本文作者用一个GPT4o学习全栈的例子来阐述大模型对学习的影响,以及对于未来学习的思考。
大模型是否会取代人类,以及它将取代哪些工作,这或许是许多人焦虑的问题。对此,众说纷纭,网络上各种观点层出不穷。虽然这些问题对未来的重要性不容忽视,但它们对于当下的我们缺少实际的指导意义。因此,我们不妨暂时将这些问题放在一边,转而关注那些对当前,以及可见的未来都有实际影响的问题。那么,什么是有影响的问题呢?我认为我们应该关注如何运用大模型。这一观点可能会被一些人所不屑。自古以来,我们对‘器’和‘术’的轻视,往往导致我们忽略了工具的重要性。事实上,工具的作用是至关重要的,在没有马镫之前,骑兵的优势并不明显,只是冲锋那一下而已。但是有了马镫之后,骑兵可以在奔劳的时候保持平衡,从而更精准地射箭和使用长矛。这个细微的变化让骑兵在战场上具备了更大的机动性和战术灵活性,极大地提升了他们的战斗力。在今天,我认为大模型在生产力和学习上都会带来深刻的变革,尤其是在学习方面。接下来,我以一个用GPT4o学习全栈的例子来阐述一下大模型对学习的影响,以及对于未来学习的思考。
我开始设定一个目标,即期望在一天内搭建一个前端项目,理解其核心代码,并实现一个需求变更。
首先,我试图向ChatGPT询问一些学习路径。它的回答显得比较机械化,与网上的答案相差不大。实践周期也较长,无法让我满意。
我意识到,我的Prompt写得有问题,我需要给GPT更明确的背景和要求,所以我重新编写了一版Prompt。
角色:前端技术专家
背景:Java开发工程师,有不错的编程基础,也有一些前端基础,比如HTML,CSS和JavaScript基础
任务:根据上下文中提到的,根据目前的技术水平和学习时间,帮助完善前端学习路径,学习路径如下:1、开启一个Helloworld项目2、学习基础语法3、学习框架React4、项目进化,实现一个待办事项功能
要求:1、Helloworld项目要使用React技术,给出Helloworld的实现步骤,包括环境搭建,使用命令行,以及每个命令的解释2、基础语法要提供ES6的一些基础语法概念,以及这些语法概念的解释3、列举React的一些基础概念,以及这些基本概念的解释4、基于React,给出核心实现代码,以及实现代码的解释
