导读 随着大数据技术的迅猛发展,传统 BI(商业智能)产品已经逐步向智能化方向转型。从最初的报表式分析到自助式分析,再到如今的智能化 BI,数据分析正迎来更加高效、精准的变革。尤其是在行业内部,智能化改造正在加速推进,不仅关注提升 AI 能力,更注重 AI 能力的复用和跨平台的灵活适配。本次分享将深入探讨腾讯在智能化 BI 系统中的技术实践,详细阐述如何通过工程架构、微调模型、引导补全、前端指令层设计等手段,提升数据分析的智能化水平,并展示如何应对上述挑战,以实现更高效、更智能的商业智能分析。
今天的介绍会围绕以下六点展开:1. 背景介绍
2. 目标与挑战
3. 架构演进
4. 重点模块设计
5. 未来规划
6. 问答环节
分享嘉宾|霍琦 腾讯 资深研发工程师
编辑整理|陈思永
内容校对|李瑶
出品社区|DataFun
1. 背景与现状:
- 大数据领域进入智能化阶段,BI 产品从传统的报表式、到自助式,现已发展为智能化BI。
- 腾讯内部推动智能化改造,注重提升智能化能力,并推动能力复用。其中工程侧是 OlaChat 落地的框架是充分释放 AI+Data 能力的底座
2. 遇到的问题:
- 架构不清晰:快速迭代导致架构耦合,AI能力难以在不同平台上复用。
- 单个 agent 设计复杂:集成了太多业务属性,导致扩展性差。
- 大语言模型的实现难度大:包括上下文管理、长文本记忆、幻觉等,导致自然语言到数据指令转换过程复杂。
目标与挑战

1. 目标与解决方案:
- 架构统一:方案统一、能灵活适应不同产品和数据场景。
- 用户体验优化:从工程架构视角,提升 Agent 智能化应用体验的响应速度和准确性效果。
- 集成 AI 能力:ABI 技术方案收敛和统一,Agent 能力快速迭代,灵活交付。
2. 面临的挑战:
- AI 能力原子化:如何做到低成本、快速迭代的 AI 能力。
- 长文本与响应速度问题:模型幻觉和响应延迟影响效果。
- 自然语言到 BI 指令的准确性与效率:如何降低复杂度,提高准确率,并简化工程实现。
架构演进
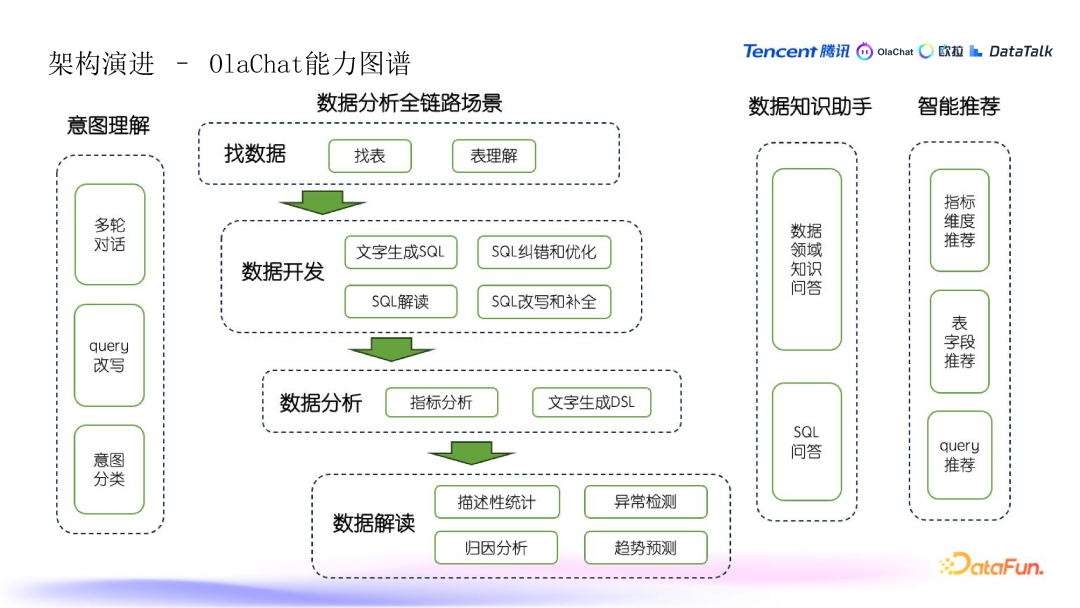
1. OlaChat 概述:
- OlaChat 是一款基于大语言模型的智能数据助手,能够灵活集成到各种数据分析产品中,提供原生的 AI 数据体验。
2. 数据全链路分析能力:
- 意图理解:包括多轮对话、Query 改写、意图分类和意图识别。
- 数据开发:文字生成 SQL、SQL 纠错优化,改写解读等。端到端分析:指标分析、文字生成 DSL(动态查询条件)等。
- 数据解读:描述性统计、异常检测、归因分析和趋势预测等。
3. 知识&推荐:
- 数据知识助手:为新手和不熟悉数据平台的用户提供词汇解释和问答功能,帮助理解数据概念和数据开发。
