
































 粤ICP备17114055号
粤ICP备17114055号
微信扫码
添加专属顾问
我要投稿
03
—
智能录制和纪要
腾讯会议推出覆盖会议全流程的AI小助手,通过简单自然的指令,完成信息提取、内容分析、会管会控等多种复杂任务,提升开会和信息流转效率。
腾讯会议官网
在快节奏的工作环境中,会议效率和信息管理变得日益重要。用户需要工具帮助他们更好地抓住会议重点、管理会议产出和后续跟进。腾讯会议AI小助手旨在通过AI技术提升会议的效率和效果。
根据官方介绍,其主要的使用场景包括:
实时紧急回顾:提供快速回溯会议内容的功能,让用户能够迅速获取错过的讨论。
个性化提醒事项:根据用户设定的关键词或成员发言进行实时提醒
晚入会无后顾之忧:为晚入会者提供入会前的会议内容回顾
会中实时会议纪要:自动提炼讨论内容,生成结构化的会议纪要
个性化纪要总结:提供针对特定议题或人员的纪要总结
会后智能提炼纪要:对会议全程进行智能提炼,突出重点议题
高效整理待办事项:自动识别和整理会议中的任务和责任人
会议录制个性回顾:针对性回顾会议中的关键发言和内容
而这些基本都依赖于腾讯会议的“智能录制”和“智能纪要”功能,加上混元大模型提供支持得以实现。
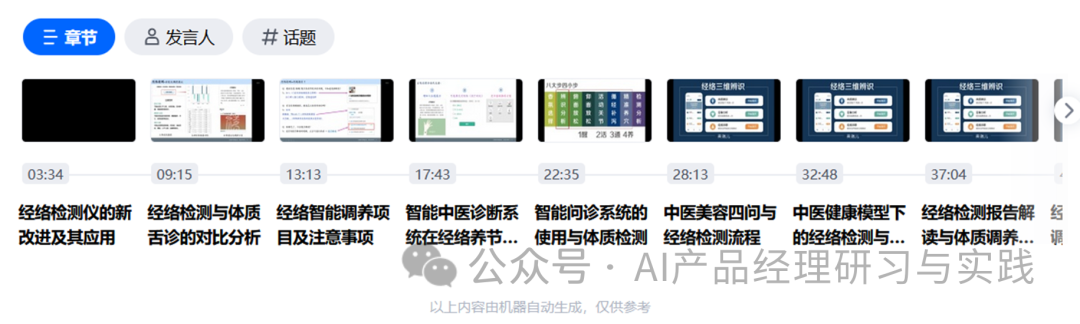
腾讯会议在全程文字转写的基础上推出了智能纪要,可基于全文或者分章节进行智能摘要总结,帮助未参会人员在一拿到会议录制的时候,对会议有全局的把握,更好地去理解会议内容,提高沟通协作效率。
智能录制和纪要的功能包括:
1.总结与纪要

用户故事:Alice需要在离开并返回会议后,快速了解错过的重要内容。
功能需求:
支持按用户指定的要求(如时间范围、发言人、特定主题等),自动分析会议内容,提炼纪要。
会议结束后自动生成简介的总体纪要。
技术实现:
使用NLP技术自动提取关键信息,如决策点和重要议题。
应用时间戳和语音识别来支持时间范围的纪要提炼。
整合混元大模型等先进AI算法进行内容分析和总结。
2.章节与发言人标注
用户故事:陈先生是一名项目经理,负责管理多个跨部门的项目。由于参与者众多,他的会议通常内容丰富且持续时间较长。在回顾会议内容时,他经常花费大量时间寻找特定议题的讨论。他需要一种方式,能够快速定位到长时间会议中的特定讨论内容,以提高工作效率和会议内容的管理。
这时,我们就可以定义一个名为“智能章节”的功能:
智能章节功能:自动将会议录制视频划分为若干章节,每个章节对应会议的一个主要议题或讨论点。
章节概述和纪要:为每个章节生成简短的概述和详细纪要,帮助用户快速了解每个部分的核心内容。
快速定位和导航:提供类似于书籍目录的导航界面,使用户能够快速跳转到感兴趣的章节。
从实现层面,我们需要考虑:
NLP和文本分析:
使用自然语言处理技术来分析会议转写文本,识别不同的讨论主题和自然的切换点。
应用文本摘要技术生成每个章节的概述和纪要。
机器学习和模式识别:
训练机器学习模型来识别会议中的关键议题和结构变化。
采用模式识别技术来识别和标记不同章节的开始和结束。
语音和视频处理:
将语音识别与视频内容分析相结合,确保章节标注与视觉内容一致。
实现音频和视频内容的同步分析,以准确划分章节。
用户界面设计:
设计直观的章节导航界面,使用户可以像浏览书籍目录一样,轻松访问不同章节。
提供章节预览和跳转功能,以提高用户的浏览效率。
由于参会人使用了不同的输入设备(麦克风),采集/录制的时候就可以分成不同的音轨,加上对登录用户的身份识别,发言人的识别是比较好办的。但是当不同用户使用同一个设备时,我们就需要额外采用声纹识别技术来区分发言人了:
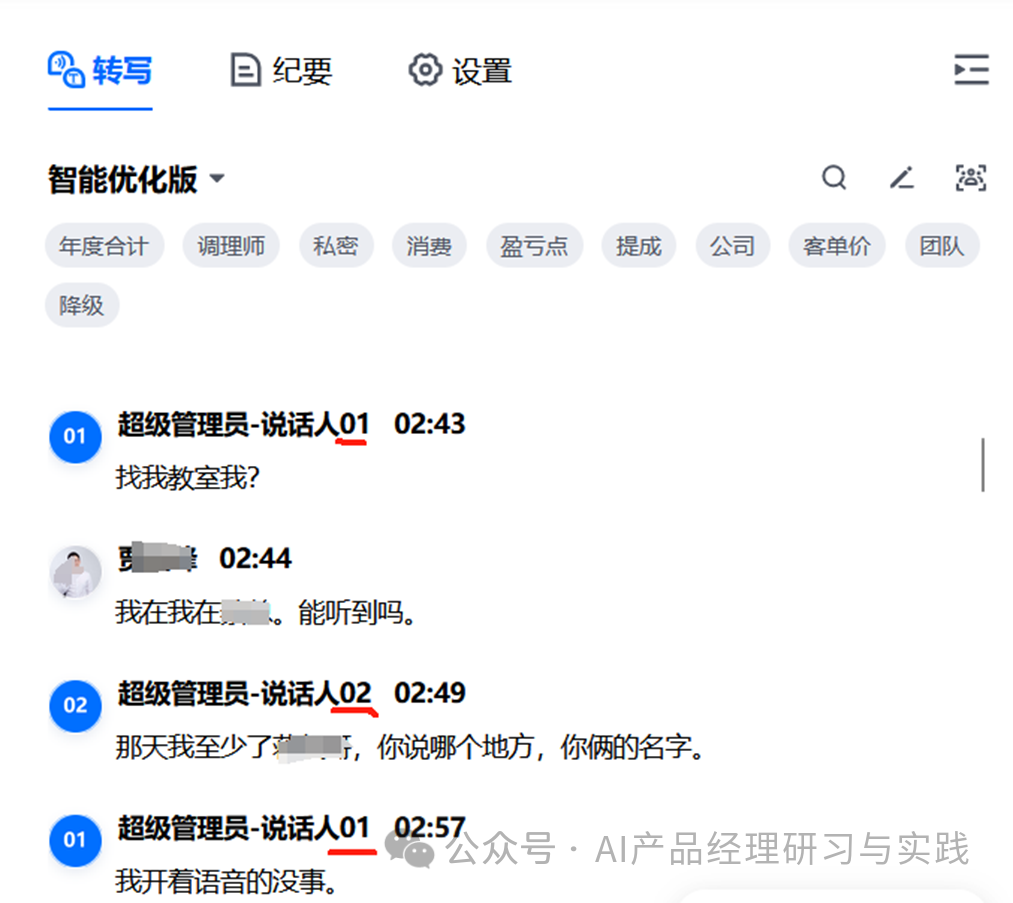
声纹识别技术是一种基于声音特征来识别和验证个体身份的技术。它利用的是每个人的声音都有其独特的特征,类似于指纹。其关键特征和实现为:
声音特征提取:从音频信号中提取个人的声音特征,这些特征可能包括音调、语速、发音方式等。
模型训练:使用机器学习技术,尤其是深度学习模型,来分析这些声音特征,并训练模型识别不同个体的声纹。
发言人识别:在实际应用中,声纹识别技术可以用来识别会议中的不同发言人,即使多人使用同一设备进行通话。
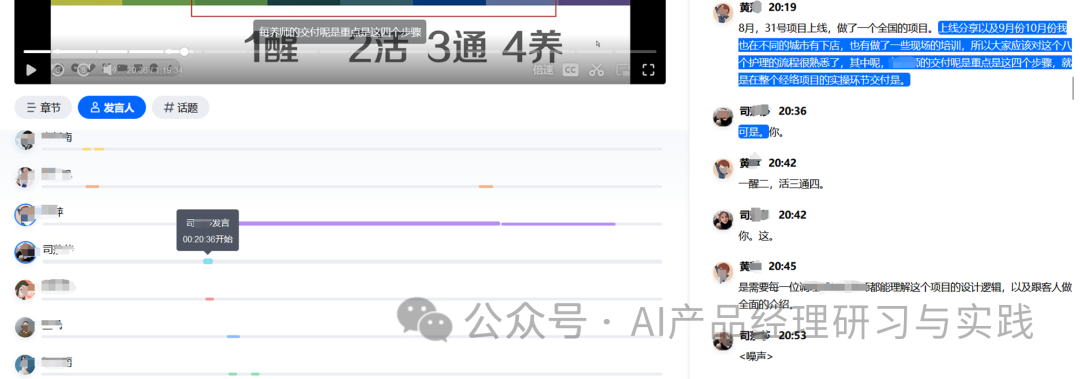
如此一来,智能章节+发言人标注,将极大地提升会议内容管理的效率,使用户能够快速定位和回顾关键讨论。
例如,结合发言人的识别和内容的分析,可以针对发言者的主要观点生成个性化的摘要。
2.话题标注
用户故事:王女士是一家科技公司的团队领导,她经常参加涉及多个项目和议题的会议。由于会议内容繁杂,她希望能快速抓住会议中的重点话题,特别是那些与她的项目直接相关的部分。她需要一种工具,能够自动分析会议内容,快速提炼出会议的核心话题和热点,帮助她更有效地回顾和跟踪相关讨论。
功能描述:
智能话题归纳:自动分析会议录制的内容,识别并总结会议中的关键话题和热点。