这次GPT的回答结构更清晰,更实用,也更符合预期。
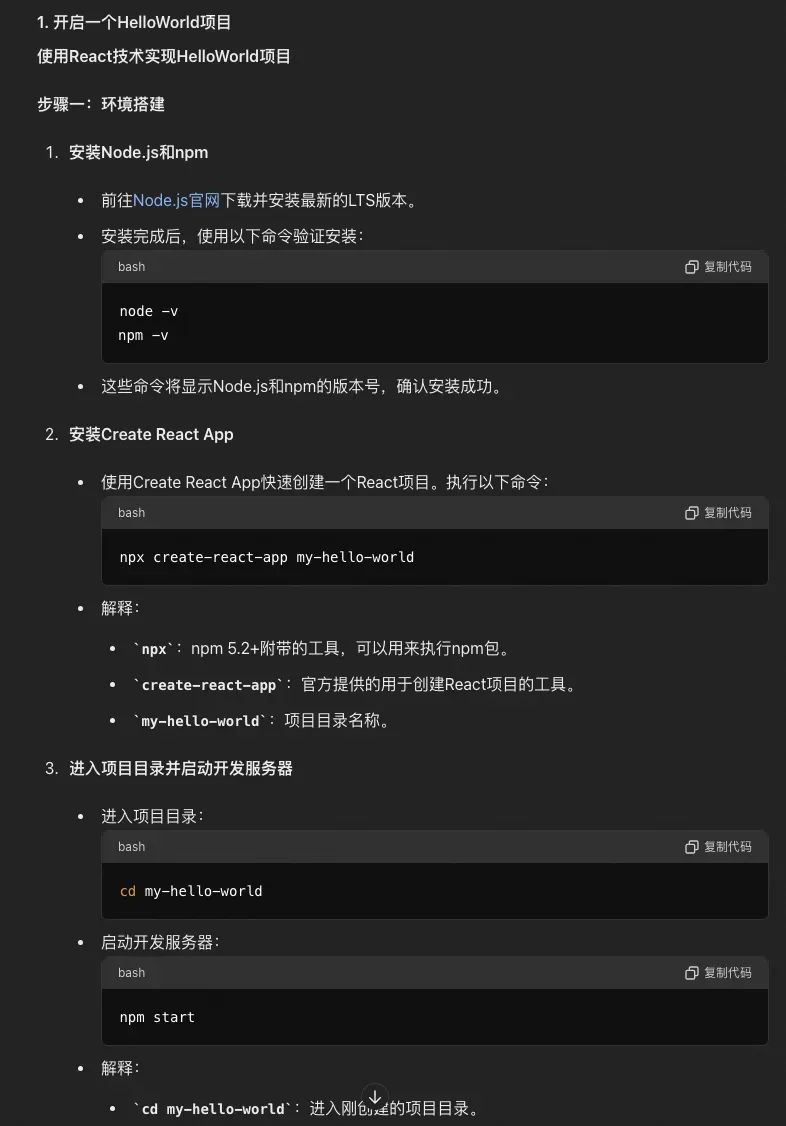
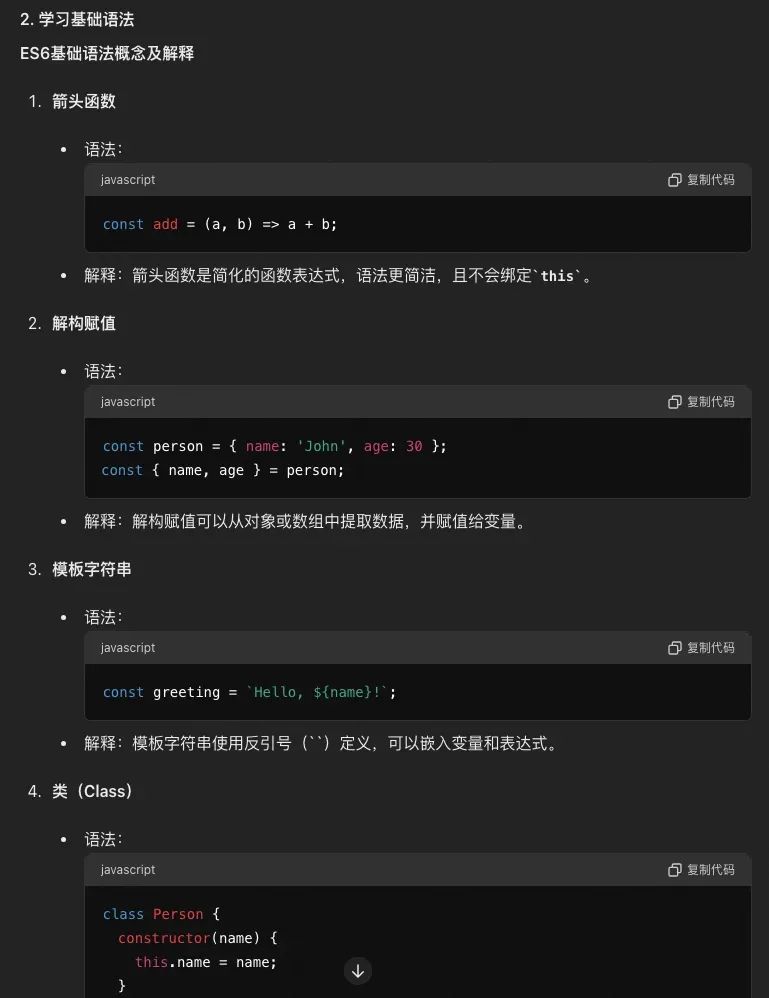
详细的步骤,请参考:
https://chatgpt.com/share/f0b61434-3302-4140-88a9-b64fe8ae986e
这一步比较容易出现问题,我们让GPT给出更详细的步骤。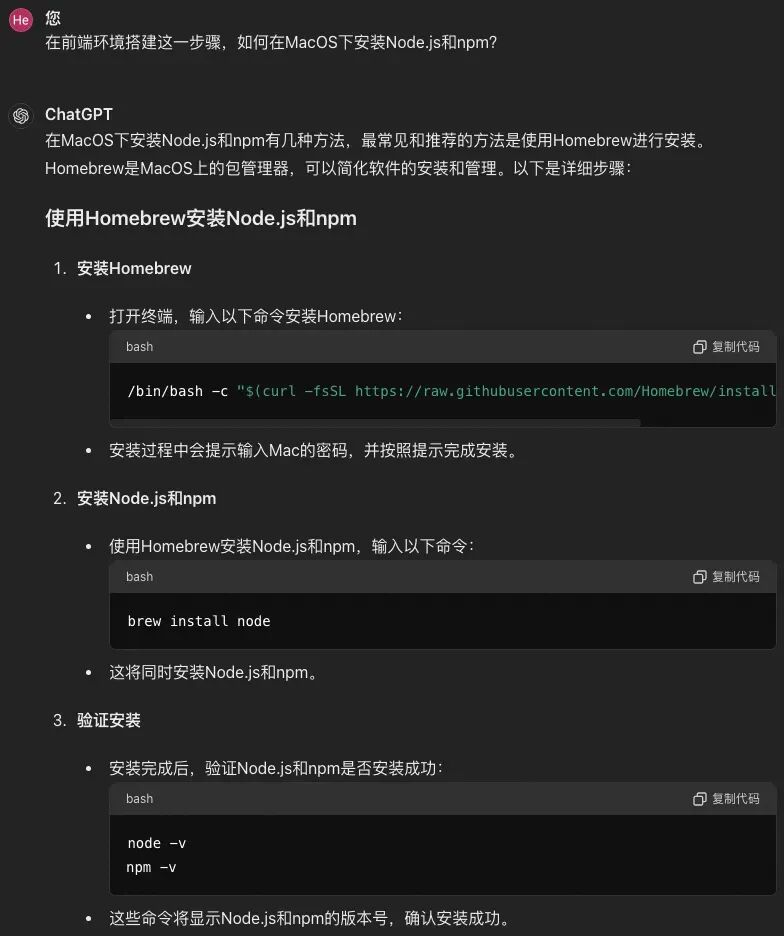 非常nice,GPT给出了可执行的步骤~ 同时它也给出了其他可选项(使用nvm安装)
非常nice,GPT给出了可执行的步骤~ 同时它也给出了其他可选项(使用nvm安装)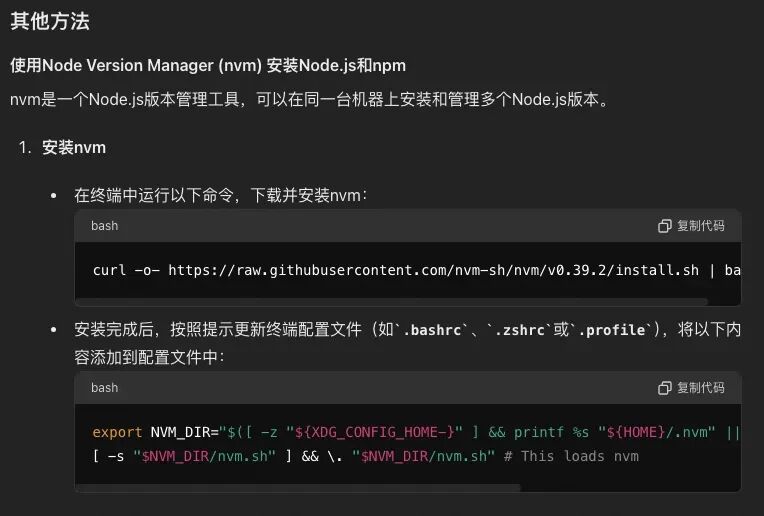 如果我们想进一步理解nvm,可以接着追问,这里不再赘述。首先,按照HelloWorld(GPT答案中提供的案例)创建项目,并确保能够正常启动。然后,将TodoApp的代码复制到HelloWorld项目中,直接执行即可。如遇到编译或执行问题,可直接向GPT提问,GPT通常能解决这类问题。
如果我们想进一步理解nvm,可以接着追问,这里不再赘述。首先,按照HelloWorld(GPT答案中提供的案例)创建项目,并确保能够正常启动。然后,将TodoApp的代码复制到HelloWorld项目中,直接执行即可。如遇到编译或执行问题,可直接向GPT提问,GPT通常能解决这类问题。
首先,各种“乱七八糟”的符号,变量和函数超级多的定义和赋值方式。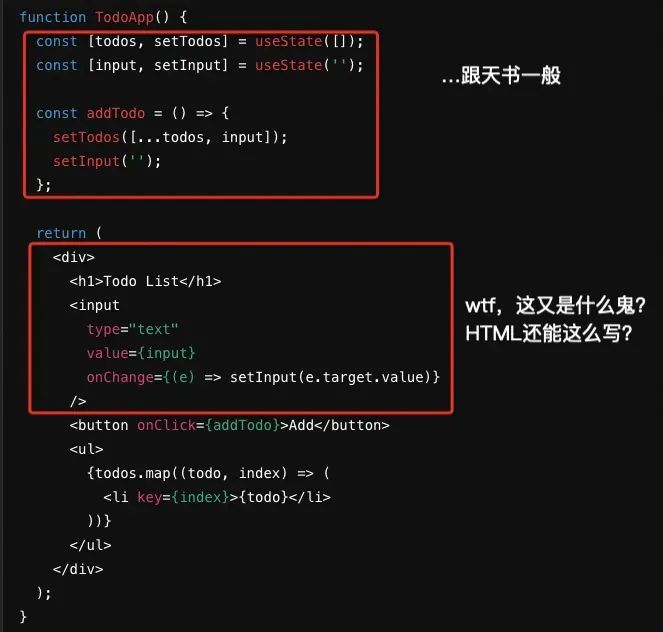 其次,前端框架(如React)的概念理解,例如什么是生命周期,什么又是状态(state)。
其次,前端框架(如React)的概念理解,例如什么是生命周期,什么又是状态(state)。
