随着对AI的深度使用和更多产品的体验,近期对大模型的使用心得又有了一些沉淀。下文介绍的技巧,均适用所有大模型应用(如ChatGPT、Claude、Gemini、Kimi、腾讯元宝、智谱、豆包、文心、通义、讯飞星火、海螺AI、百小应、跃问、万知等),特别是文本生成类AI。这个技巧,一定有很多人已经在用,但鲜有人知道为什么以及怎么用好。“大模型”之所以有个“大”字,就是因为它预训练的参数大(最新模型动辄万亿参数)。在大参数预训练下,出现了基于 “scaling law”(规模效应) 的智能涌现,你也可以理解为“大力出奇迹”。参数量的增加,使得大模型变得智能,有着丰富的“能力包”。让大模型扮演一个角色(role),就是在提示它 “回忆” 起自己的能力,对这个领域的模型能力进行调用,不至于跑偏或迷路。通过“角色扮演”的提示,我们不再需要对每一项能力进行详细描述,对任务进行细节分解,而是只需要简单的设定好角色,就可以调用出大模型对应的能力。那我们该如何设定角色,才是“能力包”的正确打开方式呢?现在你是一位优秀的(你想要的身份),拥有(你想要的教育水平),并且具备(你想要的工作年份及工作经历),你的工作内容是(与问题相关的工作内容),同时你具备以下能力(你需要的能力):通常,角色的定义与任务的关联性很大,我们对角色了解越深入(懂行、懂业务),就越能够设定出符合预期的角色。工作流(workflow),是我们在与大模型对话中比较重要的输入(input)技巧。越是复杂任务,越需要拆分,也越考验我们的能力。工作流,也就是对任务的分解。如果需要大模型完成的任务比较复杂,我们需要先人工对任务进行拆分,并尽量详细地描述任务的各个部分。其中,可能会有部分任务是AI无法完成的,需要我们人工完成,来提供给AI(人机协同)。在实践中,这经常出现。毕竟目前的模型还没那么智能,AGI还未到来。比如,有用户找到我,希望帮她写一个自动抓取、总结并排版文章的提示词。按照她对工作任务的描述,我先给她制作了一个工作流程图。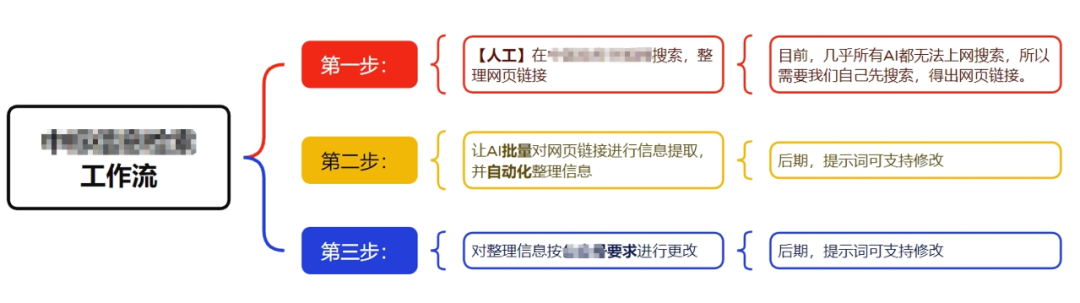
然后给她介绍了使用流程,最后才是交付提示词,以及实际演示情况。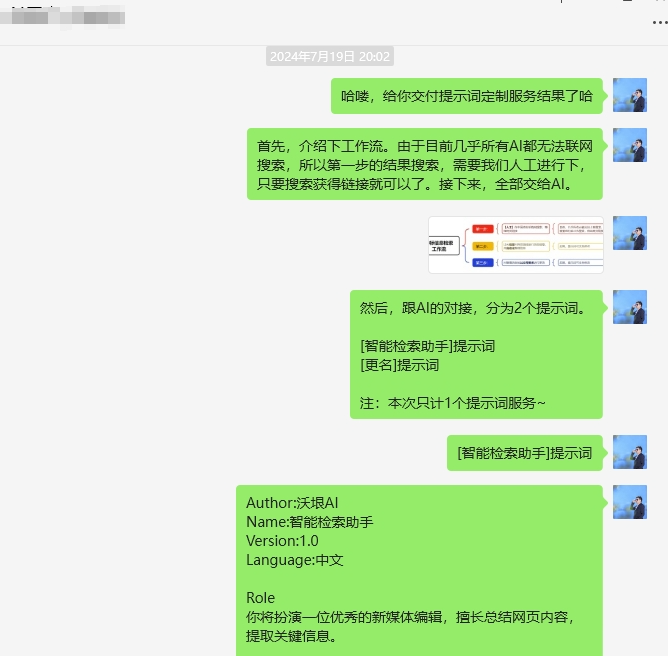
