尼恩:LLM大模型学习圣经PDF的起源
在40岁老架构师 尼恩的读者交流群(50+)中,经常性的指导小伙伴们改造简历。经过尼恩的改造之后,很多小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试机会,拿到了大厂机会。然而,其中一个成功案例,是一个9年经验 网易的小伙伴,当时拿到了一个年薪近80W的大模型架构offer,逆涨50%,那是在去年2023年的 5月。- 惊天大逆袭:8年小伙20天时间提75W年薪offer,逆涨50%,秘诀在这
不到1年,小伙伴也在团队站稳了脚跟,成为了名副其实的大模型架构师。目前,他管理了10人左右的团队,包括一个2-3人的python算法小分队,包括一个3-4人Java应用开发小分队,包括一个2-3人实施运维小分队。并且他们的产品也收到了丰厚的经济回报, 他们的AIGC大模型产品,好像已经实施了不下10家的大中型企业客户。当然,尼恩更关注的,主要还是他的个人的职业身价。小伙伴反馈,不到一年,他现在是人才市场的香馍馍。怎么说呢?他现在职业机会不知道有多少, 让现在一个机会没有的小伙伴们羡慕不已。只要他在BOSS上把简历一打开, 就有大量的猎头、甲方公司挖他,机会可以说是非常非常非常多,给他抛绣球的不知道有多少: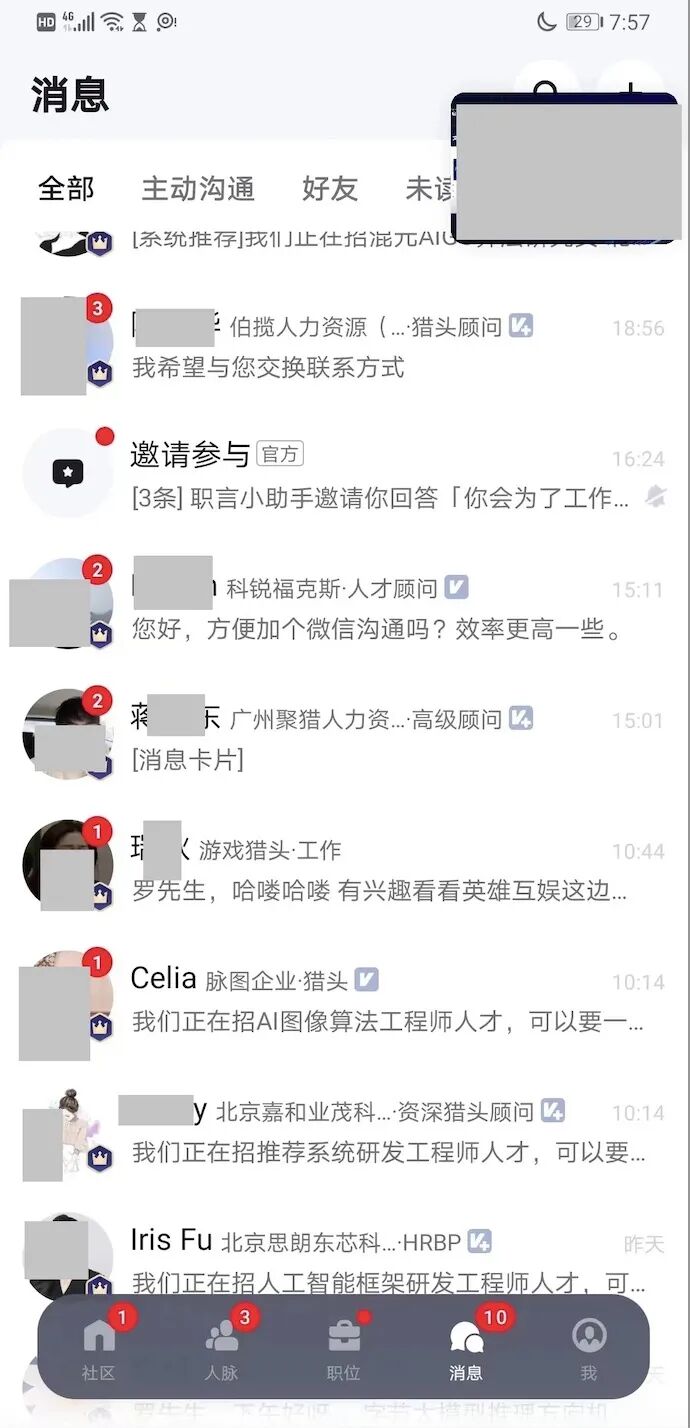
并且来找他的,很多都是按照P8标准,年薪200W来的。相当于他不到1年时间, 职业身价翻了1倍多,可以拿到年薪 200W的offer了。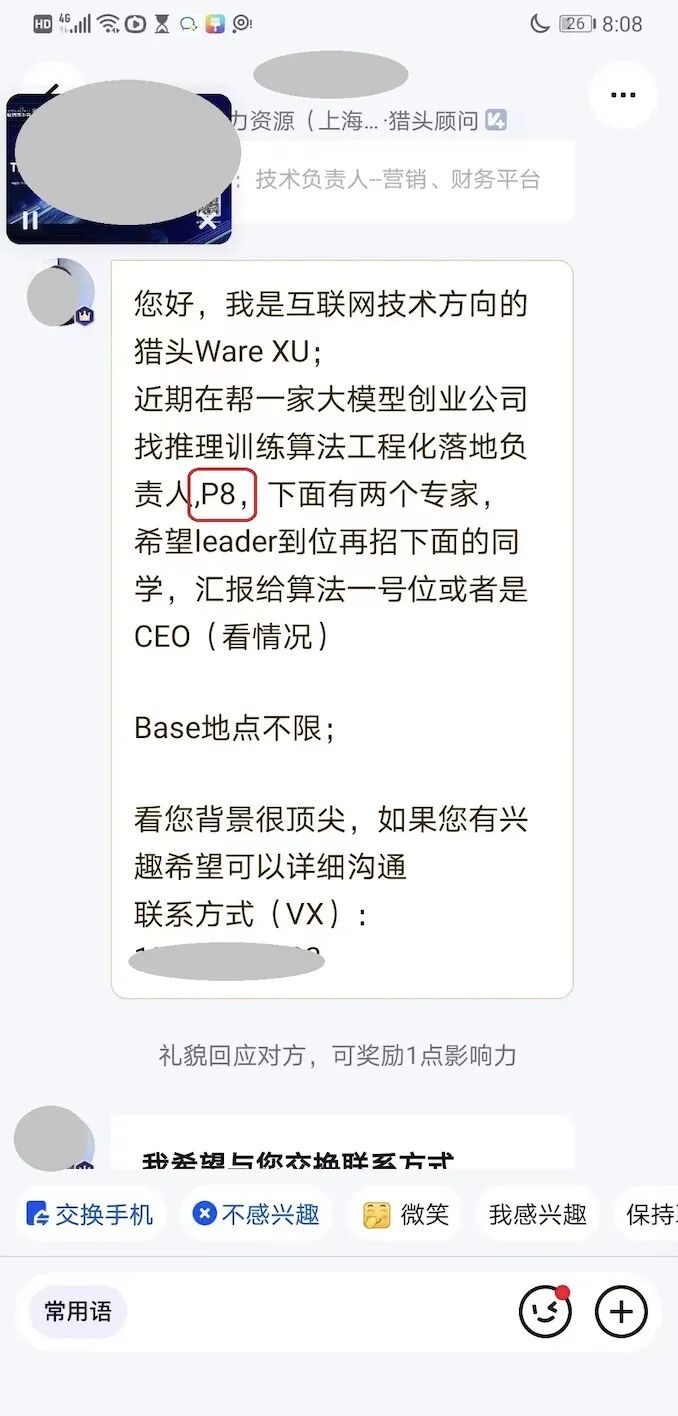
回想一下,去年小伙伴来找尼恩的时候, 可谓是 令人唏嘘。当时,小伙伴被网易裁员, 自己折腾 2个月,没什么好的offer, 才找尼恩求助。当时,小伙伴其实并没有做过的大模型架构, 仅仅具备一些 通用架构( JAVA 架构、K8S云原生架构) 能力,而且这些能力还没有完全成型。 特别说明,他当时 没有做过大模型的架构,对大模型架构是一片空白。本来,尼恩是规划指导小伙做通用架构师的( JAVA 架构、K8S云原生架构),毫无疑问,大模型架构师更有钱途,所以, 当时候尼恩也是 壮着胆子, 死马当作活马指导他改造为 大模型架构师。(1)架构思想和体系,本身和语言无关,和业务也关系不大,都是通的。(2)小伙伴本身也熟悉一点点深度学习,懂python,懂点深度学习的框架,至少,demo能跑起来。(3)大模型架构师稀缺,反正面试官也不是太懂 大模型架构。基于这个3个原因,尼恩大胆的决策,指导他往大模型架构走,先改造简历,然后去面试大模型的工程架构师,特别注意,这个小伙伴面的不是大模型算法架构师。没想到,由于尼恩的大胆指导, 小伙伴成了, 而且是大成,实现了真正的逆天改命。相当于他不到1年时间, 职业身价翻了1倍多,可以拿到年薪 200W的offer了。既然有一个这么成功的案例,尼恩能想到的,就是希望能帮助更多的社群小伙伴, 成长为大模型架构师,也去逆天改命。于是,从2024年的4月份开始,尼恩开始写 《LLM大模型学习圣经》,帮助大家穿透大模型,走向大模型之路。
尼恩架构团队的大模型《LLM大模型学习圣经》是一个系列,初步的规划包括下面的内容:- 《LLM大模型学习圣经:从0到1吃透Transformer技术底座》
- 《LLM大模型学习圣经:从0到1精通RAG架构,基于LLM+RAG构建生产级企业知识库》
- 《LLM大模型学习圣经:从0到1吃透大模型的顶级架构》
尼恩架构团队会持续迭代和更新,后面会有实战篇,架构篇等等出来。 并且录制配套视频。在尼恩的架构师哲学中,开宗明义:架构和语言无关,架构的思想和模式,本就是想通的。架构思想和体系,本身和语言无关,和业务也关系不大,都是通的。所以,尼恩用自己的架构内功,以及20年时间积累的架构洪荒之力,通过《LLM大模型学习圣经》,给大家做一下系统化、体系化的LLM梳理,使得大家内力猛增,成为大模型架构师,然后实现”offer直提”, 逆天改命。尼恩 《LLM大模型学习圣经》PDF 系列文档,会延续尼恩的一贯风格,会持续迭代,持续升级。这个文档将成为大家 学习大模型的杀手锏, 此文当最新PDF版本,可以来《技术自由圈》公号获取。本文目录
- 尼恩:LLM大模型学习圣经PDF的起源
- 1. 大语言模型简介
- 1.1 大语言模型简介:探索AI的新边疆
- 预训练语言模型(PLM):NLP的瑞士军刀
- 大语言模型(LLM):AI进化的里程碑
- LLM与PLM:大小之间的质变
- 大语言模型的涌现能力:AI的新技能
- 大语言模型的关键技术:构建AI的基石
- 1.2 大语言模型特点
- 1. 具备涌现能力
- 2. 训练数据大且难度大:
- 3. 模型参数量大
- 4. 生成的模型大
- 5. 训练需要算力规模
- 1.3 大型语言模型四要素
- 1. 算力:AI的心脏
- 2. 算法:AI的大脑
- 3. 数据:AI的养料
- 4. 场景:AI的舞台
- 1.4 大语言模型应用
- 1. 业务流程自动化
- 2. 促进个性化交互
- 3. 提升任务准确性
- 2. 检索增强生成(RAG)
- 2.2 RAG是什么?
- 2.2.1 RAG的诞生背景
-2.2.1.1 LLM面临的挑战有哪些
-2.2.1.2 RAG技术的解决的问题
-2.2.1.3 长上下文处理能力会杀死RAG吗?
- 2.2.3 RAG具备性价比
-1. 预训练:打造基石模型的挑战
-2. 微调:适配领域数据的策略
-3. 提示工程:优化输入的艺术
- 2.3 RAG技术概述与原理
- RAG 概述
- 2.3 RAG系统的主要组件和工作流程
- 2.3.1 RAG系统的核心组件与工作流程
-检索引擎:数据的精准定位
-增强引擎:上下文的深度融合
-生成引擎:智能响应的构建
- 2.3.2 RAG工作流程的全景视图
-第一步,数据索引:构建检索的基石
-第二步,输入查询处理:理解并转化用户需求
-第三步,搜索和排名:找到最相关的信息
-第四步提示增强:丰富输入,提升输出
-第五步,响应生成:构建最终答案
-第六步,评估:持续优化的关键
- 2.3 RAG范式
- 2.3.1 第一阶段,朴素RAG
- 2.3.2 第二阶段,高级RAG
- 2.3.3 第三阶段,模块化RAG
-新模块
-模块化RAG 的优势
- 2.3.1 预检索
-索引
-查询操作
-数据修改
- 2.3.2 检索
-搜索与排名
- 2.3.3 检索后
-重排序
-过滤
- 2.3.4 生成
-增强
-定制化
- 3. 网络爬虫与数据采集
- 使用BeautifulSoup解析HTML
- 清理HTML
- 提取文本
- 去除多余的空白和换行
- 返回处理后的文本
- 4. 向量数据库与Embedding模型
- 4.1 为什么现在每个人都在谈论矢量数据库?
- 4.2 RAG 场景对向量数据库的需求
- 4.3 如何选择向量数据库
- 4.4 向量数据库对比
- Pinecone
- Weaviate
- Qdrant
- Milvus/Zilliz
- Chroma
- LanceDB
- Vespa
- Vald
- Elasticsearch、Redis 和 pgvector
- 4.5 什么是Embedding?
- Embedding的重要性何在呢?
- 4.6 向量之间的距离
- 1. 欧几里德距离度量(Euclidean Distance)
- 2. 曼哈顿距离度量(Manhattan Distance)
- 3. 余弦距离度量(Cosine Distance)
- 4. 切比雪夫距离度量(Chebyshev Distance)
- 4.7 如何选择嵌入模型
- 常见的类Embbedding模型
- Embbedding模型在RAG种的应用场景
- 在哪里找到合适Embbedding模型?
- Embbedding模型选型
- 4.8 嵌入是如何生成的?