搞定糟心的符号
对于无法理解的语法const [todos, setTodos] = useState([]);,让我们交给GPT来解释。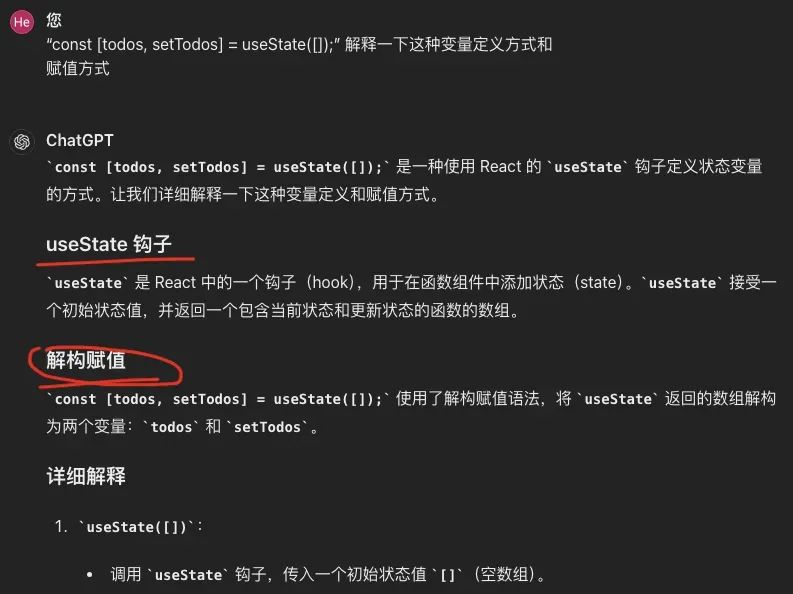 不先考虑表达式右边的useState,我们看一下左边的部分。GPT只解释了[todos, setTodos]是“解构赋值”。那么,我们进一步追问const是什么。
不先考虑表达式右边的useState,我们看一下左边的部分。GPT只解释了[todos, setTodos]是“解构赋值”。那么,我们进一步追问const是什么。 好的,我们现在大概了解了const是用来定义常量的,特别是它的“不可重新赋值”的特性。这是否与Java的final关键字非常相似?让我们让GPT进行一下对比。
好的,我们现在大概了解了const是用来定义常量的,特别是它的“不可重新赋值”的特性。这是否与Java的final关键字非常相似?让我们让GPT进行一下对比。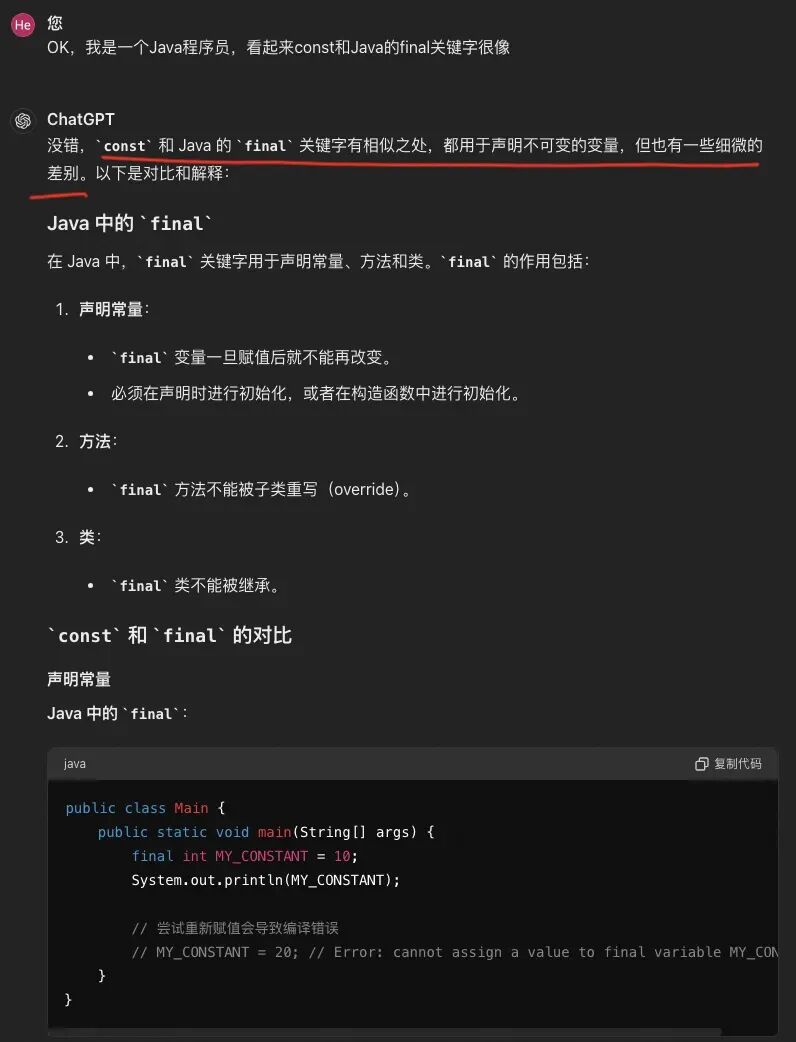
难以理解的概念
我们以组件生命周期为例,来看如何利用GPT理解这一概念。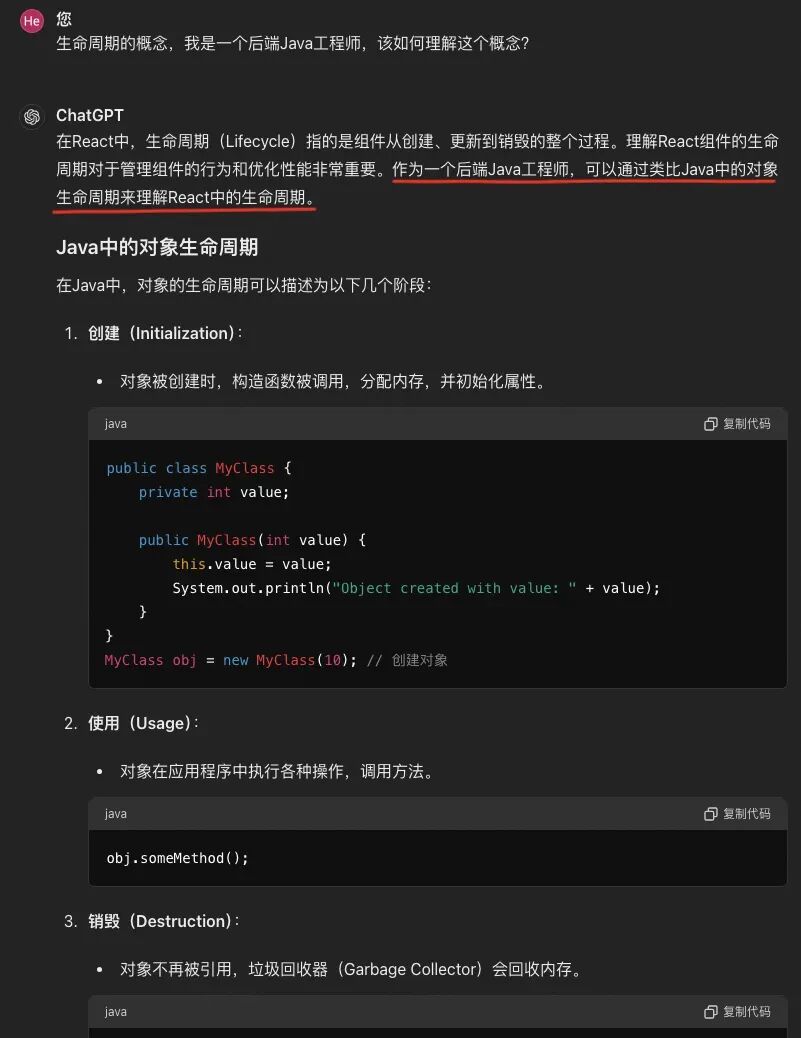 被惊艳到了?,GPT用到了”类比“的方式帮助我们理解生命周期的概念。对于自己理解上不太确定的点,同样可以向GPT提问。
被惊艳到了?,GPT用到了”类比“的方式帮助我们理解生命周期的概念。对于自己理解上不太确定的点,同样可以向GPT提问。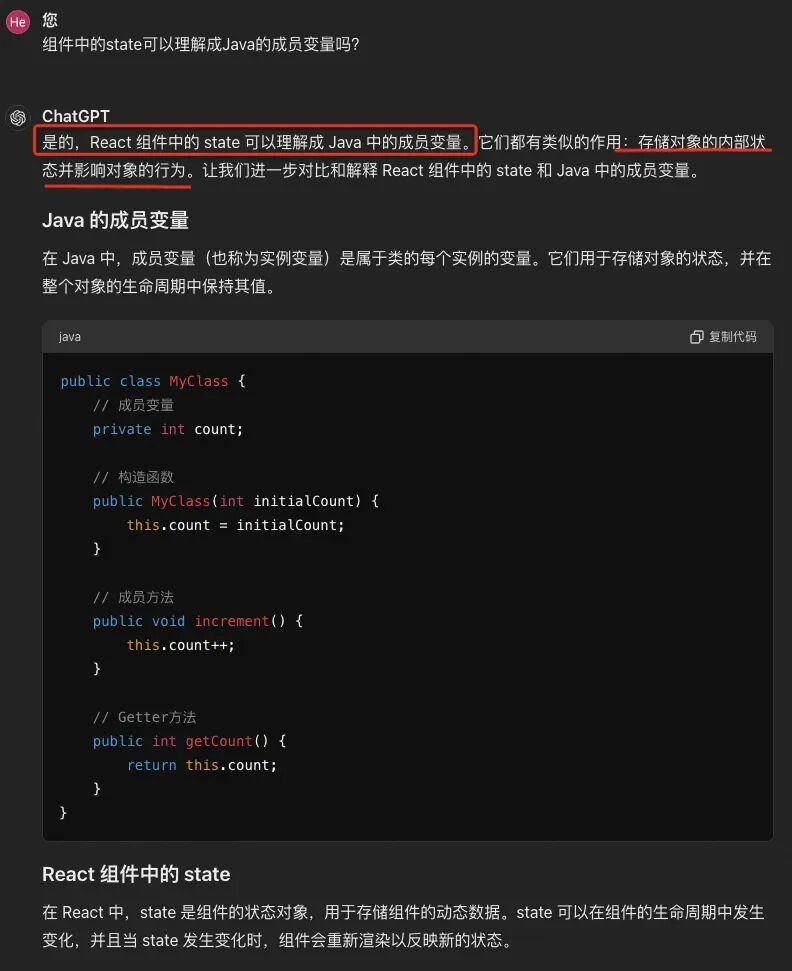 以上,我们已经基本入门了全栈开发,并且运行了项目。整体来看,我们大概花了2-3个小时,这比预期的一天要快得多。下面,让我们暂时忘记GPT的神奇,回到文章的初衷,重新思考GPT为学习带来的变革。
以上,我们已经基本入门了全栈开发,并且运行了项目。整体来看,我们大概花了2-3个小时,这比预期的一天要快得多。下面,让我们暂时忘记GPT的神奇,回到文章的初衷,重新思考GPT为学习带来的变革。