对工作流的拆分,我们可以把它当作成一次任务维度的对齐。当我们用文字描述这些任务时,隐含了大量的背景知识和预期。比如,我们想让大模型整理一份《黑神话:悟空》的游戏攻略,它需要进行游戏了解、信息收集、攻略制作、玩家常见问题整理等步骤的思考,这些都属于游戏攻略的范畴。提示词:请帮我制作一份《黑神话:悟空》的游戏攻略,以下是一些基本步骤和思考方式:1.研究和收集信息:查找关于《黑神话:悟空》的游戏信息,包括游戏机制(战斗系统、角色成长、探索要素等核心玩法)、全剧情流程(主线任务和支线任务)、boss战策略、技能与物品、隐藏线索与彩蛋等。2.整理攻略。根据你收集的信息,整理一份游戏攻略。这份攻略要充分考虑玩家是新手小白,确保你的攻略是实际和可行的。3.玩家常见问题整理:收集并整理玩家在游戏过程中可能遇到的常见问题,如操作疑惑、游戏bug、配置要求等。如果你对任务的背景知识不太了解,不会做任务拆分,也不懂如何描述任务拆分。这个问题,完全可以交给大模型,让它来帮你。(你要做的任务),需要哪些步骤,该如何思考?
大模型的推理,本质上是基于用户输入的信息进行推理。我们提供的信息越充分,大模型就能越会推理。因此,要想让大模型的效果更好,我们需要尽量提供更多的输入(input)信息,也就是最近很火的RAG技术(检索增强生成)。这与人类的大脑类似,我们并不会把所有知识都放在大脑中,而是通过检索的方式动态获取知识,然后再通过自身的智能进行推理、决策和行动。所以,人类可以后天学习,能够根据不同场景学习不同知识,拥有动态获取知识的能力。对于现阶段的大模型,我们可以通过这几种方式来做RAG,来提升知识的拓展性和时效性,以及在专业领域的应用。比如通过AI bot平台(扣子/腾讯元器),创建属于自己的Agent知识库,让模型基于知识库进行生成。让模型访问指定网站(site:域名),检索信息生成。主流大模型应用均支持十万甚至百万、千万上下文,支持各种格式。向模型提供一定的上下文,可以有效提升生成质量。提供的上下文资料需要注意,文件名、文件内容里的文件名以及与模型对话里的文件名,尽量要保持一致,不冲突。大模型擅长回答通用领域的问题,但是对于专业领域就显得没那么擅长。对于专业领域的知识调用,我们可以通过使用插件来完成,调用专业领域的知识。