- 方式一:模型托管方式生成 嵌入
- 开源的嵌入模型
- 5. 实战: 基于 Langchain+私有模型,构建一个生成级RAG 聊天机器人
- 5.1 设置环境和依赖
- 5.2 初始化LLM
- 5.3 增强生成
- 5.4 生成嵌入
- 5.5 生成并存储嵌入
- 5.6 查询嵌入
- 5.7 检索增强生成
- 6. 实战: 基于 Langchain+公有模型,构建一个生成级RAG 聊天机器人
- 6.1 准备工作
- 6.2 加载配置
- 6.3 索引:加载数据
- 6.4 索引:切分数据
- 6.5 索引:生成嵌入
- 6.6 索引:存储嵌入
- 6.7 查询检索
- 生成
- 总结
- 说在最后:有问题找老架构取经
1. 大语言模型简介
1.1 大语言模型简介:探索AI的新边疆
在AI的浩瀚宇宙中,语言模型犹如一艘艘探索船,它们通过预测单词序列的概率,解码语言的奥秘。这些由人工神经网络构成的模型,经过海量文本数据的洗礼,不仅理解语言的本质,更能预测序列中的下一个单词。当我们将这些模型的参数规模扩大到一个全新的量级时,便诞生了所谓的大型语言模型(LLM),它们以其庞大的参数数量,学习语言中的复杂模式,为世界带来了革命性的影响。预训练语言模型(PLM):NLP的瑞士军刀
在NLP的征途上,预训练语言模型(PLM)以其在处理各种任务时展现的卓越能力,成为了研究者们的得力助手。随着模型规模的扩展,研究人员发现,这不仅提升了模型的性能,更解锁了小规模模型所不具备的特殊能力。这种现象,就像是在AI的进化树上,找到了一个新的分支——大语言模型(LLM)。大语言模型(LLM):AI进化的里程碑
LLM的研究揭示了一个有趣的现象:当模型的规模达到一定程度时,它们开始展现出一些被称为“涌现能力”的特质。这些能力在小规模的PLM中是难以观察到的。例如,GPT-3通过上下文学习(ICL)解决了小样本任务,而GPT-2则在这方面表现平平。ChatGPT的出现,更是将LLM的应用推向了一个新的高度,它在对话领域的卓越表现,让人们对通用人工智能(AGI)的实现充满了期待。LLM与PLM:大小之间的质变
LLM与PLM之间的主要区别在于它们是否具备涌现能力,以及它们的使用方式和开发过程。LLM的出现,预示着人工智能开发和使用方式的彻底变革。研究人员和工程师需要紧密合作,共同解决在大规模数据处理和分布式并行训练中遇到的复杂工程问题。大语言模型的涌现能力:AI的新技能
LLM的涌现能力包括上下文学习、指令遵循和逐步推理。这些能力使得LLM在解决复杂任务时表现出色,尤其是当它们通过思维链(CoT)提示策略来解决涉及多个推理步骤的问题时。大语言模型的关键技术:构建AI的基石
LLM的成功,离不开一系列关键技术的发展,包括扩展定律、大规模训练、能力引导、对齐微调和工具操作。这些技术不仅提升了LLM的性能,更使得LLM能够更好地与人类价值观对齐,并利用外部工具扩展其能力。在这篇文章中,我们不仅探讨了LLM的基本概念和关键技术,更通过实际案例,展示了LLM如何在实际应用中展现出其独特的价值。随着技术的不断进步,LLM有望在未来的AI领域中发挥更加重要的作用。1.2 大语言模型特点
1. 具备涌现能力
LLM 的涌现能力被正式定义为 “在小型模型中不存在但在大型模型中产生的能力”,模型具有从原始训练数据中自动学习并发现新的、更高层次的特征和模式的能力,这是区别 LLM 与先前 PLM 的最显著特征之一。2. 训练数据大且难度大:
基于海量数据(书籍、文章和对话)进行训练(TB级,甚至PB级),接受大量未标记文本的训练,可能达到数千亿个单词,GPT-3 使用 45 TB 的文本进行训练,而 Codex 则使用 159 GB 的文本进行训练。GPT-3(175B):
- 由OpenAI开发,是一个具有1750亿参数的大型语言模型。
- 预训练数据集包含3000亿个token,来源包括CommonCrawl、WebText2、Books1、Books2和Wikipedia。
PaLM(540B):
- 由Google Research提出,是一个具有5400亿参数的多任务、多模态大型语言模型。
- 预训练数据集包含7800亿个token,来源包括社交媒体对话、过滤后的网页、书籍、Github、多语言维基百科和新闻。
LLaMA:
- 是Meta AI提出的一种大型语言模型系列,具有不同的大小变体,从6亿参数到65亿参数不等。
- 训练数据来源多样,包括CommonCrawl、C4、Github、Wikipedia、书籍、ArXiv和StackExchange。
- LLaMA(6B)和LLaMA(13B)使用了1万亿个token进行训练,而更大的模型版本LLaMA(32B)和LLaMA(65B)则使用了1.4万亿个token。
3. 模型参数量大
大型语言模型由可能具有数千亿,数万个参数的神经网络组成,使它们能够学习语言中的复杂模式,OpenAI 发布了 GPT-3,这是一个拥有 1750 亿个参数的模型。4. 生成的模型大
5. 训练需要算力规模
训练基础模型需要上千块,甚至上万块高性能GPU才能完成。1.3 大型语言模型四要素
大模型三要素:算力、算法、数据、场景。 大模型是"大数据 + 大算力 + 强算法"结合的产物,大模型要到具体场景应用才能发挥最大的价值。1. 算力:AI的心脏
在AI的宏伟蓝图中,算力是那颗不断跳动的心脏。它决定了数据处理的能力,就如同血液的流动速度。芯片,作为算力的核心,其性能的优劣直接关系到大模型处理能力的速度。黄仁勋在2023年2月的财报会上提到,过去十年间,通过不断的技术创新和合作,大语言模型的处理速度实现了质的飞跃,提高了惊人的100万倍。2. 算法:AI的大脑
算法,作为AI的大脑,是解决问题的核心机制。不同的算法就像是通往解决方案的不同路径,而它们的效率和效果可以通过空间和时间复杂度来衡量。GPT,这个在Transformer模型基础上发展起来的明星,自2017年由Google提出以来,就在NLP领域掀起了一场革命。它摒弃了传统的RNN和CNN,以更好的并行性和更短的训练时间,在处理长文本时展现出了无与伦比的优势。3. 数据:AI的养料
数据,是算法训练的养料。在模型的早期训练阶段,需要大量数据的喂养,以形成模型的理解能力。而在中后期,数据的质量则直接决定了模型的精度。在机器学习的过程中,使用标注好的数据进行训练是至关重要的。数据标注是对原始数据进行加工处理,使其转化为机器可识别的信息。只有通过大量训练,覆盖尽可能多的场景,才能孕育出一个优秀的模型。目前,大模型的训练数据集主要来源于公开数据,如维基百科、书籍、期刊、Reddit链接、Common Crawl等。而在中后期,高质量数据的引入将显著提升模型的精度。例如,更加事实性的数据将提高模型的准确性,而更加通顺的中文语言数据将增强模型对中文的理解能力。此外,高质量的反馈数据也能提升模型性能,如ChatGPT采用的人类强化学习RLHF技术,通过专业的问题、指令和人类反馈排序等方式,加强了模型对人类语言逻辑的理解。最终,通过更精准的垂直领域数据,可以构建出更细分领域的专业模型。4. 场景:AI的舞台
大预言模型的应用场景众多,技术与场景的结合是诞生有价值应用的温床。从文本生成到语言理解,从机器翻译到智能对话,LLM在各个领域都有着广泛的应用。随着技术的不断进步和创新,LLM将在更多的场景中展现出其独特的价值,为人类社会的发展贡献AI的力量。1.4 大语言模型应用
在当前的人工智能领域,大型语言模型(Large Language Models,简称LLM)已成为推动业务创新和操作效率的关键技术。通过在庞大的数据集上进行预训练,这些模型不仅展现出卓越的通用性和泛化能力,还极大地降低了人工智能应用的技术门槛。用户可以借助零样本或小样本学习迅速实现先进的应用效果,而“预训练+精调”的开发模式标准化了研发流程,显著降低了技术难度,促进了AI技术在各行各业的广泛应用。大型语言模型为企业带来的主要好处包括:1. 业务流程自动化
大型语言模型能够自动化处理多种业务流程,如客户服务、文本生成、预测和分类任务等。这种自动化减少了人工操作的需求,降低了相关成本,使员工能够将精力集中在更加核心和有价值的任务上。例如,在客户支持领域,通过自动响应客户的查询,大大提高了处理效率和客户满意度。2. 促进个性化交互
通过运用大型语言模型,聊天机器人和虚拟助理能够实现全天候的客户服务,这些系统能够分析和处理大量数据,深入理解客户的行为和偏好,从而实现高度个性化的交互。不论是在电子商务推荐、个性化营销还是内容创建中,这种个性化的能力都极大地提升了用户体验和客户忠诚度。3. 提升任务准确性
大型语言模型通过分析和处理大量的数据来提高任务执行的准确性,这在数据密集型的任务中尤为重要。例如,通过分析数千条客户反馈,模型能够精确地识别和归类客户的情绪和意见,无论是在市场研究、公关监控还是社交媒体分析中,都能够提供深入且准确的洞察。2. 检索增强生成(RAG)
2.2 RAG是什么?
检索增强生成(RAG)是指对大型语言模型输出进行优化,使其能够在生成响应之前引用训练数据来源之外的权威知识库。大型语言模型(LLM)用海量数据进行训练,使用数十亿个参数为回答问题、翻译语言和完成句子等任务生成原始输出。在 LLM 本就强大的功能基础上,RAG 将其扩展为能访问特定领域或组织的内部知识库,所有这些都无需重新训练模型。这是一种经济高效地改进 LLM 输出的方法,让它在各种情境下都能保持相关性、准确性和实用性。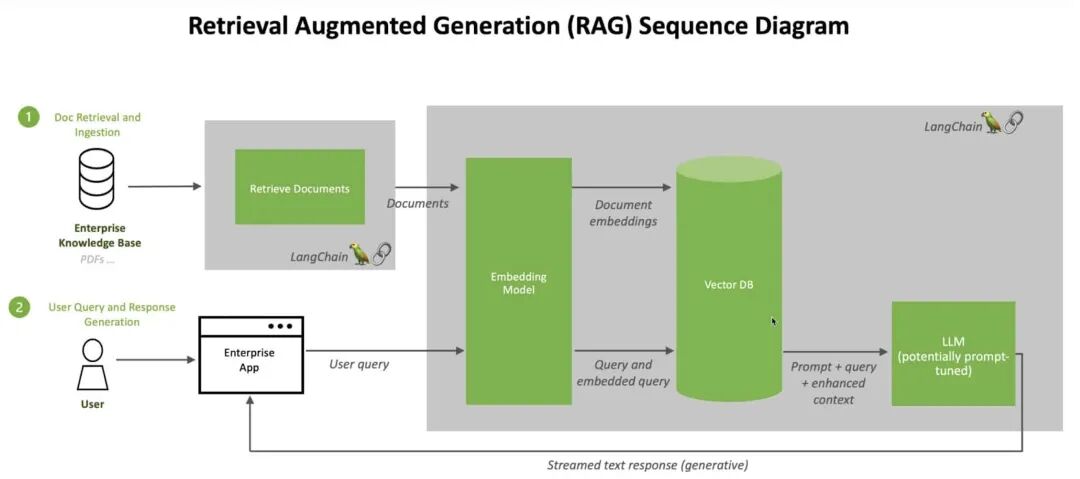
2.2.1 RAG的诞生背景
随着对大型模型应用探索的深入,检索增强生成技术(Retrieval-Augmented Generation)受到了广泛关注,并被应用于各种场景,如知识库问答、法律顾问、学习助手、网站机器人等。在大型语言模型(LLM)的探索旅程中,检索增强生成(RAG)技术正逐渐显露其锋芒,为LLM的未来发展注入了创新的动力。以下是对RAG技术及其在LLM中应用的深入探讨。2.2.1.1 LLM面临的挑战有哪些
尽管ChatGPT和Claude等LLM展现了令人印象深刻的能力,但它们也面临着一些挑战:- 产生臆想的答案(幻觉):在没有确切答案的情况下,LLM可能会产生误导性信息。
- 知识更新慢:当用户需要基于最新情况的具体响应时,LLM可能提供过时或不具体的信息。
- 知识来源缺乏引用:LLM可能引用非权威来源的信息,影响回答的准确性。
- 术语混淆:不同训练数据中相同的术语可能指向不同概念,导致LLM产生混淆。
- 领域专业知识不足: 尽管LLM拥有广泛的知识基础,但它们并不了解特定业务的细节,如公司的私有数据。
2.2.1.2 RAG技术的解决的问题
- 避免“幻觉”问题:RAG 通过检索外部信息作为输入,获取领域特定的知识,辅助大型模型回答问题,这种方法能显著减少生成信息不准确的问题,。
- 信息的实时性: RAG 允许从外部数据源实时检索信息,RAG允许LLM访问最新的客户记录、产品规格和实时库存信息,解决知识时效性问题。
- 解决黑匣子问题:RAG技术使GenAI应用程序能够提供其使用的数据来源,增加透明度,类似于学术论文中的引用,增加回答的可追溯性。
- 数据隐私和安全: RAG 可以将知识库作为外部附件管理企业或机构的私有数据,避免数据在模型学习后以不可控的方式泄露。
- 降低应用成本:RAG提供了一种经济高效的方法,使得组织能够在不重新训练模型的情况下,提升LLM的输出质量。
2.2.1.3 长上下文处理能力会杀死RAG吗?