个性化回顾导航:提供一个界面,展示归纳出的话题列表,方便用户根据个性化需求选择和回顾特定内容。
内容摘要:为每个识别的话题提供简短的摘要,概述该话题在会议中的讨论要点。
话题编辑:支持用户添加关键词作为话题标签,保存成功后系统自动匹配对应的转写文本段落、录制音视频文件时间段。同时也支持修改或删除话题标签。
用户界面设计:
提供一个直观的界面,展示会议的话题列表和相关摘要,使用户能够轻松选择和浏览感兴趣的内容。
提供搜索和筛选功能,帮助用户快速定位特定话题或相关讨论。
提供添加、编辑、删除功能,以支持用户更加灵活和个性化地定义和圈选话题内容。
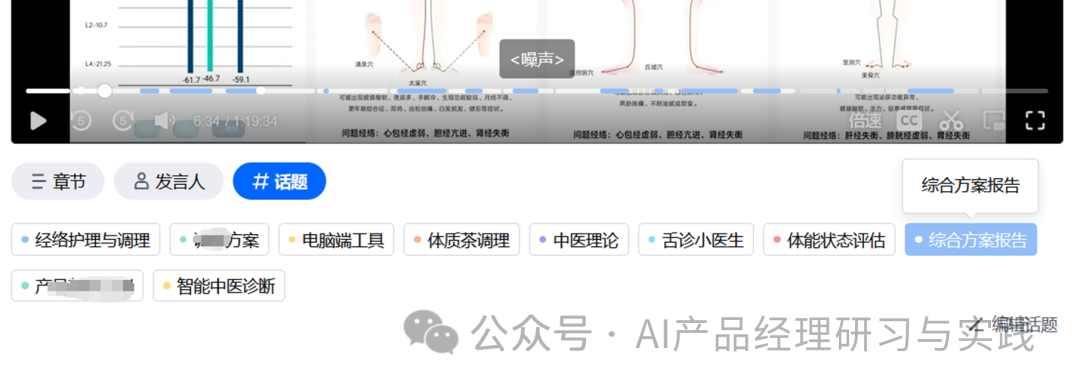
在技术实现层面,就需要考虑:
NLP和文本分析:
使用自然语言处理技术分析转写的会议文本,识别讨论中的关键词和短语。
应用文本摘要和话题模型技术,从会议内容中提取主要话题。
机器学习和模式识别:
训练机器学习模型来识别常见的讨论模式和话题转换。
使用模式识别技术自动归类讨论内容,生成话题列表。
用上“云录制+自动会议纪要”的组合,可轻松解放你的双手和大脑,把时间和精力专注在会议讨论和后续执行上。
最后,对于云录制文件、转写纪要等内容,腾讯会议还支持:
翻译:支持将当前的转写文本按指定目标语言翻译
导出与分享:会议创建者及有权限的用户可以对转写/编辑/优化后的文本进行导出或分享。
04
—
视频处理
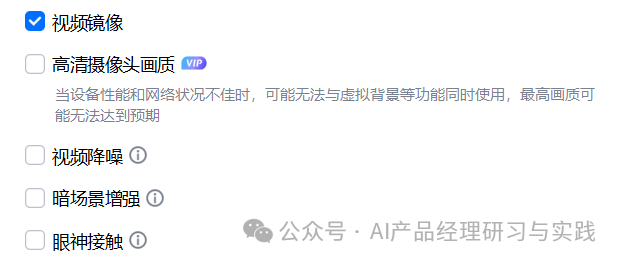
1.高清摄像头画质

用户故事:营销经理Tom需要在客户演示中展示产品细节,高清画质可以帮助客户更好地理解产品优势。
高清摄像头画质是一种视频优化技术,它需要使用先进的编解码器(如H.265)和AI增强算法来提供1080P的视频质量。其基本原理是:
高效编解码:使用最新的视频编解码技术,减少数据传输量同时保持图像质量。
AI图像处理:通过AI算法优化图像质量,包括清晰度、对比度和色彩饱和度。
带宽自适应:根据可用网络带宽调整视频流的质量,确保稳定传输。
作为AI产品经理,我们就得联合研发团队开展以下工作:
硬件和软件要求确认:定义所需的最小硬件规格和软件版本,确保用户能够达到最佳使用效果。
用户界面设计:在腾讯会议设置中添加明确的选项,让用户可以轻松开启高清摄像头画质。
性能优化:确保软件在不同的设备和网络条件下均能提供优质的视频体验。
用户教育:通过帮助文档和提示,教育用户如何满足硬件和网络条件,以充分利用高清功能。