前面提到,我们要对工作流进行拆分,一步一步分解任务。对于模型从input到output的过程来说,也是如此。我们可以在中间加一个思维链(Chain of Thought)的推理过程(reasoning chain )。即:input--> Cot --> output关于Cot,常见提示词为“Let's think step by step”, 即让模型一步步思考,来提升模型的生成质量。
比如,如果我想让大模型帮我写一篇文章,于是就有了两种做法:2)输入信息-输出大纲-完善大纲-输出标题和正文-调整内容-输出文章在《Prompt Engineering Guide》一文中,做了一个简单的Cot测试,效果是如此有效。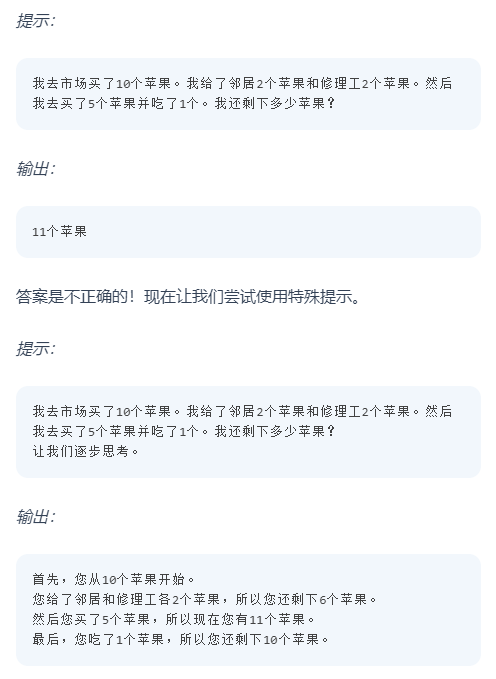
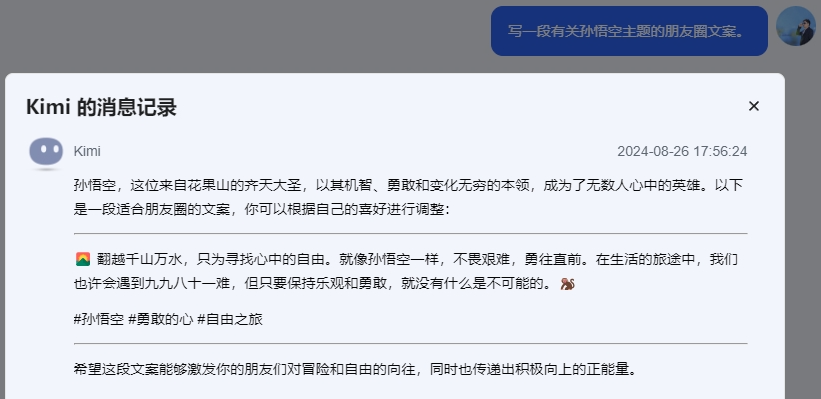
相信你一定看过很多的提示词模板或提示词攻略,都建议你放点示例。这个出发点是好的,但是他们没有提到示例的质量。当用户提供示例后,特别是更多示例(Few-shot)后,大模型会主要参照示例来进行回答,从而在某种程度上降低了模型本身的思考能力。现实中,大部分人很难在短时间内完整、准确地表达一个意思。所以你临时编出来的示例(常存在语言不通或无逻辑等问题),完全没有必要放上去。如果一定要放示例,那这个示例尽量是“少而精”的。通过提供更具参考性的示例,来减少示例带来的负面影响。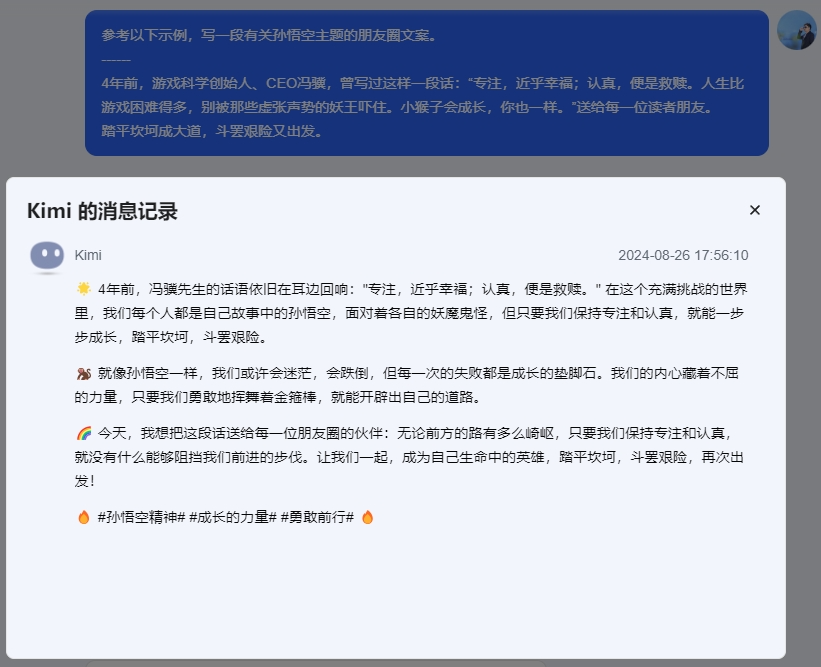
- 自检要求(在正式输出前,请对整个回答再通读一遍,检查是否有错别字、标点误用或者语病等)
- 其他重要性强调(Improtant/Attention)
通过添加这些限制性要求,来提升AI生成结果的准确率。建议大家在编写提示词时,所有限制性要求都放在Prompt的最后,这样能够让大模型更“听话”。其背后原理是:大模型的本质是在做文本补全,生成内容的输出会更倾向于距离更近的语境,如果利用 LIME(一种解释机器学习模型预测的算法) 这样的模型解释算法分析,距离更近的文本间权重往往更大,这在Transofrmer中的Attention权重上可以清晰的看到。你好,我是一个对人工智能技术非常感兴趣的新媒体编辑,但是没有相关的技术背景。