推荐语
掌握Embedding模型选型技巧,提升知识库与RAG准确率上限。
核心内容:
1. 嵌入模型与向量模型的核心概念解析
2. 全球模型性能全景对比分析
3. MTEB基准下各模型参数与得分情况
杨芳贤
53A创始人/腾讯云(TVP)最具价值专家
一、核心概念解析
1.1 嵌入模型(Embedding)
作为AI领域的核心基础技术,嵌入模型通过将非结构化数据映射为低维稠密向量,实现语义特征的深度捕捉:
- 文本嵌入:如将语句转换为1536维向量,使"机器学习"与"深度学习"的向量余弦相似度达0.92
- 跨模态嵌入:支持图像与文本的联合向量空间映射,如CLIP模型实现文图互搜
1.2 向量模型(Vector Model)
作为嵌入技术的下游应用体系,主要包含两大方向:
- 判别式模型:基于SVM/神经网络的分类器(情感分析准确率可达92.3%)
- 检索式模型:利用向量相似度计算(如Faiss索引加速)实现毫秒级语义搜索
二、主流模型性能全景对比
2.1 全球模型排行榜(MTEB基准)
参考地址:MTEB Leaderboard - a Hugging Face Space by mteb
| | | | | | | | | | | | | | | | |
|---|
| gemini-embedding-exp-03-07 | | | | | | | | | | | | | | | |
| | | | | | | | | | | | | | | | |
| | | | | | | | | | | | | | | | |
| multilingual-e5-large-instruct | | | | | | | | | | | | | | | |
| | | | | | | | | | | | | | | | |
| | | | | | | | | | | | | | | | |
| text-multilingual-embedding-002 | | | | | | | | | | | | | | | |
| | | | | | | | | | | | | | | | |
| | | | | | | | | | | | | | | | |
| Cohere-embed-multilingual-v3.0 | | | | | | | | | | | | | | | |
| | | | | | | | | | | | | | | | |
| bilingual-embedding-large | | | | | | | | | | | | | | | |