学习是一个复杂而多阶段的过程,每个阶段都有其独特的特点和目标。我们可以将学习过程分为以下几个阶段:1.接触(Exposure):学习的起点。首先,我们需要注意新的信息、知识或技能,并对其产生兴趣。
2.收集(Gathering):系统地广泛地获取更多相关的信息和资源,以便更全面地理解新知识或技能。
3.理解(Understanding):指将所收集的信息进行消化、分析和综合,以便形成对新知识或技能的全面认识。
4.记忆(Memorization):涉及将理解的知识或技能存储在长期记忆中,以便将来可以方便地检索和应用。知识的理解程度对记忆的影响非常大。
5.应用(Application):指将所学的知识或技能在实际情境中加以运用,以解决问题或完成任务。
6.反馈(Feedback):根据应用的结果和他人的评价,反思和改进学习方法和策略。
众所周知,学习过程中最耗费精力的是收集资料。寻找资料源、筛选高质量资料、系统化组织资料,这些任务不仅耗时费力,而且结果往往不尽如人意。在理解知识的过程中,我们需要大量的阅读、训练和思考。由于缺乏系统指导,学习者常常感到困惑和迷茫。长周期的学习需要及时反馈。比如,学习一门新的编程语言,从基本语法开始逐步掌握,可能需要一到两个月才能开始实际操作项目。这么长的学习周期可能让我们失去目标感,增加中途放弃的风险,最终可能感到挫败。在学习过程中,缺乏足够的动力、信息过载、容易陷入单调重复、缺乏实践应用场景、反馈时间过长或无法得到反馈等都是障碍。这些问题都可能导致人们放弃学习。因此,我们常常看到失败的学习案例,而成功有效的学习案例则寥寥无几。
通过上述演示,我们可以看到大型模型在各个学习环节中都能提供巨大的帮助,甚至在某些方面产生颠覆性的影响,这些影响能够提高学习成功的几率。在资源收集方面,传统的模式(主要是搜索)需要在许多来源中收集。 在此基础上还需要进一步做筛选和判断,这将消耗大量的精力。