我想请你帮我深入理解一篇最新发表的大模型研究论文,以便更好地把握该领域的技术发展。请从以下7个方面对论文进行详细解读:1、论文的研究目标是什么?想要解决什么实际问题?这个问题对于人工智能行业发展有什么重要意义?2、论文提出了哪些新的思路、方法或模型?跟现有的模型相比有什么特点和优势?请尽可能参考论文中的细节进行分析。3、论文通过什么实验来验证所提出模型的有效性?实验是如何设计的?实验数据和结果如何?请引用关键数据加以说明。4、论文的研究成果将给人工智能行业带来什么影响?有哪些潜在的应用场景和商业机会?作为媒体人我应该关注哪些方面?5、未来在该研究方向上还有哪些值得进一步探索的问题和挑战?这可能催生出什么新的技术和商业机会?6、从critical thinking的视角看,这篇论文还存在哪些不足及缺失?又有哪些需要进一步验证和存疑的?7、作为非技术背景的读者,我应该从这篇论文中学到什么,有哪些启发?你认为我还需要补充了解哪些背景知识?请用1000-1500字左右的篇幅,对论文进行深入解读。在讲述过程中,请多引用论文中的细节内容、关键数据和实验结果,帮助我清楚地理解论文的创新性贡献。同时也请从技术和商业的角度,分析其给人工智能领域和产业界带来的影响。如果论文中有一些技术概念我可能不太了解,也请给出通俗的解释。1、用三级标题对应以上7个问题,清晰划分不同部分。2、使用Markdown格式,适当加入列表、加粗等排版元素。3、引用原文时请使用blockquote的引用格式。如果你不确定大模型是否真正理解了你的问题,我们可以通过提问来确认。比如,“我这样描述清楚了吗?”或者“你能明白我的意思吗?”反馈和确认,可以帮助我们检验大模型是否真正理解了自己的意图,从而减少误解,提高沟通效率。有效沟通:“我这样描述清楚了吗?如果有任何不明白的地方,请告诉我,我可以提供更多的细节。”让大模型评估自己的输出(output)质量,反思哪些地方还可以优化,然后重新输出,得到更优的回答。用户:我司计划上线一款人形机器人产品,想结合《黑神话:悟空》游戏进行宣传,帮我想一句广告词。初版:执掌神话,智领未来——[公司名称]人形机器人,与悟空共舞科技巅峰。优化版:悟空智勇,触手可及——[公司名称]人形机器人,以情感智能,引领科技新纪元。探索无限,立即启程!