- 指标维度推荐:推荐相关的分析维度,帮助用户做深度数据分析。表字段推荐:根据用户行为和数据热度推荐常用表字段,提升数据查询效率。Query 推荐:引导用户通过问答,帮助其完成完整的数据分析任务,并提供相关问题或分析推荐。
4. OlaChat 落地思路:
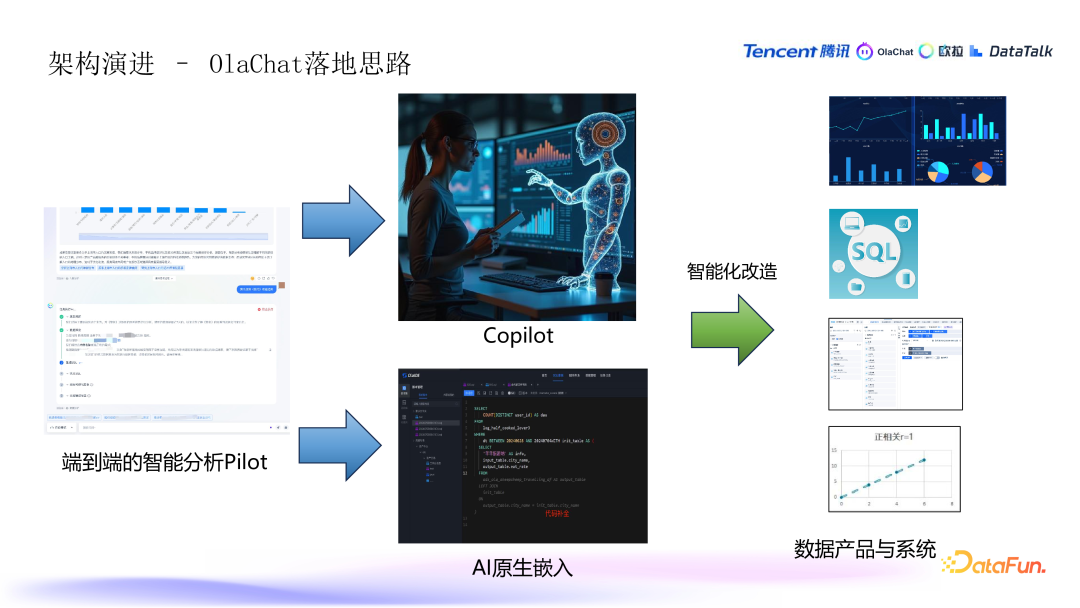
- 初期尝试使用大屏展示和对话流式展示方式,用户提问后展示思考过程和分析结果。这种方式主要适合数据分析和数据运营人员,但并非适用于所有用户。
- 在数据探索阶段,需要与多平台的数据进行交互,因此逐渐引入了“Copilot”和“AI 组件原生嵌入”的形式。将 AI 助手和组件嵌入到不同的数据产品和系统中(例如图表分析、拖拽式自助分析、解读和归因等),使用户在不改变现有数据使用习惯的基础上提升效率,完成数据产品的智能化改造。
5. OlaChat 技术框架
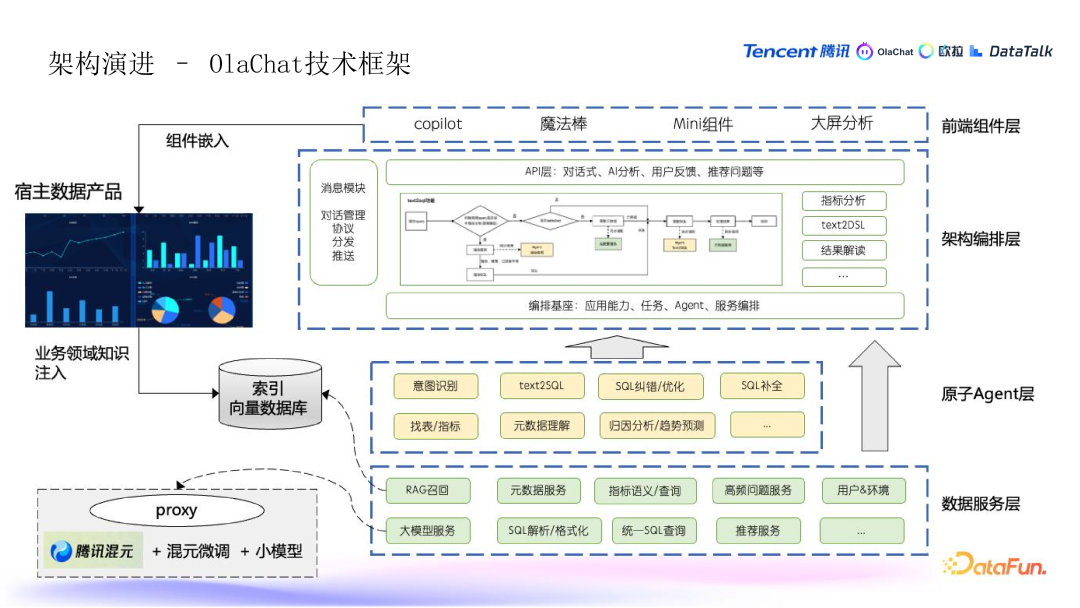
- 前端组件层:包括 copilot(助手功能)、魔法棒、输入模块,以及大屏分析等。
- 架构编排层:负责将原子级的 agent 能力(从用户输入到操作再到输出)进行拆分和编排,适配不同的数据场景。包括数据操作指令和服务的编排,同时结合消息模块进行对话式协议的流式分发和推送。
- 原子 agent 层:将各种 AI 能力(如意图识别、Text2SQL、数据解读等)拆解成更小的原子操作,进行组合和优化。
- 数据服务层:除了传统 BI 分析的数据处理能力(SQL 查询、元数据服务等)外,还包括 ABI(智能 BI)和大模型相关的服务,如数据领域知识的 RAG、高频 query、上下文理解等
- 使用腾讯的混元大模型(作为通用大模型),并根据具体业务需求(如 SQL 领域)对模型进行微调,以及机器学习模型。
- OlaChat 与宿主的数据产品集成,通过前端组件和 API 方式嵌入,同时将领域知识(如数据指标、维度等)和用户行为数据集成到召回库中,用于提升推荐和分析效果。
重点模块设计
1. 编排层 - 单 Agent 多 step
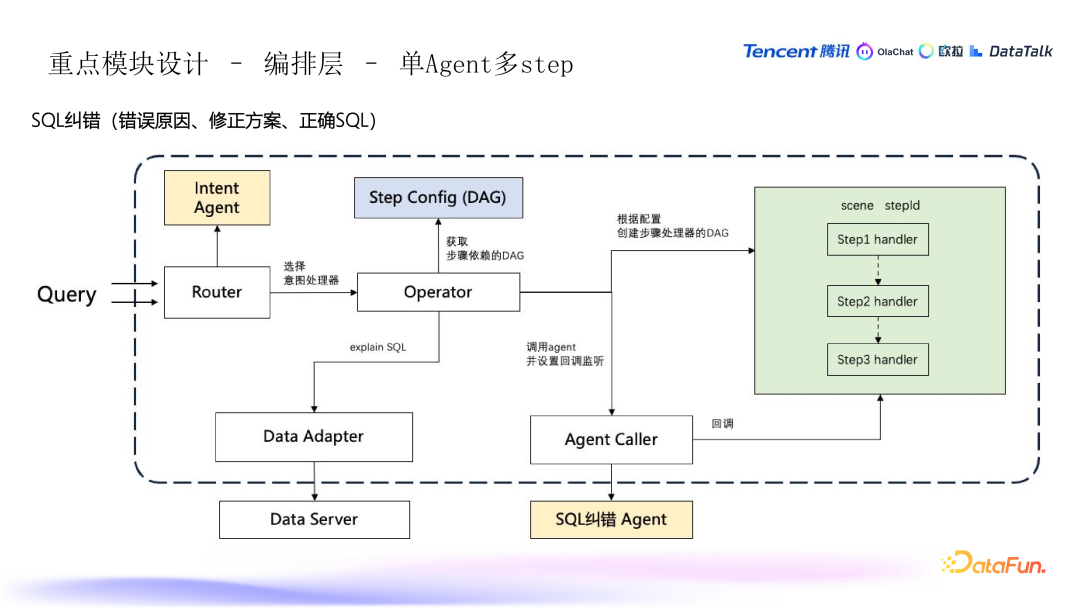
用户输入 SQL 语句后,SQL 纠错按步骤纠错:
- 第一步:系统首先告知用户 SQL 语句的错误原因(如权限问题、数据表字段错误等)。
- 第二步:系统提供修正建议,指出可能的错误来源,如函数使用不当或语法问题,并给出修改方法。
- 第三步:最终,系统提供一个正确的 SQL 语句供用户参考和使用。
- 用户输入:用户输入一个 SQL 语句,提交给系统进行分析。
- 意图识别:系统通过意图识别模块判断输入的意图,例如判断用户是否在进行 SQL 纠错操作。
- 编排层(DAG 图):通过配置的 DAG(有向无环图)编排,系统逐步执行纠错的过程。编排层会定义每个步骤的执行顺序,并在过程中异步处理不同子模块的返回结果(如数据服务层、SQL 解释层等)。