我们都知道,理解是形成长期记忆的关键,而通过知识的类比和迁移来理解新知识是一种有效的方法。然而,建立类比和迁移这座连接新旧知识的桥梁并不容易。这不仅需要学习者理解新的概念,还需要将这些概念与已有的知识结构相结合,以便在新的情境中使用。如果对新概念理解不足,或者旧知识基础薄弱,就无法建立这种联系。大型模型在我们理解知识的过程中带来了新的启示,它具备非常强的知识类比能力。大模型以Java工程师的角度解释了如何理解React组件生命周期。它通过类比Java类的生命周期来讲解React组件,这个方法非常有效。我相信只有既熟悉前端又熟悉后端的人才能如此解释,而GPT的回答如此自然。同样,当我们尝试用类比(如将state与Java的成员变量进行比较)来理解新知识时,它会给我们提供更丰富的建议,更深入的解释,以及更多样的案例。反馈对于学习的重要性,毋庸再言。在这一阶段,大模型同样展现出强大的能力。
学习是反人性的,人类也并不擅长学习,重要的原因是学习过程充满未知,可预期性差。尽管人类天生好奇,但遗憾的是这种好奇心并不能维持很长时间。聪明的教育者会运用各种技巧来提升学习的可预期性(更明确的奖赏),以尽可能地延长好奇心的持续时间。提升反馈效率不仅表面上会提升效率,同时也会提升学习的可预期性,可能大模型会使学习这件事情不那么反人性。
在此基础上还需要进一步做筛选和判断,这将消耗大量的精力。
我们都知道,理解是形成长期记忆的关键,而通过知识的类比和迁移来理解新知识是一种有效的方法。然而,建立类比和迁移这座连接新旧知识的桥梁并不容易。这不仅需要学习者理解新的概念,还需要将这些概念与已有的知识结构相结合,以便在新的情境中使用。如果对新概念理解不足,或者旧知识基础薄弱,就无法建立这种联系。大型模型在我们理解知识的过程中带来了新的启示,它具备非常强的知识类比能力。大模型以Java工程师的角度解释了如何理解React组件生命周期。它通过类比Java类的生命周期来讲解React组件,这个方法非常有效。我相信只有既熟悉前端又熟悉后端的人才能如此解释,而GPT的回答如此自然。同样,当我们尝试用类比(如将state与Java的成员变量进行比较)来理解新知识时,它会给我们提供更丰富的建议,更深入的解释,以及更多样的案例。反馈对于学习的重要性,毋庸再言。在这一阶段,大模型同样展现出强大的能力。