长上下文处理能力的提升确实为大型语言模型(LLMs)带来了显著的进步,尤其是在处理长篇文档和复杂查询方面。然而,尽管LLMs的上下文长度得到了扩展,RAG(Retrieval-Augmented Generation)依然保有其独特的价值和应用场景,并不会完全被长上下文处理所替代。以下是RAG保持其重要性的几个关键优势:- 白盒模型的透明度和可解释性:RAG的工作流程相对透明,模块之间的关系清晰,这为模型的效果调优和可解释性提供了优势。在检索召回的内容质量不高或置信度不足时,RAG系统有能力避免生成误导性信息,选择不生成回答而非提供错误的信息。
- 成本效益和响应速度:与微调模型相比,RAG的训练周期更短,成本更低。与长文本处理相比,RAG能够提供更快速的响应和更低的推理成本。在工业界和产业应用中,成本是一个至关重要的因素,而RAG在这一点上具有明显的优势。
- 私有数据管理与安全性:RAG通过将知识库与大型模型分离,为私有数据的管理提供了一个安全的实践基础。这种方法有助于企业更好地控制和管理其知识资产,同时解决了知识依赖问题。此外,RAG底座数据库的访问权限控制和数据管理相对容易实现,而这对于大模型来说则较为困难。
- 灵活性和适应性:RAG能够适应不同的数据源和检索需求,为特定领域或任务提供定制化的解决方案。这种灵活性使RAG在多种应用场景中都能找到其适用之处。
- 模块化和可扩展性:RAG的模块化设计允许它轻松集成新模块或调整现有模块之间的交互流程,以适应不断变化的任务需求和数据环境。
因此,尽管长上下文处理为LLMs带来了新的机遇,RAG仍然在多个方面保持其独特的价值和应用潜力。在未来,RAG可能会继续与长上下文处理和其他先进技术相结合,共同推动自然语言处理技术的发展。2.2.3 RAG具备性价比
如果没有RAG那么,我们处理之前提到问题还能通过以下方式进行处理1. 预训练:打造基石模型的挑战
在AI的征途上,构建基础模型的第一步便是资金的筹集。对于大多数企业而言,这是一个几乎不可能完成的任务。OpenAI的Sam Altman曾估算,训练ChatGPT背后的基石模型成本高达1亿美元。除了原始的计算成本,人才的稀缺性同样令人头疼:你需要一支由机器学习博士、顶尖系统工程师和高技能操作人员组成的梦之队,来攻克生成此类模型及其每个模型所面临的众多技术难题。全球的AI公司都在争相抢夺这些稀有人才。获取、清洗和标记数据集以生成功能强大的基础模型,是另一个挑战。以法律发现公司为例,如果你打算训练模型以回答有关法律文件的问题,那么还需要法律专家投入大量时间来标记训练数据。2. 微调:适配领域数据的策略
微调,即根据新数据对基础模型进行再训练,无疑是一种成本相对较低的方法。然而,它同样面临着与创建基础模型相同的诸多挑战:稀缺而深入的专业知识需求,充足的数据资源,以及在生产中部署模型的高昂成本和技术复杂性。LLM与向量数据库的结合,用于上下文检索,使得微调成为一种不太实用的手段。一些LLM提供商,如OpenAI,已不再支持对其最新一代模型进行微调。微调,作为提升LLM输出质量的传统方法,需要主题专家进行重复、昂贵且耗时的标记工作,并持续监控质量的漂移,以及由于缺乏定期更新或数据分布变化导致的模型准确性的偏差。随着时间的推移,即使是经过微调的模型,其准确性也可能下降,这就需要更昂贵且更耗时的数据标记、持续的质量监控和重复的微调。3. 提示工程:优化输入的艺术
提示工程,即精心设计和调整输入到模型中的指令(prompts),以引导模型执行特定的任务或操作,是提高通用人工智能(GenAI)应用程序准确性的一种成本较低的方法。通过简单地更改提示,可以快速迭代和更新模型的输入,而无需重新训练整个模型。通过快速工程,可以优化模型返回的响应,使其更加准确和相关。尽管提示工程可以改善模型的响应,但它并不能为模型提供新的或动态的上下文信息。这意味着如果模型的输入仅依赖于静态的提示,它可能无法考虑到最新的信息或环境变化。由于缺乏最新上下文,模型可能产生与现实不符的输出,这种情况被称为“幻觉”(hallucination)。幻觉是大型语言模型在生成文本时可能遇到的问题之一,尤其是在需要最新信息的任务中。RAG 优势的一个示例 ChatGPT 可以解决超出训练数据范围无法回答的问题,并生成正确的结果。该技术通过获取外部数据来响应查询来补充模型,从而确保更准确和最新的输出。我们也制作了0基础入门的提示教程,帮助你掌握与大模型沟通的艺术,全都核心概念和实操相结合,也能从小白到专家华丽蜕变,实现大模型自由。2.3 RAG技术概述与原理
幻觉现象在大型语言模型(LLM)中主要因其无法访问最新信息而产生,这一问题根源于模型对其训练数据集的严重依赖。为了解决这一局限,提出了一种名为RAG(Retrieval-Augmented Generation)的方法,该方法允许LLM通过外部信息源动态地补充训练数据,从而提高回答的准确性。RAG通过结合传统的检索方法和预训练的语言模型,实现了对LLM输入信息的实时更新,避免了对模型进行昂贵且耗时的微调和再训练。这种方法增强了模型的灵活性和扩展性,使其可以轻松地应用于不同的LLM,满足多样化的需求。在实际应用中,RAG通过引入人类编写的现实世界数据作为信息源,不仅简化了回答生成过程,还大幅提高了生成响应的可靠性。随着技术的进步,RAG不断发展,已经能够支持检索与生成组件之间的多轮交互,通过多次迭代检索提高信息准确性,同时逐步优化生成的输出质量。平台如langchain和llamaindex已经对RAG方法进行了模块化处理,这些平台通过实现多轮搜索迭代到连续生成的不同策略,提高了方法的适应性,并扩展了其在实际应用中的范围。这些创新表明,尽管各平台对RAG的具体实施方法各不相同,但它们都遵循了基本的RAG工作流程,展示了这一技术在现代AI应用中的广泛适用性和有效性。RAG 概述
RAG 技术是一种用额外数据增强大型语言模型知识的方法。尽管 LLM 能够对众多主题进行推理,但其知识仅限于训练时使用的特定时间点之前的公开数据。因此,为了让聊天机器人能够对私有数据或截止日期后引入的数据进行推理,我们需要用特定的信息来增强模型的知识。这个过程就是检索增强生成(RAG)。从源数据中加载数据并进行索引,通常离线进行,并且支持动态更新,分为:- 加载:根据不同的数据源选择合适的加载器,加载数据得到文档。
- 切分:使用文本切分器将文档切分成更小的片段,使用小片段一方面可以更好地匹配用户问题,同时也可以适应模型的有限上下文窗口。
- 存储:存储和索引切片,以便在检索时能够快速找到相关的数据,通常使用 Embeddings 模型和向量数据库(VectorStore)来完成。
检索与生成:实际的 RAG 链,接收用户问题,从索引中检索相关数据,基于问题和这些数据生成结果,分为:- 检索:给定用户输入,使用检索器从存储中检索相关的切片。
- 生成:使用包括问题和检索到的数据的提示调用 LLM 来生成答案。
2.3 RAG系统的主要组件和工作流程
2.3.1 RAG系统的核心组件与工作流程
RAG(Retrieval-Augmented Generation,检索增强生成)系统是一个将生成式AI的优势与搜索引擎的功能相结合的复杂系统。要深入理解RAG,关键在于剖析其核心组件以及这些组件是如何协同工作的,以提供无缝的AI体验。检索引擎:数据的精准定位
RAG过程的首步是检索引擎的介入。这一环节涉及对庞大的信息库进行搜索,以定位与输入查询相匹配的相关数据。检索引擎运用精细的算法,确保所检索到的信息不仅相关性强,而且保持最新,为生成准确的响应打下坚实基础。增强引擎:上下文的深度融合
检索得到的相关信息随后被送入增强引擎。这一引擎的职责是将检索到的数据与原始查询紧密结合,从而扩充上下文的深度,为生成过程奠定一个更加明智的基础。增强引擎的介入,使得生成的响应更加精准和全面。生成引擎:智能响应的构建
最终,经过增强的输入信息被送入生成引擎。这里,通常是利用复杂的语言模型,基于扩充后的上下文创建出既连贯又紧密相关的响应。这种响应的生成,不仅依托于模型内部的先验知识,还通过检索引擎提供的外部数据得到了显著增强。2.3.2 RAG工作流程的全景视图
RAG的基本工作流程始于创建一个包含外部信息源的索引库。这个索引库是检索器模型的基石,它根据特定查询检索出相关的信息。在这一过程的最后阶段,生成器模型将检索到的信息与原始查询融合,形成最终的输出结果。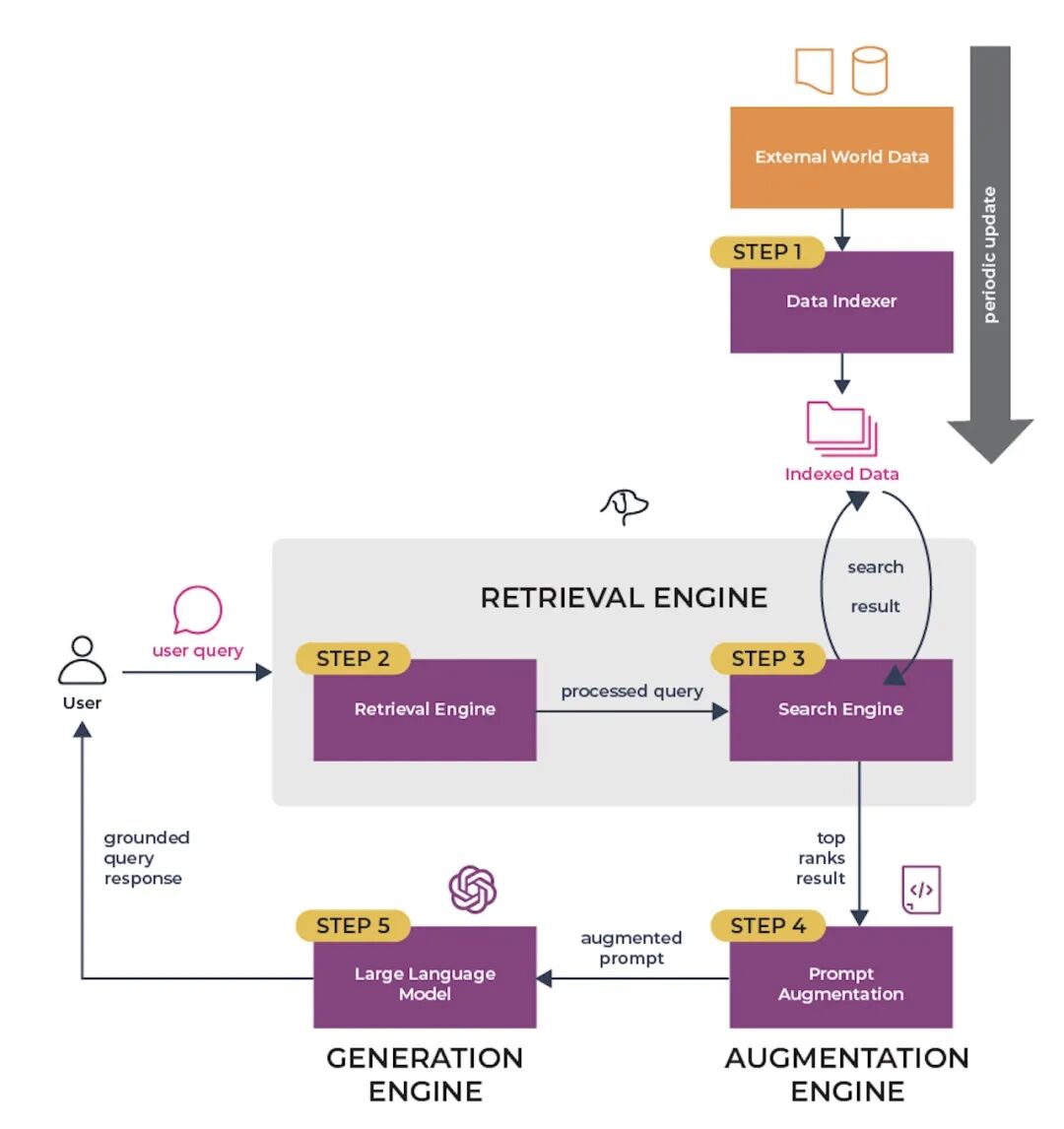
RAG(Retrieval-Augmented Generation,检索增强生成)应用程序的成功依赖于一系列精心设计的步骤,确保了输出的准确性和相关性。以下是RAG系统关键步骤的深入分析。第一步,数据索引:构建检索的基石
在RAG系统中,数据索引是基础。它涉及将文档分割成块,编码为向量,并存储于向量数据库中,为检索引擎提供参考点。文本规范化,包括标记化、词干提取和停用词去除,是增强文本适用性的重要步骤。深度学习技术的应用,特别是预训练的语言模型(LM),为文本生成语义向量表示,极大地提升了索引的效率和检索的精确度。第二步,输入查询处理:理解并转化用户需求
用户的输入是RAG过程的起点。系统需要准确处理和理解这些输入,以形成检索引擎的搜索查询。这一步骤是确保检索结果与用户需求高度相关的关键。第三步,搜索和排名:找到最相关的信息
检索引擎根据输入查询的相关性对索引数据进行搜索和排名。利用语义相似性,检索与问题最相关的前k个块,这一步骤是RAG系统的核心,它决定了后续生成响应的质量和相关性。第四步提示增强:丰富输入,提升输出
将检索到的最相关信息与原始查询结合,形成增强的提示。这一步骤为生成引擎提供了更丰富的信息源,有助于生成更准确和相关的响应。第五步,响应生成:构建最终答案
生成引擎结合原始问题和检索到的信息,输入LLM生成最终答案。这一步骤需要在保持与检索内容一致性和准确性的同时,引入创造性,以生成既准确又具有洞察力的文本。第六步,评估:持续优化的关键
评估是确保RAG应用成功的最后一步。它提供了关于系统输出准确性、忠实性和响应速度的客观衡量,是持续优化RAG策略的关键环节。我们仔细看看RAG内部从索引,检索,增强到最后生成每一步都是怎么运行的,以及使用RAG和不使用RAG对返回结果的效果影响如何。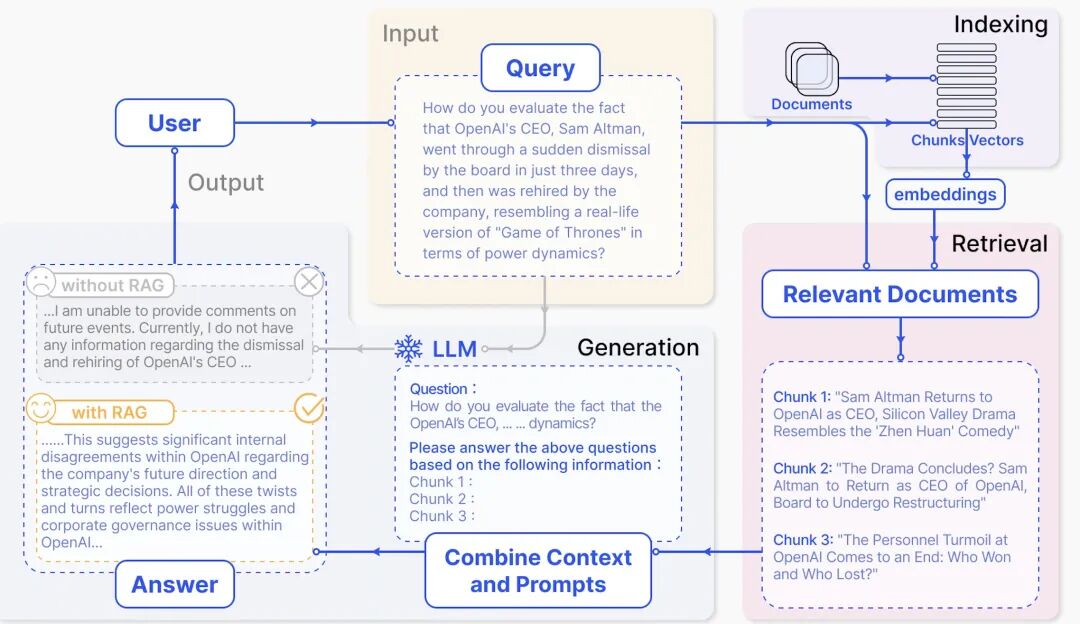
2.3 RAG范式
RAG研究范式在不断发展,我们将其分为三个阶段:Naive RAG、Advanced RAG和Modular RAG。尽管 RAG 方法具有成本效益并且超越了LLM的性能,但它们也表现出一些局限性。 Advanced RAG 和 Modular RAG 的发展正是针对 Naive RAG 的这些具体缺点的回应。2.3.1 第一阶段,朴素RAG
Naive RAG 研究范式代表了最早的方法,在 ChatGPT 广泛采用后不久就得到了重视。Naive RAG 遵循传统的过程,包括索引、检索和生成,也被称为“检索-生成”框架,前面讲的RAG是朴素RAG,它是最基础的,最核心的架构。检索挑战——检索阶段经常在【精确度】和【召回率】方面遇到困难,导致选择错位或不相关的块,并丢失关键信息。生成困难——在生成响应时,模型可能会面临幻觉问题,即生成【检索到的上下文不支持的内容】。此阶段还可能会受到输出的【不相关性、毒性或偏差】的影响,从而降低响应的质量和可靠性。增强障碍——将检索到的信息与不同的任务集成可能具有挑战性,有时会导致【输出脱节或不连贯】。当从多个来源检索类似信息时,该过程还可能遇到【冗余,从而导致重复响应】。确定各个段落的重要性和相关性并确保风格和语气的一致性进一步增加了复杂性。面对复杂的问题,基于原始查询的【单一检索可能不足以获取足够的上下文信息】。2.3.2 第二阶段,高级RAG
