人工智能(AI)在生成类似人类的文本和准确回答问题方面取得了飞跃,但存在局限性。传统模型完全依赖于它们的训练数据——在训练期间吸收的固定知识。它们无法查找新鲜或专业信息,这限制了它们在动态情况下的实用性。
检索增强生成(RAG)通过使 AI 能够实时“咨询外部来源”来解决这个问题,就像学生在开卷考试中参考教科书一样。这种检索和生成的混合方法使 RAG 能够产生更准确、上下文相关和最新的回答。让我们深入了解 RAG 是如何工作的以及为什么它是 AI 演变中的变革性步骤。
什么是检索增强生成(RAG)?
检索增强生成(Retrieval-Augmented Generation, RAG)是一种结合“检索”和“生成”能力的人工智能技术,类似于学生在开卷考试中的答题策略。想象一个学生亚历克斯正在准备一场开卷考试。在考试中,亚历克斯不仅依赖记忆,还会在遇到难题时查阅课本中的相关章节(检索信息),然后结合自己的知识写出完整、有依据的答案(生成回答)。这正是RAG的核心理念。
RAG 将两种主要的AI能力——检索和生成——巧妙融合。
检索:当面临问题时,RAG并不局限于其训练数据(类似于“记忆”),而是主动从外部知识源中检索相关信息。这些外部来源可以是数据库、文档或其他结构化知识库,就像亚历克斯在答题时查阅课本一样,确保获取准确且最新的知识。
生成:在获取到相关信息后,RAG结合这些检索结果与自身已有的知识,生成一个连贯且准确的回答。这个过程类似于亚历克斯将课本中的知识与自己的理解融合,以写出逻辑清晰的答案。
RAG的这种能力,使其特别适用于处理需要最新信息或复杂背景的动态查询。通过同时依赖外部知识和内在推理,RAG不仅可以回答精确的问题,还能应对更广泛、深层次的内容需求,为用户提供更智能、更可靠的解决方案。
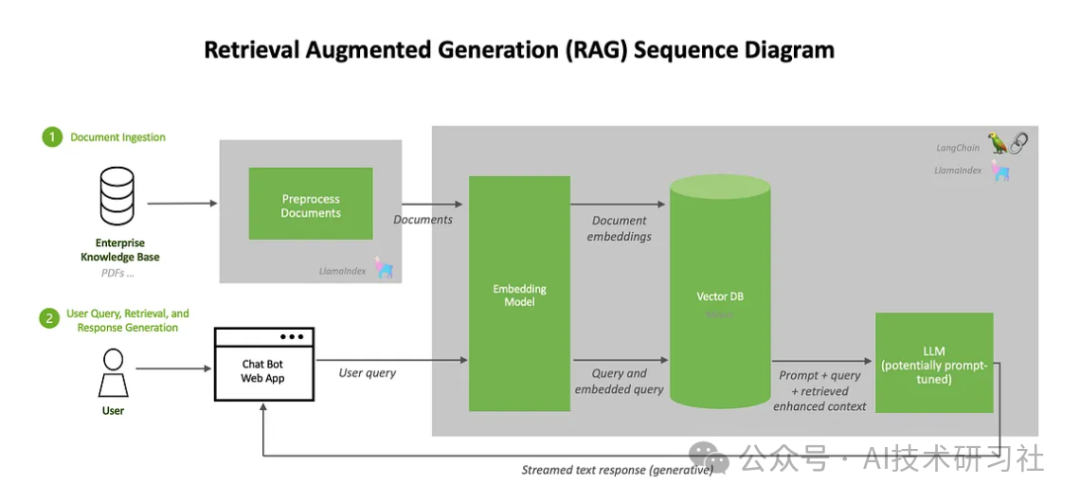
RAG 的工作原理:分解核心组件
检索增强生成(RAG)依赖几个核心组件来高效完成信息的检索和生成。这些组件协同工作,确保 RAG 能够准确理解问题、检索相关信息,并生成连贯的回答。
RAG 的第一个核心是 向量嵌入技术,它用于高效检索信息。向量嵌入是一种将文本转化为数值表示(向量)的方法,根据文本的语义相似性对信息进行组织和匹配。这种方式使得 RAG 能快速找到与问题相关的信息。类似于教科书按章节分类,向量嵌入帮助系统迅速定位关键内容,而无需逐页搜索。当提出一个问题时,RAG 会通过向量嵌入匹配问题与数据库中的相关段落,从而实现高效的信息检索,即使面对庞大的数据量也能快速响应。
第二个核心是 检索模型,其主要任务是从外部来源中定位相关信息。检索模型通过分析问题的语义,与外部知识库、文档集合甚至网络实时检索中找到最相关的内容,同时过滤掉无关的信息。这一步对 RAG 的整体能力至关重要,尤其是在回答关于最新事件或特定领域问题时。例如,用户询问最近的科学发现时,检索模型可以访问科学数据库并提取最新的研究结果,从而让 RAG 提供及时准确的回答。
在完成检索后, 生成模型 接管任务。生成模型将检索到的信息与系统内部固有的知识相结合,生成自然流畅且与上下文相关的回答。这一过程不仅确保回答的内容准确,还让语言表达更加连贯。类似于学生将笔记和课本内容整合成全面的答案,而非直接复制原文,生成模型能够根据检索结果进行推理和扩展,从而为用户提供更有深度的回应。