- 数据服务层:如果 SQL 未执行,系统会先进行数据解释(EXPLAIN),检查 SQL 可能的问题,提升纠错的准确性。
- Agent 调用:编排层将调用 SQL 纠错 agent,返回用户修正建议和最终正确的 SQL。
- 顺序执行与回调:系统通过编排层确保返回结果的顺序,虽然不同场景下返回的结果顺序可能有所不同,但编排层会按照配置的步骤顺序处理每个结果。
- 并行与串行:虽然流程一般是串行的,但也可以设计为并行返回,提升系统吞吐能力,适应不同业务场景。
2. 编排层 - 多 Agent 协作
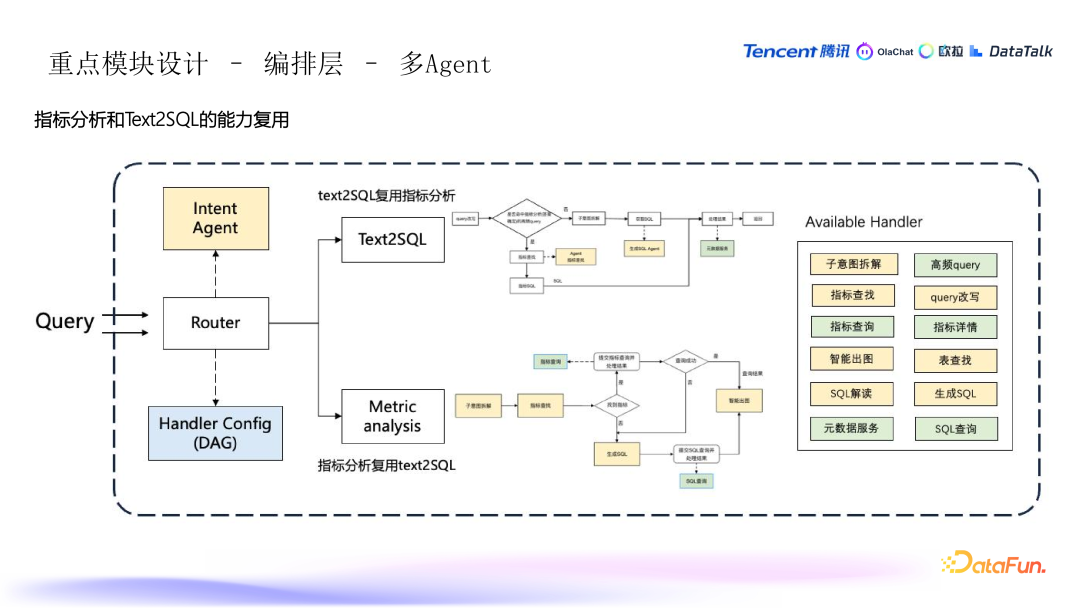
- 指标分析:用户提出一个问题,系统从中提取出涉及的指标、维度和过滤条件,最终通过这些组合来提交指标查询,获取数据。
- 文本生成 SQL:当用户提出问题时,系统会判断该问题是否命中指标的高频查询。如果是,直接返回指标预定义的 SQL;如果不是,则通过 Test2SQL 流程生成 SQL。
- 多个原子 Agent:流程中包含多个原子 Agent,分别负责不同任务,例如:
- DAG 图编排:系统通过编排 DAG(有向无环图)来协调不同 Agent 的工作步骤,确保按顺序执行并处理数据。
- 预定义查询:如果用户的查询已经是系统处理过的常见查询(标注过的高频查询),则直接返回该查询的 SQL,减少计算和延迟。
- 动态生成 SQL:如果查询是新问题,则通过文字生成 SQL 的流程,系统依赖拆解和生成 SQL 的逻辑来处理,确保生成正确的查询。
- 统一语义层:在指标分析中,通过指标的统一语义层,确保不同数据源下的指标定义一致。
- 数据源可用性:系统会检查指标对应的数据源是否可用,若不可用,则降级处理,使用其他离线数据源查询。
- 降级处理:如果在指标查询中未能找到有效指标,系统会降级到 Test2SQL 的逻辑,走标准的查询流程。对于某些在线数据源,系统使用同步查询;对于其他数据源,则采用异步查询。
3. 编排层 - 统一协议与自动化编排

- 统一协议:所有的 handler(处理单元)在输入输出时遵循统一协议,包括通用部分和特定参数的设计。响应处理也是基于这种协议。通过统一协议,agent 与 agent 之间能够在编排框架中自动流转,无需硬编码逻辑,从而简化了流程的自动化。
- 编排流转:当所有的 handler 和 operator 的协议对接成功后,整个编排流程就能够顺利进行。编排过程更加灵活,能够自动调用不同的 agent 并处理数据,避免了传统编程中强依赖和硬编码的复杂性。
4. 编排层 - 人工干预
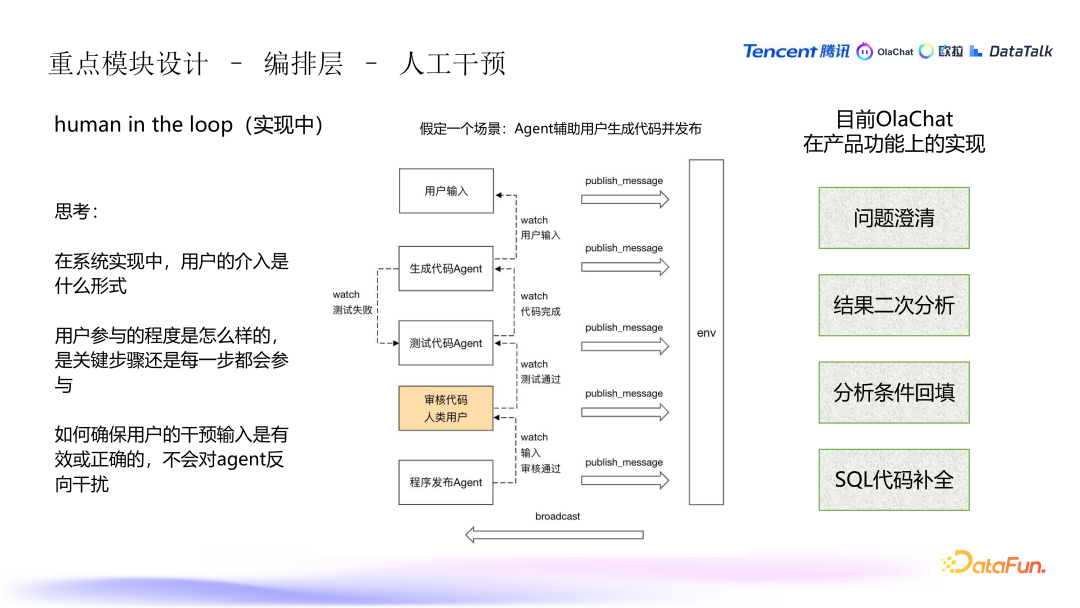
- 干预流程:在某些关键步骤中,人工干预是不可避免的。例如,假定有这样一个场景,在生成代码并提交测试发布,如果测试失败,则回到生成代码的环节直到测试通过。审核过程需要人工介入,只有审核通过后才能发布程序。
