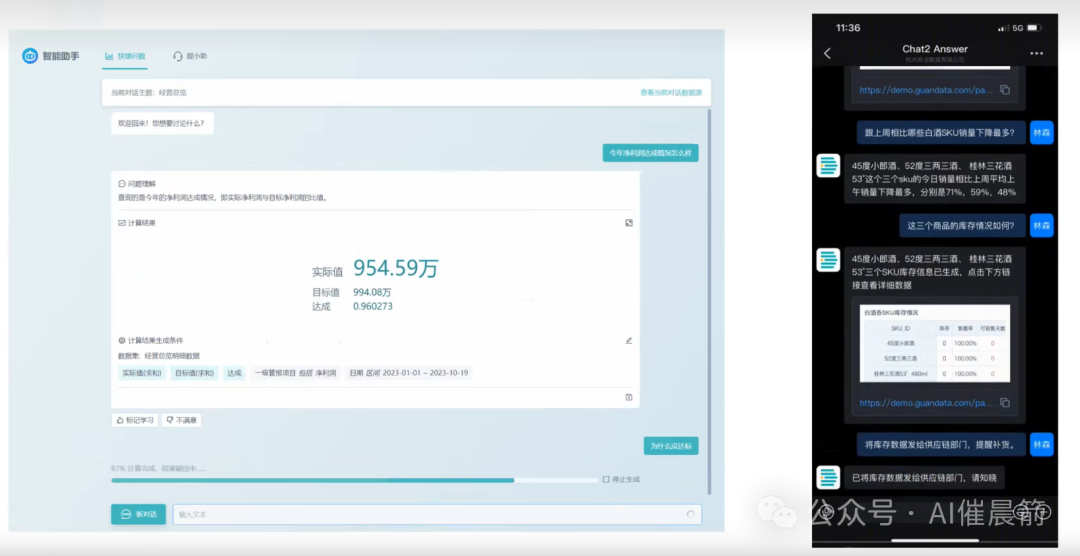
对话式BI允许非技术人员通过网页端或移动端以自然语言提问。
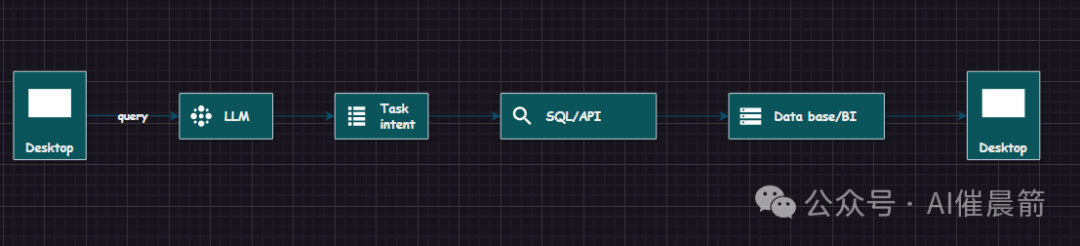
例如,业务人员可以直接在页面上以自然语言提问。提出问题后,我们结合大语言模型和RAG技术进行用户意图的理解,并生成相应的查询语句,这些查询语句可能是SQL形式的,也可能是一些API,如渠道平台API或BI平台的API。查询语句将发送到后端数据库系统或BI系统中,产生结果后,最终的数据结果将展现给前端。当然,还包括一些可视化或自然语言报告解读,这些都是可以做到的。产品形态实际上是一种比较简单的一问一答形式。但中间可能有些环境可以做得更加复杂,例如可以做一些意图识别和需求确认。
在开发chat BI产品过程中,它虽然也是一个问答系统,但相对于通用问答系统来说,有一个核心难点,即回答准确率的要求非常高。例如,如果我们打开其他一些AI助手,做一些问答,它会去网上搜索一些文章,然后结合网上的文章做些回答。这类产品在回答精度上有很多日常问题,比如“天空为什么是蓝色?”如果出现了一些幻觉或者甚至答错了,可能关系也不是很大的。但是在企业内部,如果我问了一个数据相关的问题,比如“最近的营销活动效果如何?”或“会员的复购率情况如何?”,如果数据有问题,企业后续基于这个数据再去做决策,肯定会导致决策失误,带来的后果是非常严重的。
因此,回答准确率本身是chat BI产品落地的一个核心挑战。在尝试落地chat BI过程中,我们发现导致回答准确率难以提升的一些难点。
包括企业内部有很多专有知识,尤其是与通用问答相比,这更加明显。例如,我们服务的美妆客户,他们会有一些“神仙水”、“小灯泡”、“小紫瓶”等产品的特殊称呼。这些产品名称在业务人员口中说出后,最终转化成底层数据库或API层面的查询时,底层数据肯定是商品的全称,如“某产品精华面霜多少毫升”。
一个简单的昵称可能对应多个SKU号码,甚至对应一个品类也有可能。所以背后的规则是多种多样的,这绝对是通用大语言模型不可能学到的知识。此外,知识的变化也非常快,包括一些计算口径,如在查询时是否包含赠品,是否要做税前和税后的计算等。同样一个指标名称,在不同业务部门、不同公司可能有不同的定义,这些都是企业内部的主要知识。我们需要通过一些技术把这些知识提供给通用的大模型。
另外,还有查询逻辑的复杂度问题。很多业务提问虽然相对简单,如询问复购率或激活率,但当生成回答时,逻辑的复杂度非常高。不像回答“天空为什么是蓝色”这样简单的问题,它可能只是一个事实性的维度,没有多少逻辑推理部分。
在生成复杂指标查询时,可能需要多个子查询,有不同的过滤条件,子查询做了join之后,外围还有一层嵌套,最后再去算比例。代码生成必须是可执行的,代码中的每个单词都需要非常精确,错一个都不行。代码本身一串下来,前后上下都是互相关联的,逻辑关联的关系也不能错,所以对复杂度和精确度的要求非常高。
这也导致像GPT 3.5之类的模型可能无法达到生成复杂查询的要求,可能需要接近GPT 4级别的模型才能实现。
最后一块可能是与评估相关,即用户如何判断数据是对还是错?他们判断数据对错后,才会给我们反馈。这个其实可能在通用问答类产品中也会有问题。例如,如果用户本来就不知道“天空为什么是蓝色”,你给出了一个回答,中间有一些事实性、科学性的错误,用户可能也无法判断。