通过将向量嵌入、检索模型和生成模型紧密结合,RAG 实现了从问题理解到知识获取再到语言生成的完整流程。这种多层次的协作使其能够应对复杂的动态查询,尤其在需要实时更新或专业知识支持的场景中表现尤为出色。
为什么 RAG 很重要:检索增强生成的优势
检索增强生成(RAG)为人工智能的发展带来了重要突破,尤其是在需要提供最新、上下文敏感答案的应用中表现出色。以下是 RAG 的关键优势:
RAG 能够获取最新信息,这是传统模型无法实现的能力。传统模型的知识来源于训练数据,无法应对实时信息的需求,例如当前事件或最新研究成果。这种局限性在信息快速更新的场景中尤为明显。而 RAG 的检索组件能够从外部来源实时获取所需内容,使其在处理经常变化的话题时表现尤为出色。例如,当需要解答最新科技突破或新闻动态时,RAG 能够快速调取相关资料,提供及时且准确的回答。
通过检索相关主题的精确信息,RAG 提高了回答的准确性和相关性。相比完全依赖训练数据的传统模型,RAG 可以根据查询需求动态获取专业内容,特别是在处理复杂或技术性问题时。例如,在解决专业性较强的医学问题时,RAG 可以直接引用相关文献或研究,确保答案更具权威性和针对性。这种结合内在知识与外部数据的能力,使其回答更加符合实际需求。
RAG 的高效内存使用是其另一大优势。传统模型需要记住海量数据,其中很多内容可能在实际应用中很少被使用,而这种“死记硬背”的方式对内存和计算资源的消耗较大。RAG 则避免了这一点。它只在需要时检索相关信息,将计算资源集中在通用知识的管理上,从而优化了内存使用效率。这种按需获取的机制不仅减少了冗余信息的存储,还提升了模型的整体性能。
RAG 还展现了高度的领域适应性。它可以根据特定行业需求,从特定数据库或知识库中检索信息,满足不同领域的专业需求。例如,在医疗领域,RAG 能从医学数据库中提取病例分析或药物研究;在金融领域,它可以获取实时的经济数据或市场动态。这种可定制化能力,使 RAG 能够成为各行业内的高效工具,满足特定场景的知识需求。
综合来看,RAG 不仅突破了传统模型的局限性,还在实时性、准确性、内存使用效率以及领域适应性方面表现出众。其独特的检索与生成结合能力,使其在复杂、多变的实际应用中成为不可或缺的智能系统。
LangChain Memory 结合 LLMs:为聊天机器人赋予记忆能力
在人工智能技术迅速发展的今天,聊天机器人已成为我们日常生活中不可或缺的工具。从解答客户问题到提供个性化服务,这些智能助手覆盖了多种场景。然而,传统聊天机器人面临一个核心限制:它们往往是无状态的,无法记住用户的上下文信息。每次用户的查询都被视为独立交互,而之前的对话内容则被忽略。这种局限性使得对话缺乏连贯性,偶尔显得机械和缺乏人情味。
为了解决这一问题,LangChain Memory 应运而生。作为一种创新的对话记忆解决方案,LangChain Memory 能够让聊天机器人记住过去的交互历史,并利用这些信息生成更贴近用户需求、更自然的回答。通过引入对话记忆,聊天机器人不仅变得更流畅,还能提供个性化和连贯性的对话体验,为用户带来更加贴心的服务。
LangChain Memory 的核心功能在于其模块化和高效的设计,使开发人员能够轻松将其集成到聊天机器人或其他对话代理中。它提供了一个统一的接口,能够管理不同类型的记忆,包括对话缓冲记忆和对话摘要记忆。这种灵活性让开发者可以根据需求轻松存储和检索对话历史,从而优化聊天机器人的性能。