- 伪装为 Agent 的输入:人工输入被设计成类似 agent 的角色,遵循与其他 agent 相同的输入输出协议。这样,在人工干预的环节,依然能够与编排流程保持一致,确保整体流程的连贯性。
- 控制输入的有效性:每个 agent 都有输入控制环节(preCheck),可以判断和限制用户输入是否符合预期,决定是否继续执行下一步。若输入不符合预期,可能会被拦截,避免对流程造成干扰。
- 意图理解与澄清:用户的输入可能会不清晰或含糊,系统在意图识别后提供问题澄清,确保分析的准确性。
- 二次分析与修改:用户在数据分析过程中可以基于初步结果做二次分析,或修改已经生成的分析条件。比如,生成的报表或看板中的指标维度可以供用户做进一步修改。
- SQL 补全:用户在写 SQL 代码时,可以获得类似 GitHub 补全的功能,系统会建议补全的 SQL 代码,用户可以选择接受建议,或继续手动修改 SQL。
5. Agent 提升 - 对话上下文
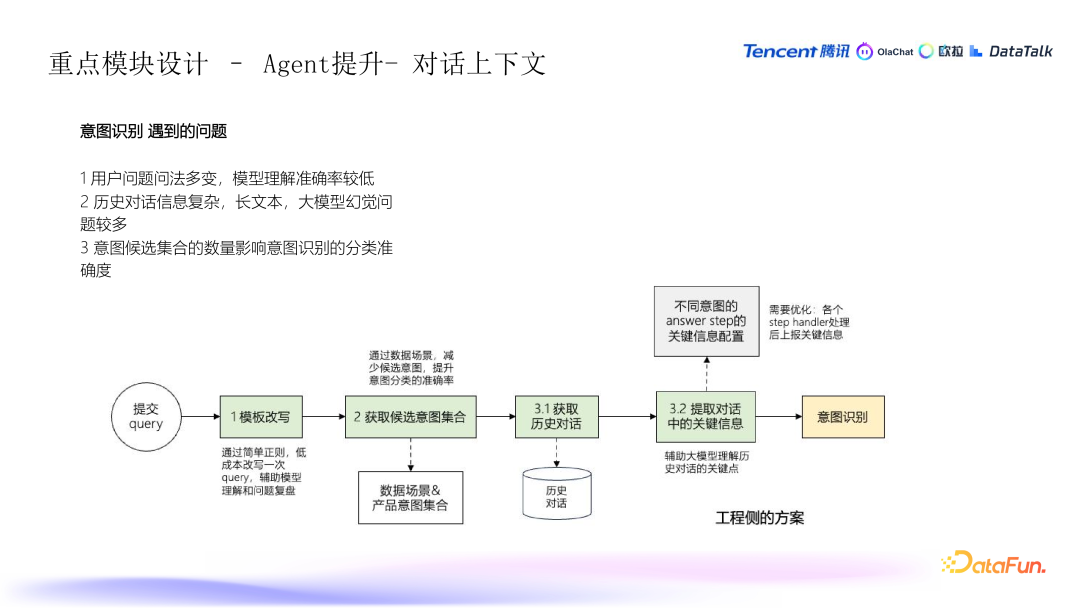
意图识别的挑战
- 用户的多样性问法:用户提问时常用的语言比较随意,可能有各种不同的表达方式,这使得意图识别变得更加复杂。
- 历史信息的复杂性:在多轮对话中,随着信息的不断积累,历史对话的长度和复杂度也逐渐增加。大量的历史信息可能带来问题,例如长文本问题和 Token 限制(每次对话的字符数限制),这些会影响模型的处理能力。同时,这也容易导致幻觉问题,模型返回与实际情况不符的信息。
减少意图候选的复杂性
- 精简意图类别:为了提高意图识别的准确性,可以通过减少可能的意图类别来简化模型的判断范围。这样可以避免分类过多导致的误判,并提高分类的准确度。
- 场景导向的意图识别:在不同的数据分析场景中,系统需要告知用户可能的操作意图。例如,用户可能需要执行的任务包括编写 SQL 语句、查找数据表、或者解读分析结果等。根据场景来指导意图识别,可以有效缩小识别范围。
意图辅助理解
- 简化问题和意图改写:对于一些模糊或者复杂的用户提问,系统可以通过正则和其他处理手段进行问题改写,将问题转化为更简洁和标准的形式,从而提高意图识别的准确度,并作出快速反应。
历史对话信息的提取与优化
- 从历史对话中提取关键信息:多轮对话中的信息量很大,系统会通过不同的 agent(处理单元)将关键的、有效的信息从历史对话中提取出来。这样做可以帮助精简历史信息,避免无关数据对后续操作造成干扰。
- 减少无效信息:每个 agent 在响应用户请求时,会分析返回的历史信息,过滤掉无效的部分,只保留关键信息。这一过程通过编排和工程优化来实现,帮助系统处理更简洁的数据,从而减少幻觉问题,确保后续对话和决策更加准确。
优化后的效果