对应这个功能,可能适合的性能和模型评估方法是:
用户反馈:收集用户反馈,特别是关于画质的满意度,作为性能的直接指标。
使用数据分析:分析开启高清功能的用户数量和频率,以及在不同网络条件下的表现。
技术监测:监测CPU和带宽使用情况,确保在低占用率下提供稳定的高清视频。
2.视频降噪
用户故事:李先生是一位远程工作的软件开发者,他居住在繁忙的市区,他的工作空间临近交通路口和建筑工地,这些环境和噪音影响了他视频会议中的画面质量,例如出现颗粒状噪声。每次开会,李先生总是担心他的视频质量会影响同事对他工作的看法。有时他需要在屏幕上展示代码或文档,而噪点影响了细节的清晰度。
对于这种情形,我们可以应用深度学习算法,来实时识别和去除视频中的噪声。这些算法可以训练识别常见的干扰模式,比如模糊和颗粒,然后清晰地重建图像。其基本原理是:
图像噪声识别:AI模型识别视频中的噪声元素,如颗粒噪声、运动模糊等。
实时处理:视频流在传输过程中实时进行处理,以提供无噪声的清晰画面。
图像质量提升:除去噪声的同时,AI技术还能提升图像的整体质量,包括对比度和锐度。
因此,我们需要开展以下工作来实现这个AI功能:
数据采集与模型训练:收集各种噪声条件下的视频数据,用于训练降噪模型。
算法集成:将降噪算法集成到腾讯会议软件中,确保它能在不同硬件和网络条件下工作。
用户体验优化:不断测试和优化算法,以提供更自然和令人满意的视频体验。
性能监控与调整:监控算法的性能,包括其在不同网络带宽和不同摄像头硬件上的表现,根据反馈进行调整。
3.暗场景增强
用户故事:Alice是一位远程工作者,她经常需要在晚上参加跨时区的视频会议,但她的房间光线较暗,普通摄像头无法提供清晰的视频。她希望视频质量能够在会议中得到提高。
为了设计一个能够自动调整视频设置以适应不同光线条件的系统,团队(不一定是AI产品经理)就需要调研现有的图像处理和增强算法,选择或开发最适合技术,例如:
计算机视觉算法:使用计算机视觉算法来增强视频帧的质量,包括亮度调节、对比度优化等。
深度学习模型:利用深度学习模型进行图像增强,如自适应曝光调整、颜色校正等。
实时视频处理策略:设计算法以便在不牺牲实时性的情况下实现视频质量的改善。
其对应的基本原理是:
亮度增强:通过AI模型实时分析视频帧,智能调整亮度,使图像在暗环境中依然清晰。
噪声抑制:使用噪声抑制技术,如波段滤波器,去除由于低光环境引入的噪点。
边缘增强:通过边缘检测和锐化技术,提升视频中物体轮廓的清晰度。