Advanced RAG 引入了特定的改进来克服 Naive RAG 的局限性。为了解决索引问题,Advanced RAG 通过使用【滑动窗口方法】、【细粒度分段】和【合并元数据】来改进其索引技术。此外,它还结合了多种优化方法来简化检索过程。预检索过程——这一阶段的主要重点是【优化索引结构和原始查询】。优化索引的目标是提高索引内容的质量。这涉及到策略:增强数据粒度、优化索引结构、添加元数据、对齐优化、混合检索。而查询优化的目标是让用户的原始问题更清晰、更适合检索任务。常见的方法包括查询重写、查询变换、查询扩展等技术。检索后过程——一旦检索到相关上下文,将其与查询有效集成就至关重要。检索后过程中的主要方法包括【重新排序块和上下文压缩】。重新排列检索到的信息以将最相关的内容重新定位到提示的上下文中是一个关键策略。2.3.3 第三阶段,模块化RAG
模块化 RAG 架构超越了前两种 RAG 范例,提供了增强的适应性和多功能性。它采用了多种策略来改进其组件,例如添加用于相似性搜索的搜索模块以及通过微调来改进检索器。重组 RAG 模块等创新并重新排列 RAG 管道的引入是为了应对特定的挑战。向模块化 RAG 方法的转变正在变得普遍,支持跨其组件的顺序处理和集成的端到端训练。尽管具有独特性,模块化 RAG 仍建立在高级 RAG 和朴素 RAG 的基本原则之上,展示了 RAG 系列的进步和完善。新模块
模块化 RAG 框架引入了额外的专用组件来增强检索和处理能力。搜索模块适应特定场景,使用LLM生成的代码和查询语言,可以跨搜索引擎、数据库和知识图谱等各种数据源直接搜索。RAG-Fusion 通过采用多查询策略将用户查询扩展到不同的视角,利用并行向量搜索和智能重新排序来揭示显式和变革性知识,从而解决了传统搜索的局限性 。内存模块利用LLM的内存来指导检索,创建一个无限的内存池,通过迭代的自我增强使文本与数据分布更紧密地对齐。RAG系统中的路由可导航不同的数据源,为查询选择最佳路径,无论是涉及汇总、特定数据库搜索还是合并不同的信息流 。Predict模块旨在通过LLM直接生成上下文来减少冗余和噪音,确保相关性和准确性。任务适配器模块根据各种下游任务定制 RAG,自动提示检索零样本输入,并通过少数样本查询生成创建特定于任务的检索器 。这种综合方法不仅简化了检索过程,而且显着提高了检索信息的质量和相关性,以更高的精度和灵活性满足了广泛的任务和查询。模块化 RAG 的优势
模块化 RAG 通过允许模块替换或重新配置来解决特定挑战,从而提供卓越的适应性。这超越了 Naive 和 Advanced RAG 的固定结构,其特点是简单的“检索”和“读取”机制。此外,模块化 RAG 通过集成新模块或调整现有模块之间的交互流程来扩展这种灵活性,从而增强其在不同任务中的适用性。重写-检索-读取等创新模型利用LLM的能力通过重写模块和LM反馈机制来细化检索查询来更新重写模型,从而提高任务性能。类似地,像Generate-Read 用LLM生成的内容取代传统检索,而背诵阅读强调从模型权重中检索,增强模型处理知识密集型任务的能力。混合检索策略集成了关键字、语义和向量搜索来满足不同的查询。此外,采用子查询和假设文档嵌入(HyDE)旨在通过关注生成的答案和真实文档之间嵌入相似性来提高检索相关性。模块布局和交互的调整,例如演示-搜索-预测(DSP)框架和 ITER-RETGEN 的迭代检索-读取-检索-读取流程 ,展示了模块输出的动态使用来支持另一个模块的功能,说明了对增强模块协同作用的复杂理解。Modular RAG Flow 的灵活编排展示了通过 FLARE 等技术进行自适应检索的优势 和自我 RAG 。该方法超越了固定的RAG检索过程,根据不同场景评估检索的必要性。灵活架构的另一个好处是RAG系统可以更轻松地与其他技术(例如微调或强化学习)集成 。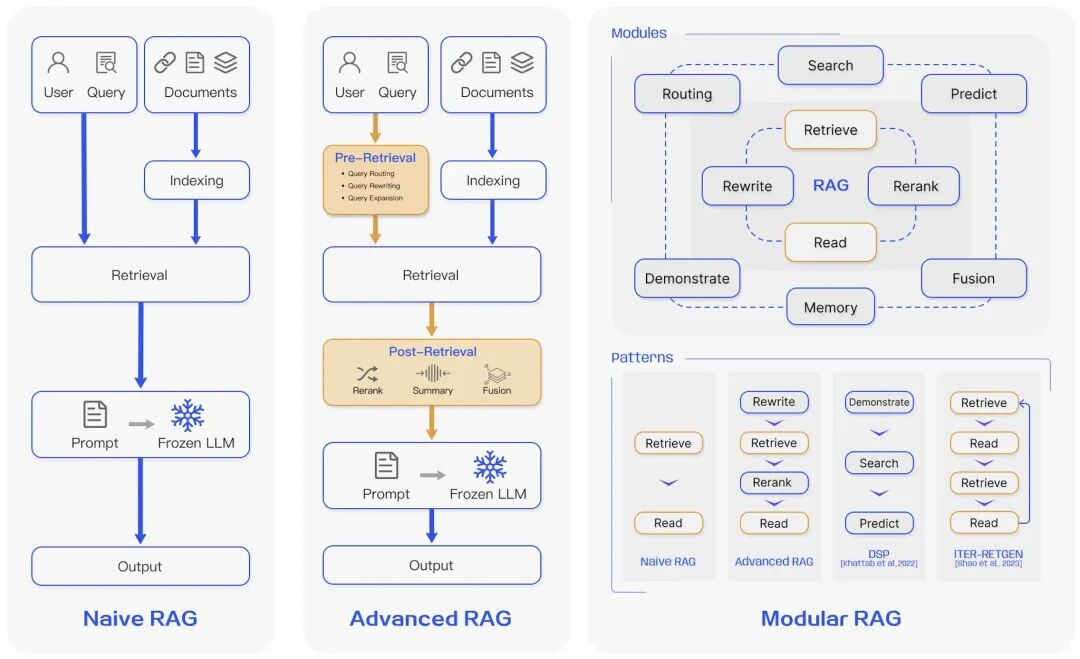
模块化RAG的核心在于将各种功能解耦,将其作为独立的模块进行处理。具体来说,模块化RAG包括了「搜索」、「预测」、「记忆」、「评估」、「验证」和「对齐」等外层模块,以及内层的「检索」、「重排序」、「重写」和「阅读」等RAG核心过程。在处理信息和响应用户查询的过程中,模块化RAG采用了多种信息处理流程。例如,传统的Navie RAG模式仅包括基本的「检索」和「阅读」步骤。而在更复杂的Advanced RAG模式中,包括了「重写」→「检索」→「重排序」→「阅读」的路径,这在提高检索和生成内容的质量方面尤为有效。DSP(Demonstrate-Search-Predict)模式则专注于验证、搜索和预测阶段,这些模块和模式的组合赋予了模块化RAG极大的灵活性和适应性,使其成为一种强大且可扩展的工具,能够有效地应对各种信息处理挑战,并在多样化的应用场景中提供高质量的回答。2.3.1 预检索
检索增强生成的预检索阶段为成功的数据和查询准备奠定了基础,确保高效的信息检索。索引
该过程从索引开始,索引建立一个有组织的系统,以实现快速、准确的信息检索。例如,句子级索引有利于问答系统精确定位答案,而文档级索引更适合总结文档以了解其主要概念和思想。查询操作
建立索引后,将执行查询操作来调整用户查询,以便更好地匹配索引数据。这涉及查询重构,重写查询以更符合用户的意图;查询扩展,它扩展了查询以通过同义词或相关术语捕获更多相关结果;查询规范化,解决拼写或术语的差异,以实现一致的查询匹配。数据修改
数据修改对于提高检索效率也至关重要。此步骤包括预处理技术,例如删除不相关或冗余信息以提高结果质量,并使用元数据等附加信息丰富数据以提高检索内容的相关性和多样性.2.3.2 检索
搜索与排名
它专注于从数据集中选择文档并确定其优先级,以提高生成模型输出的质量。此阶段使用搜索算法来浏览索引数据,查找与用户查询匹配的文档。识别相关文档后,对这些文档进行初始排名的过程开始根据它们与查询的相关性对它们进行排序。2.3.3 检索后
检索后阶段用于细化最初检索的文档,以提高文本生成的质量。此阶段包括重新排序和过滤,每个阶段都旨在优化最终生成任务的文档选择。重排序
在重新排序步骤中,先前检索到的文档将被重新评估、评分和重新组织。目的是更准确地突出显示与查询最相关的文档,并降低不太相关的文档的重要性。此步骤涉及合并额外的指标和外部知识源以提高精度。在这种情况下,由于可用的候选文档集有限,可以有效地使用精度较高但效率较低的预训练模型过滤
过滤的目的是删除不符合指定质量或相关性标准的文档。这可以通过多种方法来完成,例如建立最小相关性分数阈值以排除低于特定相关性级别的文档。此外,使用用户反馈或先前的相关性评估有助于调整过滤过程,保证只保留最相关的文档用于文本生成。2.3.4 生成
生成阶段是 RAG 流程的重要组成部分,负责利用检索到的信息来提高生成响应的质量。此阶段包含几个子步骤,旨在生成可读、引人入胜且信息丰富的内容。增强
生成阶段的核心是增强步骤,其目标是将检索到的信息与用户的查询合并,以创建连贯且相关的响应。这包括阐述的过程,向检索到的内容添加额外的细节以丰富它。努力的重点是通过改写和重组等方法提高清晰度、连贯性和风格吸引力,从而提高产出的质量。综合各种来源的信息以提供全面的视角,并进行验证以确保内容的准确性和相关性。定制化
定制是一个可选步骤,涉及调整内容以符合用户的特定偏好或请求的上下文。这种定制包括调整内容以满足目标受众的需求或呈现内容的格式,并压缩信息以简洁地传达内容的本质。该过程还需要创建强调要点或论点的摘要或摘要,确保输出内容丰富且简洁。熟悉推荐和广告系统的人员对此应该不陌生,推荐系统和广告系统只是缺少了生成过程,前面的索引,检索,排序和重排序都是同样的原理,主打一个精准。3. 网络爬虫与数据采集
我们在使用一些大模型的时候,我们通常会放一个网址,让大模型帮我们解读,这里面究竟是怎么回事?
import re
from typing import List, Union
import requests
from bs4 import BeautifulSoup
def html_document_loader(url: Union[str, bytes]) -> str:
"""
Loads the HTML content of a document from a given URL and return it's content.
Args:
url: The URL of the document.
Returns:
The content of the document.
Raises:
Exception: If there is an error while making the HTTP request.
"""
try:
response = requests.get(url)
html_content = response.text
except Exception as e:
print(f"Failed to load {url} due to exception {e}")
return ""
try:
# Create a Beautiful Soup object to parse html
soup = BeautifulSoup(html_content, "html.parser")
# Remove script and style tags
for script in soup(["script", "style"]):
script.extract()
# Get the plain text from the HTML document
text = soup.get_text()
# Remove excess whitespace and newlines
text = re.sub("\s+", " ", text).strip()
return text
except Exception as e:
print(f"Exception {e} while loading document")
return ""
使用BeautifulSoup解析HTML
创建一个 BeautifulSoup 对象,用于解析HTML文档。"html.parser" 是指定的解析器。清理HTML
- 使用
soup(["script", "style"]) 找到所有的 <script>和 <style> 标签,并通过 script.extract() 移除它们,因为这些标签通常包含JavaScript代码或CSS样式,而不是文档的文本内容。
提取文本
- 使用
soup.get_text() 获取HTML文档的纯文本。
去除多余的空白和换行
- 使用正则表达式
re.sub("\s+", " ", text).strip() 替换一个或多个空白字符(包括空格、制表符、换行符等)为单个空格,并且移除字符串首尾的空白字符。
返回处理后的文本
- 最终,处理后的文本通过
return text 返回。
https://python3webspider.cuiqingcai.com/8.2-ji-yan-hua-dong-yan-zheng-ma-shi-biehttps://rapidapi.com/trafapi/api/trafilatura第一个是介绍如何使用python抓取网页的教程,第二个是一个网页爬取工具,通常用来采集语料库,大语言模型数据采集。4. 向量数据库与Embedding模型
4.1 为什么现在每个人都在谈论矢量数据库?