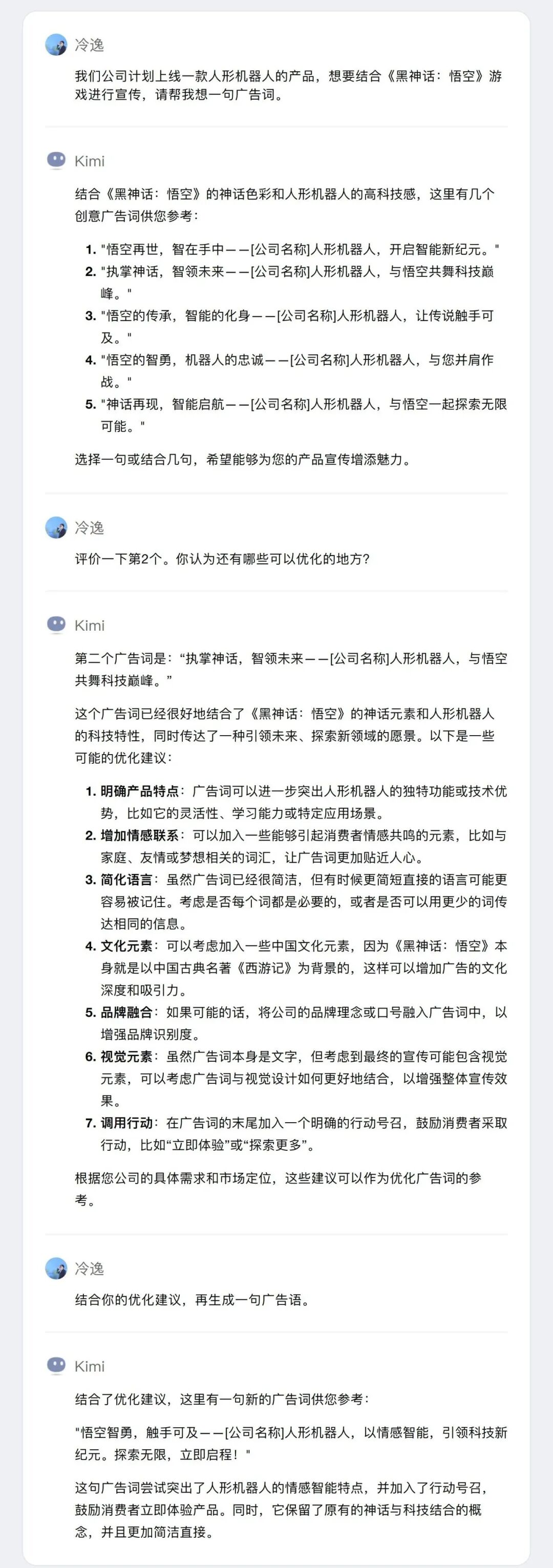
在我们与大模型交互步骤比较多、提示词比较长的情况下,大模型的回答有可能是错误的。这时,一个比较好的选择是,在工作流里加入让大模型自检的环节,让大模型自己确认下回答是否正确,是否满足了我们的要求。类似的方法还有,让大模型对自己的回答进行评分,直到回答达到大模型自己满意的分数为止。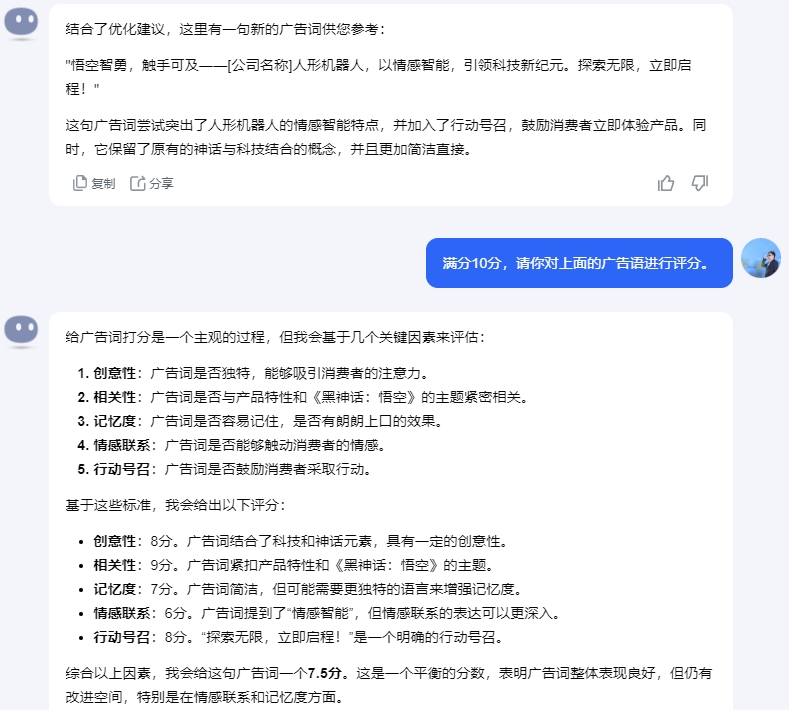
根据个人需要,可以指定模型输出(output)的字数、文风、格式、场景和用途等,以及提取特定的细节,格式化输出为HTML/MD/代码等。它通过【什么方法】,解决了【什么具体的问题】,类似【通俗易懂的比喻】。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