学习是反人性的,人类也并不擅长学习,重要的原因是学习过程充满未知,可预期性差。尽管人类天生好奇,但遗憾的是这种好奇心并不能维持很长时间。聪明的教育者会运用各种技巧来提升学习的可预期性(更明确的奖赏),以尽可能地延长好奇心的持续时间。提升反馈效率不仅表面上会提升效率,同时也会提升学习的可预期性,可能大模型会使学习这件事情不那么反人性。
多年前就有人提出了一个类似的问题:“在现代社会,为什么我们需要记忆呢?我们可以在几秒钟内通过互联网查找到任何需要的事实性信息。”这并不是大数据模型时代特有的问题。我认为,我们仍然需要学习,并应该利用大数据模型来加速学习进程。首先,知识是思考的基础,没有知识就无法谈论分析能力或批判性思维等高级能力。许多人认为思考过程类似于计算器的功能,计算器具有一系列的函数(如加法、乘法等),这些函数可以应用于任何数据。它的数据和函数是完全分开的。因此,一旦学习了新的函数,就可以处理所有的数字。然而,人类的思考方式并非如此,至少对大多数人来说,功能(模型)和数据是无法完全分离的。例如,我们能够批判性地思考欧洲地缘政治如何导致第二次世界大战,并不意味着我们也能批判性地思 考中东当前的局势。再比如,我们知道在使用金字塔模型进行分类时,应确保每个分类之间既无重叠也无遗漏。然而,即使我们在某个领域成功实现了这一点,但在仅仅理解模型的情况下,并不能保证在另一个领域也能做到无重无漏。其次,通过知识的学习,可以提高我们的记忆力。我们把人脑分成工作记忆和长期记忆,工作记忆的空间是有限的,它的上限决定了我们的推理能力。这一点其实也很容易理解,当我们涉足到非常专业的领域时,会遇到大量的专有名词。例如,在营销运营领域,我们会遇到像“招选搭投”、“盘货池”这样的专有名词。这些名词都包含大量的背景知识。如果我们不清楚这些知识,我们根本是无法讨论问题(判断、推理、分析、决策等)的。让我们想象一下,在不熟悉背景知识的情况下,我们如何探讨“直接将盘货池暴露给搭建页面是否合理?”