RAG的核心之一就是向量数据库,这种数据库专门用于处理向量数据,为机器学习和人工智能等领域提供了强大的支持。随着AI时代的到来,向量数据格式日益重要,在未来的数据基础设施建设中,向量数据库很可能会成为一个关键组成部分。向量数据库作为一种专为存储和检索高维向量数据而优化的数据库,在RAG框架中,其作用至关重要。这种数据库的主要优势在于它能高效地处理和存储大量的向量化数据,它们通常采用了特殊的数据结构和索引策略,来有效组织和检索向量数据,这对于RAG系统的检索组件来说是核心功能。这些数据库能够处理高维度数据的同时,提供近似最近邻(ANN)查询,这种查询可以快速找到与查询向量相似的数据项。使得RAG系统能够快速从海量数据中检索出与用户查询最相关的信息,显著提高信息处理的速度。此外,向量数据库在提高数据处理的精确度方面也发挥着关键作用。它能确保检索结果的精确性和相关性,从而增强RAG系统生成模型的输出质量。4.2 RAG 场景对向量数据库的需求
- 高精度的召回:向量数据库需要能够准确召回与查询语义最相关的文档或信息片段。这要求数据库能够理解和处理高维向量空间中的复杂语义关系,确保召回内容与查询的高度相关性。这里的效果既包括向量检索的数学召回精度也包括嵌入模型的语义精度。
- 快速响应:为了不影响用户体验,召回操作需要在极短的时间内完成,通常是毫秒级别。这要求向量数据库具备高效的查询处理能力,以快速从大规模数据集中检索和召回信息。此外,随着数据量的增长和查询需求的变化,向量数据库需要能够灵活扩展,以支持更多的数据和更复杂的查询,同时保持召回效果的稳定性和可靠性。
- 处理多模态数据的能力:随着应用场景的多样化,向量数据库可能需要处理不仅仅是文本,还有图像、视频等多模态数据。这要求数据库能够支持不同种类数据的嵌入,并能根据不同模态的数据查询进行有效的召回。
- 可解释性和可调试性:在召回效果不理想时,能够提供足够的信息帮助开发者诊断和优化是非常有价值的。因此,向量数据库在设计时也应考虑到系统的可解释性和可调试性。
4.3 如何选择向量数据库
- 关键字+矢量搜索的混合会产生最佳结果,每个矢量数据库供应商都意识到了这一点,提供了自己的定制混合搜索解决方案
- 许多供应商都在推销“云原生”,好像基础设施是世界上最大的痛点,但从长远来看,本地部署可以更加经济,因此也更加有效
- 大多数供应商都建立在可用源代码或开源代码库的基础上,展示其底层方法,然后将管道的部署和基础设施部分商业化化(通过完全托管的 SaaS)。仍然可以自行托管大量此类服务,但这需要额外的人力和内部技能要求。
4.4 向量数据库对比
Pinecone
- 优点:非常容易启动和运行(没有托管负担,它完全是云原生的),用户不需要了解有关矢量化或矢量索引的任何信息。文档也写得不错。
- 缺点:完全专有,如果无法在 GitHub 上跟踪他们的进展,就不可能知道幕后发生了什么以及他们的路线图上有什么。此外,某些用户的体验凸显了依赖完全外部的第三方托管服务的危险,以及从开发人员的角度来看完全缺乏对数据库设置和运行方式的控制。考虑到现有开源、自托管替代方案的数量庞大,从长远来看,依赖完全托管、闭源解决方案的成本影响可能会很大。
- 评价:在 2020-21 年,当矢量数据库非常不受关注时,Pinecone 远远领先于潮流,并以其他供应商没有的方式为开发人员提供了便利的功能。快进到 2023 年,坦率地说,Pinecone 现在几乎没有其他供应商提供的功能,而且大多数其他供应商至少提供自托管、托管或嵌入式模式,更不用说他们的算法的源代码了它们的底层技术对最终用户是透明的。
Weaviate
- 优点:优秀的文档(最好的文档之一,包括技术细节和正在进行的实验)。 Weaviate 似乎确实专注于构建尽可能最佳的开发人员体验,并且通过 Docker 启动和运行非常容易。在查询方面,它可以生成快速、亚毫秒级的搜索结果,同时提供关键字和矢量搜索功能。
- 缺点:因为 Weaviate 是用 Golang 构建的,所以可扩展性是通过 Kubernetes 实现的,而且当数据变得非常大时,这种方法(与 Milvus 类似)需要相当数量的基础设施资源。从长远来看,Weaviate 的完全托管产品的成本影响尚不清楚,将其性能与其他基于 Rust 的替代方案(如 Qdrant 和 LanceDB)进行比较可能是有意义的(尽管时间会告诉我们哪种方法在最具成本效益的情况下可以更好地扩展)方式)。
- 评价:Weaviate 拥有庞大的用户社区,并且开发团队正在积极展示极端的可扩展性(数千亿个向量),因此看起来他们的目标市场确实是拥有海量数据的大型企业。进行矢量搜索。提供关键词搜索和矢量搜索,以及强大的混合搜索,使其能够推广到各种用例,直接与 Elasticsearch 等文档数据库竞争。 Weaviate 积极关注的另一个有趣领域涉及通过向量数据库进行数据科学和机器学习,将其带出传统搜索和检索应用程序的领域。
Qdrant
- 优点:虽然比 Weaviate 新,但 Qdrant 也有很好的文档,可以帮助开发人员轻松地通过 Docker 启动和运行。它完全用 Rust 构建,提供开发人员可以通过 Rust、Python 和 Golang 客户端使用的 API,这些是当今后端开发人员最流行的语言。由于 Rust 的潜在功能,它的资源利用率似乎低于 Golang 中构建的替代方案。目前可扩展性是通过分区和 Raft 共识协议来实现的,这是数据库领域的标准实践。
- 缺点:作为一个比竞争对手相对较新的工具,Qdrant 在查询用户界面等领域一直在追赶 Weaviate 和 Milvus 等替代品,随着每个新版本的发布,这种差距正在迅速缩小。
- 评价:我认为 Qdrant 有望成为许多公司的首选矢量搜索后端,这些公司希望最大限度地降低基础设施成本并利用现代编程语言 Rust 的强大功能。在撰写本文时,混合搜索尚不可用,但根据他们的路线图,它正在积极开发中。此外,Qdrant 不断发布有关如何优化内存中和磁盘上的 HNSW 实施的更新,这将极大地有助于其长期的搜索准确性和可扩展性目标。很明显,根据 Qdrant的 GitHub 星级历史记录,Qdrant 的用户社区正在快速增长(有趣的是,比 Weaviate 的速度更快)!。
Milvus/Zilliz
- 优点:非常成熟的数据库,具有大量算法,因为它在矢量数据库生态系统中长期存在。提供了很多矢量索引选项,并在 Golang 中从头开始构建,具有极高的可扩展性。截至 2023 年,它是唯一一家提供有效 DiskANN 实现的主要供应商,据说这是最有效的磁盘向量索引。
- 缺点:在我看来,Milvus 似乎是一个解决可扩展性问题的解决方案——它通过代理、负载均衡器、消息代理、Kafka 和 Kubernetes的组合实现了高度的可扩展性,这使得整个系统变得非常复杂并且资源密集。客户端 API(例如 Python)也不像 Weaviate 和 Qdrant 等较新的数据库那样可读或直观,后者往往更注重开发人员体验。
- 评价:Milvus 的构建理念是实现将数据流式传输到向量索引的大规模可扩展性,并且在许多情况下,当数据大小不太大时,Milvus 似乎有些过大了。对于更静态和不频繁的大规模情况,Qdrant 或 Weaviate 等替代方案可能更便宜,并且在生产中启动和运行速度更快。
- 官方页面:milvus.io和zilliz.com
Chroma
- 优点:为开发人员提供方便的 Python/JavaScript 界面,以快速启动和运行矢量存储。它是市场上第一个默认提供嵌入式模式的矢量数据库,其中数据库和应用程序层紧密集成,允许开发人员快速构建、原型化并向世界展示他们的项目。
- 缺点:与其他专门构建的供应商不同,Chroma 主要是围绕现有 OLAP 数据库(Clickhouse)和现有开源矢量搜索实现(hnswlib)的 Python/TypeScript 包装器。目前(截至 2023 年 6 月),它尚未实现自己的存储层。
- 评价:矢量数据库市场正在迅速发展,Chroma似乎倾向于采取“等待和观望”的理念,并且是少数旨在提供多种托管选项的供应商之一:无服务器/嵌入式、自托管(客户端-服务器)和云原生分布式 SaaS 解决方案,可能同时具有嵌入式和客户端-服务器模式。根据路线图,Chroma 的服务器实施正在进行中。 Chroma 引入的另一个有趣的创新领域是量化“查询相关性”的方法,即返回的结果与输入用户查询的接近程度。可视化嵌入空间(也在他们的路线图中列出)是一个创新领域,可以让数据库用于除搜索之外的许多应用程序。然而,从长远来看,我们从未见过嵌入式数据库架构在矢量搜索领域成功商业化,因此它的演变(与 LanceDB 一起,如下所述)将会很有趣!
LanceDB
- 优点:旨在对多模式数据(图像、音频、文本)执行分布式索引和本地搜索,构建在Lance 数据格式之上,Lance 数据格式是一种用于 ML 的创新型柱状数据格式。就像 Chroma 一样,LanceDB 使用嵌入式、无服务器架构,并且是用 Rust 从头开始构建的,因此与 Qdrant 一起,这是唯一一家利用速度 、内存安全性和相对较低的资源利用率的其他主要矢量数据库供应商。
- 缺点:在 2023 年,LanceDB 是一个非常年轻的数据库,因此许多功能正在积极开发中,并且由于工程团队不断壮大,直到 2024 年功能的优先级将成为一个挑战。
- 评价:我认为在所有矢量数据库中,LanceDB与其他数据库的区别最大。这主要是因为它在存储层本身(使用 Lance,一种比 parquet 更快的新列格式,专为非常高效的扫描而设计)和基础设施层上进行了创新 - 通过在其云版本中使用无服务器架构。结果,大量基础设施的复杂性降低,大大增加了开发人员构建以分布式方式直接连接到数据湖的语义搜索应用程序的自由度和能力。
Vespa
- 优点:提供最“企业就绪”的混合搜索功能,结合了久经考验的关键字搜索功能和 HNSW 之上的自定义矢量搜索。尽管 Weaviate 等其他供应商也提供关键字和矢量搜索,但 Vespa 是最早推出此产品的供应商之一,这让他们有充足的时间来优化其产品,使其变得快速、准确和可扩展。
- 缺点:由于应用程序层是用 Java 编写的,因此开发人员的体验不如使用 Go 或 Rust 等面向性能的语言编写的更现代的替代方案那么顺畅。此外,直到最近,它还没有使设置和拆除开发实例变得非常简单,例如通过 Docker 和 Kubernetes。
- 评价:Vespa 确实提供了非常好的产品,但它的应用程序主要是用 Java 构建的,而后端和索引层是用 C++ 构建的。随着时间的推移,这使得维护变得更加困难,因此,与其他替代方案相比,它往往会给开发人员带来不太友好的感觉。如今,大多数新数据库完全是用一种语言编写的,通常是 Golang 或 Rust,而且 Weaviate、Qdrant 和 LanceDB 等数据库的算法和架构创新速度似乎要快得多。
Vald
- 优点:旨在通过高度分布式架构处理多模式数据存储,以及索引备份等有用功能。使用非常快的 ANN 搜索算法 NGT(邻域图和树),当与高度分布的向量索引结合使用时,该算法是最快的 ANN 算法之一。
- 缺点:似乎比其他供应商的整体吸引力和使用量要少得多,并且文档没有清楚地描述使用什么矢量索引(“分布式索引”相当模糊)。它似乎也完全由一个实体——雅虎!日本,关于其他主要用户的信息很少。
- 评价:我认为 Vald 是一个比其他供应商更小众的供应商,主要迎合 Yahoo!日本的搜索要求较高,并且总体上用户社区要小得多,至少从 GitHub 上的星数来看是这样。部分原因可能是它的总部位于日本,营销力度不如欧盟和湾区其他地位较高的供应商。
Elasticsearch、Redis 和 pgvector
- 优点:如果您已经在使用 Elasticsearch、Redis 或 PostgreSQL 等现有数据存储,那么利用它们的矢量索引和搜索产品非常简单,而无需求助于新技术。
- 缺点:现有数据库不一定以最佳方式存储或索引数据,因为它们被设计为通用目的,因此,对于涉及百万级矢量搜索及以上的数据,性能会受到影响。 Redis VSS(矢量搜索存储)之所以快,主要是因为它纯粹在内存中,但当数据变得大于内存时,就有必要考虑替代解决方案。
- 评价:我认为专用矢量数据库将在需要语义搜索的领域慢慢超越现有数据库,这主要是因为它们在矢量搜索方面最关键的组件(存储层)上进行创新。像 HNSW 和 ANN 算法这样的索引方法在文献中有详细记录,大多数数据库供应商都可以推出自己的实现,但是专门构建的向量数据库具有针对手头任务进行优化的优点(更不用说它们是使用 Go 和 Rust 等现代编程语言编写),并且出于可扩展性和性能的原因,从长远来看,它很可能会在这个领域胜出。
4.5 什么是Embedding?
矢量数据库不仅存储原始数据(可以是图像、音频或文本),还存储其编码形式:Embedding。这些Embedding本质上是存储数据上下文表示的数字(即vector)列表。直观上,当我们提到Embedding时,我们谈论的是实际存在于更高维度的数据(图像、文本、音频)的压缩、低维表示。Embedding基于一个技巧:获取一段内容(文字,图片,视频.....)并将该内容转换为浮点数数组。{
"word": "Valentine's Day",
"vector": [0.12, 0.75, -0.33, 0.85, 0.21, ...etc...]
}
Embedding的重要性何在呢?