然后,我们就可以在研发过程中,进行内部测试以评估算法在各种环境下的表现,收集反馈并优化算法,最终集成到腾讯会议产品中并上线。
那么,我们应该从哪些方面评估这个算法/模型的性能和质量呢?以下是可能适合的指标:
画质清晰度:用户在不同光照条件下的视频清晰度显著提高。
用户满意度:通过调查和反馈收集,用户满意度有明显提升。
使用频率:在低光环境下使用腾讯会议的频率增加,尤其是在晚上或暗光环境中。
性能指标:确保算法优化不会引入过长的延迟或过高的计算成本。
4.眼神接触
在视频会议中,直视摄像头来维持眼神接触通常是不自然的,尤其是当用户需要查看屏幕上的内容时。不直接看镜头可能会给对方一种不专注的印象,影响沟通效果。
用户故事:张女士是一名远程客服经理,她需要在视频呼叫中给客户留下良好印象。使用“眼神接触”功能后,即使她查看屏幕资料,客户也感觉到她是在直视他们,这提高了客户服务的质量。
在这种情况线下,我们考虑采用:
视线修正技术:使用机器学习算法调整用户在视频中的眼神方向,使其看起来像是在直视摄像头。
面部追踪技术:实时追踪用户的面部动态,识别用户的脸部特征,并计算眼睛的实际方向,通过图像处理技术在不改变用户脸部其他特征的情况下,微调眼睛区域的图像以模拟直视摄像头的效果,确保眼神接触修正自然且准确。
在这里,我们还需要考虑一些异常情况:
(1)用户的脸部偏移幅度过大。如果这个时候眼神接触仍然生效,就会比较怪异,因此需要测试并定义合理的生效范围。官方表示的是,用户脸部在pitch/roll/yaw三个维度上正负偏移30°以内范围,眼神接触功能可生效。
(2)在同一个摄像头前面不止1位用户。这个时候我们应该只对头部(或者说脸部)占比最大的用户生效更加合理,否则每位成员都被“调整”为同一个眼神方向也会很尴尬。
53AI,企业落地大模型首选服务商
产品:场景落地咨询+大模型应用平台+行业解决方案
承诺:免费场景POC验证,效果验证后签署服务协议。零风险落地应用大模型,已交付160+中大型企业
2025-03-06
2024-09-04
2024-12-25
2024-10-24
2024-04-02
2025-01-25
2024-05-08
2024-07-07
2024-09-26
2024-06-17
2025-04-12
2025-04-11
2025-04-11
2025-04-10
2025-04-09
2025-04-08
2025-04-07
2025-04-06
回到顶部