当知道了数据是对还是错之后,用户如果有了反馈,这个反馈后面怎么样去收集和利用,能够不断地自动地提升整个系统的智能性,这也是一个值得深入探讨的话题。
为了解决上述挑战,尤其是前两个,我们可以探讨如何通过RAG技术解决这些难点。数据分析领域的RAG与通用RAG流程区别
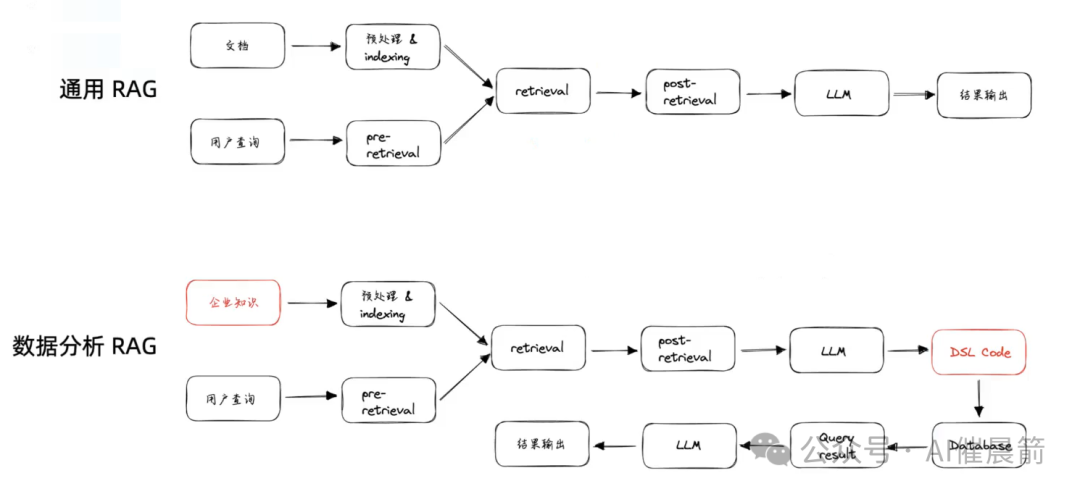
我们看一下通用的RAG流程,借鉴的是同济大学的那篇关于RAG的survey。
- 2.通过预处理(embedding)进入到索引数据库中;
- 3.用户查询后,也会做一个预处理(embedding),可能会做一些查询改写、扩写;
- 4.把这个改写和用户的查询做了向量检索,或者使用传统检索做真正的召回;
- 5.召回之后,可能后面还会有一些后处理的重排序或压缩操作;
- 6.最后把所有的context结合用户的问题一起扔给大模型;
数据分析领域的RAG可能主要有两个核心的区别
一个是在知识这块,另一个是在输出结果的时候。
知识这块的话,会发现有很多企业内部的专有知识需要输入。知识的输入形态可能与通用知识问答不同,更多是指标定义、行业黑话等如何定义和理解的内容。这些内容没有那么直接能获得,也不会有一些企业内部的黑话大全等现成文档。怎么样去获取和进入到我们的知识库中,这是一个非常不一样的点。
另外,在输出结果时,第一步输出其实不是直接的回答,而是一个代码。这个代码可能是SQL、JSON或一些API的调用function call等,接下来会去数据库做查询。数据库查询的结果后续再进到大模型中,最后让大模型再把数据结果用自然语言的方式解读,生成一份自然语言的报告给到用户端。
企业知识内容

数据分析的企业内部知识形态与通用知识非常不一样,它包含表知识、业务知识等
来自企业内部的数仓或数据库,包括表的名称、描述、服务的主题、字段类型等。包括指标口径的定义、业务关注的问题、不同业务部门关注的主要指标、常用语的缩写、简写和规则等。
当用户问一个数据相关的问题后,可能会提出一些洞察类分析类的问题。这时需要让系统的大模型理解用户的洞察意图,做一系列的指标拆解、维度遍历或算法归因,找到指标变化的原因。之前有很多产品做了智能洞察相关能力,但这些产品可能都有一个通用问题,即洞察流程主要以数据统计的显著性为依据。例如,用户问销量为什么上升,系统通过数据统计挖掘发现是因为双十一活动导致销量上升。这对业务人员来说是一个常识,虽然从数据统计意义上来说是正确的,但日常分析不会这么去分析。因此洞察和问答都依赖于对数据的深入理解和分析,而大模型在这个过程中起到了辅助和加速的作用。然而,为了实现最佳效果,还需要结合具体的业务场景和需求,如以下方面:洞察的个性化:不同的业务人员和部门在分析同一份数据时,会根据自己的业务需求、经验和知识背景,形成不同的洞察思路。这种个性化的洞察过程是动态的,需要不断调整和优化。
识别常识与非常识:在洞察过程中,用户需要区分哪些信息是常识,即广泛认可和理解的信息,哪些是少见的insight,即需要深入挖掘才能得到的洞见。
大模型的局限性:虽然大型模型在处理和分析数据方面具有强大的能力,但并不是所有问题都能通过一个通用的大模型来解决。特定领域的知识和业务逻辑需要定制化的模型来更有效地解决。