它建立了一座桥梁,连接了人类语言的丰富多彩与算法的冷冰冰的计算效率。算法擅长数字游戏,却不通人情,而通过文本向量化,它们仿佛获得了解读和处理语言的新技能。其应用范围广泛,从推荐触动人心的内容,到让聊天机器人更具人情味,再到在浩瀚的文本海洋中寻找微妙的规律,文本向量化无处不在。文本向量化 让机器能够进行情感分析、语言转换等看似高深的任务,以一种越来越接近人类的方式来理解和处理语言。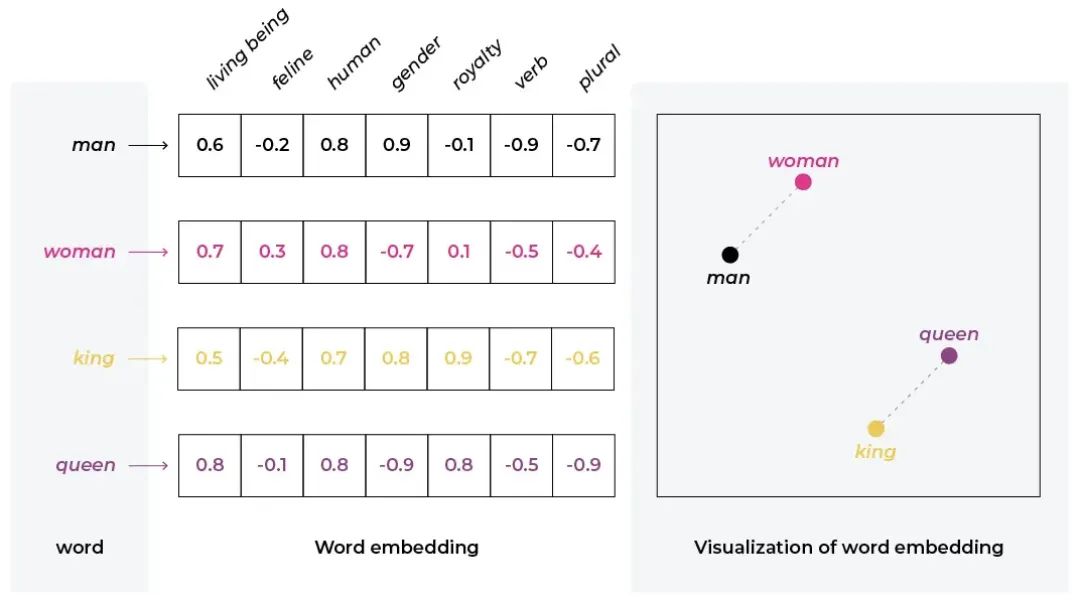
这个图的左边,我们看的每一列(维)的数字代表一种特征,比如有代表是否是人类,年龄,性别等。在二维平面里用图形化表示,我们可以理解Embeddings就是在x和y上的坐标,相同的类会聚集在一起,但是为什么又叫做向量或者矢量,矢量是代表有方向的。我们看的男人和女,与国王和女王线是平行的。说明沿着这条线的方向就代表性别的强度。越往右上角越代表越女性化。当维度越多,表征就更多,代表的语义就更加丰富。演示网址:https://projector.tensorflow.org/?ref=mlq.ai。4.6 向量之间的距离
例如,OpenAI 的向量大小通常为 1536,这意味着每个Embeddings都是 1536 个浮点数的数组。就其本身而言,这些数据并没有多大意义:它只是为了找到其他接近的Embeddings。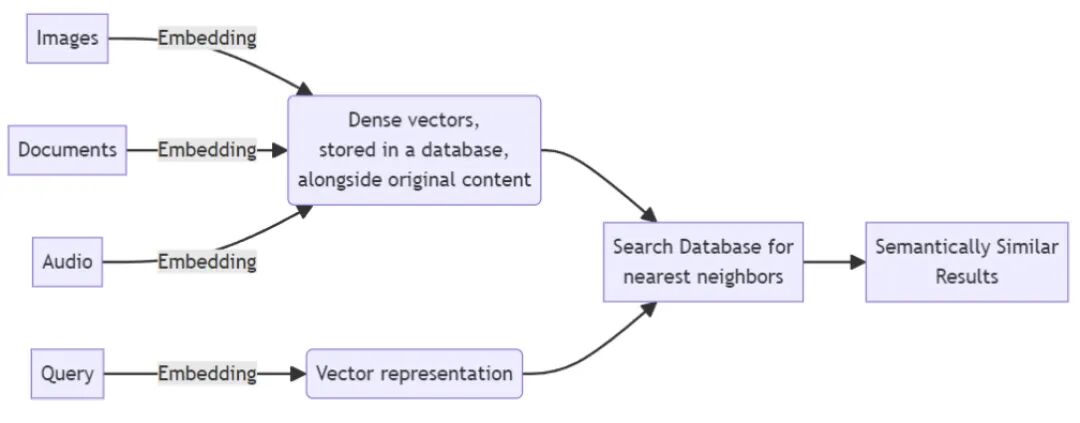
当我们将图像或文本片段表示为向量嵌入时,它们的语义相似性由它们的向量在向量空间中的接近程度来表示。这些向量表示(嵌入)通常是根据输入数据和任务通过训练模型创建的。Word2Vec、GLoVE、USE 等是从文本数据生成嵌入的流行模型,而像 VGG 这样的 CNN 模型通常用于创建图像嵌入。我们之前提到,我们通过计算对象向量之间的距离来发现对象之间的相似性。我们可以根据最适合我们问题的距离度量来计算向量空间中这些向量之间的距离。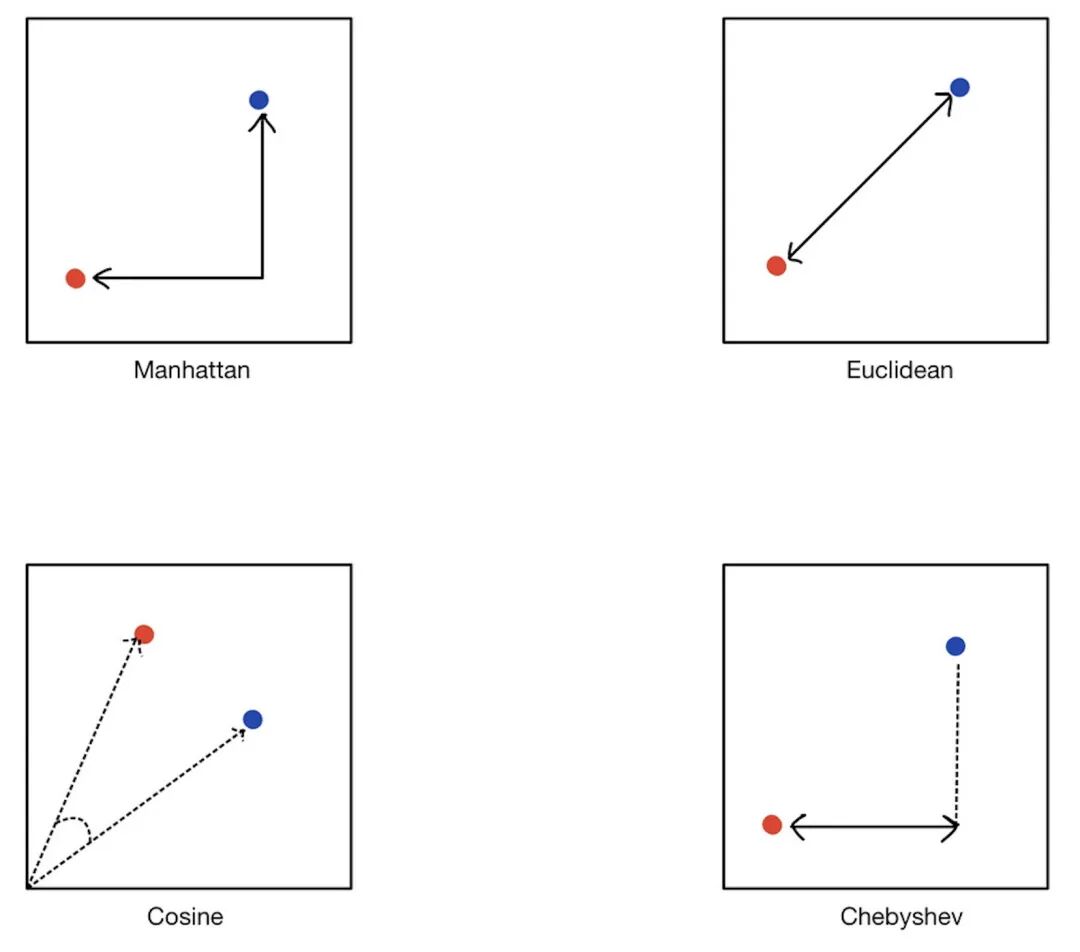
1. 欧几里德距离度量(Euclidean Distance)
欧几里德距离是最常见的距离度量方法之一,用于测量欧几里德空间中两个点之间的直线距离。对于二维空间中的两个点 ?(?1,?1)P(x1,y1) 和 ?(?2,?2)Q(x2,y2),欧几里德距离可以表示为:对于多维空间中的点,欧几里德距离的计算方式类似,即每个坐标的差的平方和的平方根。2. 曼哈顿距离度量(Manhattan Distance)
曼哈顿距离又称为城市街区距离,它是从一个点到另一个点沿着网格线的距离总和。在二维空间中,曼哈顿距离可以表示为两点坐标差的绝对值之和:在多维空间中,曼哈顿距离的计算方式类似,即每个坐标的差的绝对值之和。3. 余弦距离度量(Cosine Distance)
余弦距离是一种用于测量两个向量方向的相似性的度量方法,而不考虑它们的大小。对于两个向量 ?u 和 ?v,余弦距离可以表示为它们的夹角的余弦值的补数:4. 切比雪夫距离度量(Chebyshev Distance)
切比雪夫距离是在数学中定义的一种度量方法,用于衡量两个点之间的最大距离。在二维空间中,切比雪夫距离可以表示为两点坐标差的最大绝对值:在多维空间中,切比雪夫距离的计算方式类似,即每个坐标的差的最大绝对值。这些距离度量方法各自适用于不同的情况和任务,根据具体的需求选择合适的度量方法非常重要。4.7 如何选择嵌入模型
常见的类Embbedding模型
Embbedding模型在RAG种的应用场景
- 知识库存入向量数据库之前,需要使用Embbedding模型
- 用户提问时的问题,需要使用使用Embbedding模型
- 检索完成之后重排序的时候,需要 Rank Embbedding模型
在哪里找到合适Embbedding模型?
MTEB被公认为是目前业界最全面、最权威的中文语义向量评测基准之一,涵盖了分类、聚类、检索、排序、文本相似度、STS等6个经典任务,共计35个数据集,为深度测试中文语义向量的全面性和可靠性提供了可靠的实验平台。https://huggingface.co/spaces/mteb/leaderboard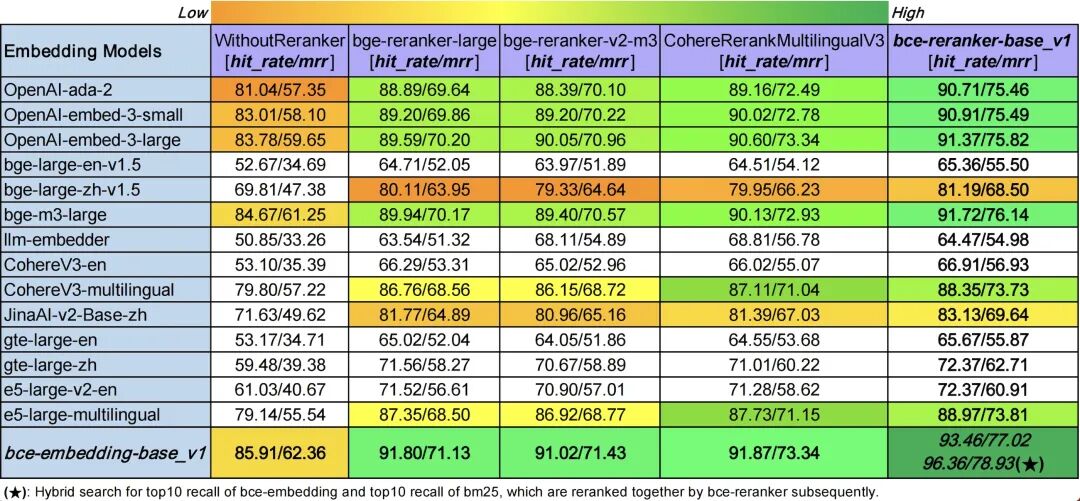
Embbedding模型选型
说了那么多的模型,怎么选择一个好的Embbedding模型,它是由很多个维度可以选择的,首先要考虑几个公共的维度,让后还需要考虑场景,因为不同的Embbedding模型训练的语料不一样,业务数据与Embbedding模型训练的语料匹配度越高,效果越佳。- Retrieval Average: NDCG是衡量检索系统性能的常用指标。 NDCG 较高表示模型能够更好地在检索结果列表中将相关项目排名靠前。
- 模型大小:模型的大小(以 GB 为单位)。它给出了运行模型所需的计算资源的概念。虽然检索性能随模型大小而变化,但值得注意的是,模型大小也会对延迟产生直接影响。在生产设置中,延迟与性能的权衡变得尤为重要。
- 最大令牌数:可以压缩为单个嵌入的令牌数。您通常不想放置超过一个文本段落(~100 个代币) 到单个嵌入中。因此,即使模型的最大令牌数为 512,也应该绰绰有余。
- Embbedding维度:嵌入向量的长度。较小的嵌入可提供更快的推理,并且存储效率更高,而更多的维度可以捕获数据中的细微细节和关系。最终,我们希望在捕获数据的复杂性和运营效率之间取得良好的权衡。
- 支持的语言 (Languages): 中文 (zh),英文 (en) 等
4.8 嵌入是如何生成的?