时,首先,我要解释一下什么是盘货池,它是根据特定的商品指标规则圈选的商品集合。然后,我会介绍什么是搭建,在这一通输出之后,估计大家的脑子已经炸了。可是,我们还没有开始讨论真正有意义的内容。发散一下:这种情况是不是跟当今的大模型所遇到的困境非常像?实际上,我们可以通过学习知识来解决这个问题。我们可以将知识压缩成一小块一小块,然后存入长期记忆中。当我们需要时,可以随时调取。例如,当我提到"盘货池"这个概念,我们的脑海中立刻会想到"按指标圈选的商品集合"。而且,我们还可以联想到更多,例如它的存储形式,它在数据流向中的位置等等。我们能联想到的内容完全取决于我们的大脑中存储了多少信息。这样,我们就大大节省了工作记忆空间,从而变相地突破了工作记忆空间的限制。另外,学习知识还能更容易地触发长期记忆,也就是说,学得越多,记忆力越好。由于篇幅原因,我就不再详细说明这一点了。
前面,花了大量的篇幅在论证,我们要不要学习,接下来,我们阐述一下,应该怎么学习。与机器赛跑,仅仅靠技能型学习是不够的
模型最擅长的是什么?显然,大型模型在重复型技能学习方面表现出色。无论是对某种模式的判断,还是执行某些套路化的动作,模型都能高效而准确地完成。在这些领域,人类难以与大模型竞争。令人沮丧的是,这些技能我们并不能抛弃,并且他们非常重要。就像篮球运动员必须具备扎实的基本功,才能完成复杂的动作一样,基本技能是我们掌握高级能力的基础。没有这些基本技能,任何高层次的应用和创新都无从谈起。然而,在这个时代,仅仅依赖这些基本技能是不够的。面对“与机器赛跑”的挑战,我们需要培养更高等级的能力,如分析、判断、决策和创新。这些能力能够让我们在与大模型的竞争中脱颖而出。未来也不全是坏事儿,值得高兴的是,在大模型的加持下,技能型学习过程将显著加快,从而提高这一阶段的学习效率。通过高度整合的、定制化的知识,提供多样化的案例,并及时给予学习者反馈,学习者可以更快地掌握基本技能。这不仅节省了大量的时间和精力,同时也使我们能够将更多的资源投入到更高层次的分析、判断和创新中,促进整体学习效果的提升。要从技能型学习到专家型学习的转变