问答知识的重要性:收集和整理历史问答数据,形成标准答案库,可以帮助大模型更好地理解和生成回答。这种问答知识可以辅助大模型提供更准确、更个性化的服务。
知识输入的必要性:无论是洞察还是问答,都需要将相关的业务知识和数据输入到大模型中,以便模型能够提供有价值的分析和回答。
如果业务人员之前在工单系统或与分析师交流过,提过一些需求,那么这些标准答案也可以收集下来,辅助大模型生成回答。为了提供企业的数据分析定义,知识的来源可以是BI系统。例如,表知识可以在BI系统的数据集中找到,业务知识可以在指标平台、dashboard等中找到。BI系统作为企业数据分析的核心入口,沉淀了大量的数据分析相关知识,因此由BI系统扩展去做chat BI是非常合适的路径。
SQL代码生成方面
大模型拿到context后生成的是代码。代码生成与普通回答生成在技术上有一些区别。
任务拆分(schema linking)
例如在SQL领域非常流行的schema linking技术,将生成SQL的任务拆成两步:先做选表和选字段,再生成具体的SQL代码。这样虽然是一个复杂的逻辑推理任务,但当任务拆得足够细时,难度也会大大降低。
代码验证与修复
生成的代码可以做验证,检查代码是否可执行,通过静态代码检查工具如SQL Parser等。如果发现问题,如选了不存在的列,可以告诉大模型之前的问题并做一些自动修复。这与常规的RAG问答类似,在回答生成时可以做一些事实检查。
抽象和复用
例如用语义层生成API调用,而不是直接生成SQL。这样的好处是减少了生成的Token量,提高了效率和准确率。例如,同环比分析在自然语言中只有几个字,但写成SQL非常复杂。可以把这些常用功能包装成一个函数,当用户提到同环比时,直接调用这个函数,提高了生成的效率和准确率。
RAG优势
使用RAG技术做ChatGPT落地有一些明显的优势,例如可以通过RAG引入企业内部知识,结合大模型的通用能力和逻辑推理能力,有效降低幻觉。
RAG与Fine-tuning相比,可控性更好,数据安全性更高,更新成本更低。
可控性:RAG提供了更好的可控性,尤其是在处理企业内部特定术语和黑话时。
过拟合与灾难性遗忘:RAG相比fine-tuning,更不容易出现灾难性遗忘,即在提高特定领域知识的准确度时,不会丢失通用知识。
数据安全与权限控制:RAG允许在检索阶段进行安全权限检查,便于控制不同部门对知识的访问。
RAG与Agent之间的关系也是一个常见的话题。RAG可以看作是一个固定流程的工具,而Agent则具备更多自主性。未来的发展方向可能包括将RAG作为Agent记忆模块的一部分,实现更高级的自动化和智能化。
技术组件选择上,建议根据现有技术栈和数据量选择合适的向量数据库和embedding模型。开发框架方面,推荐使用成熟的项目如Llama Index,它专为RAG设计,提供了丰富的高级技术。
最后,结合RAG技术在数据分析领域的落地难点,包括准确性评估、测试用例管理、线上追踪和评估框架的选择。准确率是关键挑战,需要通过各种技术手段确保知识库的更新和维护。

































 粤ICP备17114055号
粤ICP备17114055号