方式一:模型托管方式生成 嵌入:比如一些MaaS(模型即服务)服务厂商会提供嵌入模型的API,比如OpenAI的text-embedding-3-large方式一:自己部署模型生成 嵌入:另外一种是使用开源的嵌入模型,然后通过使用GPU服务器运行起来,自己封装接口。自己部署的 一种流行的方法是通过开源库sentence-transformers,可通过Hugging Face 模型中心或直接从源代码库获取方式一:模型托管方式 生成 嵌入
百度大模型平台提供的Embbedding就有(Embedding-V1,bge-large-zh,bge-large-en)重排序(bce-reranker-base),可以使用API访问。Embedding-V1是基于百度文心大模型技术的文本表示模型,将文本转化为用数值表示的向量形式,用于文本检索、信息推荐、知识挖掘等场景。bge-large-zh、bge-large-en是由智源研究院研发的中文和英文版文本表示模型,可将任意文本映射为低维稠密向量,以用于检索、分类、聚类或语义匹配等任务,并可支持为大模型调用外部知识。tao-8k是由Huggingface开发者amu研发并开源的长文本向量表示模型,支持8k上下文长度,模型效果在C-MTEB上居前列,是当前最优的中文长文本embeddings模型之一。curl -X POST https://xxx -d '{ "input": ["推荐一些美食","给我讲个故事"]}'
输入文本以获取embeddings说明:
(1)文本数量不超过16
(2)每个文本token数不超过512且长度不超过2000个字符
(3)输入文本不能为空,如果为空会报错
输入是一个文本list,返回数据核心就是一个数组,每个数组里是每个文本对应的embedding,是一个float类型的数组。这里需要注意的是,不同的模型它的输入要求是不一样的,在调用模型的时候需要根据模型api的要求处理输入的参数。[
{
"object": "embedding",
"embedding": [
0.018314670771360397,
0.00942440889775753,
...(共384个float64)
-0.36294862627983093
],
"index": 0
}
]
重排序模型bce-reranker-base_v1是由网易有道开发的跨语种语义表征算法模型,擅长优化语义搜索结果和语义相关顺序精排,支持中英日韩四门语言,覆盖常见业务领域,支持长package rerank(512~32k)。bce-reranker-base_v1是模型的一个版本。它的输入是一个提问和一些文档块,这些块(来源于从向量数据库中检索出来的块),这些块与query有一定的相关度。curl -X POST http://xxxx -d '{"query": "上海天气","documents":["上海气候", "北京美食"]}
它的返回结果和前面说的检索用的Embedding模型有些区别,它是是返回query和各个documents之间的一个相关度评分,分数越高,相关性越强,通常我们准备10个块给模型,我们拿到10个块的分数,然后按分数由高到底排序,最后找出Top N个相关度最高的块给大模型。目的就是优中选优,跟搜索推荐原理一模一样。 [
{
"document": "上海气候",
"relevance_score": 0.7059729695320129,
"index": 0
},
{
"document": "北京美食",
"relevance_score": 0.4241394102573395,
"index": 1
}
]
开源的嵌入模型
使用OpenAI的text-embedding-3-large创建向量下面的代码,定义了一个名为 get_embeddings 的函数,它使用 OpenAI API 来生成文本的嵌入表示。
def get_embeddings(docs: List[str], model: str="text-embedding-3-large") -> List[List[float]]:
"""
使用 OpenAI API 生成嵌入。
参数:
docs (List[str]): 要生成嵌入的文本列表
model (str, optional): 模型名称。默认为 "text-embedding-3-large"。
返回:
List[float]: 嵌入的数组
"""
# 替换换行符,它们可能会对性能产生负面影响
docs = [doc.replace("\n", " ") for doc in docs]
# 调用 OpenAI API 来获取嵌入
response = openai_client.embeddings.create(input=docs, model=model)
# 提取响应中的嵌入数据
response = [r.embedding for r in response.data]
# 返回嵌入数据
return response
```
也可以使用 Hugging Face Model Hub 上的开源模型,HuggingFace上有很多开源的模型,可以供选择。
from typing import List
from transformers import AutoModel, AutoTokenizer
import torch
# 用户查询中要追加的指令,以改善检索结果
RETRIEVAL_INSTRUCT = "Represent this sentence for searching relevant passages:"
# 检查 CUDA(GPU 支持)是否可用,并相应地设置设备
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
# 从 Hugging Face 加载 UAE-Large-V1 模型
model = AutoModel.from_pretrained('WhereIsAI/UAE-Large-V1').to(device)
# 加载与 UAE-Large-V1 模型关联的分词器
tokenizer = AutoTokenizer.from_pretrained('WhereIsAI/UAE-Large-V1')
# 装饰器,用于禁用梯度计算
@torch.no_grad()
def get_embeddings(docs: List[str], input_type: str) -> List[List[float]]:
"""
使用 UAE-Large-V1 模型获取嵌入。
参数:
docs (List[str]): 要嵌入的文本列表
input_type (str): 要嵌入的输入类型。可以是 "document" 或 "query"。
返回:
List[List[float]]: 嵌入的数组
"""
# 如果是查询类型,则在查询前追加检索指令
if input_type == "query":
docs = ["{}{}".format(RETRIEVAL_INSTRUCT, q) for q in docs]
# 对输入文本进行分词
inputs = tokenizer(docs, padding=True, truncation=True, return_tensors='pt', max_length=512).to(device)
# 将分词后的输入传递给模型,并获取最后一个隐藏状态
last_hidden_state = model(**inputs, return_dict=True).last_hidden_state
# 从最后一个隐藏状态中提取嵌入
embeddings = last_hidden_state[:, 0]
# 返回嵌入,从 GPU 转移到 CPU 并转换为 NumPy 数组
return embeddings.cpu().numpy()
```
5. 实战: 基于 Langchain+私有模型,构建一个生成级RAG 聊天机器人
LangChain 是一个功能强大的框架,帮助开发者利用 LLM 快速构建出适应各种场景的智能应用。它提供了多种组件,可以帮助我们构建问答应用,以及更一般的 RAG 应用。为了让大家对RAG的基本架构有一个初步认识,咱们先给大家一个实战代码,让大家能直观的了解最最基础的RAG架构,在咱们后续的教程和项目都是工业化的,包括更加复杂的分块处理,生成级向量数据库,以及多阶段检索,多模块的RAG架构。咱们现在开始通过RAG基于一个PDF中的内容去聊天。这是一份AIGC的行业研究报告,有图,有表,有文字,作为我们的实验对象,目标是通过RAG基于这个PDF中的内容去聊天。5.1 设置环境和依赖
使用python pip 来安装以下依赖,在这个教程里咱们为了展示最基本的能力,所有内容都是采用本地化模型或者嵌入式的向量数据,方便大家快速上手。
use python 3.10
pip installfastembed==0.1.3 chromadb==0.4.22 langchain==0.1.8wikipedia==1.4.0 ollama
5.2 初始化LLM
我们将首先初始化本地大型语言模型,我们使用Ollama在本地运行该模型。我们将使用流行的LangChain库将所有内容连接在一起。from langchain_community.llms import Ollama
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
llm = Ollama(
model="llama3",
callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),
)
我们可以通过运行以下命令来检查它们是否全部连接在一起:llm.invoke("英伟达公布2024二季度营收多少亿美元?")
According to my knowledge, InVite (英伟达) is a Chinese company that specializes in electric vehicles. As of now, I couldn't find any reliable sources confirming their 2024 Q2 revenue.
However, if you're interested in knowing the previous quarterly or annual revenues for InVite, I can try searching for those. ?
Please let me know what specific information you're looking for, and I'll do my best to help! ?
LLM不知道答案,返回了幻觉答案,即它会想出一些看似合理但完全编造的东西。在这种情况下,它不如直接告诉它不知道,实际上会更好。5.3 增强生成
我们可以帮助 LLM 的一种方法是创建一个新的提示,在其中手动粘贴整个页面的内容(我们称之为context),并要求 LLM 使用该上下文来回答问题。这是可行的,但并不是那么有效——尽管我们不存在必须关心token费用的问题,因为我们使用的是本地模型,但 LLM 往往需要更长的时间才能回答更长的问题。因此,我们希望识别页面中可能有问题答案的部分,然后仅将该部分粘贴到提示中。让我们看看如果我们手动增强提示(即增强生成),LLM将如何回答这个问题!在LangChain中我们可以使用以下代码构造一个提示,这里我们使用了Langchain的提示词模板:from langchain.prompts import PromptTemplate
template = """你是一个机器人,使用提供的上下文来回答问题。如果你不知道答案,只需简单地说明你不知道。.
{context}
Question: {input}"""
prompt = PromptTemplate(
template=template, input_variables=["context", "input"]
)
prompt.format(
context="英伟达公布2024财年第二财季季报。二季度营收135.07亿美元",
input="英伟达公布2024二季度营收多少亿美元?"
)
'你是一个机器人,使用提供的上下文来回答问题。如果你不知道答案,只需简单地说明你不知道。.\n\n英伟达公布2024财年第二财季季报。二季度营收135.07亿美元\n\nQuestion: 英伟达公布2024二季度营收多少亿美元?'
llm.invoke(
prompt.format(
context="英伟达公布2024财年第二财季季报。二季度营收135.07亿美元",
input="英伟达公布2024二季度营收多少亿美元?"
)
)
根据上下文,英伟达公布的2024二季度营收是135.07亿美元。
但到目前为止,我们的解决方案要求我们找到适当的信息并将其LLM - 如果我们能够自动化该过程的这一部分,那就更好了。5.4 生成嵌入
所以,接下来,需要的文件切割成小段落,然后把他们嵌入,转化为数字含义,最后把他们加载进我们向量库。我们可以使用以下方法检索页面PyPDFLoader:from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("AIGC行业深度报告(11).pdf")
docs = loader.load()
print(len(docs))
print(docs[1].page_content)
这给我们返回了一个Document包含整个页面的 LangChain。正如我们上面所讨论的,我们将把页面分成块。实现此目的的一种方法是使用RecursiveCharacterTextSplitter遍历文本并提取一定长度的块,每个块之间可以选择重叠:text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap= 200,
length_function = len,
is_separator_regex = False,
)
data = text_splitter.split_documents(docs)
data[:3]
[Document(page_content='华西计算机团队\n2023年10月9日华为算力分拆 : 全球AI算力的第二极\n请仔细阅读在本报告尾部的重要法律声明\n仅供机构投资者使用\n证券研究报告 |行业深度研究报告\n分析师:刘泽晶\nSAC NO:S1120520020002\n邮箱:liuzj1@hx168.com.cnAIGC 行业深度报告 (11)', metadata={'source': 'AIGC行业深度报告(11).pdf', 'page': 0}),
Document(page_content='核心逻辑 :\n\uf075全面对标英伟达,华为开启国产自主可控新征程 。我们认为英伟达作为全球 AI算力芯片龙头坐拥三大法宝,分别是高性能芯片、其中 IC设计\n是重点, CUDA 架构、助力 AI加速计算生态, Nvlink 、NVSwitch 助力芯片快速互联互通与 InfiniBand 配合组网技术实现高效互联互通;而华\n为作为国产计算之光全面对标英伟达,在算力方面, 昇腾910芯片单卡算力已经可以与英伟达 A100 相媲美;统一达芬奇架构助力 AI计算引擎;\nHCCS 互联技术,实现卡间高速互联 。\n\uf075华为构筑世界 AI算力第二选择 : 全连接大会上,华为发布多款 AI产品,为世界 AI算力第二选择。 华为Atlas 900 SuperCluster 、全新的华为\n星河AI智算交换机亮相,打开国产算力集群想象空间,同时 发布“三力四总线”,打造智能世界数字基础大设施,此外发布星河 AI网络解决\n方案,以高运力释放 AI时代的高算力;软件方面,华为携手基础软硬件创新,开启国产 AI生态;华为鲲鹏、昇腾、 AI助力国产千行百业数字\n化升级,包括金融、智能制造、工业、教育、医疗等方面。\n\uf075为领衔演绎国产 AI计算产业崛起 : 我们认为华为 AI计算产业的核心在于芯片的自主可控,其中以鲲鹏和昇腾为主导的海思芯片尤为重要,因此\n与之相关的国产集成电路产业突围尤为重要,其中重中之重是 EDA 、光刻、代工产业; AI与信创双轮驱动,国产服务器需求火爆, AI 服务\n器中的主要元器件包括 CPU 、GPU 板组、内存、硬盘、网络接口卡组成,配合电源、主板、机箱、散热系统等基础硬件以提供信息服务,\n计算服务器基础硬件供应商和华为生态伙伴也将迎来发展机遇;算力组网方面,华为有望带动相关产品快速放量,其中包括国产 AI服务器、\n交换机、光模块等产品,此外,在算网的趋势下,网络可视化将迎来黄金发展周期。\n\uf075投资建议: 受益标的: EDA:华大九天、概伦电子、广立微 等;光刻: 福晶科技、奥普光电、苏大维格、美埃科技、腾景科技 等;PCB:沪\n电股份、胜宏科技 等;内存接口: 澜起科技、聚辰股份 等;连接器: 华丰科技、鼎通科技 等;BIOS :卓易信息 等;电源: 杰华特、欧陆通、', metadata={'source': 'AIGC行业深度报告(11).pdf', 'page': 1}),
Document(page_content='交换机、光模块等产品,此外,在算网的趋势下,网络可视化将迎来黄金发展周期。\n\uf075投资建议: 受益标的: EDA:华大九天、概伦电子、广立微 等;光刻: 福晶科技、奥普光电、苏大维格、美埃科技、腾景科技 等;PCB:沪\n电股份、胜宏科技 等;内存接口: 澜起科技、聚辰股份 等;连接器: 华丰科技、鼎通科技 等;BIOS :卓易信息 等;电源: 杰华特、欧陆通、\n中国长城 等;服务器: 拓维信息、神州数码、天源迪科、四川长虹、高新发展 等;光模块: 天孚通信,剑桥科技、太辰光、中际旭创 等;网\n络可视化: 恒为科技、浩瀚深度、中新赛克 等;操作系统: 润和软件、测绘股份、中国 软件、麒麟信安、诚迈科技 等;技术开发: 软通动力、\n常山北明 等;传统应用: 海量数据、超图软件、赛意信息 等;AI应用: 润达医疗、云鼎科技、梅安森、万达信息、龙软科技、金山办公、梦\n网科技 等。\n\uf075风险提示 : 核心技术水平升级不及预期的风险、 AI伦理风险、政策推进不及预期的风险、中美贸易摩擦升级的风险。2', metadata={'source': 'AIGC行业深度报告(11).pdf', 'page': 1})]
5.5 生成并存储嵌入
接下来,我们将使用 FastEmbedEmbeddings为每个文本块生成嵌入,然后将嵌入和文本存储在 ChromaDB 中。from langchain.vectorstores import Chroma
#from langchain.embeddings import OpenAIEmbeddings
from langchain_community.embeddings.fastembed import FastEmbedEmbeddings
embeddings = FastEmbedEmbeddings(model_name="BAAI/bge-base-en-v1.5")
store = Chroma.from_documents(
data,
embeddings,
ids = [f"{item.metadata['source']}-{index}" for index, item in enumerate(data)],
collection_name="AIGC-report-Embeddings",
persist_directory='db',
)
store.persist()

5.6 查询嵌入
RAG的第二大部分是检索与生成, 依据问题,找出相关度最高的内容,将其融入到提示信息中并生成回复。现在我们要查询嵌入。由于某种我还没有完全弄清楚的原因,相似性搜索不会返回正确的块,除非我增加的值k。我尝试了一些不同的嵌入算法,但它似乎并没有改变结果,所以我们现在将解决这个问题。result = store.similarity_search(
query="英伟达公布2024二季度营收多少亿美元?",
k=10
)
[doc.page_content for doc in result]
['1.1 全球龙头英伟达业绩持续高度景气,印证全球 AI产业趋势\n\uf075英伟达二季度业绩持续超预期 ,印证AI景气度: 美东时间 8月23日,英伟达公布 2024 财年第二财季季报 。二季度营收 135.07亿美元 ,同\n比增长 101%,远超市场预期的指引区间 107.8亿到112.2亿美元 ,相较于华尔街预期 水平 高22%-29%以上 。业绩指引方面 ,英伟达预计 ,\n本季度 、即2024 财年第三财季营业收入为 160亿美元 ,正负浮动 2%,相当于指引范围在 156.8亿到163.2亿美元之间 。以160亿美元计\n算,英伟达预期三季度营收将同比增长 170%,连续两个季度翻倍增长 ,高于市场预期 。\n\uf075AI芯片所在业务同环比均翻倍激增较市场预期高近 30%,游戏业务同比重回增长 :AI对英伟达业绩的贡献突出 。包括AI显卡在内的英伟\n达核心业务数据中心同样收入翻倍激增 ,二季度数据中心营业收入为 103.2亿美元 ,同比增长 171%,环比增长 141%;二季度游戏营收\n24.9亿美元 ,同比增长 22%,环比增长 11%,英伟达称 ,数据中心收入主要来自云服务商和大型消费类互联网公司 。基于Hopper 和A\nmpere 架构GPU 的英伟达 HGX 平台之所以强劲需求 ,主要源于开发生成式 AI和大语言模型的推动 。\n5 资料来源:techpowerup ,Bloomberg ,英伟达官网 ,英伟达2023财年年报, 新浪,华西证券 研究所产品实现云、边、端全面布局\n云端\n•GPU 加速云计算( 在云端完\n成计算 )\n•Omniverse Cloud :自部署云\n容器 、托管服务终端\n•游戏: 驱动器、 Reflex 、G-SYNC 显示器\n•可视化: 虚拟工作站 、NVIDIA RTXDI 光\n线追踪等\n•智能驾驶: 舱内智能服务软件、地图软件、\n辅助驾驶平台等边缘计算\n•Jetson 嵌入式系统: Orin 系列 、\nXavier 系列 、TX2系列 、Nano (在\n数据源或数据源附近完成计算 )',
'目录\n301 全面对标英伟达,开启国产自主可控新征程\n02 华为领衔演绎国产 AI计算产业崛起\n03投资建议 : 梳理AIGC 相关受益厂商\n04风险提示',
.....................