- 通过精简意图候选集、优化正则匹配、以及提取关键信息,系统能够减少无效信息的干扰,增强意图识别的准确性。这不仅提升了模型的效率,也有效降低了长文本、Token 限制和幻觉问题对系统性能的影响。
6. Agent 提升 - Text2SQL 落地的准确性
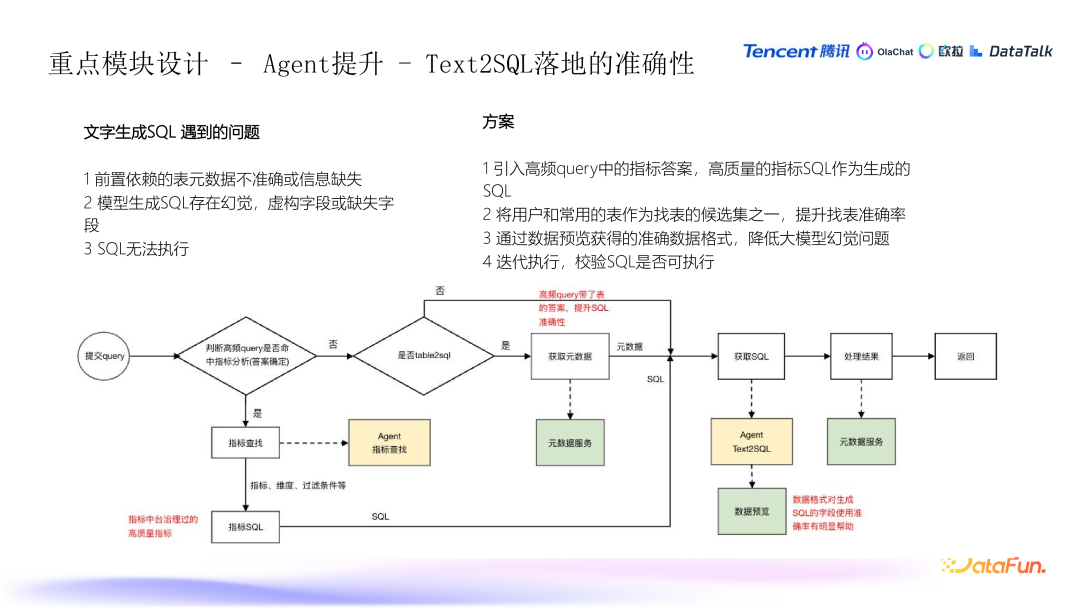
自然语言到 SQL 的生成问题
- 元数据不准确或缺失:如果元数据存在问题,如数据不准确或缺失,生成的 SQL 可能会出错。
- 幻觉问题:生成的 SQL 可能包含虚构字段、缺失字段,或者生成的 SQL 存在语法错误等问题,导致无法执行。
- 杜撰字段问题:生成的 SQL 中可能包含不相关的或不适用的字段,导致 SQL 执行出错。
方案设计:高频查询与候选集的优化
- 高频查询中的指标答案:为了提高准确性,可以从高频的查询中提取已经验证过的高质量指标,用来作为生成 SQL 时的参考。这些指标生成的 SQL 具有更高的准确性。
- 常用表的候选集:在查找表时,系统会使用用户常用的表和字段作为候选集。这些表和字段被认为是用户最常操作的,因此在生成 SQL 时,系统会优先考虑它们。
- 数据预览和抽样:在生成 SQL 时,可以对数据进行格式查询和抽样,确保字段类型(例如日期格式)被正确识别,避免因数据格式问题导致错误的判断。
迭代执行与 SQL 可执行性校验
- 生成后校验 SQL 的可执行性:在生成 SQL 之后,系统会对 SQL 进行校验,确保其可执行。如果生成的 SQL 无法执行,系统会回到生成阶段,进行调整,直到生成有效的 SQL。
7. Agent 提升 - Text2DSL(拖曳分析条件)
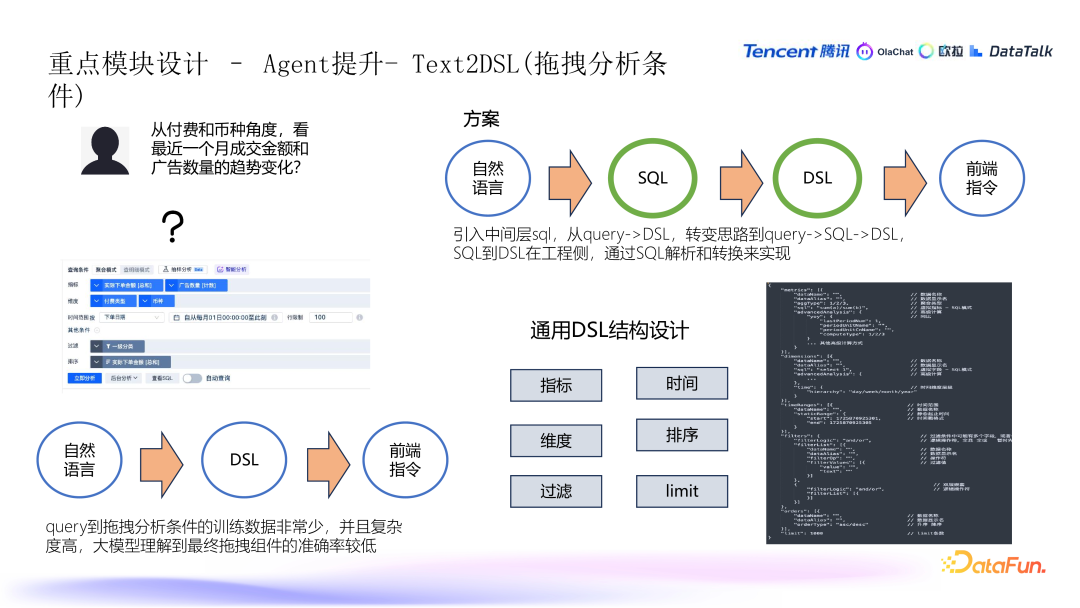
DSL 转换问题与解决方案
- 自然语言到 DSL 的转换困难:自然语言到 DSL 的转换存在一定的难度,尤其是对于拖拽分析条件的理解。DSL(Domain Specific Language)是一个协议语言,用于描述数据分析条件,通常包括指标、维度、过滤条件、时间范围等。
- 解决方案:引入中间层:为了解决自然语言到 DSL 的直接转换困难,系统引入了 SQL(中间层)。这个中间层将自然语言转化为 SQL,再从 SQL 转换为 DSL,最后将 DSL 转换为前端指令,便于用户在数据分析工具中进行查询。
SQL 到 DSL 的转换流程
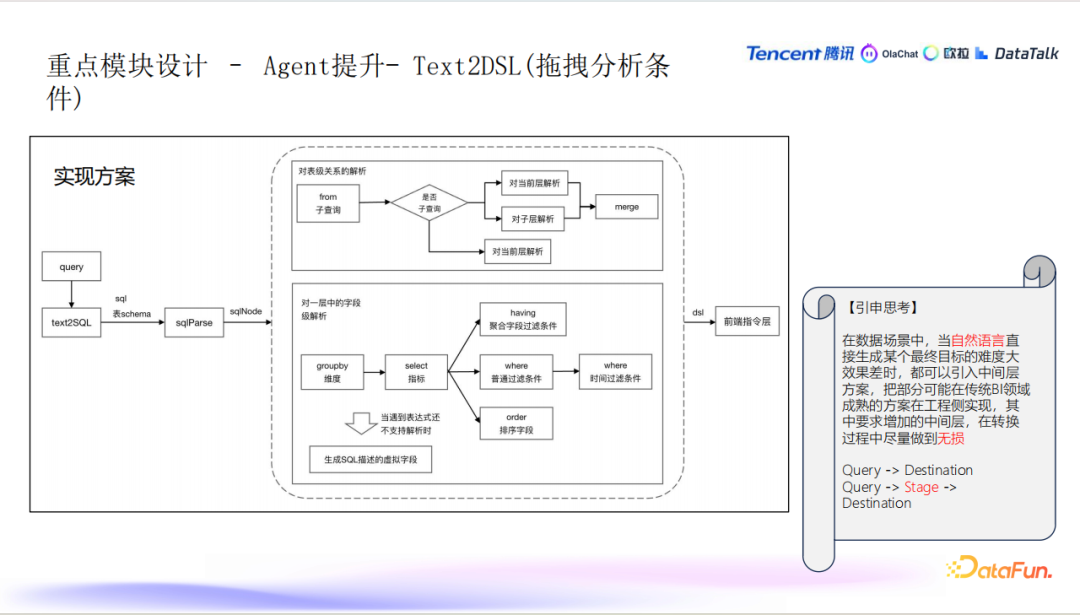
- SQL 解析和转换:在生成 SQL 后,系统会解析 SQL,将其转化为类似语法树的结构。这个过程中,系统会对 SQL 进行处理,提取出维度、指标、过滤条件、时间条件、排序字段等信息。
- 单层 SQL:如果 SQL 是单层的,系统会进行
group