专家型学习这个概念不太容易定义,首先解释一下什么是专家能力,以帮助大家理解什么是专家型学习。当专家面对一个问题时,他们首先会运用概念框架来锚定问题的类型。例如,在处理一个需要在多个服务器之间共享数据的系统时,专家首先会锚定这是一个分布式问题,然后再进一步锚定是分布式当中数据一致性的问题,其后才会着手解决数据如何在不同节点之间实现一致。这一点或许有些抽象。专家不仅能应用概念模型,还能在复杂情境中看清楚各方关系和角色。比如,在设计复杂的软件系统时,专家能识别核心服务和辅助服务,理解它们如何协同工作,并优化接口和数据流。他们能预见扩展系统时的挑战,并提前设计解决方案。再次,专家具备扎实的基础知识,并能够顺畅地提取和运用这些知识。扎实的基础是专家型学习的基石。假设一个人连基本的概念都无法理解,就无法指望他能深入分析和解决问题。那么,什么是专家型学习,或者换句话说,如何通过学习达到专家能力?扎实的基础知识是专家型学习的第一步,这一步是可以通过系统的学习和反复练习来实现的。然而,令人沮丧的是,后续的高级能力——如分析能力、系统化思维、批判性思维、决策和创新等——并不能通过简单的学习获得。这些高级能力需要大量实践来培养,我相信阿里的“借事修人”的理念,但是这首先需要我们“躬身入局”。具体来说,主动承担有挑战性的任务,尝试跨领域学习和应用,迫使自己运用高级能力;持续反思和总结经验,改进策略,不断输出,寻求反馈;这样才有可能将高级能力内化为自己的技能。软实力从来没有变得像今天那么重要
在现今社会,许多技术性的任务可能被机器取代,但判断和决策仍然需要人来完成。因此,在可预见的未来,软实力(沟通能力、同理心、逆商、团队精神、领导力等)的重要性将变得更为突出,比以往任何时候都更为关键。本方案为您介绍如何使用云效将项目代码部署到云服务器ECS,快速完成一个企业门户网站的开发和部署。欢迎点击阅读原文查看详情。

































 粤ICP备17114055号
粤ICP备17114055号