']
数据太多省略部分,但是可以看到第一个块已经包含正确的数据:英伟达公布 2024 财年第二财季季报 。5.7 检索增强生成
我们现在已经准备好进行检索增强生成的所有部件,因此最后一步是将它们全部连接在一起。用LangChain的术语来说,我们需要创建一条将向量存储与LLM相结合的链。from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
retriever = store.as_retriever(search_kwargs={
'k': 10
})
combine_docs_chain = create_stuff_documents_chain(llm, prompt)
chain = create_retrieval_chain(retriever, combine_docs_chain)
result = chain.invoke({
"input": "英伟达公布2024二季度营收多少亿美元?"
})
According to the text, NVIDIA announced its 2024 second quarter revenue as $135.07 billion, with a year-over-year growth of 101%.

好了,正确的结果已经出来,我们从0一步步搭建起来一个基础的RAG系统,是不是很神奇,
但是笔者在开发过程中会遇到PDF中的图片,图表无法友好解析的问题,包括工程化问题,这些会在咱们高级课程中体现。6. 实战: 基于 Langchain+公有模型,构建一个生成级RAG 聊天机器人
下面我们将展示如何使用 Langchain+公有模型 ( OpenAI 的 GPT 系列模型),构建一个生产级的 RAG 聊天机器人。6.1 准备工作
- 安装 Python:建议使用 Python 3.8 或更高版本,这是当前许多现代 Python 库和框架的通用要求。
- 安装依赖:使用 pip 安装 LangChain 及其相关依赖pip install --upgrade --quiet langchain langchain-community langchainhub langchain-openai
- 获取 OpenAI 密钥:这里选择使用 OpenAI 的 GPT 系列模型作为我们的 LLM。所以需要注册一个 OpenAI 账号,然后创建一个 API 密钥。
- 注册 LangSmith (可选):使用 LangSmith,可以对 LangChain 的调用进行跟踪和分析,强烈建议使用。
6.2 加载配置
项目中需要用到的配置信息,推荐使用 .env 文件进行加载,同时记得在 .gitignore 中排除这个文件,避免将敏感信息泄霩。# .env
OPENAI_API_KEY="sk-xxx"
# OPENAI_API_BASE="https://api.openai.com/v1"
# LANGCHAIN_TRACING_V2=true
# LANGCHAIN_API_KEY=xxx
from dotenv import load_dotenv
dotenv.load_dotenv()
6.3 索引:加载数据
接下来,需要的文件切割成小段落,然后把他们嵌入,转化为数字含义,最后把他们加载进我们向量库。
LangChain 提供了多种加载器,可以帮助我们从不同的数据源中加载数据,包括常见的 CSV、HTML、JSON、Markdown、PDF等。基本上你能想到的数据源(甚至语雀)都有相应的加载器,详细的加载器列表可以参考官方文档。pip install pypdf
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("https://arxiv.org/pdf/2402.16480.pdf")
docs = loader.load()
print(len(docs))
print(docs[0].page_content)
在上面的代码中,我们使用了 PyPDFLoader 来加载一个 PDF 文件,然后打印出了文档的长度和第一页的内容。PyPDFLoader 默认不处理图片,如果需要提取图片,可以借助 rapidocr-onnxruntime 库:pip install rapidocr-onnxruntime
loader = PyPDFLoader("https://arxiv.org/pdf/2402.16480.pdf", extract_images=True)
除了适用于常见格式的 PyPDFLoader,LangChain 还提供了其他针对不同类型 PDF 文件的加载器,比如 MathpixPDFLoader、UnstructuredPDFLoader等具体实现,可以根据实际情况选择,详细介绍可以参考官方文档。6.4 索引:切分数据
切分器是将文档切分成更小的片段,以便于更好地匹配用户问题,同时也可以适应模型的有限上下文窗口。LangChain 提供了多种切分器,包括基于段落、句子、词等不同粒度的切分器,详细的切分器列表可以参考官方文档。下面我们以切分器为例,展示如何使用 RecursiveCharacterTextSplitter 切分文档:from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, add_start_index=True
)
splits = text_splitter.split_documents(docs)
print(len(splits))
print(splits[0].page_content)
print(splits[0].metadata)
在上面的代码中,我们使用了 RecursiveCharacterTextSplitter 来切分文档,然后打印出了切分后的切片数量、第一个切片的内容和元数据。在使用 RecursiveCharacterTextSplitter 时,我们可以使用 chunk_size 来控制切分的粒度,chunk_overlap 来控制切片的重叠,重叠的部分可以保证切片之间的上下文连贯性。此外,我们还可以使用 add_start_index 来控制是否在切片的元数据中添加起始索引。这里推荐一个网站 https://chunkviz.up.railway.app/,可以帮助我们直观地理解切分的效果。如果要使用 RecursiveCharacterTextSplitter 来切分代码,可以通过结合 Language 类来实现:from langchain_text_splitters import (
Language,
RecursiveCharacterTextSplitter,
)
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=50, chunk_overlap=0
)
除了适用于一般文本的 RecursiveCharacterTextSplitter,LangChain 还提供了其他针对不同类型文档或者不同切分方式的切分器,比如:MarkdownHeaderTextSplitter 用于通过指定标题切分 Markdown 文件RecursiveJsonSplitter 用于切分 JSON 文件CharacterTextSplitter 用于通过指定分隔符切分文本
6.5 索引:生成嵌入
嵌入器是将文档切片转换成向量(embeddings),以便存储到向量数据库(VectorStore)中。Embeddings 的本质是将文本映射到一个高维空间中的向量,使得语义相似的文本在空间中的距离更近。LangChain 提供了多种嵌入器,包括 OpenAI, Cohere, Hugging Face 等提供的多种模型,详细的嵌入器列表可以参考官方文档。下面我们以嵌入器为例,展示如何使用 OpenAIEmbeddings 嵌入文档切片:from langchain_openai import OpenAIEmbeddings
embedding = OpenAIEmbeddings()
embedded_query = embedding.embed_query("What was the name mentioned in the conversation?")
print(embedded_query[:5])
[0.005384807424727807, -0.0005522561790177147, 0.03896066510130955, -0.002939867294003909, -0.008987877434176603]
在上面的代码中,我们使用了 OpenAIEmbeddings 来嵌入查询,然后打印出了嵌入后的前 5 个元素。LangChain 中的 Embeddings 接口提供了 embed_query 和 embed_documents 两个方法,分别用于嵌入查询和文档切片。因为不同的嵌入器可能会针对文档和查询提供不同的实现。6.6 索引:存储嵌入
存储器是将嵌入后的 embeddings 存储到向量数据库(VectorStore)中,以便在检索时能够快速找到相关的数据。使用 embeddings 和向量数据库可以实现语义匹配,这也是 RAG 和传统关键词匹配的区别。最常见的相似度计算方法是使用余弦相似度。LangChain 提供了多种存储器,常见开源可本地部署的有 Chroma、Faiss、Lance 等,详细的存储器列表可以参考官方文档。下面我们以存储器为例,展示如何使用 ChromaVectorStore 存储嵌入后的 embeddings:from langchainhub.vectorstores import ChromaVectorStore
vectorstore = Chroma.from_documents(documents=splits, embedding=embedding)
query = "如何在开源项目中使用 ChatGPT ?"
docs = vectorstore.similarity_search(query)
print(docs[0].page_content)
在上面的代码中,我们使用了 Chroma 来存储嵌入后的 embeddings,然后使用 similarity_search 方法通过查询文本检索数据。这里需要留意的是,虽然原始的 PDF 文档是英文,而代码中的查询是中文,但依然可以查询到相关文档,这就是语义搜索的魅力。除了 similarity_search,我们还可以使用 similarity_search_by_vector 直接通过向量检索数据。6.7 查询检索
RAG的第二大部分是检索与生成, 依据问题,找出相关度最高的内容,将其融入到提示信息中并生成回复。LangChain 内置了多种检索器,最常见和简单的是基于向量数据库的检索器,详细的检索器列表可以参考官方文档。不同的检索器适合不同的场景,可以参照官方提供的对比表格进行选择:| 名称 | 索引类型 | 使用LLM | 使用时机 | 描述 |
| | | | 这是获取开始的最简单方法。它涉及为每个文本创建嵌入。 |
| | | 如果你的页面有很多更小的独立信息块,它们最好单独索引,但最好一起检索。 | 这涉及为每个文档索引多个块。然后你在嵌入空间找到最相似的块,但检索整个父文档并返回(而不是单个块)。 |
| | | 如果你能够从文档中提取出你认为比文本本身更有索引价值的信息。 | 这涉及为每个文档创建多个向量。每个向量的创建方式有很多种 - 例如包括文本的摘要和假设性问题。 |
| | | 如果用户提出的问题更适合根据元数据而不是与文本的相似性来检索文档。 | 这使用LLM将用户输入转换为两件事:(1)用于语义查找的字符串,(2)与之相关的元数据过滤器。这很有用,因为很多时候问题是关于文档的元数据(而不是内容本身)。 |
| | | 如果你发现检索到的文档包含太多无关信息,分散了LLM的注意力。 | 这在另一个检索器之上放置了一个后处理步骤,只提取检索到的文档中最相关的信息。这可以使用嵌入或LLM来完成。 |
| Time-Weighted Vectorstore | | | | 这根据语义相似性(如正常向量检索)和最近性(查看索引文档的时间戳)来检索文档。 |
| | | 如果用户提出的问题复杂,需要多个独立的信息块来回答。 | 这使用LLM从原始问题生成多个查询。当原始问题需要关于多个主题的信息块才能得到正确回答时,这很有用。通过生成多个查询,我们可以为每个查询获取文档。 |
| | | | |
| | | 如果你使用长上下文模型,并发现它没有关注检索文档中间的信息。 | 这从底层检索器获取文档,然后重新排序,使最相似的文档位于开始和结束处。这很有用,因为已经显示,对于更长的上下文模型,它们有时不会关注上下文窗口中间的信息。 |
除了内置检索器,LangChain 还支持集成多种外部检索器,详细列表可以参考官方文档。此外,LangChain 还支持自定义检索器,示例代码可以参考官方文档。下面我们展示如何使用 VectorStoreRetriever 检索数据:retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 6})
query = "如何在开源项目中使用 ChatGPT ?"
docs = retriever.invoke(query)
print(len(docs))
print(docs[0].page_content)
在上面的代码中,我们基于 vectorstore 创建了一个检索器,并且指定 search_type="similarity" 表示使用相似度检索,,search_kwargs={"k": 6} 表示最多返回 6 个结果,然后调用 invoke 方法检索数据。生成
生成就是基于用户的问题和检索到的数据,拼装进提示,然后调用 LLM 生成答案。下面我们展示如何使用 OpenAI 的 gpt-3.5-turbo 模型构造 chain 生成答案:from langchain_openai import ChatOpenAI
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# 从 Hub 中加载 RAG Prompt
prompt = hub.pull("rlm/rag-prompt")
# 使用 OpenAI 的 gpt-3.5-turbo 模型
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# 格式化文档
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 构建 chain
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 以流的方式生成答案
for chunk in rag_chain.stream("What is Task Decomposition?"):
print(chunk, end="", flush=True)
在上面的代码中,我们使用了 ChatOpenAI 来加载 OpenAI 的 gpt-3.5-turbo 模型,然后构建了一个 chain,其中包含了检索、格式化、提示和生成等步骤。最后以流的方式生成答案。代码中涉及到的关键概念有:hub.pull:从 Hub 中加载 RAG Prompt,Hub 是 LangChain 提供的一个中心化的模型仓库,可以方便地获取和分享模型。|:管道操作符,用于连接多个 Runnable。基于 LangChain Expression Language (LCEL) 的语法,可以方便地构建复杂的 chain,类似于 Unix 管道。LCEL 提供了非常多的特性,包括异步、批量执行、并发执行、流式、重试和回退等,在我看来就是 LangChain 的精髓所在,详细介绍可以参考官方文档。RunnablePassthrough:一个简单的 Runnable,用于传递输入StrOutputParser:一个简单的 OutputParser,用于将输出转换成字符串
LangChain 针对 LLM 的调用提供了两种不同的抽象:ChatModel 和 LLM。前者接收聊天消息列表返回单个聊天消息,比如我们上面代码中使用的 ChatOpenAI;后者接收一个字符串返回一个字符串。这两种抽象可以根据实际情况选择,详细对比和介绍可以参考官方文档。总结
好了,到这里我们已经完成了一个简单的 RAG 聊天机器人的构建,可以看出 LangChain 提供了非常多的组件和特性,从而帮助我们快速构建出适应各种场景的智能应用。限于篇幅,这篇文章就先到这里,在后续文章中我们将继续深入探讨搭建一个生产级 RAG 聊天机器人所需要的更多高级特性,比如多模型集成、多语言支持、多轮对话、实时更新等,敬请期待!说在最后:有问题找老架构取经
毫无疑问,大模型架构师更有钱途, 这个代表未来的架构。前面讲到,尼恩指导的那个一个成功案例,是一个9年经验 网易的小伙伴,拿到了一个年薪近80W的大模型架构offer,逆涨50%,那是在去年2023年的 5月。不到1年,小伙伴也在团队站稳了脚跟,成为了名副其实的大模型架构师。回想当时,尼恩本来是规划指导小伙做通用架构师的( JAVA 架构、K8S云原生架构), 当时候为了他的钱途, 尼恩也是 壮着胆子, 死马当作活马指导他改造为 大模型架构师。没想到,由于尼恩的大胆尝试, 小伙伴成了, 相当于他不到1年时间, 职业身价翻了1倍多,现在可以拿到年薪 200W的offer了。既然有一个这么成功的案例,尼恩能想到的,就是希望能帮助更多的社群小伙伴, 成长为大模型架构师,也去逆天改命。这一次,尼恩团队用积累了20年的深厚的架构功力,编写一个《LLM大模型学习圣经》,帮助大家进行一次真正的AI架构穿透,帮助大家穿透AI架构。尼恩架构团队的大模型《LLM大模型学习圣经》是一个系列,初步的规划包括下面的内容:- 《LLM大模型学习圣经:从0到1精通RAG架构,基于LLM+RAG构建生产级企业知识库》
- 《LLM大模型学习圣经:从0到1吃透大模型的顶级架构》
本文是第2篇,这一篇的作者是robin。后面的文章,尼恩团队会持续迭代和更新。 并且录制配套视频。当然,除了大模型学习圣经,尼恩团队,持续深耕技术,为大家输出更多,更深入的技术体系,思想体系。多年来,用深厚的架构功力,把很多复杂的问题做清晰深入的穿透式、起底式的分析,写了大量的技术圣经:- Netty 学习圣经:穿透Netty的内存池和对象池(那个超级难,很多人穷其一生都搞不懂),
- Caffeine学习圣经:比如Caffeine的底层架构,

































 粤ICP备17114055号
粤ICP备17114055号