by、having、where 等处理,提取出维度和指标,并应用过滤条件。多层 SQL:对于包含子查询的 SQL,系统会将每一层的字段通过别名连接起来,并最终生成完整的查询结构。 - 虚拟字段的使用:当 SQL 中包含特定平台的自定义函数或复杂逻辑时,系统会生成虚拟字段,用 SQL 语句来描述这些指标,并在查询时回填相应的数据。
DSL 层的设计
- DSL 结构:DSL 的设计主要包括指标、维度、过滤条件、时间条件、排序和限制条件等。此外,DSL 还封装了复杂的操作,如指标过滤、窗口函数、同比、环比等。
引入中间层的引申思考
- 引入中间层的好处:当从自然语言直接生成目标结果变得困难或效果较差时,引入中间层(如 SQL)可以使得系统更加灵活和高效。通过先将自然语言转化为 SQL,再从 SQL 转化为 DSL,最终生成前端指令的方式,能够更好地适应不同的数据产品和复杂的数据分析场景。
- 无损转换的挑战:在设计中间层时,要确保每一层的转换过程尽量无损,以避免在多次转换中丢失信息。例如,如果每一层都产生一定的损耗(如 0.9 的转化率),最终的结果将显著降低。系统需要在每一层的转换中尽量避免这种信息丢失,以确保最终结果的高质量。
8. 数据服务层的设计与实现
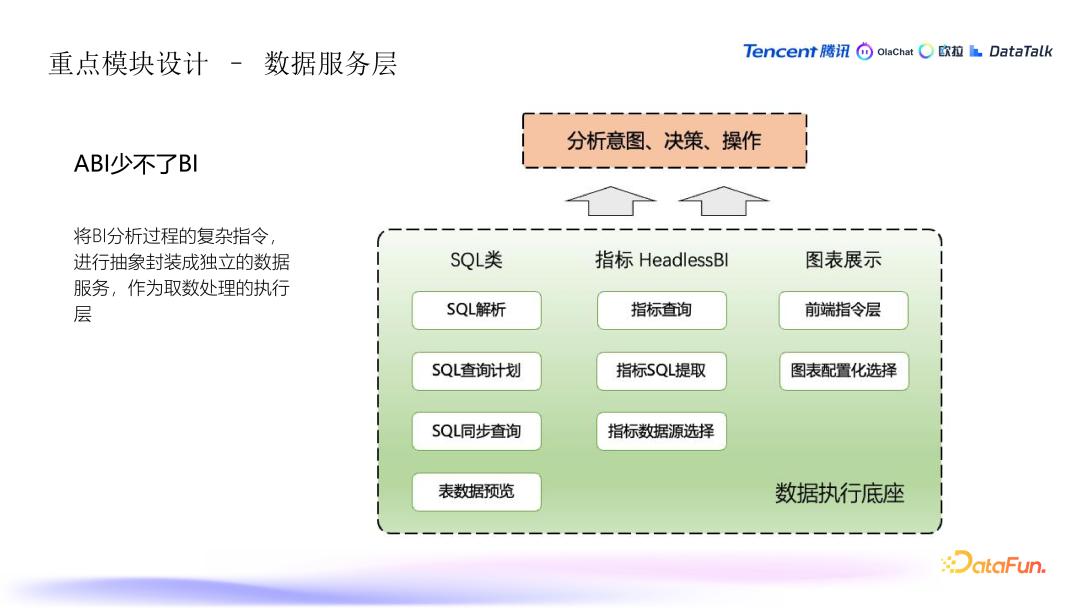
- SQL 类服务:这部分负责处理 SQL 相关的任务,包括解析、格式化和查询计划的生成。这使得系统可以动态地生成并执行 SQL 查询。
- 指标 HeadlessBI:该服务管理高质量的统一指标,确保分析的结果一致且准确。它支持基于用户定义的指标和维度进行查询,并提供有效的 SQL 表达形式。此外,它还能够识别并选择合适的数据源,确保查询效果最佳。
- 图表服务:图表相关的服务负责图表配置与推荐。当用户选择展示数据时,系统会推荐最适合的图表形式,如趋势图、饼图、柱状图等。这些服务减少了用户手动选择图表类型的复杂度,并提供了智能推荐。
9. 数据场景的抽象与意图识别
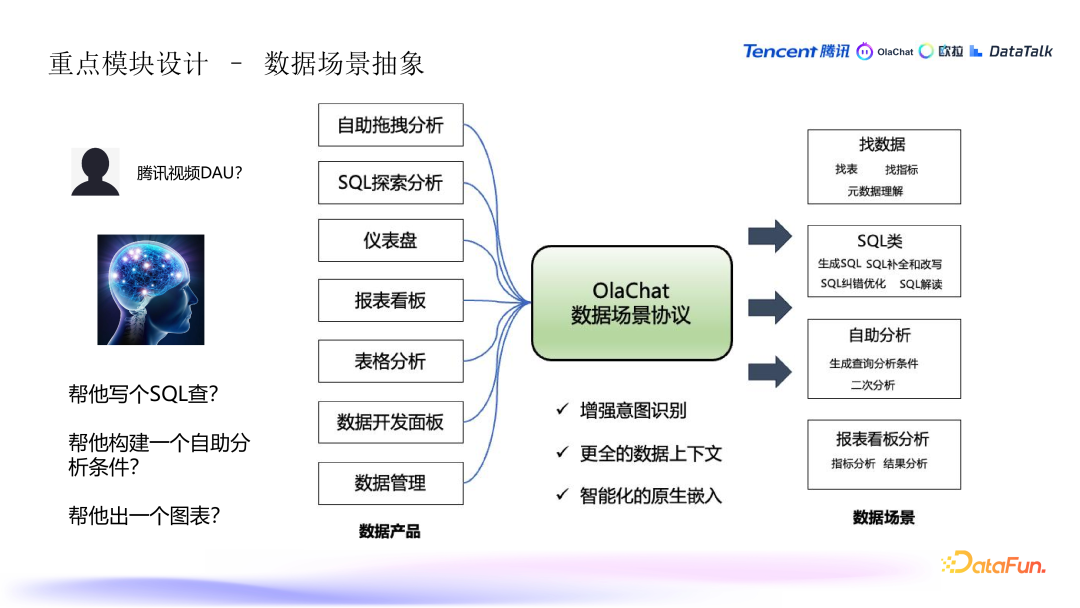
- 意图识别的增强:针对复杂数据查询的场景,系统会通过更智能的方式来识别用户意图。例如,如果用户询问某个指标(如腾讯视频 DAU),系统会根据当前的场景决定是生成 SQL 查询、展示一个图表还是直接给出数据分析结果。这个过程通过抽象不同的数据场景(如仪表盘、表格分析等)来增强意图识别的智能性。
- 数据场景抽象:不同的数据产品和平台可能有不同的数据展现形式,如仪表盘、表格等。系统通过抽象这些场景,帮助用户更自然地理解和使用数据分析功能,提升整体的用户体验。例如,用户不仅仅是提问数据结果,系统还能够根据用户的需求自动选择最合适的展示方式(表格、图表等)。
10. 对话式协议与数据交互
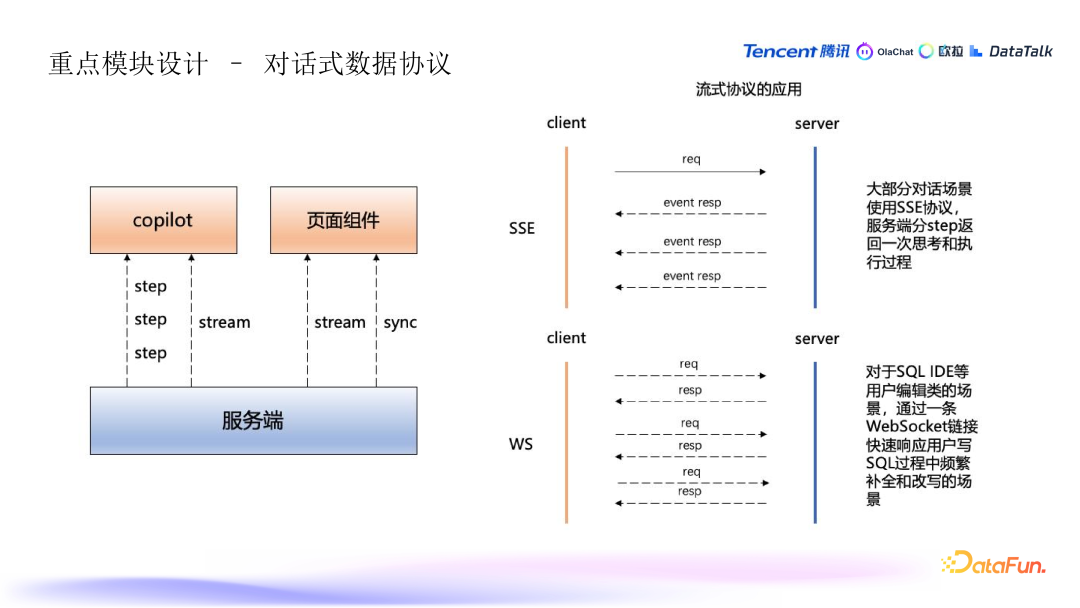
流式协议的应用:数据服务不仅支持传统的同步查询,还引入了流式协议以增强交互体验。常见的流式协议包括:
11. 监控与调试
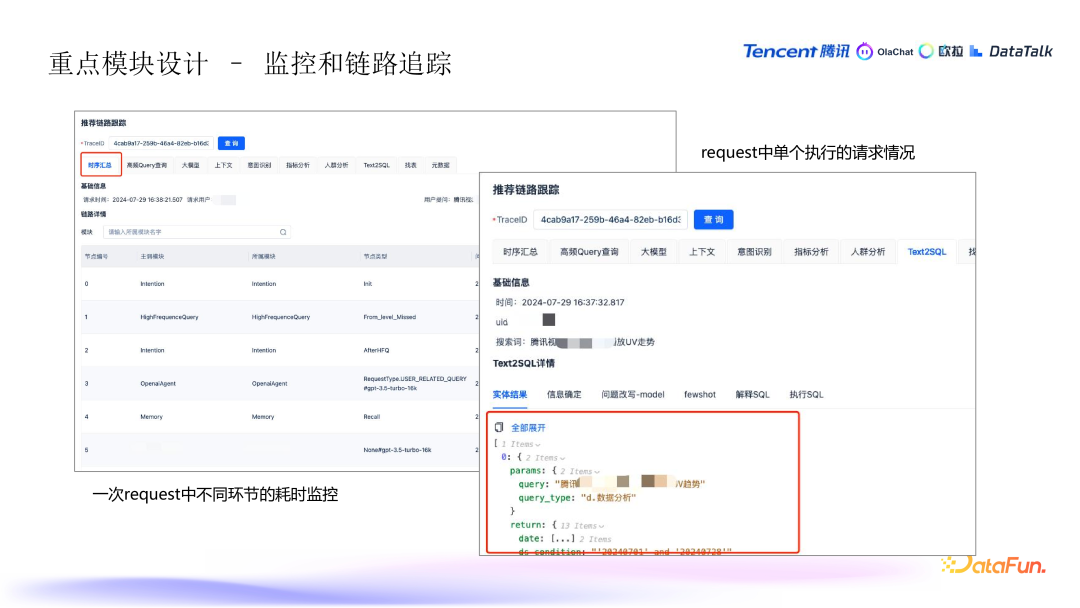
- 监控链路:除了整体的统计监控外,系统还特别注重对每次请求的过程进行详细的耗时监控,确保在查询过程中及时发现和排查问题。通过监控每个环节的执行情况,能够更快速地定位性能瓶颈或出现错误的地方。
- 执行请求的追踪排查:为了便于后续的排查问题,系统会记录和输出执行请求的详细信息,帮助开发人员在出现问题时进行分析和调试。
12. 接入方式

SaaS 服务:用户可以通过 SaaS 方式直接接入数据平台进行访问和处理。这样的设计减少了集成的复杂度,提升用户对 AI 应用一致性体验。
数据产品的接入方式:为了支持更多数据产品和平台的智能化改造,OlaChat 提供了多种接入方式,包括:
页面组件:用户通过网页组件直接与 OlaChat 交互。
API 接口:对于开发者或系统集成商,API 接口提供了更灵活的集成方式。
独立部署:对于涉及敏感或隐私数据的场景,系统提供了独立部署的方式,确保数据安全和隐私。
云原生部署:OlaChat 已支持云原生部署。
05
未来规划

1. SQL IDE 的原生体验
- 目标:打造原生的 SQL 开发环境(IDE),让用户在编写 SQL 的过程中有更加流畅、智能和高效的体验。SQL IDE 是很多数据分析师和开发者日常使用的工具,因此优化这一工具至关重要。
- 深耕 SQL 场景:优化和增强用户在 SQL(可能指特定的 SQL 查询或分析环境)的使用体验,使之更加符合实际需求,减少学习曲线和成本,提升效率。
2. 数仓智能化
- 数据主题理解:通过深入理解数据主题,使得数据仓库(数仓)更加智能化。例如,系统可以自动识别数据弧中不同数据的主题,进而为用户提供更相关的分析建议。
- 任务链路推荐:在用户进行任务设计和数据开发时,系统能够自动推荐常见的任务链路,尤其是对于那些重复性开发的任务。通过智能推荐,减少用户的重复思考和开发,提升工作效率。
- 异常代码识别:系统能够识别那些看似可以通过编译,但在实际执行中可能会遇到的代码问题(比如,数据分布不均可能导致的性能瓶颈或者执行错误),并给予用户及时的提醒和修复建议,避免用户陷入隐性 bug 中。
3. 标注质量和效率的提升
- 自动化标注:在数据分析过程中,数据标注是非常重要的部分。系统希望通过自动化手段提升标注的质量和效率。通过自动化,能够提升数据标注的规模化效应,同时减轻人工标注的工作量。
4. 画布形态的引导式数据分析
- 引导用户分析旅程:在数据分析的过程中,系统会通过画布形态逐步引导用户的分析思路。用户一开始可能有一个大概的问题,系统会推荐多个方向或步骤,帮助用户逐步构建完整的数据分析流程。
- 并行推荐与分析:系统将支持数据的多路并行处理,并提供多种分析引导和推荐。这不仅能帮助用户发现更多可能的分析路径,还能在复杂的分析过程中,提供更多的决策支持。