| | | | | | | | | | | | | | | | |
| | | | | | | | | | | | | | | | |
| jasper_en_vision_language_v1 | | | | | | | | | | | | | | | |
| | | | | | | | | | | | | | | | |
| | | | | | | | | | | | | | | | |
| Solon-embeddings-large-0.1 | | | | | | | | | | | | | | | |
| KaLM-embedding-multilingual-mini-v1 | | | | | | | | | | | | | | | |
| | | | | | | | | | | | | | | | |
2.2 细分领域冠军模型
中文场景TOP3
- BGE-M3:支持8192长文本,金融领域语义相似度达87.2%
- M3E-base:轻量级模型推理速度达2300 QPS
- Ernie-3.0:百度知识图谱融合模型,摘要生成ROUGE-L值72.1
跨语言模型TOP3
- BGE-M3:支持108种语言混合检索,跨语言映射准确率82.3%
- Nomic-ai:8192 tokens长文本处理能力,合同解析效率提升40%
- Jina-v2:512维轻量化设计,边缘设备内存占用<800MB
2.3 企业级选型策略
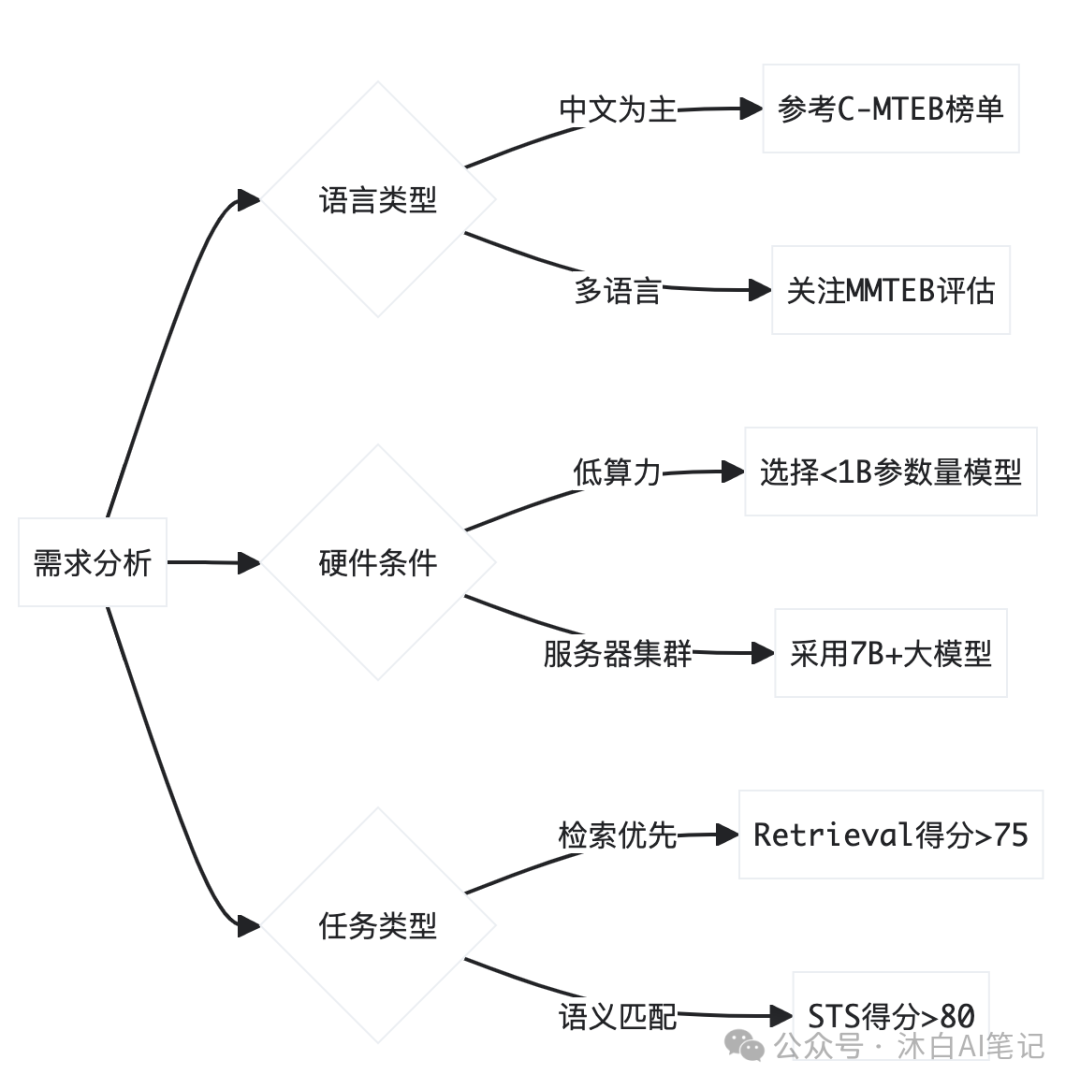
三、技术架构创新趋势
3.1 动态维度输出技术
- Matryoshka嵌套向量:通过训练模型输出256-1792维的灵活向量(如BGE-M3模型),实现不同精度需求的按需裁剪,资源利用率提升40%
- 稀疏注意力机制:NV-Embed采用潜在注意力层替代传统均值池化,使关键语义捕获效率提升58%
3.2 跨模态统一空间构建
- 多模态对齐架构:CLIP-like模型(如阿里云M6)实现文本-图像-音频的联合嵌入,医疗影像报告分析准确率提升至89%
- 层次化表征学习:分层编码器将对象拆解为原子特征(颜色/形状/纹理),支持组合式生成(如AI绘画中的风格迁移)
3.3 上下文理解增强
- 双向时序建模:在Transformer架构中引入时间戳嵌入,实现动态上下文感知(如金融合同版本差异识别)
- 因果推理嵌入:通过因果图网络构建因果向量空间,解决传统相似度计算的逻辑谬误问题

































 粤ICP备17114055号
粤ICP备17114055号