除此之外,LangChain Memory 还具备学习和适应新信息的能力。它能够根据存储的上下文信息,生成更准确和相关的响应。例如,当用户与机器人进行多轮对话时,LangChain Memory 可以通过记住用户的偏好和先前提到的内容,提供更个性化的服务。这种上下文意识让聊天机器人显得更加智能和人性化。
值得一提的是,LangChain Memory 可以与多种语言模型(LLMs)无缝集成,包括预训练模型如 GPT-3、ChatGPT,以及自定义模型。开发人员可以根据具体需求选择合适的语言模型,并结合 LangChain Memory 的记忆功能,打造反应迅速、体验出色的聊天系统。
通过结合 Streamlit 和 OpenAI GPT API,LangChain Memory 的潜力进一步被放大。开发者可以利用 Streamlit 构建友好的前端界面,并通过 GPT API 提供强大的语言生成能力。这种结合不仅让聊天机器人更智能,还为开发人员提供了一个高效的开发框架,快速实现从基础对话到复杂互动的全流程体验。
LangChain Memory 的出现,为解决传统聊天机器人“无状态”这一痛点提供了突破性方案。它不仅提升了对话的连贯性和自然性,还大幅拓展了聊天机器人的应用边界。未来,随着更多技术的融合,聊天机器人将以更智能、更人性化的姿态,为用户提供更加优质的服务体验。
pip install langchainpip install openaiimport os os.environ['OPENAI_API_KEY'] = "your-openai-api-key"from langchain.llms import OpenAIfrom langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemoryconversation_with_memory = ConversationChain(llm=OpenAI(temperature=0,openai_api_key=os.getenv("OPENAI_API_KEY")), memory=ConversationBufferMemory(), verbose=True)
conversation_with_memory.predict(input="你好,我是Kevin") conversation_with_memory.predict(input="我是一个人工智能爱好者,喜欢通过公众号分享人工智能领域相关的知识") conversation_with_memory.predict(input="我希望你能用我的名字为我的公众号设计一个专业名称") conversation_with_memory.predict(input="你还可以给出更多选项吗")
在 LangChain 中,链通常用于分解任务,由链接组成。Lang Chain提供了 ConversationChain,它是专门为有一些记忆概念的场景而创建的。创建类的实例时ConversationChain,必须提供三个参数:
llm,指定用于生成响应的语言模型;
memory,它确定用于存储对话历史记录的内存类型;
verbose,控制通话过程中是否打印提示等信息。

































 粤ICP备17114055号
粤ICP备17114055号