5. 短期内的规划总结
- 短期内,以上这些规划将集中在优化用户在数据分析过程中的体验,包括 SQL IDE 的升级、数据仓库智能化的推进等方面。通过这些改进,系统能够更好地支持数据开发与分析工程师的工作,提高分析效率,并带来更加智能化的分析体验。
问答环节
1. 指标查询覆盖不全的解决方案
问题:用户提问关于如果 SQL 查询覆盖不全,且涉及复杂的多表联合查询,如何确保查询的正确性以及 SQL 的生成和解析。
- 微调模型:首先,生成的 SQL 是基于微调的混元大模型(例如在现有大模型的基础上进行微调),从而确保模型在特定场景中的表现更好。
- 补全引导:针对用户输入的复杂 SQL,系统会逐步引导用户进行局部补全。比如在多层 SQL 查询中,系统会分层次地引导用户补全各层的 SQL 语句,最终生成完整的正确 SQL 查询。
2. 智能化 BI 的知识梳理和数据标注
问题:如何使用大模型实现智能化 BI,企业需要做哪些数据标注和知识梳理?
- 领域知识:需要标注业务领域的知识,特别是数仓的主题层,即数据仓库中各个主题的具体定义。
- 数据源和 SQL 标注:除了业务知识外,还需要对原始数据字段、库表和 SQL 查询进行标注。
- 流程与模型训练:通过对这些标注数据进行系统化梳理和训练,可以帮助模型理解和应用这些标注数据,进而提升BI智能化的能力。
3. 前端指令层的解释
问题:前端指令层是什么?以及如何将用户的意图和数据进行映射的协议?
- 前端指令层:前端指令层用于处理不同平台的特定需求和约束。例如,某些平台可能会校验权限,或限制某些指标是否可以展示在某些位置。通过将这些平台的规则封装成指令层,可以确保统一的指令逻辑适应不同的平台要求。
- 数据场景与映射:针对不同产品和平台的数据场景,系统会进行映射或转换。例如,在进行数据展示时,不同平台可能有不同的数据场景定义,因此需要在系统中进行灵活的配置和映射。
4. 如何适配多个产品平台而不进行定制开发
问题:为了适配多个产品,是否需要对每个产品做单独定制?
- 通用性设计:为避免对每个平台进行完全的定制开发,系统会设计通用的框架和钩子(回调机制),使得各个产品可以根据自己特有的需求,灵活地实现必要的自定义功能,而不需要修改通用的系统逻辑。
5. 与 DBGBT 的对比
问题:有同学提到开源产品 DBGBT,能否与本系统做一个对比?
- 不同的专注点:本系统主要面向数据分析领域,尤其是在分析场景和数据仓库构建方面具有优势,而 DBGBT 更侧重于特定的数据处理和生成领域。
- 架构和通用性:本系统的架构偏向于通用数据处理,能够适应不同的数据分析和数据仓库的构建需求,相比之下 DBGBT 可能在某些方面较为专注。

































 粤ICP备17114055号
粤ICP备17114055号